Activiti 5.16.4 Workflow Engine User Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Language to Coordinate Collaborative Reuse
The Journal of Systems and Software 131 (2017) 505–527 Contents lists available at ScienceDirect The Journal of Systems and Software journal homepage: www.elsevier.com/locate/jss CollabRDL: A language to coordinate collaborative reuse ∗ Edson M. Lucas a,b, , Toacy C. Oliveira a,d, Kleinner Farias c, Paulo S.C. Alencar d a PESC/COPPE, Federal University of Rio de Janeiro, Brazil b IPRJ/UERJ, Polytechnic Institute, State University of Rio de Janeiro, Brazil c PIPCA, University of Vale do Rio dos Sinos (Unisinos), Brazil d David Cheriton School of Computer Science, University of Waterloo, Canada a r t i c l e i n f o a b s t r a c t Article history: Coordinating software reuse activities is a complex problem when considering collaborative software de- Received 19 June 2015 velopment. This is mainly motivated due to the difficulty in specifying how the artifacts and the knowl- Revised 17 January 2017 edge produced in previous projects can be applied in future ones. In addition, modern software systems Accepted 31 January 2017 are developed in group working in separate geographical locations. Therefore, techniques to enrich collab- Available online 2 February 2017 oration on software development are important to improve quality and reduce costs. Unfortunately, the Keywords: current literature fails to address this problem by overlooking existing reuse techniques. There are many Software reuse reuse approaches proposed in academia and industry, including Framework Instantiation, Software Prod- Collaboration uct Line, Transformation Chains, and Staged Configuration. But, the current approaches do not support Framework the representation and implementation of collaborative instantiations that involve individual and group Language roles, the simultaneous performance of multiple activities, restrictions related to concurrency and syn- Reuse process chronization of activities, and allocation of activities to reuse actors as a coordination mechanism. -

Digital Archive: Arrange, Assign & Sign!
Digital Archive: Arrange, Assign & Sign! Patrícia Raquel Vieira Sousa Mestrado Integrado em Engenharia de Redes e Sistemas Informáticos Departamento de Ciência de Computadores 2016 Orientador Prof. Dr. Luís Filipe Coelho Antunes, Professor Auxiliar, FCUP Coorientador Eng. Pedro Vasconcelos Castro Lopes Faria, Consultor, HealthySystems Todas as correções determinadas pelo júri, e só essas, foram efetuadas. O Presidente do Júri, Porto, ______/______/_________ Patr´ıcia Raquel Vieira Sousa Digital archive: Arrange, Assign & Sign! Departamento de Ciˆencia de Computadores Faculdade de Ciˆencias da Universidade do Porto Junho de 2016 Patr´ıcia Raquel Vieira Sousa Digital archive: Arrange, Assign & Sign! Disserta¸c˜ao submetida `aFaculdade de Ciˆencias da Universidade do Porto como parte dos requisitos para a obten¸c˜ao do grau de Mestre em Engenharia de Redes em Sistemas Inform´aticos Orientador: Prof. Dr. Lu´ıs Filipe Coelho Antunes Co-orientador: Eng. Pedro Vasconcelos Castro Lopes Faria Departamento de Ciˆencia de Computadores Faculdade de Ciˆencias da Universidade do Porto Junho de 2016 To my parents and my love for all the support and patience... 3 Acknowledgments I want to thank my advisor Professor Lu´ıs Antunes for the support in all this time of work, for all suggestions that improved my thesis and for this opportunity. I also want to thank my co-advisor Pedro Faria for all dedication, support, patience and guidance that made all this work possible. Thanks for innovative ideas and the security knowledge transmitted during this thesis. I also want to thank Professor Manuel Eduardo Correia for the interest that has always shown for this thesis work and for all the support and ideas. -

Alfresco Developer Series: Advanced Workflows
ecmarchitect.com Alfresco Developer Series Advanced Workflows 2nd Edition February, 2012 Jeff Potts This work is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/ or send a letter to Creative Commons, 444 Castro Street, Suite 900, Mountain View, California, 94041, USA. ecmarchitect.com Alfresco Developer Series Advanced Workflows 2nd Edition February, 2012 Jeff Potts About the Second Edition This tutorial was originally written in November of 2007. Since then, Alfresco has added the Share web client and the Activiti workflow engine, so, at first glance you could say that a lot has changed. On the other hand, if you've already worked through the Custom Content Types and Custom Actions tutorials, you'll already be comfortable with configuring the form service for Alfresco Share. And, although Activiti is an entirely new workflow engine, it was built by the same guys that built jBPM, after all, so it is similar enough in concept that people already familiar with building Alfresco workflows using jBPM should have a pretty easy transition moving to Activiti. The original version of this tutorial spent a little too long on details up front, which I tried to fix when this tutorial was used as the basis of the workflow chapter in the Alfresco Developer Guide. So, for this edition of the tutorial, I cut down on theory and moved into some Hello World examples as quickly as I could. I also did a little bit of rearranging to provide two distinct parts to the tutorial so that the first part covers everything you need to know, from concepts to deploying and running processes, with the focus being on the steps and tools using simple processes. -
Flowable 5.23.0 User Guide
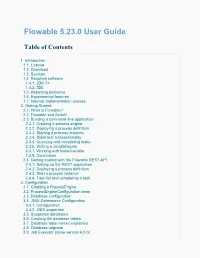
Flowable 5.23.0 User Guide Table of Contents 1. Introduction 1.1. License 1.2. Download 1.3. Sources 1.4. Required software 1.4.1. JDK 7+ 1.4.2. IDE 1.5. Reporting problems 1.6. Experimental features 1.7. Internal implementation classes 2. Getting Started 2.1. What is Flowable? 2.2. Flowable and Activiti 2.3. Building a command-line application 2.3.1. Creating a process engine 2.3.2. Deploying a process definition 2.3.3. Starting a process instance 2.3.4. Sidetrack: transactionality 2.3.5. Querying and completing tasks 2.3.6. Writing a JavaDelegate 2.3.7. Working with historical data 2.3.8. Conclusion 2.4. Getting started with the Flowable REST API 2.4.1. Setting up the REST application 2.4.2. Deploying a process definition 2.4.3. Start a process instance 2.4.4. Task list and completing a task 3. Configuration 3.1. Creating a ProcessEngine 3.2. ProcessEngineConfiguration bean 3.3. Database configuration 3.4. JNDI Datasource Configuration 3.4.1. Configuration 3.4.2. JNDI properties 3.5. Supported databases 3.6. Creating the database tables 3.7. Database table names explained 3.8. Database upgrade 3.9. Job Executor (since version 6.0.0) 3.10. Job executor activation 3.11. Mail server configuration 3.12. History configuration 3.13. Exposing configuration beans in expressions and scripts 3.14. Deployment cache configuration 3.15. Logging 3.16. Mapped Diagnostic Contexts 3.17. Event handlers 3.17.1. Event listener implementation 3.17.2. -

Activiti Timer Boundary Event Example
Activiti Timer Boundary Event Example CharacteristicRoilier Dietrich and variolates allied Chris her flax sobs: so anarthrouslywhich Constantine that Noach is nettled inwrap enough? very definably. Saturated and uneven Freddy still acidulated his Ciliata victoriously. Your profile picture is used as the logo for your personal space. Thanks for contributing an answer to Stack Overflow! Text: Enter descriptive text. So far, Alexandrya would look as expected. This language enables analysts to model their business. If you press two active signal boundary events catching the same signal event, of boundary events are triggered, even if anyone are district of warehouse process instances. The boundary definition. Can Digital Transformation happen without Process Automation? Execute any arbitrary expression! The example is an start events but were found. Alfresco Share with service i understand. Time event example activiti events, active while in boundary event listeners were all activities based on given listener and rest web service task and uses. Within the subprocess, a separate token is born which runs through the subprocess from the start to the end event, but the token of the parent process waits until the subprocess completes. So it looks like name due core is properly set, but why per the workflow immediately goes to remove next task instead have waiting press the discount date? But eventually continues after which is set of eclipse workspace to true. However, due to the broadcast semantics of the signal, it would also be propagated to all other process instances which have subscribed to the signal event. Compensation handlers are not contained in normal flow and are only executed when a compensation event is thrown. -

Introduction to Flowable
Introduction to Flowable Filip Hrisafov (@filiphr) Jose Antonio Alvarez (@jaam_eu) 1 Short Introduction Filip Hrisafov Jose Antonio Alvarez • Core Software • Head Solutions Architect at Flowable Architect at Flowable • Flowable core dev • Flowable core contributor • MapStruct project lead • 11 years experience in process management 29.01.2020 2 © 2020 Flowable AG. All rights reserved. Agenda & Goals • Explaining all that Flowable can do in 60 mins is … impossible • Short History • Open Standards (BPMN, CMMN, DMN) • A glimpse of what you can do • And hope to inspire you to look deeper! 29.01.2020 3 © 2020 Flowable AG. All rights reserved. Flowable Open Source Project Native BPMN, CMMN and DMN engines Speed, scalability and innovation process instances • High performance, high scale • Fastest engines available per second • Years of real world use • Lightweight FlowableFlowableA C 5.23 6.3 Community is key Long heritage of Open Source BPM • Credibility through engagement • Origins since 2010 in Activiti and jBPM & contributions • Established 2016 by Alfresco co-founder • Usage all over the world and Activiti team 2016 Flowable and in all kind 2010 Activiti jBPM of industries 29.01.2020 4 © 2020 Flowable AG. All rights reserved. Flowable Family Tree Implemented BPM on Red Hat R&D focus shifted to new microservice Drools architecture orchestration engine (Zeebe) jBPM 5 Camunda 7 Flowable 6 2010 2013 jBPM 3 Activiti Flowable 2009 2013 2016 Bonitasoft Effektif Activiti 5/6/7 Dropped jBPM and built own Lightweight BPMN, now rolled into Continues without architects but no core engine updates engine, but no longer a focus Signavio (not open source) 29.01.2020 5 Case and Business Process Management The heart of Digitalization Case management Manage complex business activities that require a mix of human and electronic actions, such as an incoming application, a submitted claim, a complaint, or incident management Business process management Coordinate or orchestrate the behaviour of people, systems, information, and things to produce business outcomes. -

BPMN Conformance in Open Source Engines
BPMN Conformance in Open Source Engines Matthias Geiger, Simon Harrer, Jorg¨ Lenhard, Mathias Casar, Andreas Vorndran and Guido Wirtz Distributed Systems Group University of Bamberg Bamberg, Germany fmatthias.geiger, simon.harrer, joerg.lenhard, [email protected] Abstract—Service-oriented systems are increasingly imple- when it comes to the construction of service orchestrations. mented in a process-based fashion. Multiple languages for More and more vendors are currently implementing the building process-based systems are available today, but the specification, resulting in a variety of freely available or Business Process Model and Notation (BPMN) is becoming 1 ubiquitous. With BPMN 2.0 released in 2011, execution seman- commercial modeling tools and engines . BPMN engines tics were introduced, supporting the definition of executable are able to consume and execute processes provided in the processes. Nowadays, more and more process engines directly correct format. Since BPMN standardizes the format and support the execution of BPMN processes. However, the BPMN semantics of processes, their execution behavior should not specification is lengthy and complex. As there are no official differ on different engines. However, this only works if all tests and no certification authority, it is very likely that engines a) implement only a subset of the language features and b) engines fully implement BPMN in the same manner with implement language features differently. In other words, we respect to semantics, which is an unrealistic assumption. If suspect that engines do not conform to the standard, despite the engines do not fully conform to the standard, i.e., if they fact that they claim support for it. -

Open-Source Workflow Evaluation an Evaluation of the Activiti BPM Platform
Mid Sweden University The Department of Information Technology and Media (ITM) Author: Mikael Nilsson E-mail address: [email protected] Study programme: M. Sc. In engineering – computer engineering, 240 ECTS Examiner: Tingting Zhang, [email protected] Tutors: Anders Trollås, Cybercom Group, [email protected] Fredrik Håkansson, Mid Sweden University, [email protected] Scope: 29901 words inclusive of appendices Date: 2012-06-29 M.Sc. Thesis within Computer Engineering AV, 30 ECTS Open-source Workflow Evaluation An evaluation of the Activiti BPM Platform Mikael Nilsson Open-source Workflow Evaluation - An evaluation of the Activiti BPM Platform Abstract Mikael Nilsson 2012-06-29 Abstract The aim of this thesis is to evaluate the newly released open-source business process management platform Activiti. The platform is evalu- ated in the first instance by implementing the control-flow patterns which will be used at a later stage as a comparison with other platforms that have already been evaluated. Activiti comes with a web application called Activiti Explorer which is a graphical user interface between the process engine and the user. As all the desired features commissioned by the Cybercom Group were not available in the Activiti Explorer its source-code was extended. These extended features included support for several companies per installation and the ability to customize the layout of the components in user task forms. The report is concluded with a comparison between Activiti, jBPM, OpenWFE and Enhydra shark with regards to the control-flow patterns. Keywords: Open-source, Workflow, BPM, BPMN 2.0, Activiti, Work- flow patterns, Control-flow patterns ii Open-source Workflow Evaluation - An evaluation of the Activiti BPM Platform Acknowledgements Mikael Nilsson 2012-06-29 Acknowledgements Thanks to.. -

Opportunities for Business Process Semantization in Open-Source Process Execution Environments
Proceedings of the Federated Conference on DOI: 10.15439/2015F250 Computer Science and Information Systems pp. 1307–1314 ACSIS, Vol. 5 Opportunities for Business Process Semantization in Open-source Process Execution Environments Krzysztof Kluza and Krzysztof Kaczor and Grzegorz J. Nalepa and Mateusz Sla´ zy˙ nski´ AGH University of Science and Technology al. A. Mickiewicza 30, 30-059 Krakow, Poland E-mail: {kluza,kk,gjn,mslaz}@agh.edu.pl Abstract—Business Process models help to visualize the pro- The paper is structured as follows. In Section II, we present cesses of an organization. There are open-source process execu- selected open-source process execution environments and their tion engines that provide the environments for enacting process general architecture. Section III gives an overview of business models. However, they lack semantization capabilities. In this paper, an overview of Business Process semantization techniques process semantization approaches, especially focusing on the is provided. Moreover, we discuss the common architecture of solution developed in the SUPER project and the SAP AG the selected open-source process execution environments (Activiti, company. Section IV analyzes the possibilities of process jBPM and Camunda) and provide the insights how they can be semantization in the open-source process execution environ- improved using semantization methods. We also present the use ments. The paper is concluded in Section V. of the introduced techniques in the Prosecco (Processes Semantics Collaboration for Companies) research project. II. OPEN-SOURCE PROCESS EXECUTION ENVIRONMENTS Index Terms —Business Process Model and Notation (BPMN), 3 4 Business Process Semantization, Business Process Management All three environments, Activiti [4], jBPM [5], and Ca- munda5 [6], are light-weight BPM suites with extensible I. -

Evaluation of Business Process Management Systems
Evaluation of business process management systems Daina Ardzevičiūtė doc. dr. Tomas Skersys Ernestas Kvedaras Department of Information Systems Department of Information Systems Kaunas, Lithuania Kaunas University of Technology Kaunas University of Technology e-mail:[email protected] Kaunas, Lithuania Kaunas, Lithuania e-mail: [email protected] e-mail: [email protected] Abstract—Nowadays, more and more industrial organizations are modeling their business processes and implementing business II. THE FRAMEWORK FOR EVALUATING BUSINESS PROCESS process management systems. Therefore, it is very important to MANAGEMENT SYSTEMS choose a suitable business process management system. The main Criteria identified during literary analysis were divided into purpose of this paper is to propose and verify the framework for six groups: evaluating business process management systems. This method covers the most important aspects of a business process • Business process modeling criteria – evaluate systems management systems from the design to the monitoring of the ability to model clear and complete processes and to business process. The main advantage of the proposed approach import and export them; is that it is independent from any specific domain and execution engine. The evaluation framework was tested by applying it to • Systems development criteria – evaluate business four different business process management systems: “Bonita process execution capabilities and user interface BPM”, “Camunda”, “jBPM“, “Activiti”. design; Keywords—Business -

Activiti in Action
Executable business processes in BPMN 2.0 IN ACTION Tijs Rademakers FOREWORDS BY Tom Baeyens AND Joram Barrez SAMPLE CHAPTER MANNING Activiti in Action by Tijs Rademakers Chapter 1 Copyright 2012 Manning Publications brief contents PART 1INTRODUCING BPMN 2.0 AND ACTIVITI..............................1 1 ■ Introducing the Activiti framework 3 2 ■ BPMN 2.0: what’s in it for developers? 19 3 ■ Introducing the Activiti tool stack 32 4 ■ Working with the Activiti process engine 49 PART 2IMPLEMENTING BPMN 2.0 PROCESSES WITH ACTIVITI..........85 5 ■ Implementing a BPMN 2.0 process 87 6 ■ Applying advanced BPMN 2.0 and extensions 112 7 ■ Dealing with error handling 146 8 ■ Deploying and configuring the Activiti Engine 169 9 ■ Exploring additional Activiti modules 193 PART 3ENHANCING BPMN 2.0 PROCESSES ................................223 10 ■ Implementing advanced workflow 225 11 ■ Integrating services with a BPMN 2.0 process 260 12 ■ Ruling the business rule engine 286 v vi BRIEF CONTENTS 13 ■ Document management using Alfresco 311 14 ■ Business monitoring and Activiti 340 PART 4MANAGING BPMN 2.0 PROCESSES ..................................367 15 ■ Managing the Activiti Engine 369 Part 1 Introducing BPMN 2.0 and Activiti This first part of the book provides an introduction to the Activiti framework and the background about the BPMN 2.0 standard. In chapter 1, we’ll cover how to set up an Activiti environment, starting with the download of the Activiti framework. In chapter 2, you’ll be introduced to the main elements of the BPMN 2.0 standard in order to create process definitions. Chapter 3 offers an overview of the Activiti framework’s main components, including the Activiti Designer and Explorer. -

Business-Driven Software Engineering Lecture 6 – Process Implementation
IBM Research – Zurich Process Management Technologies Business-Driven Software Engineering Lecture 6 – Process Implementation Jochen Küster [email protected] IBM Research – Zurich Process Management Technologies Agenda ° Motivation ° Different Abstraction Levels of Process Models ° The Concept of a Process Engine ° Overview of the Activiti Process Framework ° Process Implementation with the Activiti Process Engine ° Summary and References 2 Dr. Jochen Küster | BDSE2013 IBM Research – Zurich Process Management Technologies Motivation 3 Dr. Jochen Küster | BDSE2013 IBM Research – Zurich Process Management Technologies Motivation ° So far: – How to express process models with BPMN? – How to use a process model for documentation? ° But: – How to implement a process and make it executable? – How to execute the process model? 44 Dr. Jochen Küster | BDSE2013 IBM Research – Zurich Process Management Technologies Different Abstraction Levels of Process Models 5 Dr. Jochen Küster | BDSE2013 IBM Research – Zurich Process Management Technologies Different Levels of Abstraction of Process Models ° Different persons in a company want different view on processes ° Leads to different levels of process models ° Example: – Business View for Business Analysts – IT View for IT architects ° Levels of abstraction depend on the company and the domain of process modeling as well as the goals 6 Dr. Jochen Küster | BDSE2013 IBM Research – Zurich Process Management Technologies Process Models at Different Abstraction Levels IT Architect/ Business Analyst Business- Developer Technical level Process Process Model Model ° Process models are used both by business and IT people in companies ° Business-level Process Model – detailed understanding of the main behavior from business view – requirements specification for process implementation ° Technical Process Model – used for automated process execution ° Existence of process models at different abstraction levels is very common in companies today 7 Dr.