An Overview of Matchmoving Using Structure from Motion Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
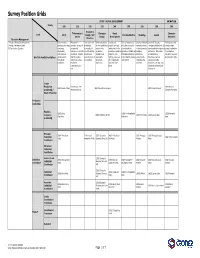
2020 Croner Animation Position Grids.Xlsx
Survey Position Grids STORY / VISUAL DEVELOPMENT ANIMATION Family 200 210 220 230 240 250 260 280 300 Production TV Animation / Character Visual Character Level Story Design / Art Pre-Visualization Modeling Layout Shorts Design Development Animation Direction Executive Management 12 Head of Production Management Generates and Manages the Creates the look Creates characters Creates and Creates sequences of Creates, builds and Creates 3D layouts. Defines, leads and 14 Head of Animation Studio develops story ideas, animation process of and artistic to meet established presents concepts shots that convey the maintains models Translates sketches into 3D executes major 16 Top Creative Executive sequences, an animated deliverables to vision for the and designs for the story through the of story elements, layouts and shot sequences character animation storyboards, television or short film meet the artistic, production, production, including application of traditional including and scenes. May create for productions, elements and production, ensuring creative and including look, character, sets, filmmaking principles in characters, sets and scenes. including personality Brief Job Family Descriptions enhancements that the creative aesthetic vision of personality, lighting, props, key a 3D computer graphics environments, Determines camera and animation style. throughout desires, as well as a production. movement, art. Creates plan environment. elements, sets, placement, blocks production. production expression. views and blue structures. characters, -

A Process of Seamlessly Replacing Cg Elements Into Live-Action Footage
1st Annual International Interdisciplinary Conference, AIIC 2013, 24-26 April, Azores, Portugal - Proceedings- A PROCESS OF SEAMLESSLY REPLACING CG ELEMENTS INTO LIVE-ACTION FOOTAGE Jin Zhi Duncan of Jordanstone College of Art & Design, United Kingdom Abstract: This research focused on inserting a computer-generated element into live-action footage and replacing unwanted existing objects in the footage. In addition, creating a realistic and seamless visual representation in the field of digital compositing. The purpose of this paper is to cover a detailed working process of digital compositing in order to clarify the production process and provide a clear idea for those entry-level artists to improve an overall understanding of the digital compositing and visual effects and hopefully inspire further collaboration and participants particularly between academia and industry. Key Words: Digital compositing, CG elements, Realistic, Visual effects Introduction Along with the increase of digital compositing in feature films, the role of digital compositors has become of unprecedented importance. Compositors thus sit at the core of most image manipulation pipelines. In order to meet the needs of the visual effects industry, universities, art and film schools have established relevant professional courses in recent years. Nevertheless, current educational concepts still need to promote a sound scientific understanding in order to steer entry- level visual effects artists in the right direction. This study has addressed several main factors from the perspective of theory and practice. As a general discussion, the research briefly outlines the historical perspectives of digital compositing, and continues to investigate the current situation of the digital compositing and visual effects industry. -

New Mode of Cinema V1n1
New Mode of Cinema: How Digital Technologies are Changing Aesthetics and Style Kristen M. Daly, Columbia University, New York Abstract This article delves intrinsically into how the characteristics of digital cinema, its equipment, software and processes, differ from film and therefore afford new aesthetic and stylistic modes, changing the nature of mise-en-scène and the language of cinema as it has been defined in the past. Innovative filmmakers are exploring new aesthetic and stylistic possibilities as the encumbrances of film, which delimited a certain mode of cinema, are released. The article makes the case that the camera as part of a computer system has enabled a more cooperative relationship with the filmmaker going beyond Alexandre Astruc’s prediction of the camera-pen (camére-stylo) to become a camera-computer. The technology of digital cinema makes the natural indexicality of film and the cut simply options amongst others and permits new forms of visual aesthetics not premised on filmic norms, but based on other familiar audiovisual forms like video games and computer interface. Voir le résumé français à la fin de l’article ***** “We see in them, if you like, something of the prophetic. That’s why I am talking about avant-garde. There is always an avant-garde when something new takes place . .” (Astruc, 1948, 17) In this article, I will examine some of the material qualities and characteristics of the equipment, software and processes of digital cinema production and propose how these afford a new aesthetics and style for cinema. Of course, many styles are available, including the status quo. -

3D Compositing and Visual Effects ITP 360X (3 Units)
3D Compositing and Visual Effects ITP 360x (3 Units) Fall 2010 Objective Advanced techniques for 3D animation and visual effects development; including 3D pre-visualization, match moving, dynamics, multi-pass rendering, and digital compositing. Concepts Camera and advanced photographic applications for 3D including: Camera tracking and match moving, high dynamic range image making, image based lighting, and global illumination. Advanced materials, lighting, and rendering techniques. Multi-pass rendering and node based compositing. Film, video, and chroma-keying for 3D. Pre-visualization and pipeline planning techniques. 3D asset creation, photorealistic texturing, and asset management. Color correction, optical effects, and advanced compositing. In addition to a series of weekly assignments, students will apply their knowledge to a final capstone project. Prerequisites ITP 215x Instructor Lance S. Winkel Contacting the E-mail: [email protected] Instructor Tel: 213.740.9956 Office Hours Varies by semester Lab Assistants TBA Class Meeting 3 hours / week. Lecture and hands on lab combined. Course The course material will be structured around a series of projects. Structure Each project will extend over several weeks with assignments / progress checks due each week. See the Grading criteria below. The anticipated Course Outline contains a weekly breakdown of the lecture material and assignment due dates. Required Digital Lighting and Rendering (2nd Edition) (Paperback) Textbooks Jeremy Birn, (ISBN: 978-0321316318) Compositing Visual Effects -

Department of Media Sciences Anna University, Chennai
DEPARTMENT OF MEDIA SCIENCES ANNA UNIVERSITY, CHENNAI VISION To offer quality media studies and research, using state-of-the-art images for building an inter-disciplinary knowledge base, so as to contribute to development and democracy. To produce creative and technically apt professionals for the media industry. The theoretical and practical media courses taught in the PG programme will improve, explore, innovate and implement core media techniques by “learn by doing” philosophy. The PG programme will continue to prepare students for professional and personal success in today’s exciting and innovative media landscape. MISSION To create an enabling environment to nurture ideas, freedom of expression, creativity and scholarship, and develop leaders in the arena of media and mass communication. The mission of the PG programme is to excel in media education on fundamental media concepts, values and skills in various platforms that focus on problem solving, critical thinking, innovation and communications. To promote the understanding of ethical and legal implication of all forms of media and the importance of cultural and intellectual diversity, techno-savvy, civic engagement and social responsibility in preparing the students for leadership role in media industry. To enable students to understand the role of media in nation building. To instill a sense by creating and innovation among journal minds for better societal contribution. 1 ANNA UNIVERSITY, CHENNAI UNIVERSITY DEPARTMENTS M. Sc. ELECTRONIC MEDIA (2 YEARS) REGULATIONS – 2019 CHOICE BASED CREDIT SYSTEM 1. PROGRAMME EDUCATIONAL OBJECTIVES (PEOs): 1. Find gainful employment in media and entertainment industry. 2. Enter into higher studies leading to research degrees and advanced specialization. -

Motion 3 Supplemental Documentation
Motion 3 Supplemental Documentation K Apple Inc. Apple, the Apple logo, Final Cut, Final Cut Pro, Copyright © 2007 Apple Inc. All rights reserved. Final Cut Studio, Mac, and Mac OS are trademarks of Apple Inc., registered in the U.S. and other countries. Your rights to the software are governed by the accompanying software license agreement. The owner Finder is a trademark of Apple Inc. or authorized user of a valid copy of Final Cut Studio software may reproduce this publication for the purpose Other company and product names mentioned herein of learning to use such software. No part of this are trademarks of their respective companies. Mention publication may be reproduced or transmitted for of third-party products is for informational purposes commercial purposes, such as selling copies of this only and constitutes neither an endorsement nor a publication or for providing paid for support services. recommendation. Apple assumes no responsibility with regard to the performance or use of these products. The Apple logo is a trademark of Apple Inc., registered in the U.S. and other countries. Use of the “keyboard” Apple logo (Shift-Option-K) for commercial purposes without the prior written consent of Apple may constitute trademark infringement and unfair competition in violation of federal and state laws. Every effort has been made to ensure that the information in this manual is accurate. Apple is not responsible for printing or clerical errors. Note: Because Apple frequently releases new versions and updates to its system software, applications, and Internet sites, images shown in this book may be slightly different from what you see on your screen. -

The Director's Method in Contemporary Visual Effects Film
The Director’s Method in Contemporary Visual Effects Film: The Influence of Digital Effects on Film Directing Gianluca Balla PhD University of York Theatre, Film and Television September 2016 Abstract The director’ s method – meant as the organisation of the filmmaking process – is usually characterised by common procedures such as work on the script, shot design and the actors’ performance. For films involving a large-scale use of digital effects, directors consistently approach such procedures with a particular attitude dictated by the digital pipeline, the step-by- step technical procedure through which computer-generated images are created. In light of this, the use of digital effects might influence the director’s method. This thesis aims to define what is considered to be a consensual methodological approach to direct films with no or few digital effects and then compares this approach to when such effects are conspicuously involved. This analysis is conducted through interviews with working directors, visual effects companies and practitioners, and integrated with the current literature. The frame of the research is represented by a large spectrum of contemporary films produced in western countries and which involve digital effects at different scales and complexity but always in interaction with live-action. The research focuses on commercial films and excludes computer-animated and experimental films. The research is intended to address an area in production studies which is overlooked. In fact, although the existent literature examines both digital effects and film directing as distinct elements, there is to date no detailed analysis on the influence that the former has on the latter. -

Methods for Freezing Time with Computer Graphics Imagery
Beteckning:________________ Department of Industrial Development, IT and Land Management Methods for Freezing Time with Computer Graphics Imagery Martin Andersson MartinMarcus Andersson Olofsson Marcus Olofsson June 2010 Bachelor Thesis, 15 hp, C Computer Science Creative Computer Graphics Examiner: Sharon Lazenby Co-examiner: Ann-Sofie Östberg Methods for Freezing Time with Computer Graphics Imagery By Martin Andersson Marcus Olofsson Akademin för teknik och miljö Högskolan i Gävle S-801 76 Gävle, Sweden Email: [email protected] [email protected] Abstract The most effective method to create an illusion of frozen time in film media was explored for this research. Starting with a description and evaluation of different methods of achieving the effect, this document describes the implementation of a specific technique for a particular project to test freezing time. It was also established to aid students in their understanding of the process in both pre- and post-production. After testing and researching, the method of filming still-posing actors with a high speed camera was chosen. However, the testing and pre- production phase demanded a large amount of time, therefore for the remainder of the project only one scene was established. For budget and time consuming purposes the two recommended techniques are; camera projection and filming still-posing actors with a high speed camera. The choice between these two methods mainly depends on the amount of camera movement. Keywords: Time freeze, film production, pre-production, -

Chromakey Technology and Technique HISTORY Schüfftan Process Miniatures and Mirrors
Chromakey Technology and Technique HISTORY Schüfftan process Miniatures and mirrors Double exposure Matted cameras Glass Plates Rear projection HISTORY Double exposure Glass Plates Matted cameras Rear projection From Filming the fantastic: a history of visual effects cinematography by Mark Sawicki HISTORY Double exposure Glass Plates Matted cameras Rear projection From Filming the fantastic: a history of visual effects cinematography by Mark Sawicki COLOUR - Selectively defining of a specific colour value - Making specific colour values generate an alpha channel - Using the Alpha Channel to define transparency COLOUR RGB colour space + Alpha Channel Black and white mask dictating transparency RGB RGBA ELEMENTS of the COMPOSIT Source Alpha Plate Final CAMERA and COLOUR SPACE The greater the amount of colour information the cleaner the key - Option A) Use a high-end 4:2:2 camera (Varicam, Sony F900, Panasonic HPX500, Sony PDW700, etc) Option B) Record SDI feed direct form camera to SDI hardware (deck, PC card, etc) Option C) Use a 4:2:0 camera with a high native resolution and large sensor (Sony Ex1, Ex3) High native resolution can make up limitations of colour sampling. 1920x1080 photosites at 420 provides more ‘colour data’ than a less photosites at 422. LIGHTING Screen light Screen light Back Back Fill Key LIGHTING STEPS 1. Light the screen 2. Adjust camera exposure until Zebras show (90IRE) 3. Adjust lighting to make Zebra pattern even across the screen 4. Stop exposure down to loose the Zebra 5. Light the subject with Key, Fill and Backlight 6. White balance for the subject not the screen 7. Adjust Key, Fill and Backlight to match the Plate 8. -

The Visual Effects Guide to Davinci Resolve 17
The Visual Effects Guide to DaVinci Resolve 17 Download DAVINCI RESOLVE 17 Free! Author: Dion Scoppettuolo, Damian Allen, Tony Gallard The Visual Effects Guide to DaVinci Resolve 17 The Visual Effects Guide to DaVinci Resolve 17 Damian Allen, Tony Gallardo, and Dion Scoppettuolo © 2021 by Blackmagic Design Pty Ltd Blackmagic Design www.blackmagicdesign.com To report errors, please send a note to [email protected]. Series Editor: Patricia Montesion Editor: Dan Foster Technical Review: David Hover Cover Design: Blackmagic Design Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For information on obtaining permission for reprints and excerpts, contact [email protected]. Notice of Liability Neither the author nor Blackmagic Design shall have any liability to any person or entity for any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this book, or by omissions from this book, or by the computer software and hardware products described within it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Blackmagic Design was aware of a trademark claim, the designations appear as requested by the owner of the trademark. All other product names and services identified throughout this book are used in editorial fashion only and for the benefit of such companies with no intention of infringement of the trademark. -

Posthuman Geographies in Twentieth Century Literature and Film Alex
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Carolina Digital Repository Surfing the Interzones: Posthuman Geographies in Twentieth Century Literature and Film Alex McAulay A dissertation submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of English. Chapel Hill 2008 Approved by: Pamela Cooper María DeGuzmán Kimball King Julius Raper Linda Wagner-Martin © 2008 Alex McAulay ALL RIGHTS RESERVED ii ABSTRACT ALEX MCAULAY: Surfing the Interzones: Posthuman Geographies in Twentieth Century Literature and Film (Under the direction of Pamela Cooper) This dissertation presents an analysis of posthuman texts through a discussion of posthuman landscapes, bodies, and communities in literature and film. In the introduction, I explore and situate the relatively recent term "posthuman" in relation to definitions proposed by other theorists, including N. Katherine Hayles, Donna Haraway, Judith Halberstam and Ira Livingston, Hans Moravec, Max More, and Francis Fukuyama. I position the posthuman as being primarily celebratory about the collapse of restrictive human boundaries such as gender and race, yet also containing within it more disturbing elements of the uncanny and apocalyptic. My project deals primarily with hybrid texts, in which the posthuman intersects and overlaps with other posts, including postmodernism and postcolonialism. In the first chapter, I examine the novels comprising J.G. Ballard's disaster series, and apply Bakhtin's theories of hybridization, and Deleuze and Guattari's notions of voyagings, becomings, and bodies without organs to delineate the elements that constitute a posthuman landscape. -

Srm Institute of Science and Technology
SRM INSTITUTE OF SCIENCE AND TECHNOLOGY FACULTY OF SCIENCE & HUMANITIES SRM SCHOOL OF FILM TECHNOLOGY PROGRAMME B.Sc – Film Technology SEMESTER SYSTEM CURRICULUM AND SYLLABI Academic year 2018-2019 onwards SRM INSTITUTE OF SCIENCE AND TECHNOLOGY FACULTY OF SCIENCE AND HUMANITIES SRM SCHOOL OF FILM TECHNOLOGY SYLLABUS FOR B.Sc. in FILM TECHNOLOGY For Academic Year 2018-2019 I SEMESTER Total S. Subject Subject Title L T P of C N code LTP ULT181T1 Tamil – I Part- ULM181T2 Malayalam-I 1 Language 4 0 0 4 4 1 ULH181T3 Hindi – I ULF18101 French – I Part- 2 ULE181T4 English – I 4 0 0 4 4 2 Part- Orientation to Film 3 Core-1 UFT181T5 4 0 0 4 4 3 Technology–I 4 Core-2 UFT181T6 History of Cinema 4 0 0 4 4 Indian Art and 5 Core-3 UFT181T7 3 1 0 4 3 Culture 6 Core-4 UFT181P1 Film Appreciation 0 0 4 4 4 Script Writing and 7 Core-5 UFT181P2 Basics of 0 1 3 4 3 Videography Part- 8 CAC18101 Soft Skill 2 0 0 2 2 4 21 2 7 30 28 2 SRM FILM TECHNOLOGY II SEMESTER Total S. Subject Subject Title L T P of C N code LTP ULT182T1 Tamil – II ULM182T2 Malayalam – II 1 Part-1 Language 5 0 0 5 5 ULH182T3 Hindi – II ULF18201 French – II 2 Part-2 ULE182T4 English – II 5 0 0 5 5 Orientation to Film 3 Part-3 Core-6 UFT182T5 4 0 0 4 4 Technology – II Contemporary World 4 Core-7 UFT182T6 3 1 0 4 3 Cinema Intro to Sociology and 5 Core-8 UFT182T7 2 1 0 3 3 Polity 6 Core-9 UFT182P1 Film Making Exercises 0 1 4 5 3 Post Production 7 Core-10 UFT182P2 0 1 3 4 3 Exercises UNS18201 NSS UNC18201 NCC 8 Part-5 0 0 0 0 1 UNY18201 Yoga UNS18201 Sports Total 19 4 7 30 27 3 SRM FILM TECHNOLOGY DIRECTION III SEMESTER Total S.