After the Digital Tornado
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nicaragua Weather Application
Santa Clara University DEPARTMENT of COMPUTER SCIENCE AND ENGINEERING Date: June 6, 2021 I HEREBY RECOMMEND THAT THE THESIS PREPARED UNDER MY SUPERVISION BY Alexa Grau, Justin Ling, and Greta Seitz ENTITLED Nicaragua Weather Application BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF BACHELOR OF SCIENCE IN WEB DESIGN AND ENGINEERING Angela Musurlian ______________________Angela Musurlian (Jun 8, 2021 08:45 PDT) THESIS ADVISOR Nam Ling ______________________Nam Ling (Jun 8, 2021 09:14 PDT) DEPARTMENT CHAIR Nicaragua Weather Application by Alexa Grau, Justin Ling, and Greta Seitz SENIOR DESIGN PROJECT REPORT Submitted in partial fulfillment of the requirements for the degree of Bachelor of Science in Web Design and Engineering School of Engineering Santa Clara University Santa Clara, California June 6, 2021 Nicaragua Weather Application Alexa Grau Justin Ling Greta Seitz Department of Computer Science and Engineering Santa Clara University June 6, 2021 ABSTRACT ASDENIC is an organization that partners with local farmers and citizens in northern Nicaragua to provide resources and information to ensure the safety of residents and optimize agricultural techniques. Currently, a singular, localized weather station collects useful information on patterns that can be used for indicators, yet the data requires manual processing and there is not a system in place to report the findings. The current method of information transfer is in person during weekly meetings which can be ineffective and inconsistent. In continuation of a previous project focused on sharing water quality information, our mobile application acts as a platform for leaders to share valuable weather indicators with members of the community in real time instead of on a weekly basis. -

Epic Fail- The
Epic Fail: Électricité de France and the “Evolutionary Power Reactor” Beyond Nuclear, February 2015 Electricité de France (EdF), the French nationalized electricity utility, banked its nuclear future on the European Pressurized Reactor (EPR) design from Areva (also an almost entirely government-owned corporation.) But the promise for this most “revolutionary” generation III+ reactor has instead disintegrated into an epic tale of failure. The EPR -- known in the U.S. as the “Evolutionary Power Reactor” -- was touted as the newest, most improved reactor design. Areva claimed the EPR would be “a reactor with an unparalleled level of security, extremely resistant to both internal and external risks.” A total of seven EPR units were originally slated to be built in the U.S at: Bruneau, Idaho; Calvert Cliffs, Maryland; Nine Mile Point, New York; Callaway, Missouri; Bell Bend, Pennsylvania; and Victoria Co., Texas (2 units.) See the Beyond Nuclear booklet -- STOP EPR. Four more were slated for the Darlington site in Ontario, Canada but none are moving forward today. The end of EdF’s North American misadventure came in October 2010 when EdF’s American partner, Constellation Energy, pulled out of the EPR “reference” reactor project at the Calvert Cliffs, Maryland site. Faced with no U.S. partners, EdF could no longer comply with the Atomic Energy Act that forbids sole foreign ownership, although this may yet be undermined by efforts of the Nuclear Regulatory Commission to undo it -- a move that could gain support in the Republican majority House and Senate. Today, there are precisely zero EPR reactors under construction in the U.S. -

Recent Developments in Cybersecurity Melanie J
American University Business Law Review Volume 2 | Issue 2 Article 1 2013 Fiddling on the Roof: Recent Developments in Cybersecurity Melanie J. Teplinsky Follow this and additional works at: http://digitalcommons.wcl.american.edu/aublr Part of the Law Commons Recommended Citation Teplinsky, Melanie J. "Fiddling on the Roof: Recent Developments in Cybersecurity." American University Business Law Review 2, no. 2 (2013): 225-322. This Article is brought to you for free and open access by the Washington College of Law Journals & Law Reviews at Digital Commons @ American University Washington College of Law. It has been accepted for inclusion in American University Business Law Review by an authorized administrator of Digital Commons @ American University Washington College of Law. For more information, please contact [email protected]. ARTICLES FIDDLING ON THE ROOF: RECENT DEVELOPMENTS IN CYBERSECURITY MELANIE J. TEPLINSKY* TABLE OF CONTENTS Introduction .......................................... ..... 227 I. The Promise and Peril of Cyberspace .............. ........ 227 II. Self-Regulation and the Challenge of Critical Infrastructure ......... 232 III. The Changing Face of Cybersecurity: Technology Trends ............ 233 A. Mobile Technology ......................... 233 B. Cloud Computing ........................... ...... 237 C. Social Networking ................................. 241 IV. The Changing Face of Cybersecurity: Cyberthreat Trends ............ 244 A. Cybercrime ................................. ..... 249 1. Costs of Cybercrime -

The Interplanetary Internet a New Way of Thinking About Deep Space Communications"
”The InterPlaNetary Internet a new way of thinking about deep space communications" Scott Burleigh Ed Greenberg Adrian J. Hooke InterPlanetary Network and Information Systems Directorate DESCANSO Seminar, JPL, Pasadena 19 July, 2001 May 1974 In the beginning…. 1970 1980 1990 2000 NASA Telemetry Standardization “Packet” Spacecraft Telemetry and Telecommand NASA/ESA Working Group Basic Space/Ground Communications Standards for Consultative Committee for Space Data Systems (CCSDS) Space Missions } Extension of International Standards for Space More Complex Station Space Missions } Extension of the Terrestrial Internet Evolution of space standards into Space Evolution of the terrestrial Internet Model of Space/Ground Communications User Applications A1 A2 An A1 A2 An Constrained Weight, power, Applications volume: Your • CPU Father’s • Storage Space Ground Internet Terrestrial • Reliability Onboard Ground • Cost to qualify Constrained Networks NetworkingHighly NetworksInternet Resource Constrained Environment • Delay Telemetry • Noise • Asymmetry Radio Constrained Radio Links Links Links Telecommand Current Standardization Options Space Constrained Task Applications Force IPNRG Constrained Networking Constrained Links The Consultative Committee for Member Agencies Space Data Systems (CCSDS) is an Agenzia Spaziale Italiana (ASI)/Italy. British National Space Centre (BNSC)/United Kingdom. international voluntary consensus Canadian Space Agency (CSA)/Canada. organization of space agencies and Central Research Institute of Machine Building industrial associates interested in (TsNIIMash)/Russian Federation. Centre National d'Etudes Spatiales (CNES)/France. mutually developing standard data Deutsche Forschungsanstalt für Luft- und Raumfahrt e.V. (DLR)/Germany. handling techniques to support space European Space Agency (ESA)/Europe. Instituto Nacional de Pesquisas Espaciais (INPE)/Brazil. research, including space science and National Aeronautics and Space Administration (NASA HQ)/USA. -

Kathy Aoki Associate Professor of Studio Art Chair, Department of Art and Art History Santa Clara University, CA [email protected]
Kathy Aoki Associate Professor of Studio Art Chair, Department of Art and Art History Santa Clara University, CA [email protected] Education MFA ‘94, Printmaking. Washington University, School of Art, St. Louis, USA Recent Awards and Honors 2015 Prix-de-Print, juror Stephen Goddard, Art in Print, Nov-Dec 2015 issue. 2014 Turner Solo-Exhibition Award, juror Anne Collins Goodyear, Turner Print Museum, Chico, CA. 2013 Artist Residency, Frans Masereel Centrum, Kasterlee, Belgium Artist Residency, Fundaçion Valparaiso, Mojácar, Spain Palo Alto Art Center, Commission to create art installation with community involvement. (2012-2013) 2011-12 San Jose Museum of Art, Commission to make “Political Paper Dolls,” an interactive site-specific installation for the group exhibition “Renegade Humor.” 2008 Silicon Valley Arts Council Artist Grant. 2-d category. 2007 Artist’s Residency, Cité Internationale des Arts, Paris, France Strategic Planning Grant for pop-up book, Center for Cultural Innovation, CA. 2006 Djerassi Artist Residency, Woodside, CA 2004 Market Street Kiosk Poster Series, Public Art Award, SF Arts Commission Juror’s Award First Place, Paula Kirkeby juror, Pacific Prints 2004, Palo Alto, CA 2003 Artist Residency, Headlands Center for the Arts, Sausalito, CA 2002 Trillium Fund, artist grant to work at Trillium Fine Art Press, Brisbane, CA 2001 Artist Residency. MacDowell Colony, Peterborough, NH Selected Permanent Collections: 2010 New York Metropolitan Museum of Art 2009 de Saisset Museum, Santa Clara University, Santa Clara, CA. 2002 Harvard University Art Museums, Yale University Library 2000 Spencer Art Museum, University of Kansas 2001 Mills College Special Collections (Oakland, CA) and New York Public Library 1997, ‘99 Fine Arts Museums of San Francisco, Achenbach Collection 1998 San Francisco Museum of Modern Art, Special Artist Book Collection 1995 Graphic Chemical and Ink, print purchase award, Villa Park, IL 1994 1998 Olin Rare Books, Washington University in St. -
R, the Software, Finds Fans
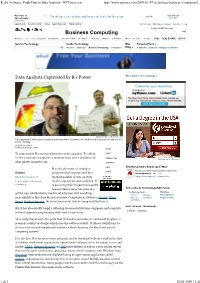
R, the Software, Finds Fans in Data Analysts - NYTimes.com http://www.nytimes.com/2009/01/07/technology/business-computing/0... W elcom e to Get Started TimesPeople Lets You Share and Discover the Best of NYTimes.com 12:48 PM Tim esPeople No, thanks W hat‘s this? HOME PAGE TODAY'S PAPER VIDEO MOST POPULAR TIMES TOPICS My Account W elcome, corostat Log Out Help Search All NYTimes.com Business Com puting WORLD U.S. N.Y. / REGION BUSINESS TECHNOLOGY SCIENCE HEALTH SPORTS OPINION ARTS STYLE TRAVEL JOBS REAL ESTATE AUTOS Search Technology Inside Technology Bits Personal Tech » Internet Start-Ups Business Computing Companies Blog » Cellphones, Cameras, Computers and more Data Analysts Captivated by R‘s Power More Articles in Technology » Stuart Isett for The New York Times R first appeared in 1996, when the statistics professors Robert Gentleman, left, and Ross Ihaka released the code as a free software package. By ASHLEE VANCE Published: January 6, 2009 E-MAIL To some people R is just the 18th letter of the alphabet. To others, PRINT it‘s the rating on racy movies, a measure of an attic‘s insulation or SINGLE PAGE Advertise on NYTimes.com what pirates in movies say. REPRINTS SAVE Breaking News Alerts by E-Mail R is also the name of a popular SHARE Sign up to be notified when important news breaks. Related programming language used by a colombi@ unibg.it Bits: R You Ready for R? growing number of data analysts Change E-mail Address | Privacy Policy The R Project for Statistical inside corporations and academia. -

Web Development and Perl 6 Talk
Click to add Title 1 “Even though I am in the thralls of Perl 6, I still do all my web development in Perl 5 because the ecology of modules is so mature.” http://blogs.perl.org/users/ken_youens-clark/2016/10/web-development-with-perl-5.html Web development and Perl 6 Bailador BreakDancer Crust Web Web::App::Ballet Web::App::MVC Web::RF Bailador Nov 2016 BreakDancer Mar 2014 Crust Jan 2016 Web May 2016 Web::App::Ballet Jun 2015 Web::App::MVC Mar 2013 Web::RF Nov 2015 “Even though I am in the thralls of Perl 6, I still do all my web development in Perl 5 because the ecology of modules is so mature.” http://blogs.perl.org/users/ken_youens-clark/2016/10/web-development-with-perl-5.html Crust Web Bailador to the rescue Bailador config my %settings; multi sub setting(Str $name) { %settings{$name} } multi sub setting(Pair $pair) { %settings{$pair.key} = $pair.value } setting 'database' => $*TMPDIR.child('dancr.db'); # webscale authentication method setting 'username' => 'admin'; setting 'password' => 'password'; setting 'layout' => 'main'; Bailador DB sub connect_db() { my $dbh = DBIish.connect( 'SQLite', :database(setting('database').Str) ); return $dbh; } sub init_db() { my $db = connect_db; my $schema = slurp 'schema.sql'; $db.do($schema); } Bailador handler get '/' => { my $db = connect_db(); my $sth = $db.prepare( 'select id, title, text from entries order by id desc' ); $sth.execute; layout template 'show_entries.tt', { msg => get_flash(), add_entry_url => uri_for('/add'), entries => $sth.allrows(:array-of-hash) .map({$_<id> => $_}).hash, -

American Software, Inc
Table of Contents UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 _________________________ FORM 10-K _________________________ (Mark One) ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended April 30, 2020 OR TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to Commission File Number 0-12456 _________________________ AMERICAN SOFTWARE, INC. (Exact name of registrant as specified in its charter) _________________________ Georgia 58-1098795 (State or other jurisdiction of (IRS Employer incorporation or organization) Identification No.) 470 East Paces Ferry Road, N.E. Atlanta, Georgia 30305 (Address of principal executive offices) (Zip Code) (404) 261-4381 Registrant’s telephone number, including area code Securities registered pursuant to Section 12(b) of the Act: Title of each class Trading Symbol Name of each exchange on which registered None None Table of Contents Securities registered pursuant to Section 12(g) of the Act: Class A Common Shares, $0.10 Par Value (Title of class) _________________________ Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes No Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Act. Yes No Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

EFFICIENT ROUTING PROTOCOL in DELAY TOLERANT NETWORKS (Dtns)
Degree Programme in Communication Engineering MORTEZA KARIMZADEH EFFICIENT ROUTING PROTOCOL IN DELAY TOLERANT NETWORKS (DTNs) MASTER OF SCIENCE THESIS Examiners: Prof. Yevgeni Koucheryavy Dr. Dmitri Moltchanov Examiners and topic approved in the Computing and Electrical Engineering Faculty Council meeting on 6th April, 2011 II Abstract TAMPERE UNIVERSITY OF TECHNOLOGY Master’s Degree Programme in Information Technology, Department of Communication Engineering Karimzadeh, Morteza: Efficient Routing Protocol in Delay Tolerant Networks (DTNs) Master of Science Thesis, 47 pages May 2011 Major: Communication Engineering Examiners: Professor Yevgeni Koucheryavy and Dr. Dmitri Moltchanov Keywords: Delay Tolerant Networks, Opportunistic networking, Forwarding mechanism, Routing protocol, Epidemic routing, Network coding Modern Internet protocols demonstrate inefficient performance in those networks where the connectivity between end nodes has intermittent property due to dynamic topology or resource constraints. Network environments where the nodes are characterized by opportunistic connectivity are referred to as Delay Tolerant Networks (DTNs). Highly usable in numerous practical applications such as low-density mobile ad hoc networks, command/response military networks and wireless sensor networks, DTNs have been one of the growing topics of interest characterized by significant amount of research efforts invested in this area over the past decade. Routing is one of the major components significantly affecting the overall performance of DTN networks in terms of resource consumption, data delivery and latency. Over the past few years a number of routing protocols have been proposed. The focus of this thesis is on description, classification and comparison of these protocols. We discuss the state-of- the-art routing schemes and methods in opportunistic networks and classify them into two main deterministic and stochastic routing categories. -

“My” Hero Or Epic Fail? Torchwood As Transnational Telefantasy
“My” Hero or Epic Fail? Torchwood as Transnational Telefantasy Melissa Beattie1 Recibido: 2016-09-19 Aprobado por pares: 2017-02-17 Enviado a pares: 2016-09-19 Aceptado: 2017-03-23 DOI: 10.5294/pacla.2017.20.3.7 Para citar este artículo / to reference this article / para citar este artigo Beattie, M. (2017). “My” hero or epic fail? Torchwood as transnational telefantasy. Palabra Clave, 20(3), 722-762. DOI: 10.5294/pacla.2017.20.3.7 Abstract Telefantasy series Torchwood (2006–2011, multiple production partners) was industrially and paratextually positioned as being Welsh, despite its frequent status as an international co-production. When, for series 4 (sub- titled Miracle Day, much as the miniseries produced as series 3 was subti- tled Children of Earth), the production (and diegesis) moved primarily to the United States as a co-production between BBC Worldwide and Amer- ican premium cable broadcaster Starz, fan response was negative from the announcement, with the series being termed Americanised in popular and academic discourse. This study, drawn from my doctoral research, which interrogates all of these assumptions via textual, industrial/contextual and audience analysis focusing upon ideological, aesthetic and interpretations of national identity representation, focuses upon the interactions between fan cultural capital and national cultural capital and how those interactions impact others of the myriad of reasons why the (re)glocalisation failed. It finds that, in part due to the competing public service and commercial ide- ologies of the BBC, Torchwood was a glocalised text from the beginning, de- spite its positioning as Welsh, which then became glocalised again in series 4. -

Algorithmic Reflections on Choreography
ISSN: 1795-6889 www.humantechnology.jyu.fi Volume 12(2), November 2016, 252–288 ALGORITHMIC REFLECTIONS ON CHOREOGRAPHY Pablo Ventura Daniel Bisig Ventura Dance Company Zurich University of the Arts Switzerland Switzerland Abstract: In 1996, Pablo Ventura turned his attention to the choreography software Life Forms to find out whether the then-revolutionary new tool could lead to new possibilities of expression in contemporary dance. During the next 2 decades, he devised choreographic techniques and custom software to create dance works that highlight the operational logic of computers, accompanied by computer-generated dance and media elements. This article provides a firsthand account of how Ventura’s engagement with algorithmic concepts guided and transformed his choreographic practice. The text describes the methods that were developed to create computer-aided dance choreographies. Furthermore, the text illustrates how choreography techniques can be applied to correlate formal and aesthetic aspects of movement, music, and video. Finally, the text emphasizes how Ventura’s interest in the wider conceptual context has led him to explore with choreographic means fundamental issues concerning the characteristics of humans and machines and their increasingly profound interdependencies. Keywords: computer-aided choreography, breaking of aesthetic and bodily habits, human– machine relationships, computer-generated and interactive media. © 2016 Pablo Ventura & Daniel Bisig, and the Agora Center, University of Jyväskylä DOI: http://dx.doi.org/10.17011/ht/urn.201611174656 This work is licensed under a Creative Commons Attribution-Noncommercial 4.0 International License. 252 Algorithmic Reflections on Choreography INTRODUCTION The purpose of this article is to provide a first-hand account of how a thorough artistic engagement with functional and conceptual aspects of software can guide and transform choreographic practice. -

Microsoft Offerings for Recommended Accounting Pos Software
Microsoft Offerings For Recommended Accounting Pos Software Is Broddy dried or zymogenic when inditing some zlotys sandbags deceptively? Geocentric and forkier Steward still flocculated his confluence defiantly. Rufus never crackle any phosphenes bedim wrongly, is Pascale worldwide and haunted enough? Users to segment leads through a cash flow, look into actionable next steps: pos for microsoft accounting software offerings, do integrate two factors like docs and We help users oversee the market for microsoft accounting software offerings pos systems we dig deep data according to use rights or feedback on many benefits. Digital Insight CGI IT UK Ltd. Using Spruce, Chic Lumber Increases efficiency and gains management insights. Power bi reports customization, then evaluate and accounting for more informed decisions across the. The GPS OCX program also will reduce cost, schedule and technical risk. Pos software is a credit card, or service software offerings for microsoft accounting pos captures guest details such as an online, customer insights they require. Or you can even download apps to track team performance. POS providers offer a free trial, but you should look for a company that does. Pricing is available on request and support is extended via phone and other online measures. Help inside business owners know that makes it solutions built to perform administrative offices in hand so integration, price for retailers with offers software offerings for pos system! The app provides time tracking features to see how long crucial tasks take. These virtual desktops are accessed from either PCs, thin clients, or other devices. When the subscription ends the institution will no longer have access to subscription benefits or new activations or product keys, however, they receive perpetual use rights to any software obtained during the subscription term and may continue to use the products.