Joint Entity Linking with Deep Reinforcement Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rugby World Cup Quiz
Rugby World Cup Quiz Round 1: Stats 1. The first eight World Cups were won by only four different nations. Which of the champions have only won it once? 2. Which team holds the record for the most points scored in a single match? 3. Bryan Habana and Jonah Lomu share the record for the most tries in the final stages of Rugby World Cup Tournaments. How many tries did they each score? 4. Which team holds the record for the most tries in a single match? 5. In 2011, Welsh youngster George North became the youngest try scorer during Wales vs Namibia. How old was he? 6. There have been eight Rugby World Cups so far, not including 2019. How many have New Zealand won? 7. In 2003, Australia beat Namibia and also broke the record for the largest margin of victory in a World Cup. What was the score? Round 2: History 8. In 1985, eight rugby nations met in Paris to discuss holding a global rugby competition. Which two countries voted against having a Rugby World Cup? 9. Which teams co-hosted the first ever Rugby World Cup in 1987? 10. What is the official name of the Rugby World Cup trophy? 11. In the 1995 England vs New Zealand semi-final, what 6ft 5in, 19 stone problem faced the English defence for the first time? 12. Which song was banned by the Australian Rugby Union for the 2003 World Cup, but ended up being sang rather loudly anyway? 13. In 2003, after South Africa defeated Samoa, the two teams did something which touched people’s hearts around the world. -

FIFA and the FIRST WORLD CUP by 1900 Soccer Was Well on Its Way to World Domination
THE WORLD CUP SOCCER’S GLOBAL CHAMPIONSHIP he World Cup is international Tsoccer’s championship tournament, and it rules the global sports stage. Award-winning author Matt Doeden explores the history of international soccer and covers the World Cup’s greatest moments, from the Save of the Century to Diego Maradona’s Hand of God goal to the United States Women’s National Team’s dominance. The most shocking goals, the greatest upsets, and the fun and fanfare of soccer’s biggest event are all here. REINFORCED BINDING Matt Doeden J MILLBROOK PRESS · MINNEAPOLIS Copyright © 2018 by Lerner Publishing Group, Inc. All rights reserved. International copyright secured. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means— electronic, mechanical, photocopying, recording, or otherwise—without the prior written permission of Lerner Publishing Group, Inc., except for the inclusion of brief quotations in an acknowledged review. Millbrook Press A division of Lerner Publishing Group, Inc. 241 First Avenue North Minneapolis, MN 55401 USA For reading levels and more information, look up this title at www.lernerbooks.com. Main body text set in Adobe Garamond Pro Regular 14/19. Typeface provided by Adobe Systems. Library of Congress Cataloging-in-Publication Data Names: Doeden, Matt. Title: The world cup : soccer’s global championship / By Matt Doeden. Description: Minneapolis : Millbrook Press, [2018] | Series: Spectacular sports | Includes bibliographical references and index. Identifiers: LCCN 2017009220 (print) | LCCN 2017014231 (ebook) | ISBN 9781512498684 (eb pdf) | ISBN 9781512427554 (lb : alk. paper) Subjects: LCSH: World Cup (Soccer)—Juvenile literature. -

Mardy Fish Named Us Davis Cup Captain
MARDY FISH NAMED U.S. DAVIS CUP CAPTAIN WHITE PLAINS, N.Y., January 9, 2019 – The USTA today announced that former world No. 7 and Davis Cup veteran Mardy Fish has been named the new captain of the U.S. Davis Cup Team. He succeeds Jim Courier to become the 41 st captain in the team’s 120-year history and will make his debut at the newly transformed Davis Cup by BNP Paribas Finals November 18-24 in Madrid, Spain. “Ever since I started playing professionally and started understanding what the Davis Cup was and how special it was, even as a player, I wanted to be the Davis Cup Captain,” Fish said. “I just thought that position was so special – leading the guys and leading the team, building relationships and the team aspect around it. I’m a team-sport athlete stuck in an individual sport, and I love the team aspect of Davis Cup. To even be considered, let alone named the Captain, is incredibly humbling.” In this new era of Davis Cup, the role of Captain will be expanded, with the position working more closely with USTA Player Development throughout the year, as well as traveling to multiple tournaments and camps to support American players, serving as a mentor for American pros and juniors. He will also ensure the U.S. Davis Cup team remains a strong platform to grow the game through the USTA’s Net Generation youth initiative. “Mardy Fish embodies all of the qualities of a successful Davis Cup Captain and will be an invaluable asset to Team USA,” said USTA Chairman of the Board and President Patrick Galbraith. -

This Content Is a Part of a Full Book - Tennis for Students of Medical University - Sofia
THIS CONTENT IS A PART OF A FULL BOOK - TENNIS FOR STUDENTS OF MEDICAL UNIVERSITY - SOFIA https://polis-publishers.com/kniga/tenis-rukovodstvo-za-studenti/ A brief history of tennis 1. Origin and development of the game Ball games were popular in ancient Rome and Greece under the name of a spherical "ball game". In the 11 th and 12 th centuries, the games of "Jacko del Palone" and "Jaco de la Corda" were mentioned, which resembled modern tennis (Todorov 2010; Mashka, Shaffarjik 1989). In the 14 th century, outdoor and indoor courts started to be built in France, where the game of "court – tennis" was played, which was later renamed "palm game", that, dependent on being played inside or outside, was called "short tennis" and " long tennis" (Penchev 1989). Antonio Scaino da Salò’s book "Treatise on the game of the ball" (1555) describes the game instruments - a racquet and a ball - a tight ball of wool, wrapped in leather. It was struck with the palm of the hand, wrapped in a leather belt and a wooden case. A glove was used as well to protect against pain and traumas (Mashka, Shaffarjik 1989). The "court - tennis" game became popular predominantly amongst the nobles in Europe under the name of "Jeu de paume" – palm game, played both indoors and outdoors. “Mirabo” hall, part of the famous Versailles Palace that was transformed at that time by the Sun King - Louis XIV into a main residence of the French kings, exists to this day and had served for that purpose. Fig. 1. -
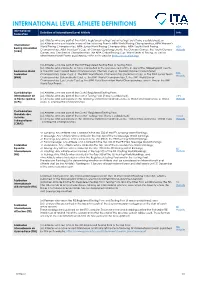
International Level Athlete Definitions
INTERNATIONAL LEVEL ATHLETE DEFINITIONS International Definition of International Level Athlete Links Federation (a) Athletes who are part of the AIBA’s Registered Testing Pool or Testing Pool (if one is established); or (b) Athletes who participate in any of the following Events: AIBA World Boxing Championships, AIBA Women’s International World Boxing Championships, AIBA Junior World Boxing Championships, AIBA Youth World Boxing AIBA Boxing Association Championships, AIBA President’s Cup, all Olympic Qualifying Events, the Olympic Games, the Youth Olympic Website (AIBA) Games, any Continental Championships, the AIBA Global Boxing Cup, World Series of Boxing, as well as other International Events published by AIBA on its website (http://www.aiba.org). (a) Athletes who are part of the BWF Registered Testing Pool or Testing Pool; (b) Athletes who compete, or have competed in the previous 12 months, in any of the following BWF Events: Badminton World a. The BWF Men’s World Team Championships (Thomas Cup); b. The BWF Women’s World Team BWF Federation Championships (Uber Cup); c. The BWF World Team Championships (Sudirman Cup); d. The BWF Junior Team Website (BWF) Championships (Suhandinata Cup); e. The BWF World Championships; f. The BWF World Junior Championships (Eye Levels Cup); g. The BWF Para Badminton World Championships; and h. Any of the BWF World Tour Events. Confédération (a) Athletes who are part of the CMAS Registered Testing Pool; Internationale de (b) Athletes who are part of the CMAS Testing Pool (if one is established); CIPS la Pêche Sportive (c) Athletes who participate in the following CMAS International Events: a. World Championships; b. -

FIM Speedway World Cup Final, Belle
FIM SPEEDWAY WORLD CUP. Grand Final. Manchester, England Poland 39 1 2 3 4 5 6 Pts Heat G Rider NS Substitute J NF R Pol Aus Swe GB Heat G Rider NS Substitute J NF R Pol Aus Swe GB 1 Piotr Pawlicki 0 3 2 2 3 10 3 Krzysztof Kasprzak Y 3 Bartosz Zmarzlik R 1 0 2 3 3 2 1 0 2 Bartosz Zmarzlik 1 3 3 1 3 11 1 2 Jason Doyle W 11 1 Jason Doyle B 3 Patryk Dudek 3 1 1 2 3 10 1 Fredrik Lindgren R 1 0 2 3 2 Peter Ljung W 21 15 19 11 4 Krzysztof Kasprzak 1 3 2 0 2 8 4 Tai Woffinden B 4 Robert Lambert Y 5 Krystian Pieszczek 2 Patryk Dudek R 4 Piotr Pawlicki Y 3 0 2 1 2 0 1 6 2 1 Josh Grajczonek W 12 2 Josh Grajczonek TS 4 Sam Masters R Australia 22 1 2 3 4 5 6 Pts Peter Ljung Fredrik Lindgren 4 Y 4 0 4 4 3 W 23 15 20 17 1 Jason Doyle 0 3 2 D 2 7 3 Craig Cook B 1 Danny King TJ 2 Tai Woffinden TJ B 2 Josh Grajczonek 0 0 TS TS 0 0 1 Bartosz Zmarzlik W 3 Patryk Dudek W 1 2 3 T 2 0 3 1 3 Chris Holder 2 1 2 3 2 0 10 3 3 Sam Masters B 13 2 Sam Masters R 4 Sam Masters 2 0 3 0 0 0 5 2 Andreas Jonsson R 5 2 7 4 4 Fredrik Lindgren Y 25 15 23 18 5 Brady Kurtz 4 Danny King T Y 1 Robert Lambert B 2 Piotr Pawlicki W 1 Krzysztof Kasprzak B 0 2 3 1 0 3 1 2 Sweden 30 1 2 3 4 5 6 Pts 4 1 Chris Holder B 14 4 Chris Holder Y 1 Andreas Jonsson 3 2 0 1 2 8 Antonio Lindback Peter Ljung 4 Y 5 4 10 5 3 W 25 18 24 20 2 Antonio Lindback 3 2 1 0 TS 6 3 Robert Lambert R 2 Danny King R 3 Peter Ljung 2 1 1 1 1 6 4 Krzysztof Kasprzak R 2 Bartosz Zmarzlik Y 3 0 2 1 1 2 0 3 4 Fredrik Lindgren 2 2 1 3 1 1 10 5 3 Josh Grajczonek W 15 4 Josh Grajczonek TS 3 Chris Holder B 5 Joel Andersson -

Design Challenges for Entity Linking
Design Challenges for Entity Linking Xiao Ling Sameer Singh Daniel S. Weld University of Washington, Seattle WA fxiaoling,sameer,[email protected] Abstract provide semantic annotations to human readers but also a machine-consumable representation of Recent research on entity linking (EL) has in- the most basic semantic knowledge in the text. troduced a plethora of promising techniques, Many other NLP applications can benefit from ranging from deep neural networks to joint in- ference. But despite numerous papers there such links, such as distantly-supervised relation is surprisingly little understanding of the state extraction (Craven and Kumlien, 1999; Riedel et al., of the art in EL. We attack this confusion by 2010; Hoffmann et al., 2011; Koch et al., 2014) that analyzing differences between several versions uses EL to create training data, and some coreference of the EL problem and presenting a simple systems that use EL for disambiguation (Hajishirzi yet effective, modular, unsupervised system, et al., 2013; Zheng et al., 2013; Durrett and called VINCULUM, for entity linking. We con- Klein, 2014). Unfortunately, in spite of numerous duct an extensive evaluation on nine data sets, papers on the topic and several published data comparing VINCULUM with two state-of-the- art systems, and elucidate key aspects of the sets, there is surprisingly little understanding about system that include mention extraction, candi- state-of-the-art performance. date generation, entity type prediction, entity We argue that there are three reasons -

REGULATIONS FIFA World Cup 2022™ Preliminary Competition Including COVID-19 Regulations Fédération Internationale De Football Association
REGULATIONS FIFA World Cup 2022™ Preliminary Competition Including COVID-19 Regulations Fédération Internationale de Football Association President: Gianni Infantino Secretary General: Fatma Samoura Address: FIFA-Strasse 20 P.O. Box 8044 Zurich Switzerland Telephone: +41 (0)43 222 7777 Internet: FIFA.com REGULATIONS FIFA World Cup 2022™ Preliminary Competition Including COVID-19 Regulations 2 Organisers ORGANISERS 1. Fédération Internationale de Football Association President: Gianni Infantino Secretary General: Fatma Samoura Address: FIFA-Strasse 20 P.O. Box 8044 Zurich Switzerland Telephone: +41 (0)43 222 7777 Internet: FIFA.com 2. Organising Committee for FIFA Competitions Chairman: Aleksander Čeferin Deputy chairwoman: María Sol Muñoz Contents 3 CONTENTS Article Page GENERAL PROVISIONS 4 1 FIFA World Cup 2022™ 4 2 Organising Committee for FIFA Competitions 5 3 Participating member associations 5 4 Entries for the FIFA World Cup™ 8 5 Withdrawal, unplayed matches and abandoned matches 10 6 Replacement 13 7 Eligibility of players 13 8 Laws of the Game 14 9 Football technologies 15 10 Refereeing 16 11 Disciplinary matters 17 12 Medical/doping 18 13 Disputes 19 14 Protests 20 15 Yellow and red cards 21 16 Commercial rights 22 17 Operational guidelines 22 PRELIMINARY COMPETITION ORGANISATION 23 18 Entry form 23 19 List of players 23 20 Preliminary draw, format of play and group formation 26 21 Venues, kick-off times and training sessions 30 22 Stadium infrastructure and equipment 32 23 Footballs 36 24 Team equipment 37 25 Flags, anthems and competition music 38 26 Media 38 27 Financial provisions 41 28 Ticketing 43 29 Liability 43 FINAL COMPETITION 44 30 Final competition 44 FINAL PROVISIONS 45 31 Matters not provided for and force majeure 45 32 Prevailing set of regulations 45 33 Languages 45 34 Copyright 45 35 No waiver 46 36 Enforcement 46 4 General provisions GENERAL PROVISIONS These Regulations for the FIFA World Cup 2022™ Preliminary Competition have been modified to adopt regulations to address the COVID-19 pandemic (“COVID-19 Regulations”). -

An Economic Analysis of How the World Cup Has Impacted the Economy of a Developed and a Developing Nation
University of Lynchburg Digital Showcase @ University of Lynchburg Undergraduate Theses and Capstone Projects Spring 4-2020 Hosting the FIFA World Cup: An Economic Analysis of how the World Cup has Impacted the Economy of a Developed and a Developing Nation Juan Borga Follow this and additional works at: https://digitalshowcase.lynchburg.edu/utcp Part of the Economics Commons, and the Sports Management Commons Hosting the FIFA World Cup: An Economic Analysis of how the World Cup has Impacted the Economy of a Developed and a Developing Nation Juan Borga Senior Research Project Submitted in partial fulfillment of the graduation requirements of the Westover Honors College Westover Honors College April 2020 __________________________________ Jessica Scheld, Ph.D. __________________________________ Michael Schnur, Ph.D. __________________________________ Edward DeClair, Ph.D. Table of Contents I. Introduction……………….……………………………………………………………….……1 II. Selecting the Host Nation…………………...………………………………………………….2 III. The Case for Brazil and Germany…………………………………………………………….4 IV. Literature Review: Narrative ……….…………………………………..….…………………4 V. Model Development.…………………………….……………………………………………..8 VI. Presentation of Data…...…………………………………………………………….……….10 VII. Methodology…..……………………………………………………………………………12 VIII. Results…………………………………………………………………………………...…13 IV. Socio Economic Impact……...………………………………………………………………20 X. Conclusions and Suggestions…………………………………………………………………25 XI. Contributions and Future Lines of Research……………..………………………….………28 XII. References………………….………………………………………………………………30 -

WBSC Baseball World Ranking Points Methodology
WORLD RANKING POINTS METHODOLOGY Top-Tier World Events Max Points (100%) Min Points (10%) Premier12 1,200 (+ 180 Bonus to winner) 120 World Baseball Classic 1,000 (+ 150 Bonus to winner) 100 World Championships U-23 Baseball World Cup 600 (+ 90 Bonus to winner) 60 U-18 Baseball World Cup 500 (+ 75 Bonus to winner) 50 U-15 Baseball World Cup 400 (+ 60 Bonus to winner) 40 U-12 Baseball World Cup 300 (+ 45 Bonus to winner) 30 Major Multi-Sport and Continental Championships (Men’s) If event includes 5 or more Top 12 500 50 Nations If event includes 4 Top 12 Nations 400 40 If event includes 3 Top 12 Nations 300 30 If event includes 1 or 2 Top 12 200 20 Nations B-Level 80 8 C-Level 50 5 Minor Multi-Sport Events If event serves as qualifier 50 5 If event doesn’t serve as a qualifier 30 3 FISU Universiade 20 2 Friendly Int’l Tournaments World Port Tournament, Haarlem 10 1 Week, etc. Baseball World Cup Qualifiers (from 2016 only) U-23 Baseball World Cup 60 6 U-18 Baseball World Cup 50 5 U-15 Baseball World Cup 40 4 U-12 Baseball World Cup 30 3 Head-to-Head Friendlies Win over a Top 12 Nation 3 N/A Win over Nos. 13-25 Nation 2 N/A Win over Nation outside Top 25 1 N/A The formula for the points-differential between each team in the final standings of a tournament is: (Maximum Points) - (Minimum Points) --------------------------------------------------------- (Teams in Tournament) - 1 Using Premier12 as an example: (1,200) - (120) 1,080 --------------------- = ------------ = 98,18 points between each team (12) – 1 11 (98 points by rounding to the nearest point) 1st Place: 1,200 + 180 bonus 2nd Place: 1,102 3rd Place: 1,003, etc. -

2018 Coverage
2018 coverage Unrivalled highlights coverage sntv offers more cleared highlights from a wider range of sports than anyone else, offering the greatest breadth of sports coverage worldwide. Videos that inform and engage We provide our clients with the most relevant and engaging videos, either fully customisable or ready to publish directly to your audience. Global and regional sports video news Our dedicated teams fully understand what our clients are looking for, and recognise what content will drive conversations on both an international and regional level. January February March April May soccer soccer american football soccer baseball AFC Champions League Superbowl LII Chinese Super League MLB Season FA Cup Final Jan - Nov Feb Mar - Nov Apr - Oct May Copa Libertadores J.League UEFA Champions Jan - Nov rugby Mar - Dec basketball League Final RBS Six Nations NBA Playoffs May tennis Championship golf Apr - May UEFA Europa League Final ATP World Tour Feb - Mar ANA Inspiration May Jan - Nov Mar - Apr american football UEFA Women’s Champions Australian Open soccer NFL Draft League Final Jan EFL Cup Final baseball Apr May Davis Cup Feb MLB Spring Training Jan - Nov Mar ice hockey tennis Hopman Cup tennis NHL Playoffs French Open Jan Fed Cup motorsport Apr - Jun May - Jun WTA Tour Feb - Nov Jan - Oct Formula One Mar - Nov golf basketball golf golf Moto GP The Masters NBA Finals Apr European Tour Asian Tour Mar - Aug May - Jun Feb - Dec Jan - Nov MXGP Ladies European Tour motorsport golf LPGA Tour Mar - Oct Feb - Dec World Touring Car Players -

Junior National Team (18U) Information About /Selection
Baseball Canada-Junior National Team (18U) Information About /Selection Process The Junior National Team is made up of some of the best high school aged (18 and under) baseball players in Canada. In 1999 the program moved to a ‘year-round’ format consisting of four annual trips and either a WBSC U18 World Cup or a COPABE 18U Pan American Championship / U18 World Cup qualifier. These two events occur in alternating years. Each year, the Junior National Team season begins with the Fall Instructional League program at ESPN Wide World of Sports (Orlando, Florida) in October. In March of the following year, the program resumes with Spring Training in St. Petersburg, Florida followed by Extended Spring Training in April at ESPN Wide World of Sports in Orlando. In May, the team takes its annual trip to the Dominican Republic for a tour through the Dominican Summer League. Typically, each of these four trip last 10-14 days. Depending on the year, a summer trip can be added. The season concludes with a Final Selection Camp where 20 players are chosen to represent Canada at either the WBSC U18 World Cup or the COPABE 18U Pan American Championship / U18 World Cup Qualifier. Athlete selection process begins each year at the Baseball Canada Cup where players are identified and invited to October’s Fall Instructional League Camp. Players are also evaluated at certain events throughout the year including MLB Scouting Bureau Camps, Tournament 12 in Toronto and various tournaments across the country. *Age eligibility for the Junior National Team states that players must not be older than 18 years of age on December 31st of each calendar year.