A Grammar Based Approach to Distributed Systems Fault Diagnosis Using Log Files
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microsoft Security Update for January 2020 Fixes 49 Security Vulnerabilities
Microsoft Security Update for January 2020 Fixes 49 Security Vulnerabilities Overview Microsoft released the January security update on Tuesday, fixing 49 security issues ranging from simple spoofing attacks to remote code execution, discovered in products like .NET Framework, Apps, ASP.NET, Common Log File System Driver, Microsoft Dynamics, Microsoft Graphics Component, Microsoft Office, Microsoft Scripting Engine, Microsoft Windows, Microsoft Windows Search Component, Windows Hyper-V, Windows Media, Windows RDP, Windows Subsystem for Linux, and Windows Update Stack. Of the vulnerabilities fixed by Microsoft's this monthly update, a total of eight critical vulnerabilities exist in the .NET Framework, ASP.NET, Microsoft Scripting Engine, and Windows RDP. In addition, there are 41 important vulnerabilities. Critical Vulnerabilities The following are eight critical vulnerabilities covered in this update. @NSFOUS 2020 http://www.nsfocus.com Windows RDP CVE-2020-0609、CVE-2020-0610 These two remote code execution vulnerabilities in the Windows Remote Desktop Gateway (RD Gateway) could be exploited by unauthenticated attackers. If the two vulnerabilities are exploited successfully, arbitrary code may be executed on the target system, allowing the attacker to install the program, view, change or delete data, or create a new account with full user rights. To exploit this vulnerability, an attacker needs to send a specially crafted request to the RD gateway of the target system via RDP. This update addresses these issues by correcting the way the RD gateway handles connection requests. For more details about the vulnerabilities and download updates, please refer to Microsoft's official security advisories: https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2020-0609 https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2020-0610 CVE-2020-0611 This is a remote code execution vulnerability in Windows Remote Desktop clients. -

MIC5161 Win 2003 Launch V6
Microsoft Windows Server 2003 and Microsoft Visual Studio .NET 2003 Launch Guide Do more with less. 1 Contents Introduction 2 Introducing Microsoft® Windows® Server 2003 4 Windows Server 2003 Case Studies 10 Introducing Microsoft® Visual Studio® .NET 2003 26 Visual Studio .NET 2003 Case Studies 41 Australian .NET Connected Partners 47 Microsoft® SQL Server™ 52 Microsoft Exchange Server 53 Windows Server 2003 and Visual Studio .NET 2003 Launch Sponsors 55 Platform Partner 56 Platinum Sponsors 61 Gold Sponsors 81 Silver Sponsors 96 Australian Windows Server 2003 JDP 100 Microsoft Gold Certified Partners 102 2 3 Welcome to the launch of Windows Server 2003! This is an exciting time for In my ten or more years in the Australian developer community, the combination Microsoft, our partners and customers, as this is unquestionably the most of Microsoft Windows Server 2003 and Microsoft Visual Studio® .NET 2003 is customer-focused Windows Server release yet. The reality of today’s IT environment the most exciting launch I have ever been involved with. Last February, Microsoft is the demand to do more with technology and, at the same time, do it with reset the bar for innovation and productivity with a new development paradigm for less cost. Over the last two years, we have spent time with customers using building Web Services and applications – Visual Studio .NET. This year, we build Microsoft® Windows® 2000 Server and Windows NT® Server 4.0 to really on that momentum by offering an entire development platform for the building understand what it would take to enable them do a lot more with Windows Server and execution of those applications. -

3700Document22374461
Copyright (c) 2018, Oracle. All rights reserved. RES QA / Test – Microsoft Patch Security Report (Doc ID 2237446.1) To Bottom Modified: 16-Apr-2018 Type: REFERENCE In this Document Purpose Scope Details Windows Security Updates Miscellaneous Information Internet Explorer 7 Known Issues Internet Explorer 8 Known Issues Internet Explorer 9 Known Issues Internet Explorer 10 Known Issues Internet Explorer 11 Known Issues Adobe Known Issues Non-Security, High Priority Updates Microsoft Security Essentials References APPLIES TO: Oracle Hospitality RES 3700 - Version 4.9.0 and later Information in this document applies to any platform. PURPOSE The Security Report contains a listing of select Microsoft patches that are directly related to the RES and E7 applications and have been tested against the RES and E7 applications to validate there are no issues or identify any updates that should NOT be installed. The list is not inclusive of ALL Microsoft patches. This report is updated monthly for patches released monthly and YTD cumulative. SCOPE This document is intended for support employees and users of the RES E7 products. DETAILS WARNING: On Workstation 2015 – POSReady 2009, the Microsoft “Optional Hardware” Update, “MosChip Semiconductor Technology Ltd – Bus Controllers and Ports – PCI Multi-IO Controller” is incompatible with the RES IDN Driver, and will cause IDN Printing to fail. Even if this update is uninstalled, IDN printing could be effected adversely. DO NOT INSTALL THIS Optional MICROSOFT UPDATE. If this was already done, reload the Ghost image for the 2015 posted on MOS, and reload all other applicable Microsoft Updates. As of August of 2016 the RES Microsoft security bulletin has been split off from the combined RES/e7 bulletin. -

Configuration Sheets
PRIMERGY RX600 S4 Configuration Sheets About this manual A Configuration Sheets of Hardware Use this form to record the hardware configuration and various settings of your server. B Configuration Sheets of BIOS Setup Utility Parameters Use this form to record the settings of the BIOS Setup Utility. C Configuration Sheets of Remote Management Controller's Web Interface Use this form to record the settings of the Remote Management Controller Web interface. D Design Sheet of the RAID Configuration Use this form to record the definitions of the disk groups (or the physical packs) and the logical drives in the RAID configuration (array configuration). E Design Sheet Use this form to record the software settings. F Accident Sheet Use this form to record any failures that occur in your server. 1 Product Names The following expressions and abbreviations are used to describe the product names used in this manual. Product names Expressions and abbreviations PRIMERGY RX600 S4 This server or the server Windows Server 2003 R2, Windows Microsoft® Windows Server® 2003 R2, Standard Edition Standard Edition 2003 Windows Server 2003 R2, Microsoft® Windows Server® 2003 R2, Enterprise Edition Enterprise Edition Windows Server 2003 , Microsoft® Windows Server® 2003 , Enterprise Edition Enterprise Edition Windows Server 2003, Microsoft® Windows Server® 2003, Standard Edition Standard Edition Windows Server 2003 R2, Microsoft® Windows Server® 2003 R2, Standard x64 Edition Standard x64 Edition Windows Server 2003 R2, Microsoft® Windows Server® 2003 R2 , Enterprise x64 Edition Enterprise x64 Edition Windows Server 2003, Microsoft® Windows Server® 2003, Standard x64 Edition Standard x64 Edition Windows Server 2003 , Microsoft® Windows Server® 2003 , Enterprise x64 Edition Enterprise x64 Edition Microsoft® Windows Server® 2003 Service Pack SP ■Trademarks Microsoft, Windows, MS, Windows Server are registered trademarks of the Microsoft Corporation in the USA and other countries. -

Perses: Syntax-Guided Program Reduction
Perses: Syntax-Guided Program Reduction Chengnian Sun Yuanbo Li Qirun Zhang University of California University of California University of California Davis, CA, USA Davis, CA, USA Davis, CA, USA [email protected] [email protected] [email protected] Tianxiao Gu Zhendong Su University of California University of California Davis, CA, USA Davis, CA, USA [email protected] [email protected] ABSTRACT KEYWORDS Given a program P that exhibits a certain property ψ (e.g., a C program reduction, delta debugging, debugging program that crashes GCC when it is being compiled), the goal ACM Reference Format: of program reduction is to minimize P to a smaller variant P 0 that 0 Chengnian Sun, Yuanbo Li, Qirun Zhang, Tianxiao Gu, and Zhendong still exhibits the same property, i.e., ψ ¹P º. Program reduction is Su. 2018. Perses: Syntax-Guided Program Reduction. In ICSE ’18: ICSE ’18: important and widely demanded for testing and debugging. For 40th International Conference on Software Engineering , May 27-June 3, 2018, example, all compiler/interpreter development projects need effec- Gothenburg, Sweden. ACM, New York, NY, USA, 11 pages. https://doi.org/ tive program reduction to minimize failure-inducing test programs 10.1145/3180155.3180236 to ease debugging. However, state-of-the-art program reduction techniques — notably Delta Debugging (DD), Hierarchical Delta 1 INTRODUCTION Debugging (HDD), and C-Reduce — do not perform well in terms of Program reduction is important and widely used. Given a program speed (reduction time) and quality (size of reduced programs), or are P that exhibits a property, the objective of program reduction is to highly customized for certain languages and thus lack generality. -

Linux Networking 101
The Gorilla ® Guide to… Linux Networking 101 Inside this Guide: • Discover how Linux continues its march toward world domination • Learn basic Linux administration tips • See how easy it can be to build your entire network on a Linux foundation • Find out how Cumulus Linux is your ticket to networking freedom David M. Davis ActualTech Media Helping You Navigate The Technology Jungle! In Partnership With www.actualtechmedia.com The Gorilla Guide To… Linux Networking 101 Author David M. Davis, ActualTech Media Editors Hilary Kirchner, Dream Write Creative, LLC Christina Guthrie, Guthrie Writing & Editorial, LLC Madison Emery, Cumulus Networks Layout and Design Scott D. Lowe, ActualTech Media Copyright © 2017 by ActualTech Media. All rights reserved. No portion of this book may be reproduced or used in any manner without the express written permission of the publisher except for the use of brief quotations. The information provided within this eBook is for general informational purposes only. While we try to keep the information up- to-date and correct, there are no representations or warranties, express or implied, about the completeness, accuracy, reliability, suitability or availability with respect to the information, products, services, or related graphics contained in this book for any purpose. Any use of this information is at your own risk. ActualTech Media Okatie Village Ste 103-157 Bluffton, SC 29909 www.actualtechmedia.com Entering the Jungle Introduction: Six Reasons You Need to Learn Linux ....................................................... 7 1. Linux is the future ........................................................................ 9 2. Linux is on everything .................................................................. 9 3. Linux is adaptable ....................................................................... 10 4. Linux has a strong community and ecosystem ........................... 10 5. -
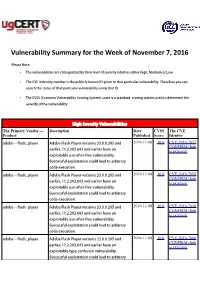
Vulnerability Summary for the Week of November 7, 2016
Vulnerability Summary for the Week of November 7, 2016 Please Note: • The vulnerabilities are cattegorized by their level of severity which is either High, Medium or Low. • The !" indentity number is the #ublicly $nown %& given to that #articular vulnerability. Therefore you can search the status of that #articular vulnerability using that %&. • The !'S (Common !ulnerability 'coring System) score is a standard scoring system used to determine the severity of the vulnerability. High Severity Vulnerabilities The Primary Vendor --- Description Date CVSS The CVE Product Published Score Identity adobe ** flash+#layer ,dobe -lash Player versions ./.0.0..01 and 2016-11-08 10.0 CVE-2016-7857 CONFIRM (link earlier, 22...20..64/ and earlier have an is external) e5#loitable use*after*free vulnerability. 'uccessful e5#loitation could lead to arbitrary code e5ecution. adobe ** flash+#layer ,dobe -lash Player versions ./.0.0..01 and 2016-11-08 10.0 CVE-2016-7858 CONFIRM (link earlier, 22...20..64/ and earlier have an is external) e5#loitable use*after*free vulnerability. 'uccessful e5#loitation could lead to arbitrary code e5ecution. adobe ** flash+#layer ,dobe -lash Player versions ./.0.0..01 and 2016-11-08 10.0 CVE-2016-7859 CONFIRM (link earlier, 22...20..64/ and earlier have an is external) e5#loitable use*after*free vulnerability. 'uccessful e5#loitation could lead to arbitrary code e5ecution. adobe ** flash+#layer ,dobe -lash Player versions ./.0.0..01 and 2016-11-08 10.0 CVE-2016-7860 CONFIRM (link earlier, 22...20..64/ and earlier have an is external) e5#loitable type confusion vulnerability. -

(NASACFZ-1S2/Ot
(NASACFZ-1s2/ot (1'AS-C-121~fPRELIMAINARY STUDY FOR A NUMERICAL AERODYNAMIC SIMULATION FACILITy. N78-19052 PHASE 1: EXTENSION Control Data Corp., St. Paul, Minn.) 434 p HC A19/MF A01 CSCL 01A Unclas G3/02 08630 PRELIMINARY STUDY FOR A NUMERICAL AERODYNAMIC SIMULATION FACILITY SUMMARY REPORT - PHASE 1 EXTENSION By: N. R. Lincoln FEBRUARY, 1978 Distribution of this report is provided in the interest of information exchang'e. Responsibility for the contents resides in the authors or organization that prepared it. Prepared under Contract No. NAS2-9457 by: CONTROL DATA CORPORATION Research and Advanced Design Laboratory 4290 Fernwood Street St. Paul, Minnesota 55112 for AMES RESEARCH CENTER NATIONAL AERONAUTICS AND SPACE ADMINISTRATION R EPVED ItA SI FACULWM SUMMARY REPORT - PHASE I EXTENSION Phase I of the NASF study which was completed in October 1977 produced several conclusions about the feasibility of construction of a flow model simulation facility. A computer structure was proposed for the Navier-Stokes Solver (NSS), now called the Flow Model Processor (FMP), along with technological and system approaches. Before such a system can enter an intensive design investigation phase several tasks must be accomplished to establish uniformity and control over the remaining design steps, as well as clarifying and amplifying certain portions of the conclusions drawn in Phase 1. In order of priority these were seen as: 1. Establishing a structure and format for documenting the design and implementation of the FMP facility. 2. Developing 'a complete, practically engineered design that would perform as claimed in the Phase 1 report. 3. Creating a design verification tool for NASA analysts, using a computerized simulation system. -

Pirate Or Hackers Bible More Like Guidelines...= a = Abbrev: /*-Breev
Pirate or Hackers Bible More like guidelines.... = A = abbrev: /*-breev'/, /*-brev'/ n. Common abbreviation for `abbreviation'. ABEND: [ABnormal END] /ah'bend/, /*-bend'/ n. Abnormal termination (of software); {crash}; {lossage}. Derives from an error message on the IBM 360; used jokingly by hackers but seriously mainly by {code grinder}s. Usually capitalized, but may appear as `abend'. Hackers will try to persuade you that ABEND is called `abend' because it is what system operators do to the machine late on Friday when they want to call it a day, and hence is from the German `Abend' = `Evening'. accumulator: n. 1. Archaic term for a register. On-line use of it as a synonym for `register' is a fairly reliable indication that the user has been around for quite a while and/or that the architecture under discussion is quite old. The term in full is almost never used of microprocessor registers, for example, though symbolic names for arithmetic registers beginning in `A' derive from historical use of the term `accumulator' (and not, actually, from `arithmetic'). Confusingly, though, an `A' register name prefix may also stand for `address', as for example on the Motorola 680x0 family. 2. A register being used for arithmetic or logic (as opposed to addressing or a loop index), especially one being used to accumulate a sum or count of many items. This use is in context of a particular routine or stretch of code. "The FOOBAZ routine uses A3 as an accumulator." 3. One's in-basket (esp. among old-timers who might use sense 1). "You want this reviewed? Sure, just put it in the accumulator." (See {stack}.) ACK: /ak/ interj. -

Computers and Apollo
COMPUTERS AND APOLLO > I. F. Grant G.R. Seymour J. H.K. Saxon O s Honeysuckle Creek Tracking Station, Canberra J \ \ r v November 25, 1970 1.1 Genera 1 The last, few days before1 a lunar mission Launch probably have a larger utilisation of' computers than any other- phase of the' mission. I'ho many fu n d i oils wi I I ha performed with increasing frequency and complexity, culminating in the vehicle liftoff from the pad, ACE (short for Automatic Checkout Equipment) is a large bank of computers situated at Cape Kennedy. This equipment is running continuous checks on all spacecraft systems, monitoring the loading of propellants and parameter trends, and performing check routines with the CMC, LGC, and LVDC, which are the computers situated in the CSM, LM, and SIVB 3rd stage of the launch vehicle. Some of A C E !s results are sent via high speed lines to Mission Control Center (MCC) at Houston, where they are processed and formatted for display by the IBM 360 computers which form the RTCC (Realtime Telemetry and Command Complex). The RTCC in turn is being used by the mission flight controllers to generate test digital command requests for transmission to the spacecraft via the Merritt Island tracking station situated at the Cape. r*\ The rest of the tracking network (l4 stations and one ship) is also being checked out by computers at MCC and Goddard Space Plight Center (GSFC) with a standard series of performance tests known as CADPISS (Computation and Data Plow Integrated Subsystems). These computers instruct the sites to perform tracking, telemetry processing, and command functions, monitor the outputs against pre-programmed standards, and inform the sites of the results. -

Jargon File, Version 4.0.0, 24 Jul 1996
JARGON FILE, VERSION 4.0.0, 24 JUL 1996 This is the Jargon File, a comprehensive compendium of hacker slang illuminating many aspects of hackish tradition, folklore, and humor. This document (the Jargon File) is in the public domain, to be freely used, shared, and modified. There are (by intention) no legal restraints on what you can do with it, but there are traditions about its proper use to which many hackers are quite strongly attached. Please extend the courtesy of proper citation when you quote the File, ideally with a version number, as it will change and grow over time. (Examples of appropriate citation form: "Jargon File 4.0.0" or "The on-line hacker Jargon File, version 4.0.0, 24 JUL 1996".) The Jargon File is a common heritage of the hacker culture. Over the years a number of individuals have volunteered considerable time to maintaining the File and been recognized by the net at large as editors of it. Editorial responsibilities include: to collate contributions and suggestions from others; to seek out corroborating information; to cross-reference related entries; to keep the file in a consistent format; and to announce and distribute updated versions periodically. Current volunteer editors include: Eric Raymond [email protected] Although there is no requirement that you do so, it is considered good form to check with an editor before quoting the File in a published work or commercial product. We may have additional information that would be helpful to you and can assist you in framing your quote to reflect not only the letter of the File but its spirit as well. -

Unsupervised Translation of Programming Languages
Unsupervised Translation of Programming Languages Marie-Anne Lachaux∗ Baptiste Roziere* Lowik Chanussot Facebook AI Research Facebook AI Research Facebook AI Research [email protected] Paris-Dauphine University [email protected] [email protected] Guillaume Lample Facebook AI Research [email protected] Abstract A transcompiler, also known as source-to-source translator, is a system that converts source code from a high-level programming language (such as C++ or Python) to another. Transcompilers are primarily used for interoperability, and to port codebases written in an obsolete or deprecated language (e.g. COBOL, Python 2) to a modern one. They typically rely on handcrafted rewrite rules, applied to the source code abstract syntax tree. Unfortunately, the resulting translations often lack readability, fail to respect the target language conventions, and require manual modifications in order to work properly. The overall translation process is time- consuming and requires expertise in both the source and target languages, making code-translation projects expensive. Although neural models significantly outper- form their rule-based counterparts in the context of natural language translation, their applications to transcompilation have been limited due to the scarcity of paral- lel data in this domain. In this paper, we propose to leverage recent approaches in unsupervised machine translation to train a fully unsupervised neural transcompiler. We train our model on source code from open source GitHub projects, and show that it can translate functions between C++, Java, and Python with high accuracy. Our method relies exclusively on monolingual source code, requires no expertise in the source or target languages, and can easily be generalized to other programming languages.