417 Whats New in Llvm.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The LLVM Instruction Set and Compilation Strategy
The LLVM Instruction Set and Compilation Strategy Chris Lattner Vikram Adve University of Illinois at Urbana-Champaign lattner,vadve ¡ @cs.uiuc.edu Abstract This document introduces the LLVM compiler infrastructure and instruction set, a simple approach that enables sophisticated code transformations at link time, runtime, and in the field. It is a pragmatic approach to compilation, interfering with programmers and tools as little as possible, while still retaining extensive high-level information from source-level compilers for later stages of an application’s lifetime. We describe the LLVM instruction set, the design of the LLVM system, and some of its key components. 1 Introduction Modern programming languages and software practices aim to support more reliable, flexible, and powerful software applications, increase programmer productivity, and provide higher level semantic information to the compiler. Un- fortunately, traditional approaches to compilation either fail to extract sufficient performance from the program (by not using interprocedural analysis or profile information) or interfere with the build process substantially (by requiring build scripts to be modified for either profiling or interprocedural optimization). Furthermore, they do not support optimization either at runtime or after an application has been installed at an end-user’s site, when the most relevant information about actual usage patterns would be available. The LLVM Compilation Strategy is designed to enable effective multi-stage optimization (at compile-time, link-time, runtime, and offline) and more effective profile-driven optimization, and to do so without changes to the traditional build process or programmer intervention. LLVM (Low Level Virtual Machine) is a compilation strategy that uses a low-level virtual instruction set with rich type information as a common code representation for all phases of compilation. -

Operating Systems and Applications for Embedded Systems >>> Toolchains
>>> Operating Systems And Applications For Embedded Systems >>> Toolchains Name: Mariusz Naumowicz Date: 31 sierpnia 2018 [~]$ _ [1/19] >>> Plan 1. Toolchain Toolchain Main component of GNU toolchain C library Finding a toolchain 2. crosstool-NG crosstool-NG Installing Anatomy of a toolchain Information about cross-compiler Configruation Most interesting features Sysroot Other tools POSIX functions AP [~]$ _ [2/19] >>> Toolchain A toolchain is the set of tools that compiles source code into executables that can run on your target device, and includes a compiler, a linker, and run-time libraries. [1. Toolchain]$ _ [3/19] >>> Main component of GNU toolchain * Binutils: A set of binary utilities including the assembler, and the linker, ld. It is available at http://www.gnu.org/software/binutils/. * GNU Compiler Collection (GCC): These are the compilers for C and other languages which, depending on the version of GCC, include C++, Objective-C, Objective-C++, Java, Fortran, Ada, and Go. They all use a common back-end which produces assembler code which is fed to the GNU assembler. It is available at http://gcc.gnu.org/. * C library: A standardized API based on the POSIX specification which is the principle interface to the operating system kernel from applications. There are several C libraries to consider, see the following section. [1. Toolchain]$ _ [4/19] >>> C library * glibc: Available at http://www.gnu.org/software/libc. It is the standard GNU C library. It is big and, until recently, not very configurable, but it is the most complete implementation of the POSIX API. * eglibc: Available at http://www.eglibc.org/home. -

What Is LLVM? and a Status Update
What is LLVM? And a Status Update. Approved for public release Hal Finkel Leadership Computing Facility Argonne National Laboratory Clang, LLVM, etc. ✔ LLVM is a liberally-licensed(*) infrastructure for creating compilers, other toolchain components, and JIT compilation engines. ✔ Clang is a modern C++ frontend for LLVM ✔ LLVM and Clang will play significant roles in exascale computing systems! (*) Now under the Apache 2 license with the LLVM Exception LLVM/Clang is both a research platform and a production-quality compiler. 2 A role in exascale? Current/Future HPC vendors are already involved (plus many others)... Apple + Google Intel (Many millions invested annually) + many others (Qualcomm, Sony, Microsoft, Facebook, Ericcson, etc.) ARM LLVM IBM Cray NVIDIA (and PGI) Academia, Labs, etc. AMD 3 What is LLVM: LLVM is a multi-architecture infrastructure for constructing compilers and other toolchain components. LLVM is not a “low-level virtual machine”! LLVM IR Architecture-independent simplification Architecture-aware optimization (e.g. vectorization) Assembly printing, binary generation, or JIT execution Backends (Type legalization, instruction selection, register allocation, etc.) 4 What is Clang: LLVM IR Clang is a C++ frontend for LLVM... Code generation Parsing and C++ Source semantic analysis (C++14, C11, etc.) Static analysis ● For basic compilation, Clang works just like gcc – using clang instead of gcc, or clang++ instead of g++, in your makefile will likely “just work.” ● Clang has a scalable LTO, check out: https://clang.llvm.org/docs/ThinLTO.html 5 The core LLVM compiler-infrastructure components are one of the subprojects in the LLVM project. These components are also referred to as “LLVM.” 6 What About Flang? ● Started as a collaboration between DOE and NVIDIA/PGI. -

CUDA Flux: a Lightweight Instruction Profiler for CUDA Applications
CUDA Flux: A Lightweight Instruction Profiler for CUDA Applications Lorenz Braun Holger Froning¨ Institute of Computer Engineering Institute of Computer Engineering Heidelberg University Heidelberg University Heidelberg, Germany Heidelberg, Germany [email protected] [email protected] Abstract—GPUs are powerful, massively parallel processors, hardware, it lacks verbosity when it comes to analyzing the which require a vast amount of thread parallelism to keep their different types of instructions executed. This problem is aggra- thousands of execution units busy, and to tolerate latency when vated by the recently frequent introduction of new instructions, accessing its high-throughput memory system. Understanding the behavior of massively threaded GPU programs can be for instance floating point operations with reduced precision difficult, even though recent GPUs provide an abundance of or special function operations including Tensor Cores for ma- hardware performance counters, which collect statistics about chine learning. Similarly, information on the use of vectorized certain events. Profiling tools that assist the user in such analysis operations is often lost. Characterizing workloads on PTX for their GPUs, like NVIDIA’s nvprof and cupti, are state-of- level is desirable as PTX allows us to determine the exact types the-art. However, instrumentation based on reading hardware performance counters can be slow, in particular when the number of the instructions a kernel executes. On the contrary, nvprof of metrics is large. Furthermore, the results can be inaccurate as metrics are based on a lower-level representation called SASS. instructions are grouped to match the available set of hardware Still, even if there was an exact mapping, some information on counters. -

XL C/C++: Language Reference About This Document
IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 Note Before using this information and the product it supports, read the information in “Notices” on page 63. First edition This edition applies to IBM XL C/C++ for Linux, V16.1.1 (Program 5765-J13, 5725-C73) and to all subsequent releases and modifications until otherwise indicated in new editions. Make sure you are using the correct edition for the level of the product. © Copyright IBM Corporation 1998, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document ......... v Chapter 4. IBM extension features ... 11 Who should read this document........ v IBM extension features for both C and C++.... 11 How to use this document.......... v General IBM extensions ......... 11 How this document is organized ....... v Extensions for GNU C compatibility ..... 15 Conventions .............. v Extensions for vector processing support ... 47 Related information ........... viii IBM extension features for C only ....... 56 Available help information ........ ix Extensions for GNU C compatibility ..... 56 Standards and specifications ........ x Extensions for vector processing support ... 58 Technical support ............ xi IBM extension features for C++ only ...... 59 How to send your comments ........ xi Extensions for C99 compatibility ...... 59 Extensions for C11 compatibility ...... 59 Chapter 1. Standards and specifications 1 Extensions for GNU C++ compatibility .... 60 Chapter 2. Language levels and Notices .............. 63 language extensions ......... 3 Trademarks ............. -

Section “Common Predefined Macros” in the C Preprocessor
The C Preprocessor For gcc version 12.0.0 (pre-release) (GCC) Richard M. Stallman, Zachary Weinberg Copyright c 1987-2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation. A copy of the license is included in the section entitled \GNU Free Documentation License". This manual contains no Invariant Sections. The Front-Cover Texts are (a) (see below), and the Back-Cover Texts are (b) (see below). (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Table of Contents 1 Overview :::::::::::::::::::::::::::::::::::::::: 1 1.1 Character sets:::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Initial processing ::::::::::::::::::::::::::::::::::::::::::::::: 2 1.3 Tokenization ::::::::::::::::::::::::::::::::::::::::::::::::::: 4 1.4 The preprocessing language :::::::::::::::::::::::::::::::::::: 6 2 Header Files::::::::::::::::::::::::::::::::::::: 7 2.1 Include Syntax ::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Include Operation :::::::::::::::::::::::::::::::::::::::::::::: 8 2.3 Search Path :::::::::::::::::::::::::::::::::::::::::::::::::::: 9 2.4 Once-Only Headers::::::::::::::::::::::::::::::::::::::::::::: 9 2.5 Alternatives to Wrapper #ifndef :::::::::::::::::::::::::::::: -

Implementing Continuation Based Language in LLVM and Clang
Implementing Continuation based language in LLVM and Clang Kaito TOKUMORI Shinji KONO University of the Ryukyus University of the Ryukyus Email: [email protected] Email: [email protected] Abstract—The programming paradigm which use data seg- 1 __code f(Allocate allocate){ 2 allocate.size = 0; ments and code segments are proposed. This paradigm uses 3 goto g(allocate); Continuation based C (CbC), which a slight modified C language. 4 } 5 Code segments are units of calculation and Data segments are 6 // data segment definition sets of typed data. We use these segments as units of computation 7 // (generated automatically) 8 union Data { and meta computation. In this paper we show the implementation 9 struct Allocate { of CbC on LLVM and Clang 3.7. 10 long size; 11 } allocate; 12 }; I. A PRACTICAL CONTINUATION BASED LANGUAGE TABLE I The proposed units of programming are named code seg- CBCEXAMPLE ments and data segments. Code segments are units of calcu- lation which have no state. Data segments are sets of typed data. Code segments are connected to data segments by a meta data segment called a context. After the execution of a code have input data segments and output data segments. Data segment and its context, the next code segment (continuation) segments have two kind of dependency with code segments. is executed. First, Code segments access the contents of data segments Continuation based C (CbC) [1], hereafter referred to as using field names. So data segments should have the named CbC, is a slight modified C which supports code segments. -

Cheat Sheets of the C Standard Library
Cheat Sheets of the C standard library Version 1.06 Last updated: 2012-11-28 About This document is a set of quick reference sheets (or ‘cheat sheets’) of the ANSI C standard library. It contains function and macro declarations in every header of the library, as well as notes about their usage. This document covers C++, but does not cover the C99 or C11 standard. A few non-ANSI-standard functions, if they are interesting enough, are also included. Style used in this document Function names, prototypes and their parameters are in monospace. Remarks of functions and parameters are marked italic and enclosed in ‘/*’ and ‘*/’ like C comments. Data types, whether they are built-in types or provided by the C standard library, are also marked in monospace. Types of parameters and return types are in bold. Type modifiers, like ‘const’ and ‘unsigned’, have smaller font sizes in order to save space. Macro constants are marked using proportional typeface, uppercase, and no italics, LIKE_THIS_ONE. One exception is L_tmpnum, which is the constant that uses lowercase letters. Example: int system ( const char * command ); /* system: The value returned depends on the running environment. Usually 0 when executing successfully. If command == NULL, system returns whether the command processor exists (0 if not). */ License Copyright © 2011 Kang-Che “Explorer” Sung (宋岡哲 <explorer09 @ gmail.com>) This work is licensed under the Creative Commons Attribution 3.0 Unported License. http://creativecommons.org/licenses/by/3.0/ . When copying and distributing this document, I advise you to keep this notice and the references section below with your copies, as a way to acknowledging all the sources I referenced. -

Nesc 1.2 Language Reference Manual
nesC 1.2 Language Reference Manual David Gay, Philip Levis, David Culler, Eric Brewer August 2005 1 Introduction nesC is an extension to C [3] designed to embody the structuring concepts and execution model of TinyOS [2]. TinyOS is an event-driven operating system designed for sensor network nodes that have very limited resources (e.g., 8K bytes of program memory, 512 bytes of RAM). TinyOS has been reimplemented in nesC. This manual describes v1.2 of nesC, changes from v1.0 and v1.1 are summarised in Section 2. The basic concepts behind nesC are: • Separation of construction and composition: programs are built out of components, which are assembled (“wired”) to form whole programs. Components define two scopes, one for their specification (containing the names of their interfaces) and one for their implementation. Components have internal concurrency in the form of tasks. Threads of control may pass into a component through its interfaces. These threads are rooted either in a task or a hardware interrupt. • Specification of component behaviour in terms of set of interfaces. Interfaces may be provided or used by the component. The provided interfaces are intended to represent the functionality that the component provides to its user, the used interfaces represent the functionality the component needs to perform its job. • Interfaces are bidirectional: they specify a set of functions to be implemented by the inter- face’s provider (commands) and a set to be implemented by the interface’s user (events). This allows a single interface to represent a complex interaction between components (e.g., registration of interest in some event, followed by a callback when that event happens). -

INTRODUCTION to ANSI C Outline
1/17/14 INTRODUCTION TO ANSI C Dr. Chokchai (Box) Leangsuksun Louisiana Tech University Original slides were created by Dr. Tom Chao Zhou, https://www.cse.cuhk.edu.hk 1 Outline • History • Introduction to C – Basics – If Statement – Loops – Functions – Switch case – Pointers – Structures – File I/O Louisiana Tech University 2 1 1/17/14 Introduction • The C programming language was designed by Dennis Ritchie at Bell Laboratories in the early 1970s • Influenced by – ALGOL 60 (1960), – CPL (Cambridge, 1963), – BCPL (Martin Richard, 1967), – B (Ken Thompson, 1970) • Traditionally used for systems programming, though this may be changing in favor of C++ • Traditional C: – The C Programming Language, by Brian Kernighan and Dennis Ritchie, 2nd Edition, Prentice Hall – Referred to as K&R Original by Fred Kuhns) Louisiana Tech University 3 Standard C • Standardized in 1989 by ANSI (American National Standards Institute) known as ANSI C • International standard (ISO) in 1990 which was adopted by ANSI and is known as C89 • As part of the normal evolution process the standard was updated in 1995 (C95) and 1999 (C99) • C++ and C – C++ extends C to include support for Object Oriented Programming and other features that facilitate large software development projects – C is not strictly a subset of C++, but it is possible to write “Clean C” that conforms to both the C++ and C standards. Original by Fred Kuhns) Original by Fred Kuhns) Louisiana Tech University 4 2 1/17/14 Elements of a C Program • A C development environment: – Application Source: application source and header files – System libraries and headers: a set of standard libraries and their header files. -

Code Transformation and Analysis Using Clang and LLVM Static and Dynamic Analysis
Code transformation and analysis using Clang and LLVM Static and Dynamic Analysis Hal Finkel1 and G´abor Horv´ath2 Computer Science Summer School 2017 1 Argonne National Laboratory 2 Ericsson and E¨otv¨osLor´adUniversity Table of contents 1. Introduction 2. Static Analysis with Clang 3. Instrumentation and More 1 Introduction Space of Techniques During this set of lectures we'll cover a space of techniques for the analysis and transformation of code using LLVM. Each of these techniques have overlapping areas of applicability: Static Analysis LLVM Instrumentation Source Transformation 2 Space of Techniques When to use source-to-source transformation: • When you need to use the instrumented code with multiple compilers. • When you intend for the instrumentation to become a permanent part of the code base. You'll end up being concerned with the textual formatting of the instrumentation if humans also need to maintain or enhance this same code. 3 Space of Techniques When to use Clang's static analysis: • When the analysis can be performed on an AST representation. • When you'd like to maintain a strong connection to the original source code. • When false negatives are acceptable (i.e. it is okay if you miss problems). https://clang-analyzer.llvm.org/ 4 Space of Techniques When to use IR instrumentation: • When the necessary conditions can be (or can only be) detected at runtime (often in conjunction with a specialized runtime library). • When you require stronger coverage guarantees than static analysis. • When you'd like to reduce the cost of the instrumentation by running optimizations before the instrumentation is inserted, after the instrumentation is inserted, or both. -
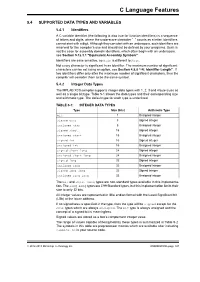
C Language Features
C Language Features 5.4 SUPPORTED DATA TYPES AND VARIABLES 5.4.1 Identifiers A C variable identifier (the following is also true for function identifiers) is a sequence of letters and digits, where the underscore character “_” counts as a letter. Identifiers cannot start with a digit. Although they can start with an underscore, such identifiers are reserved for the compiler’s use and should not be defined by your programs. Such is not the case for assembly domain identifiers, which often begin with an underscore, see Section 5.12.3.1 “Equivalent Assembly Symbols”. Identifiers are case sensitive, so main is different to Main. Not every character is significant in an identifier. The maximum number of significant characters can be set using an option, see Section 4.8.8 “-N: Identifier Length”. If two identifiers differ only after the maximum number of significant characters, then the compiler will consider them to be the same symbol. 5.4.2 Integer Data Types The MPLAB XC8 compiler supports integer data types with 1, 2, 3 and 4 byte sizes as well as a single bit type. Table 5-1 shows the data types and their corresponding size and arithmetic type. The default type for each type is underlined. TABLE 5-1: INTEGER DATA TYPES Type Size (bits) Arithmetic Type bit 1 Unsigned integer signed char 8 Signed integer unsigned char 8 Unsigned integer signed short 16 Signed integer unsigned short 16 Unsigned integer signed int 16 Signed integer unsigned int 16 Unsigned integer signed short long 24 Signed integer unsigned short long 24 Unsigned integer signed long 32 Signed integer unsigned long 32 Unsigned integer signed long long 32 Signed integer unsigned long long 32 Unsigned integer The bit and short long types are non-standard types available in this implementa- tion.