Statistical Methods in Water Resources
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
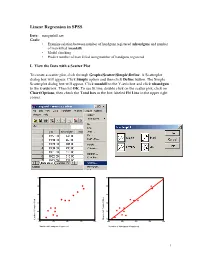
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

CONFIDENCE Vs PREDICTION INTERVALS 12/2/04 Inference for Coefficients Mean Response at X Vs
STAT 141 REGRESSION: CONFIDENCE vs PREDICTION INTERVALS 12/2/04 Inference for coefficients Mean response at x vs. New observation at x Linear Model (or Simple Linear Regression) for the population. (“Simple” means single explanatory variable, in fact we can easily add more variables ) – explanatory variable (independent var / predictor) – response (dependent var) Probability model for linear regression: 2 i ∼ N(0, σ ) independent deviations Yi = α + βxi + i, α + βxi mean response at x = xi 2 Goals: unbiased estimates of the three parameters (α, β, σ ) tests for null hypotheses: α = α0 or β = β0 C.I.’s for α, β or to predictE(Y |X = x0). (A model is our ‘stereotype’ – a simplification for summarizing the variation in data) For example if we simulate data from a temperature model of the form: 1 Y = 65 + x + , x = 1, 2,..., 30 i 3 i i i Model is exactly true, by construction An equivalent statement of the LM model: Assume xi fixed, Yi independent, and 2 Yi|xi ∼ N(µy|xi , σ ), µy|xi = α + βxi, population regression line Remark: Suppose that (Xi,Yi) are a random sample from a bivariate normal distribution with means 2 2 (µX , µY ), variances σX , σY and correlation ρ. Suppose that we condition on the observed values X = xi. Then the data (xi, yi) satisfy the LM model. Indeed, we saw last time that Y |x ∼ N(µ , σ2 ), with i y|xi y|xi 2 2 2 µy|xi = α + βxi, σY |X = (1 − ρ )σY Example: Galton’s fathers and sons: µy|x = 35 + 0.5x ; σ = 2.34 (in inches). -

Choosing a Coverage Probability for Prediction Intervals
Choosing a Coverage Probability for Prediction Intervals Joshua LANDON and Nozer D. SINGPURWALLA We start by noting that inherent to the above techniques is an underlying distribution (or error) theory, whose net effect Coverage probabilities for prediction intervals are germane to is to produce predictions with an uncertainty bound; the nor- filtering, forecasting, previsions, regression, and time series mal (Gaussian) distribution is typical. An exception is Gard- analysis. It is a common practice to choose the coverage proba- ner (1988), who used a Chebychev inequality in lieu of a spe- bilities for such intervals by convention or by astute judgment. cific distribution. The result was a prediction interval whose We argue here that coverage probabilities can be chosen by de- width depends on a coverage probability; see, for example, Box cision theoretic considerations. But to do so, we need to spec- and Jenkins (1976, p. 254), or Chatfield (1993). It has been a ify meaningful utility functions. Some stylized choices of such common practice to specify coverage probabilities by conven- functions are given, and a prototype approach is presented. tion, the 90%, the 95%, and the 99% being typical choices. In- deed Granger (1996) stated that academic writers concentrate KEY WORDS: Confidence intervals; Decision making; Filter- almost exclusively on 95% intervals, whereas practical fore- ing; Forecasting; Previsions; Time series; Utilities. casters seem to prefer 50% intervals. The larger the coverage probability, the wider the prediction interval, and vice versa. But wide prediction intervals tend to be of little value [see Granger (1996), who claimed 95% prediction intervals to be “embarass- 1. -

STATS 305 Notes1
STATS 305 Notes1 Art Owen2 Autumn 2013 1The class notes were beautifully scribed by Eric Min. He has kindly allowed his notes to be placed online for stat 305 students. Reading these at leasure, you will spot a few errors and omissions due to the hurried nature of scribing and probably my handwriting too. Reading them ahead of class will help you understand the material as the class proceeds. 2Department of Statistics, Stanford University. 0.0: Chapter 0: 2 Contents 1 Overview 9 1.1 The Math of Applied Statistics . .9 1.2 The Linear Model . .9 1.2.1 Other Extensions . 10 1.3 Linearity . 10 1.4 Beyond Simple Linearity . 11 1.4.1 Polynomial Regression . 12 1.4.2 Two Groups . 12 1.4.3 k Groups . 13 1.4.4 Different Slopes . 13 1.4.5 Two-Phase Regression . 14 1.4.6 Periodic Functions . 14 1.4.7 Haar Wavelets . 15 1.4.8 Multiphase Regression . 15 1.5 Concluding Remarks . 16 2 Setting Up the Linear Model 17 2.1 Linear Model Notation . 17 2.2 Two Potential Models . 18 2.2.1 Regression Model . 18 2.2.2 Correlation Model . 18 2.3 TheLinear Model . 18 2.4 Math Review . 19 2.4.1 Quadratic Forms . 20 3 The Normal Distribution 23 3.1 Friends of N (0; 1)...................................... 23 3.1.1 χ2 .......................................... 23 3.1.2 t-distribution . 23 3.1.3 F -distribution . 24 3.2 The Multivariate Normal . 24 3.2.1 Linear Transformations . 25 3.2.2 Normal Quadratic Forms . -

Inference in Normal Regression Model
Inference in Normal Regression Model Dr. Frank Wood Remember I We know that the point estimator of b1 is P(X − X¯ )(Y − Y¯ ) b = i i 1 P 2 (Xi − X¯ ) I Last class we derived the sampling distribution of b1, it being 2 N(β1; Var(b1))(when σ known) with σ2 Var(b ) = σ2fb g = 1 1 P 2 (Xi − X¯ ) I And we suggested that an estimate of Var(b1) could be arrived at by substituting the MSE for σ2 when σ2 is unknown. MSE SSE s2fb g = = n−2 1 P 2 P 2 (Xi − X¯ ) (Xi − X¯ ) Sampling Distribution of (b1 − β1)=sfb1g I Since b1 is normally distribute, (b1 − β1)/σfb1g is a standard normal variable N(0; 1) I We don't know Var(b1) so it must be estimated from data. 2 We have already denoted it's estimate s fb1g I Using this estimate we it can be shown that b − β 1 1 ∼ t(n − 2) sfb1g where q 2 sfb1g = s fb1g It is from this fact that our confidence intervals and tests will derive. Where does this come from? I We need to rely upon (but will not derive) the following theorem For the normal error regression model SSE P(Y − Y^ )2 = i i ∼ χ2(n − 2) σ2 σ2 and is independent of b0 and b1. I Here there are two linear constraints P ¯ ¯ ¯ (Xi − X )(Yi − Y ) X Xi − X b1 = = ki Yi ; ki = P(X − X¯ )2 P (X − X¯ )2 i i i i b0 = Y¯ − b1X¯ imposed by the regression parameter estimation that each reduce the number of degrees of freedom by one (total two). -

Sieve Bootstrap-Based Prediction Intervals for Garch Processes
SIEVE BOOTSTRAP-BASED PREDICTION INTERVALS FOR GARCH PROCESSES by Garrett Tresch A capstone project submitted in partial fulfillment of graduating from the Academic Honors Program at Ashland University April 2015 Faculty Mentor: Dr. Maduka Rupasinghe, Assistant Professor of Mathematics Additional Reader: Dr. Christopher Swanson, Professor of Mathematics ABSTRACT Time Series deals with observing a variable—interest rates, exchange rates, rainfall, etc.—at regular intervals of time. The main objectives of Time Series analysis are to understand the underlying processes and effects of external variables in order to predict future values. Time Series methodologies have wide applications in the fields of business where mathematics is necessary. The Generalized Autoregressive Conditional Heteroscedasic (GARCH) models are extensively used in finance and econometrics to model empirical time series in which the current variation, known as volatility, of an observation is depending upon the past observations and past variations. Various drawbacks of the existing methods for obtaining prediction intervals include: the assumption that the orders associated with the GARCH process are known; and the heavy computational time involved in fitting numerous GARCH processes. This paper proposes a novel and computationally efficient method for the creation of future prediction intervals using the Sieve Bootstrap, a promising resampling procedure for Autoregressive Moving Average (ARMA) processes. This bootstrapping technique remains efficient when computing future prediction intervals for the returns as well as the volatilities of GARCH processes and avoids extensive computation and parameter estimation. Both the included Monte Carlo simulation study and the exchange rate application demonstrate that the proposed method works very well under normal distributed errors. -

On Small Area Prediction Interval Problems
ASA Section on Survey Research Methods On Small Area Prediction Interval Problems Snigdhansu Chatterjee, Parthasarathi Lahiri, Huilin Li University of Minnesota, University of Maryland, University of Maryland Abstract In the small area context, prediction intervals are often pro- √ duced using the standard EBLUP ± zα/2 mspe rule, where Empirical best linear unbiased prediction (EBLUP) method mspe is an estimate of the true MSP E of the EBLUP and uses a linear mixed model in combining information from dif- zα/2 is the upper 100(1 − α/2) point of the standard normal ferent sources of information. This method is particularly use- distribution. These prediction intervals are asymptotically cor- ful in small area problems. The variability of an EBLUP is rect, in the sense that the coverage probability converges to measured by the mean squared prediction error (MSPE), and 1 − α for large sample size n. However, they are not efficient interval estimates are generally constructed using estimates of in the sense they have either under-coverage or over-coverage the MSPE. Such methods have shortcomings like undercover- problem for small n, depending on the particular choice of age, excessive length and lack of interpretability. We propose the MSPE estimator. In statistical terms, the coverage error a resampling driven approach, and obtain coverage accuracy of such interval is of the order O(n−1), which is not accu- of O(d3n−3/2), where d is the number of parameters and n rate enough for most applications of small area studies, many the number of observations. Simulation results demonstrate of which involve small n. -

Statistical Analysis in JASP
Copyright © 2018 by Mark A Goss-Sampson. All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the author except for the purposes of research, education or private study. CONTENTS PREFACE .................................................................................................................................................. 1 USING THE JASP INTERFACE .................................................................................................................... 2 DESCRIPTIVE STATISTICS ......................................................................................................................... 8 EXPLORING DATA INTEGRITY ................................................................................................................ 15 ONE SAMPLE T-TEST ............................................................................................................................. 22 BINOMIAL TEST ..................................................................................................................................... 25 MULTINOMIAL TEST .............................................................................................................................. 28 CHI-SQUARE ‘GOODNESS-OF-FIT’ TEST............................................................................................. 30 MULTINOMIAL AND Χ2 ‘GOODNESS-OF-FIT’ TEST. .......................................................................... -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed. -

Testing Normality: a GMM Approach Christian Bontempsa and Nour
Testing Normality: A GMM Approach Christian Bontempsa and Nour Meddahib∗ a LEEA-CENA, 7 avenue Edouard Belin, 31055 Toulouse Cedex, France. b D´epartement de sciences ´economiques, CIRANO, CIREQ, Universit´ede Montr´eal, C.P. 6128, succursale Centre-ville, Montr´eal (Qu´ebec), H3C 3J7, Canada. First version: March 2001 This version: June 2003 Abstract In this paper, we consider testing marginal normal distributional assumptions. More precisely, we propose tests based on moment conditions implied by normality. These moment conditions are known as the Stein (1972) equations. They coincide with the first class of moment conditions derived by Hansen and Scheinkman (1995) when the random variable of interest is a scalar diffusion. Among other examples, Stein equation implies that the mean of Hermite polynomials is zero. The GMM approach we adopt is well suited for two reasons. It allows us to study in detail the parameter uncertainty problem, i.e., when the tests depend on unknown parameters that have to be estimated. In particular, we characterize the moment conditions that are robust against parameter uncertainty and show that Hermite polynomials are special examples. This is the main contribution of the paper. The second reason for using GMM is that our tests are also valid for time series. In this case, we adopt a Heteroskedastic-Autocorrelation-Consistent approach to estimate the weighting matrix when the dependence of the data is unspecified. We also make a theoretical comparison of our tests with Jarque and Bera (1980) and OPG regression tests of Davidson and MacKinnon (1993). Finite sample properties of our tests are derived through a comprehensive Monte Carlo study. -

Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests
Journal ofStatistical Modeling and Analytics Vol.2 No.I, 21-33, 2011 Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests Nornadiah Mohd Razali1 Yap Bee Wah 1 1Faculty ofComputer and Mathematica/ Sciences, Universiti Teknologi MARA, 40450 Shah Alam, Selangor, Malaysia E-mail: nornadiah@tmsk. uitm. edu.my, yapbeewah@salam. uitm. edu.my ABSTRACT The importance of normal distribution is undeniable since it is an underlying assumption of many statistical procedures such as I-tests, linear regression analysis, discriminant analysis and Analysis of Variance (ANOVA). When the normality assumption is violated, interpretation and inferences may not be reliable or valid. The three common procedures in assessing whether a random sample of independent observations of size n come from a population with a normal distribution are: graphical methods (histograms, boxplots, Q-Q-plots), numerical methods (skewness and kurtosis indices) and formal normality tests. This paper* compares the power offour formal tests of normality: Shapiro-Wilk (SW) test, Kolmogorov-Smirnov (KS) test, Lillie/ors (LF) test and Anderson-Darling (AD) test. Power comparisons of these four tests were obtained via Monte Carlo simulation of sample data generated from alternative distributions that follow symmetric and asymmetric distributions. Ten thousand samples ofvarious sample size were generated from each of the given alternative symmetric and asymmetric distributions. The power of each test was then obtained by comparing the test of normality statistics with the respective critical values. Results show that Shapiro-Wilk test is the most powerful normality test, followed by Anderson-Darling test, Lillie/ors test and Kolmogorov-Smirnov test. However, the power ofall four tests is still low for small sample size. -

A Quantitative Validation Method of Kriging Metamodel for Injection Mechanism Based on Bayesian Statistical Inference
metals Article A Quantitative Validation Method of Kriging Metamodel for Injection Mechanism Based on Bayesian Statistical Inference Dongdong You 1,2,3,* , Xiaocheng Shen 1,3, Yanghui Zhu 1,3, Jianxin Deng 2,* and Fenglei Li 1,3 1 National Engineering Research Center of Near-Net-Shape Forming for Metallic Materials, South China University of Technology, Guangzhou 510640, China; [email protected] (X.S.); [email protected] (Y.Z.); fl[email protected] (F.L.) 2 Guangxi Key Lab of Manufacturing System and Advanced Manufacturing Technology, Guangxi University, Nanning 530003, China 3 Guangdong Key Laboratory for Advanced Metallic Materials processing, South China University of Technology, Guangzhou 510640, China * Correspondence: [email protected] (D.Y.); [email protected] (J.D.); Tel.: +86-20-8711-2933 (D.Y.); +86-137-0788-9023 (J.D.) Received: 2 April 2019; Accepted: 24 April 2019; Published: 27 April 2019 Abstract: A Bayesian framework-based approach is proposed for the quantitative validation and calibration of the kriging metamodel established by simulation and experimental training samples of the injection mechanism in squeeze casting. The temperature data uncertainty and non-normal distribution are considered in the approach. The normality of the sample data is tested by the Anderson–Darling method. The test results show that the original difference data require transformation for Bayesian testing due to the non-normal distribution. The Box–Cox method is employed for the non-normal transformation. The hypothesis test results of the calibrated kriging model are more reliable after data transformation. The reliability of the kriging metamodel is quantitatively assessed by the calculated Bayes factor and confidence.