Introduction to XSLT 3.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Priscilla Walmsley
Introduction to XQuery/Priscilla Walmsley Introduction to XQuery Priscilla Walmsley Managing Director, Datypic http://www.datypic.com [email protected] XML 2004 Conference November 15, 2004 1 Schedule • Morning Session – XQuery in Context – The Data Model – XQuery Syntax and Expressions • Afternoon Session – Advanced Queries (Sorting, Joining) – Functions and Modules – Types – Schemas © 2004 Datypic http://www.datypic.com Slide 2 1 Introduction to XQuery/Priscilla Walmsley XQuery in Context 3 W hat is XQuery? • A query language that allows you to: – select elements/attributes from input documents – join data from multiple input documents – make modifications to the data – calculate new data – add new elements/attributes to the results – sort your results © 2004 Datypic http://www.datypic.com Slide 4 2 Introduction to XQuery/Priscilla Walmsley XQuery Exam ple input document <order num="00299432" date="2004-09-15" cust="0221A"> <item dept="WMN" num="557" quant="1" color="tan"/> <item dept="ACC" num="563" quant="1"/> <item dept="ACC" num="443" quant="2"/> <item dept="MEN" num="784" quant="1" color="blue"/> <item dept="MEN" num="784" quant="1" color="red"/> quer<yitem dept="WMN" num="557" quant="1" color="sage"/> </ofrodre r$>d in distinct-values(doc("order.xml")//item/@dept) let $items := doc("order.xml")//item[@dept = $d] order by $d return <department name="{$d}" totalQuantity="{sum($items/@quant)}"/> <department name="ACC" totalQuantity="3"/> <department name="MEN" totalQuantity="2"/> results <departme© 2n00t4 Dantypaic mhttpe://=ww"w.WdaMtypNic.c"om -

XSLT in Context
XSLT in Context This chapter is designed to put XSLT in context. It's about the purpose of XSLT and the task it was designed to perform. It's about what kind of language it is, and how it came to be that way; and it's about how XSLT fits in with all the other technologies that you are likely to use in a typical web-based application. I won't be saying much in this chapter about what an XSLT stylesheet actually looks like or how it works: that will come later, in Chapters 2 and 3. I shall begin by describing the task that XSLT is designed to perform – transformation – and why there is the need to transform XML documents. I'll then present a trivial example of a transformation in order to explain what this means in practice. The chapter then moves on to discuss the relationship of XSLT to other standards in the growing XML family, to put its function into context and explain how it complements the other standards. I'll describe what kind of language XSLT is, and delve a little into the history of how it came to be like that. If you're impatient you may want to skip the history and get on with using the language, but sooner or later you will ask "why on earth did they design it like that?" and at that stage I hope you will go back and read about the process by which XSLT came into being. Finally, I'll have a few things to say about the different ways of using XSLT within the overall architecture of an application, in which there will inevitably be many other technologies and components each playing their own part. -

Xpath 2.0 in Context
P1: KTX WY030-01 WY030-Kay WY030-Kay-v3.cls July 7, 2004 15:52 XPath 2.0 in Context This chapter explains what kind of language XPath is, and some of the design thinking behind it. It explains how XPath relates to the other specifications in the growing XML family, and to describe what’s new in XPath 2.0 compared with XPath 1.0. The chapter starts with an introduction to the basic concepts behind the language, its data model and the different kinds of expression it supports. This is followed by a survey of new features, since I think it’s likely that many readers of this book will already have some familiarity with XPath 1.0. I also introduce a few software products that you can use to try out these new features. The central part of the chapter is concerned with the relationships between XPath and other languages and specifications: with XSLT, with XML itself and XML namespaces, with XPointer, with XQuery, and with XML Schema. It also takes a look at the way XPath interacts with Java and with the various document object models (DOM and its variations). The final section of the chapter tries to draw out the distinctive features of the language, the things that make XPath different. The aim is to understand what lies behind the peculiarities of the language, to get an appreciation for the reasons (sometimes good reasons and sometimes bad) why the language is the way it is. Hopefully, with this insight, you will be able to draw on the strengths of the language and learn to skirt round its weaker points. -

Building Workflow Applications with XML and Xquery
Building Workflow Applications with XML and XQuery By: Dr. Michael Kay In my previous articles, I introduced some of the mechanics of coding with XQuery and XSLT 2.0 — in a rapid progression from novice to advanced level I started with a brief ten-minute introduction to XQuery, went on from there to explore FLWOR expressions in some depth, and then exposed you to the wonderful benefits of writing schema-aware XSLT and XQuery code. In this article I'm going to stick with the assumption that you're a fast learner, and assume that you've now advanced beyond the coding level and are designing entire applications. (Actually, I don't really think of this as a hierarchy. Coders are the people who make the biggest difference to an IT system, which is why I decided five years ago after years of doing architecture and design that it was time to get back to coding. But application architecture is important too.) In this article I want to explore the role of XML in workflow applications. I'm using the term workflow in a very general kind of way, to describe applications that one can think of in terms of documents moving around a community of people who each perform particular tasks. Processing an insurance claim, or a bug report, or a capital requisition are examples that come to mind. Many processes in publishing can be viewed as workflow applications, and one also can use the idea for a spectrum of business processes from the very everyday (like processing an invoice or scheduling a meeting) to the very complex and soft (like acquiring another company). -
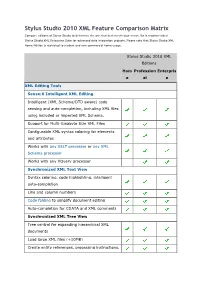
Stylus Studio 2010 XML Feature Comparison Matrix
Stylus Studio 2010 XML Feature Comparison Matrix Compare editions of Stylus Studio to determine the one that best meets your needs. Its is recommended Stylus Studio XML Enterprise Suite for advanced data integration projects. Please note that Stylus Studio XML Home Edition is restricted to student and non-commercial home usage. Stylus Studio 2010 XML Editions Hom Profession Enterpris e al e XML Editing Tools Sense:X Intelligent XML Editing Intelligent (XML Schema/DTD aware) code sensing and auto-completion, including XML files using included or imported XML Schema. Support for Multi -Gigabyte Size XML Files Configurable XML syntax coloring for elements and attributes Works with any XSLT processor or any XML Schema processor Works with any XQuery processor Synchronized XML Text View Syntax coloring, code highlighting, intelligent auto-completion Line and column numbers Code folding to simplify document editing Auto -completion for CDATA and XML comments Synchronized XML Tree View Tree control for expanding hierarchical XML documents Load large XML files (+10MB) Create entity references, processing instructions, comments, CDATA, toggle whitespace, and more Synchronized XML Grid View Export XML to Microsoft Excel Sort XML columns in ascending/descending order XML row operations: insert before/after, move up/down, delete Add nested XML table Rename XML element / attribute columns Use URIs to compare namespaces XML Differencing Visually compute differences between XML files in a Tree View Step through XML differences in fi les (Next, Previous) -

Integrated Development Environment for Xquery
XML PRODUCTIVITY THROUGH INNOVATION DATASHEET INTEGRATED DEVELOPMENT ENVIRONMENT FOR XQUERY, XML, XML SCHEMA AND XSLT KEY FEATURES > XQuery Mapper, Editor, and Overview Debugger Sonic Stylus Studio sets the benchmark for XML development productivity. > DB-to-XML Data Source Editor With over 100,000 users worldwide, Stylus Studio provides XML developers > Web Service Call Composer and data integration specialists with a comprehensive toolset for managing > XSLT Mapper, Editor, and Debugger XML data transformation and aggregation. > XML-to-HTML WYSIWYG Designer Whether you are working with latest XQuery specification or wrestling with > XML Schema Designer complex XSLT stylesheets, Stylus Studio is designed to make your life easier. > XML Editor We are committed to delivering productivity through innovation. Graphical > XQuery and XSLT Profilers mappers, code generators, unique back-mapping technology, integrated > Industry Schema Catalogs debugging, start-of-the-art profilers – all add up to the most advanced XML > Document Converters development environment available SUPPORTED STANDARDS > XQuery (W3C Nov 03 Spec) > XML, XML Schema, DTD > XPath 2.0 and XPath 1.0 > XSLT > XSL Formatting Objects > HTML, SVG The XQuery Mapper in Stylus Studio is an innovative visual programming tool for generating XQuery. Just draw the relationships between XML sources and targets, specify the integration logic, and Stylus Studio does the rest! “Stylus Studio is bar-none the best tool I have DB-TO-XML DATA SOURCE EDITOR seen for working with XML in all of its guises, Now you can use Stylus Studio to query and update relational data from building and debugging XQuery programs using the emerging SQL/XML standard. The DB-to-XML Data Source to graphically designing XSLT transformations editor, new for 5.1, lets you: for generating HTML, to designing and mapping > Define a data source for any one of several default relational databases, such as Oracle, DB2, SQL Server, and Informix. -

XSL Editor Prototype by Lindsay D. Grace a Proposal for a Final
XSL Editor Prototype by Lindsay D. Grace A proposal for a final project to be submitted in partial fulfillment of the requirements for the degree of Masters Degree in Computer Information Systems (MSCIS) Northwestern University 2003 Advisor: Dr. Chang Miao Submitted: August 13, 2003 2 Table of Contents Abstract Background: Problem Statement 1 Overview of Technologies 3 XML Fundamentals 6 XML Syntax Fundamentals 5 XML Validity 7 XSL 7 XPath 8 XML Schema Fundamentals 9 XML Parsers 10 DTD 11 XML Schema 11 Document Object Model 12 Simple API for XML 13 XHTML 14 Ancillary Technologies 16 Relevance and Significance of Research 18 The Solution Described 18 Comparison of Related Products 19 XML Spy Stylevision 23 Sonic Stylus Studio 25 Open Source Initiatives 27 Product Benefits 29 Research Findings and Design 33 Software Design 33 XML Data Source 33 Microsoft Component Object Model 35 The Implementation 37 Product Description 40 Graphical User Interface Design 40 3 Building the Graphic Design Elements 46 Using the Program 48 Using the Editor: Basic Walkthrough 52 Research Findings and Limitations 54 Test Case Scenarios and Descriptions 54 Creating a New File 54 Editing an Existing File 55 Limitations in Scope Design and Development 57 Implementation 65 Summary 69 Project Source Code Appendix A Annotated Bibliography 4 List of Figures Table Page Table1: Core Goals of XML 5 Figures Page Figure 1: Sample of Well:Formed XML 6 Figure 2: Sample of XML, not Well Formed 6 Figure 3: Screen Shot of XMLSpy® IDE 19 Figure 4: Screen Shot of StyleVision™ -

Zapthink Zapnote™
zapthink zapnote Doc. ID: ZTZN-1189 Released: Mar. 15, 2006 ZAPTHINK ZAPNOTE™ DATADIRECT SIMPLIFYING DATA INTEGRATION WITH XQUERY Analyst: Ronald Schmelzer Abstract The more companies attempt to connect their disparate systems in the enterprise, and the more success they have doing so using emerging technologies and approaches such as XML, Web Services, and Service- Oriented Architecture (SOA), the more they realize that simply getting systems to communicate is only half the problem. The other half is getting those systems to understand what they are saying to each other. While many people pin their hopes on abstract concepts such as semantic webs and ontologies, they require a more practical short-term solution to enable humans to map data structures between dissimilar systems. Fortunately, the W3C standard XQuery has recently emerged as a robust technology that is well suited for common data integration needs. Rather than using proprietary data adapters, tightly-coupled integration middleware, or complex mapping technologies, the XQuery approach applies standards-based documents and general-purpose transformation engines to the problem of data integration. In this ZapNote, we explore XQuery and DataDirect XQueryTM as an illustration of this powerful technique in practice. All Contents Copyright © 2006 ZapThink, LLC. All rights reserved. Reproduction of this publication in any form without prior written permission is forbidden. The information contained herein has been obtained from sources believed to be reliable. ZapThink disclaims all warranties as to the accuracy, completeness or adequacy of such information. ZapThink shall have no liability for errors, omissions or inadequacies in the information contained herein or for interpretations thereof. -
Learn Xquery in 10 Minutes
Learn XQuery in 10 Minutes By: Dr. Michael Kay This article is for all those people who really want to know what XQuery is, but don't have the time to find out. We all know the problem: so many exciting new technologies, so little time to research them. To be honest, I hope that you'll spend more than ten minutes on it — but if you really have to leave that soon, I hope you'll learn something useful anyway. What is XQuery For? XQuery was devised primarily as a query language for data stored in XML form. So its main role is to get information out of XML databases — this includes relational databases that store XML data, or that present an XML view of the data they hold. Some people are also using XQuery for manipulating free-standing XML documents, for example, for transforming messages passing between applications. In that role XQuery competes directly with XSLT, and which language you choose is largely a matter of personal preference. In fact, some people like XQuery so much that they are even using it for rendering XML into HTML for presentation. That's not really the job XQuery was designed for, and I wouldn't recommend people to do that, but once you get to know a tool, you tend to find new ways of using it. Playing with XQuery The best way to learn about anything is to try it out. Two ways you can try out the XQuery examples in this article are: · Install Stylus Studio® - Then go to File > New > XQuery File.. -

Award-Winning Xml Development Environment
XML Productivity Through Innovation STYLUS STUDIO® X16 XML ENTERPRISE SUITE DATASHEET NEW IN STYLUS STUDIO® X16 XML ENTERPRISE SUITE AWARD-WINNING XML DEVELOPMENT ENVIRONMENT > Support for the Latest FOR ADVANCED DATA INTEGRATION Hardware > 64-bit Support > New SQL Editor Overview > New Generic Converter Stylus Studio® X16 XML Enterprise Suite raises the bar for productivity > Latest Saxon Release (9.7) in XML development tools. Approximately 2 Million XML developers and > Windows 10 Certified > User Interface and Experience data integration specialists turn to Stylus Studio’s comprehensive and Enhancements intuitive XML toolset to tackle today’s advanced XML data transformation KEY FEATURES and aggregation challenges. And you should, too! Winner of CRN > XML Editor Magazine’s Product of the Year Award, Dr. Dobb’s Jolt Productivity Award, > XQuery Tools and SOAWorld Readers’ Choice Award for the technical excellence > XML Differencing of its powerful yet easy to-use tools, Stylus Studio simplifies all XML > Java and Microsoft .Net Code Generation development tasks. Whether you are developing Web applications that > XSLT Mapper, Editor, and transform relational data to XML, leveraging legacy data in EDI, HL7, or Debugger other flat file formats like CSV, or wrestling with complex XSLT style sheets, > XQuery and XSLT Profilers > Data Conversion Tools Stylus Studio helps you realize the promise of existing and emerging XML > XML Pipeline technologies. From XQuery to XML Pipelines to Java or C# for .NET code > XML Publisher generation, Stylus Studio is the one XML IDE that does it all. > DataDirect XML Converters™ Support > DataDirect XQuery™ Support XML PIPELINE EDITOR > WSDL Editor > EDI HL7 and HTML Conversion Tools “DataDirect Technologies’ Stylus Studio XML Enterprise Suite offers tools that make XML easy to deploy, without any coding. -

Schema-Aware Queries and Stylesheets
Schema-Aware Queries and Stylesheets By: Dr. Michael Kay In the previous articles in this series I gave a basic introduction to XQuery and a more detailed overview of what you can achieve using XQuery FLWOR expressions. One of the most significant new features in the Stylus Studio 2006 edition is the introduction of support for handling schema-aware XSLT and XQuery. So in this article, that's going to be my focus. The examples in this article requires downloading and installing Stylus Studio 2006 edition, build 501f or later: this build includes Saxon 8.6.1, an XML schema-aware XSLT and XQuery processor. XML Schema-awareness is an optional feature. Not every product will support it, and not every query or stylesheet will use it. You might consider it to be an advanced feature, which will only be needed by the most demanding applications. However, I'd like to persuade you that schema-awareness in XSLT and XQuery is something that you should consider using all the time. It's similar to the situation with XML itself: you can create and manipulate XML documents without ever validating them against a DTD or schema, but many experts will tell you that that's not good practice in anything other than a throwaway use-once application. Similarly, you can write queries and stylesheets that don't use schema-aware features, but I think that you're losing something by doing that. "Queries and stylesheets" is a bit of a mouthful, and it's just one example of where XQuery and XSLT have different names for what's essentially the same concept. -

Xml Development Environment for Advanced Data Integration
XML PRODUCTIVITY THROUGH INNOVATION STYLUS STUDIO® 6 XML ENTERPRISE EDITION DATASHEET XML DEVELOPMENT ENVIRONMENT FOR ADVANCED DATA INTEGRATION NEW IN STYLUS STUDIO® 6 XML Overview ENTERPRISE EDITION Stylus Studio® 6 XML Enterprise Edition sets a new standard for productivity in XML > Java Code Generation development tools. With hundreds of thousands of users worldwide, Stylus Studio provides > EDI/EDIFACT to XML XML developers and data integration specialists with the most comprehensive toolset for > Advanced XSLT 2.0 Editor tackling today's advanced XML data transformation and aggregation challenges. and Debugger > Updated XQuery 1.0 Support Stylus Studio 6 XML Enterprise Edition is the latest release of our award-winning XML IDE. > XML Schema Editor With a proven track record of delivering XML productivity through innovation, Stylus Studio's > XML Grid View powerful yet easy-to-use tools will simplify your XML development tasks. Whether you are > Enhanced XML Mapping working with the latest XQuery specification, wrestling with complex XSLT stylesheets, or leveraging legacy data as XML in your enterprise applications, Stylus Studio helps you realize KEY FEATURES the promise of XML technologies. > XML Editor > XQuery Mapper, Editor, and Debugger > XML Differencing > DB-to-XML Data Source Editor > Web Service Call Composer > XSLT Mapper, Editor, and Debugger > XML-to-HTML WYSIWYG XSLT Designer > XQuery and XSLT Profilers > Industry Schema Catalogs > Document Converters Stylus Studio's innovative XQuery Mapper accelerates XQuery development with an intuitive visual programming environment featuring a synchronized XQuery source code view. Just draw the relationships between XML sources and targets, specify the ® integration logic, and Stylus Studio does the rest.