Automatic Defense Against Zero-Day Polymorphic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Security Industry Monitor March 2014
Security Industry Monitor March 2014 For additional information on our Security Team, please contact: John E. Mack III Co-head, Investment Banking Group Head of Mergers and Acquisitions (310) 246-3705 [email protected] Michael McManus Managing Director, Investment Banking Group (310) 246-3702 [email protected] PLEASE SEE IMPORTANT DISCLOSURES ON LAST PAGE About Imperial Capital, LLC Imperial Capital is a full-service investment bank offering a uniquely integrated platform of comprehensive services to institutional investors and middle market companies. We offer sophisticated sales and trading services to institutional investors and a wide range of investment banking advisory, capital markets and restructuring services to middle market corporate clients. We also provide proprietary research across an issuer’s capital structure, including bank debt, debt securities, hybrid securities, preferred and common equity and special situations claims. Our comprehensive and integrated service platform, expertise across the full capital structure, and deep industry sector knowledge enable us to provide clients with superior advisory services, capital markets insight, investment ideas and trade execution. We are quick to identify opportunities under any market conditions and we have a proven track record of offering creative, proprietary solutions to our clients. Imperial Capital’s expertise includes the following sectors: Aerospace, Defense & Government Services, Airlines & Transportation, Business Services, Consumer, Energy (Clean Energy and Traditional Energy), Financial Services, Gaming & Leisure, General Industrials, Healthcare, Homebuilding & Real Estate, Media & Telecommunications, Security & Homeland Security and Technology. Imperial Capital has three principal businesses: Investment Banking, Institutional Sales & Trading and Institutional Research. For additional information, please visit our Web site at www.imperialcapital.com. -

L'etat Passe À La Vitesse Supérieure
AAGGAAZZ MM IINN E EE E RR 11 0 T 0 T 0 0 O O % % V V - - G G T T R I R I A U T A U T 23 - Août 2008 ISSN 1112-8178 Actualités P.05 « Aucune puce anonyme au-delà du 10 Octobre ! » Algérie Télécom s’allie à Stonesoft Corporation BIVISION SYSTEMS La 1ère encyclopédie algérienne en ligne Réunion de l’Icann Mobilité P.10 Nokia destination design HP Nouvelle gamme de PC portables SONY : Are you VAIO ? LG lance le Chocolate 3 et le KS360 SAMSUNG DOSSIER : Page 22 Le i900 Omnia et le i710 DU NOUVEAU DANS LE HAUT ET LE TRES HAUT DEBIT Conso P.24 L’Etat passe à la vitesse supérieure Bien choisir son appareil photo numérique Trucs et astuces P.31 Faire de la place dans son disque dur (XP et Vista) Internet pratique P.32 Page 18 Faites le plein de plug-ins Jeux vidéo : Que retenir des conférences à votre navigateur des constructeurs lors de l’E3 2008 ? Page 26 OU TROUVER N’TIC ? Points de distribution Edito Cyber Orange : 01, rue Hassiba Ben Bouali, Alger centre Les Technologies de l’Information et de la Communication en Algerian Learning Center (ALC) : 2 & 8, Rue de Savoie, Hydra général et l’ADSL en particulier, constituent une aubaine pour Librairie Maison de la presse : 1 Place Kennedy, El Biar les pays émergeants, elles sont un moyen de lutte contre les Librairie BOUHADJAR : (face lycée Hamia), Kouba principaux facteurs de pauvreté que sont : l’ignorance et l’iso- Librairie El Kartassia : 1 Boulevard Amirouche, Alger centre Librairie Liberté : 17 Cité des Asphodèles, Ben Aknoun lement. -

VOLUME 2 BOOK 4B
Registration No: 1998/009584/06 SOUTH AFRICAN NATIONAL ROADS AGENCY LIMITED PROCUREMENT OF A NATIONAL INTELLIGENT TRANSPORT SYSTEM AND INTEGRATED SUPPORTING SYSTEMS SOFTWARE AND THE DEPLOYMENT THEREOF IN GAUTENG, KWAZULU-NATAL AND THE WESTERN CAPE STANDARD SPECIFICATION FOR ELECTRONIC WORKS JUNE 2010 VOLUME 2 BOOK 4b THE REGIONAL MANAGER NORTHERN REGION SOUTH AFRICAN NATIONAL ROADS AGENCY LIMITED 38 IDA STREET MENLO PARK PRETORIA SOUTH AFRICA 0081 - ii - VOLUME 2 BOOK 4b: STANDARD SPECIFICATION FOR ELECTRONIC WORKS - iii - TABLE OF CONTENT PART 3 ELECTRONIC EQUIPMENT AND DESIGN .................................................................................................... 7 SECTION 1 INFORMATION AND COMMUNICATION TECHNOLOGY SPECIFICATIONS .............................................. 8 1.1 SCOPE .................................................................................................................................................................. 9 1.2 STANDARDS ........................................................................................................................................................ 9 1.3 NETWORK CABLING .......................................................................................................................................... 11 1.4 NETWORK AND COMMUNICATION EQUIPMENT .............................................................................................. 18 1.5 SERVER AND STORAGE HARDWARE ................................................................................................................. -

List of Versions Added in ARL #2622
List of Versions added in ARL #2622 Publisher Product Version .NET Foundation Windows Installer XML 3.6 .NET Foundation Windows Installer XML 3.8 .NET Foundation WiX Toolset 3.8 .NET Foundation Windows Installer XML 3.7 /n software IP*Works! SSH 9.0 [den4b] Denis Kozlov ReNamer 6.2 [den4b] Denis Kozlov ReNamer 6.7 [den4b] Denis Kozlov ReNamer 6.9 [den4b] Denis Kozlov ReNamer 7.1 10x Genomics Loupe Browser 5.0 2BrightSparks SyncBackSE 9.1 2BrightSparks SyncBackFree 8.6 2BrightSparks SyncBackFree 9.0 2BrightSparks SyncBackFree 9.1 2BrightSparks SyncBackFree 9.2 2BrightSparks EncryptOnClick 2.1 2BrightSparks SyncBackPro 6.1 360 360 Total Security 10.6 3CX 3CXPhone 12.0 3CX 3CXPhone 15.0 3D Systems 3D Sprint 2.13 3D Systems 3D Sprint 2.5 3D Systems 3D Sprint 3.0 3D Systems Geomagic Control X 2020.0 3DP Chip 16.11 3M Detection Management Software 2.3 3T Software Labs Robo 3T 10.1 3T Software Labs Studio 3T 2021.3 3uTools 3uTools 2.31 3uTools 3uTools 2.32 3uTools 3uTools 2.33 3uTools 3uTools 2.36 3uTools 3uTools 2.37 3uTools 3uTools 2.38 3uTools 3uTools 2.39 3uTools 3uTools 2.50 3uTools 3uTools 2.51 3uTools 3uTools 2.53 3uTools 3uTools 2.56 4Team Sync2 2.83 4Team OST PST Viewer 1.12 4Team OST PST Viewer 1.22 8x8 Work for Desktop 7.3 8x8 Work for Desktop 7.4 8x8 Work for Desktop 7.5 8x8 Work for Desktop 7.6 8x8 Work for Desktop 7.7 A.N.D. Technologies Pcounter 2.85 A9Tech A9CAD 1.0 AbacusNext HotDocs Server Management Tools 10.2 AbacusNext HotDocs Server 10.2 ABB RobotStudio 2020.2 ABB RobotStudio 2020.4 ABB Drive composer pro 2.0 ABB Drive -

Computer Security Handbook Computer Security Handbook
COMPUTER SECURITY HANDBOOK COMPUTER SECURITY HANDBOOK Fifth Edition Volume 1 Edited by SEYMOUR BOSWORTH M.E. KABAY ERIC WHYNE John Wiley & Sons, Inc. Copyright C 2009 by John Wiley & Sons, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-646-8600, or on the web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, 201-748-6011, fax 201-748-6008, or online at http://www.wiley.com/go/permissions. Limit of Liability/Disclaimer of Warranty: While the publisher, editors, and the authors have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. No warranty may be created or extended by sales representatives or written sales materials. The advice and strategies contained herein may not be suitable for your situation. You should consult with a professional where appropriate. -

UNITED NATIONS SYSTEM Annual Statistical Report 2006
Annual Statistical Report 2006 • Procurement of Goods & Services • All Sources of Funding • Procurement from DAC Member Countries • International & National Project Personnel • United Nations Volunteers • Fellowships Published: July 2007 by UNITED NATIONS SYSTEM Annual Statistical Report 2006 Procurement of Goods and Services • All Sources of Funding Procurement from DAC Member Countries International & National Project Personnel United Nations Volunteers Fellowships July 2007 Copyright © 2007 by the United Nations Development Programme 1 UN Plaza, New York, NY 10017, USA All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic, photocopying, recording or otherwise, without prior permission of UNDP/IAPSO. TABLE OF CONTENTS INTRODUCTION .................................................................................................................... 1 GLOASSARY OF TERMS ...................................................................................................... 2 EXECUTIVE SUMMARY: ALL SOURCES OF FUNDING (UN SYSTEM)............................ 3 PROCUREMENT OF GOODS AND SERVICES - ALL SOURCES OF FUNDING Procurement of goods by country of procurement and services by country of head office ................................................................................................... 8 Procurement by UN agency ....................................................................................... 11 Procurement of goods by country -

THE FOG of CYBER DEFENCE Eds
1 THE FOG OF CYBER DEFENCE Eds. Jari Rantapelkonen & Mirva Salminen National Defence University Department of Leadership and Military Pedagogy Publication Series 2 Article Collection n:o 10 Helsinki 2013 2 © National Defence University/Department of Leadership and Military Pedagogy ISBN 978–951–25–2430–3 ISBN 978–951–25–2431–0 (PDF) ISSN 1798–0402 Cover: Toni Tilsala/National Defence University Layout: Heidi Paananen/National Defence University Juvenes Print Oy Tampere 2013 3 CONTENTS Foreword ........................................................................................ 5 Summary ........................................................................................ 6 Jari Rantapelkonen & Mirva Salminen Introduction: Looking for an Understanding of Cyber ............. 14 Part I: Cyberspace Jari Rantapelkonen & Harry Kantola Insights into Cyberspace, Cyber Security, and Cyberwar in the Nordic Countries ...................................... 24 Topi Tuukkanen Sovereignty in the Cyber Domain ...................................... 37 Jari Rantapelkonen & Saara Jantunen Cyberspace, the Role of State, and Goal of Digital Finland .................................................................................. 46 Margarita Jaitner Exercising Power in Social Media ....................................... 57 Kari Alenius Victory in Exceptional War: The Estonian Main Narrative of the Cyber Attacks in 2007 ............................. 78 PART II: Cyber Security Anssi Kärkkäinen The Origins and the Future of Cyber Security in the Finnish -

CESG Directory of INFOSEC Assured Products
Important Information – Please Read THE DIRECTORY OF INFOSEC ASSURED PRODUCTS Users of this Directory must be aware that the most up-to-date version of Infosec Assured Products are available at www.cesg.gov.uk For current information on IA products and their usage please see the individual product entries using the product search facilities at www.cesg.gov.uk THIS DOCUMENT WAS CORRECT AT TIME OF PRODUCTION OCTOBER 2010 SECTION 1 SECTION 10 Introduction Operating Systems SECTION 2 SECTION 11 Access Control Protection Profiles SECTION 3 SECTION 12 Airwave Miscellaneous SECTION 4 SECTION 13 Communications TEMPEST SECTION 5 SECTION 14 Database Mobile Solutions SECTION 6 SECTION 15 Data Encryption IACS Scheme SECTION 16 SECTION 7 External Common Data-Erasure Criteria Scheme SECTION 17 SECTION 8 Index Firewalls Related Abbreviations SECTION 9 Networking Directory of Infosec Assured Products 2010 Page 1.2 For End Users… Products which have been certified by us, or by our partners This ‘Directory of Infosec Assured Products’ is a top-level around the world, offer end users ready-made assurance. guide listing all IT security products approved by CESG. The This allows the customer to determine whether the product Directory lists products by type, and in addition gives brief is appropriate for his needs. If assurance is required in a details of the means by which products are approved or system, then a range of packages, including IT Security certified, an overview of the products’ features, and the Health Check, is available. context in which they should be used. There is also a contact list of product vendors. -
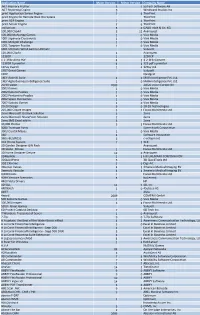
Application Name Major Version Minor Version Company Name .NET Memory Profiler 3 5 Scitech Software AB .NET Reporting Engine 8 Windward Studios Inc
Application Name Major Version Minor Version Company Name .NET Memory Profiler 3 5 SciTech Software AB .NET Reporting Engine 8 Windward Studios Inc. .print Application Server Engine 7 6 ThinPrint .print Engine for Remote Web Workplace ThinPrint .print RDP Engine 7 6 ThinPrint .print Server Engine 7 6 ThinPrint :milliarium 5 0 GABO mbH & Co. KG 100,000 ClipArt 3 12 Avanquest 100,000 Mahjongg Games 1 0 Viva Media 1001 Japanese Crosswords 1 0 Viva Media 1001 Minigolf Challenge 1 0 Viva Media 1001 Tangram Puzzles 1 0 Viva Media 1001 Ultimate Word Games Ultimate Valusoft 120,000 ClipArt 1 Avanquest 123BCP 1 123BCP 1-2-3File All to PDF 4 1 1-2-3FileConvert 123PDF Converter 4 1 123 pdf converter 12Pay Payroll 1 4 12Pay Ltd 1707 Great Games Valusoft 1ERP Quidgest 1KEY Agile BI Suite 2 0 MAIA Intelligence Pvt. Ltd. 1KEY Agile Business Intelligence Suite 1 0 MAIA Intelligence Pvt. Ltd. 20/20 vision 2009 20/20 vision Europe BV 2002 Games 1 0 Viva Media 2002 Kakuro Puzzles 1 0 Viva Media 2002 Pentamino Puzzles 1 0 Viva Media 2002 Space Out Games 1 0 Viva Media 2002 Sudoku Games 1 0 Viva Media 20-20 Design 9 0 20-20 Technologies 225,000 Clipart Images 3 2 Focus Multimedia Ltd. 2sms Microsoft Outlook Solution 3 2sms 2sms Microsoft SharePoint Solution 2 2sms 2sms SMS Excel add-in 3 2sms 30,000 Photos 3 1 Focus Multimedia Ltd. 3000 Truetype Fonts Summitsoft Corporation 3003 Crystal Mazes 1 0 Viva Media 360° 4 Software Innovation 360e-BUSINESS 3 e-velopment 3CX Phone System 7 1 3CX 3D Garden Designer Gift Pack Avanquest 3D Globe Deluxe 1 Focus Multimedia Ltd. -

Mcafee SIEM Supported Devices Updated September 2014
McAfee SIEM Supported Devices Updated September 2014 Version(s) Method of Vendor Name Device Type Parser ESM Version Supported Collection A10 Networks Load Balancer (ASP) Load Balancer All ASP Syslog 9.1 and greater Accellion Secure File Transfer (ASP) Application All ASP Syslog 9.1 and greater Access Layers Portnox (ASP) NAC 2.x ASP Syslog 9.1 and greater Bluesocket (ASP) Wireless Access Point All ASP Syslog 9.1.1 and greater Adtran NetVanta (ASP) Network Switches & Routers All ASP Syslog 9.1 and greater AirTight Networks SpectraGuard (ASP) Application All ASP Syslog 9.1 and greater NGN Switch (ASP) Switch All ASP Syslog 9.2 and greater Applications / Host / Server / Alcatel-Lucent VitalQIP (ASP) Operating Systems / Web Content / All ASP Syslog 9.1 and greater Filtering / Proxies American Power Conversion Uninterruptible Power Supply (ASP) Power Supplies All ASP Syslog 9.1 and greater Applications / Host / Server / Apache HTTP Server Operating Systems / Web Content / 1.x, 2.x Code Based Syslog 9.1 to 9.3.2 Filtering / Proxies Apache Software Foundation Applications / Host / Server / Apache Web Server (ASP) Operating Systems / Web Content / 1.x, 2.x ASP Syslog 9.1 and greater Filtering / Proxies Applications / Host / Server / Apple Inc. Mac OS X (ASP) Operating Systems / Web Content / All ASP Syslog 9.1 and greater Filtering / Proxies Peakflow SP (ASP) Network Switches & Routers 2.x and greater ASP Syslog 9.2 and greater Peakflow X Network Switches & Routers 2.x Code Based Syslog 9.1 to 9.3.2 Arbor Networks Peakflow X (ASP) Network Switches