Red Hat Jboss Enterprise Application Platform 7.3 Developing Hibernate Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Beej's Guide to Unix IPC
Beej's Guide to Unix IPC Brian “Beej Jorgensen” Hall [email protected] Version 1.1.3 December 1, 2015 Copyright © 2015 Brian “Beej Jorgensen” Hall This guide is written in XML using the vim editor on a Slackware Linux box loaded with GNU tools. The cover “art” and diagrams are produced with Inkscape. The XML is converted into HTML and XSL-FO by custom Python scripts. The XSL-FO output is then munged by Apache FOP to produce PDF documents, using Liberation fonts. The toolchain is composed of 100% Free and Open Source Software. Unless otherwise mutually agreed by the parties in writing, the author offers the work as-is and makes no representations or warranties of any kind concerning the work, express, implied, statutory or otherwise, including, without limitation, warranties of title, merchantibility, fitness for a particular purpose, noninfringement, or the absence of latent or other defects, accuracy, or the presence of absence of errors, whether or not discoverable. Except to the extent required by applicable law, in no event will the author be liable to you on any legal theory for any special, incidental, consequential, punitive or exemplary damages arising out of the use of the work, even if the author has been advised of the possibility of such damages. This document is freely distributable under the terms of the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. See the Copyright and Distribution section for details. Copyright © 2015 Brian “Beej Jorgensen” Hall Contents 1. Intro................................................................................................................................................................1 1.1. Audience 1 1.2. Platform and Compiler 1 1.3. -

Mmap and Dma
CHAPTER THIRTEEN MMAP AND DMA This chapter delves into the area of Linux memory management, with an emphasis on techniques that are useful to the device driver writer. The material in this chap- ter is somewhat advanced, and not everybody will need a grasp of it. Nonetheless, many tasks can only be done through digging more deeply into the memory man- agement subsystem; it also provides an interesting look into how an important part of the kernel works. The material in this chapter is divided into three sections. The first covers the implementation of the mmap system call, which allows the mapping of device memory directly into a user process’s address space. We then cover the kernel kiobuf mechanism, which provides direct access to user memory from kernel space. The kiobuf system may be used to implement ‘‘raw I/O’’ for certain kinds of devices. The final section covers direct memory access (DMA) I/O operations, which essentially provide peripherals with direct access to system memory. Of course, all of these techniques requir e an understanding of how Linux memory management works, so we start with an overview of that subsystem. Memor y Management in Linux Rather than describing the theory of memory management in operating systems, this section tries to pinpoint the main features of the Linux implementation of the theory. Although you do not need to be a Linux virtual memory guru to imple- ment mmap, a basic overview of how things work is useful. What follows is a fairly lengthy description of the data structures used by the kernel to manage memory. -

An Introduction to Linux IPC
An introduction to Linux IPC Michael Kerrisk © 2013 linux.conf.au 2013 http://man7.org/ Canberra, Australia [email protected] 2013-01-30 http://lwn.net/ [email protected] man7 .org 1 Goal ● Limited time! ● Get a flavor of main IPC methods man7 .org 2 Me ● Programming on UNIX & Linux since 1987 ● Linux man-pages maintainer ● http://www.kernel.org/doc/man-pages/ ● Kernel + glibc API ● Author of: Further info: http://man7.org/tlpi/ man7 .org 3 You ● Can read a bit of C ● Have a passing familiarity with common syscalls ● fork(), open(), read(), write() man7 .org 4 There’s a lot of IPC ● Pipes ● Shared memory mappings ● FIFOs ● File vs Anonymous ● Cross-memory attach ● Pseudoterminals ● proc_vm_readv() / proc_vm_writev() ● Sockets ● Signals ● Stream vs Datagram (vs Seq. packet) ● Standard, Realtime ● UNIX vs Internet domain ● Eventfd ● POSIX message queues ● Futexes ● POSIX shared memory ● Record locks ● ● POSIX semaphores File locks ● ● Named, Unnamed Mutexes ● System V message queues ● Condition variables ● System V shared memory ● Barriers ● ● System V semaphores Read-write locks man7 .org 5 It helps to classify ● Pipes ● Shared memory mappings ● FIFOs ● File vs Anonymous ● Cross-memory attach ● Pseudoterminals ● proc_vm_readv() / proc_vm_writev() ● Sockets ● Signals ● Stream vs Datagram (vs Seq. packet) ● Standard, Realtime ● UNIX vs Internet domain ● Eventfd ● POSIX message queues ● Futexes ● POSIX shared memory ● Record locks ● ● POSIX semaphores File locks ● ● Named, Unnamed Mutexes ● System V message queues ● Condition variables ● System V shared memory ● Barriers ● ● System V semaphores Read-write locks man7 .org 6 It helps to classify ● Pipes ● Shared memory mappings ● FIFOs ● File vs Anonymous ● Cross-memoryn attach ● Pseudoterminals tio a ● proc_vm_readv() / proc_vm_writev() ● Sockets ic n ● Signals ● Stream vs Datagram (vs uSeq. -
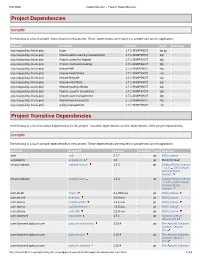
Project Dependencies Project Transitive Dependencies
9/8/2020 Dependencies – Project Dependencies Project Dependencies compile The following is a list of compile dependencies for this project. These dependencies are required to compile and run the application: GroupId ArtifactId Version Type Licenses org.onap.policy.drools-pdp base 1.7.1-SNAPSHOT tar.gz - org.onap.policy.drools-pdp feature-active-standby-management 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-controller-logging 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-distributed-locking 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-eelf 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-healthcheck 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-lifecycle 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-mdc-filters 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-pooling-dmaap 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-session-persistence 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-state-management 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-test-transaction 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp policy-management 1.7.1-SNAPSHOT zip - Project Transitive Dependencies The following is a list of transitive dependencies for this project. Transitive dependencies are the dependencies of the project dependencies. compile The following is a list of compile dependencies for this project. These dependencies are required to compile and run the application: GroupId ArtifactId Version Classifier Type Licenses antlr antlr 2.7.7 - jar BSD License -

Jakarta Enhancement Guide (V6.0) Table of Contents
Jakarta Enhancement Guide (v6.0) Table of Contents Maven . 3 Ant . 5 Command Line . 7 Runtime Enhancement . 9 Programmatic API . 10 Enhancement Contract Details . 11 Persistable . 11 Byte-Code Enhancement Myths . 12 Cloning of enhanced classes . 12 Serialisation of enhanced classes. 12 Decompilation. 13 DataNucleus requires that all Jakarta entities implement Persistable and Detachable. Rather than requiring that a user add this themself, we provide an enhancer that will modify your compiled classes to implement all required methods. This is provided in datanucleus-core.jar. • The use of this interface means that you get transparent persistence, and your classes always remain your classes; ORM tools that use a mix of reflection and/or proxies are not totally transparent. • DataNucleus' use of Persistable provides transparent change tracking. When any change is made to an object the change creates a notification to DataNucleus allowing it to be optimally persisted. ORM tools that dont have access to such change tracking have to use reflection to detect changes. The performance of this process will break down as soon as you read a large number of objects, but modify just a handful, with these tools having to compare all object states for modification at transaction commit time. • OpenJPA requires a similar bytecode enhancement process also, and EclipseLink and Hibernate both allow it as an option since they also now see the benefits of this approach over use of proxies and reflection. In the DataNucleus bytecode enhancement contract there are 3 categories of classes. These are Entity, PersistenceAware and normal classes. The Meta-Data (XML or annotations) defines which classes fit into these categories. -

Licensing Information User Manual Release 21C (21.1) F37966-01 March 2021
Oracle® Zero Downtime Migration Licensing Information User Manual Release 21c (21.1) F37966-01 March 2021 Introduction This Licensing Information document is a part of the product or program documentation under the terms of your Oracle license agreement and is intended to help you understand the program editions, entitlements, restrictions, prerequisites, special license rights, and/or separately licensed third party technology terms associated with the Oracle software program(s) covered by this document (the "Program(s)"). Entitled or restricted use products or components identified in this document that are not provided with the particular Program may be obtained from the Oracle Software Delivery Cloud website (https://edelivery.oracle.com) or from media Oracle may provide. If you have a question about your license rights and obligations, please contact your Oracle sales representative, review the information provided in Oracle’s Software Investment Guide (http://www.oracle.com/us/ corporate/pricing/software-investment-guide/index.html), and/or contact the applicable Oracle License Management Services representative listed on http:// www.oracle.com/us/corporate/license-management-services/index.html. Licensing Information Third-Party Notices and/or Licenses About the Third-Party Licenses The third party licensing information in Oracle Database Licensing Information User Manual, Third-Party Notices and/or Licenses and Open Source Software License Text, applies to Oracle Zero Downtime Migration. The third party licensing information included in the license notices provided with Oracle Linux applies to Oracle Zero Downtime Migration. Open Source or Other Separately Licensed Software Required notices for open source or other separately licensed software products or components distributed in Oracle Zero Downtime Migration are identified in the following table along with the applicable licensing information. -

Table of Contents
TABLE OF CONTENTS Chapter 1 Introduction ............................................................................................. 3 Chapter 2 Examples for FPGA ................................................................................. 4 2.1 Factory Default Code ................................................................................................................................. 4 2.2 Nios II Control for Programmable PLL/ Temperature/ Power/ 9-axis ....................................................... 6 2.3 Nios DDR4 SDRAM Test ........................................................................................................................ 12 2.4 RTL DDR4 SDRAM Test ......................................................................................................................... 14 2.5 USB Type-C DisplayPort Alternate Mode ............................................................................................... 15 2.6 USB Type-C FX3 Loopback .................................................................................................................... 17 2.7 HDMI TX and RX in 4K Resolution ........................................................................................................ 21 2.8 HDMI TX in 4K Resolution ..................................................................................................................... 26 2.9 Low Latency Ethernet 10G MAC Demo .................................................................................................. 29 2.10 Socket -

IPC: Mmap and Pipes
Interprocess Communication: Memory mapped files and pipes CS 241 April 4, 2014 University of Illinois 1 Shared Memory Private Private address OS address address space space space Shared Process A segment Process B Processes request the segment OS maintains the segment Processes can attach/detach the segment 2 Shared Memory Private Private Private address address space OS address address space space space Shared Process A segment Process B Can mark segment for deletion on last detach 3 Shared Memory example /* make the key: */ if ((key = ftok(”shmdemo.c", 'R')) == -1) { perror("ftok"); exit(1); } /* connect to (and possibly create) the segment: */ if ((shmid = shmget(key, SHM_SIZE, 0644 | IPC_CREAT)) == -1) { perror("shmget"); exit(1); } /* attach to the segment to get a pointer to it: */ data = shmat(shmid, (void *)0, 0); if (data == (char *)(-1)) { perror("shmat"); exit(1); } 4 Shared Memory example /* read or modify the segment, based on the command line: */ if (argc == 2) { printf("writing to segment: \"%s\"\n", argv[1]); strncpy(data, argv[1], SHM_SIZE); } else printf("segment contains: \"%s\"\n", data); /* detach from the segment: */ if (shmdt(data) == -1) { perror("shmdt"); exit(1); } return 0; } Run demo 5 Memory Mapped Files Memory-mapped file I/O • Map a disk block to a page in memory • Allows file I/O to be treated as routine memory access Use • File is initially read using demand paging ! i.e., loaded from disk to memory only at the moment it’s needed • When needed, a page-sized portion of the file is read from the file system -

A Machine-Independent DMA Framework for Netbsd
AMachine-Independent DMA Framework for NetBSD Jason R. Thorpe1 Numerical Aerospace Simulation Facility NASA Ames Research Center Abstract 1.1. Host platform details One of the challenges in implementing a portable In the example platforms listed above,there are at kernel is finding good abstractions for semantically- least three different mechanisms used to perform DMA. similar operations which often have very machine- The first is used by the i386 platform. This mechanism dependent implementations. This is especially impor- can be described as "what you see is what you get": the tant on modern machines which share common archi- address that the device uses to perform the DMA trans- tectural features, e.g. the PCI bus. fer is the same address that the host CPU uses to access This paper describes whyamachine-independent the memory location in question. DMA mapping abstraction is needed, the design consid- DMA address Host address erations for such an abstraction, and the implementation of this abstraction in the NetBSD/alpha and NetBSD/i386 kernels. 1. Introduction NetBSD is a portable, modern UNIX-likeoperat- ing system which currently runs on eighteen platforms covering nine processor architectures. Some of these platforms, including the Alpha and i3862,share the PCI busasacommon architectural feature. In order to share device drivers for PCI devices between different platforms, abstractions that hide the details of bus access must be invented. The details that must be hid- den can be broken down into twoclasses: CPU access Figure 1 - WYSIWYG DMA to devices on the bus (bus_space)and device access to host memory (bus_dma). Here we will discuss the lat- The second mechanism, employed by the Alpha, ter; bus_space is a complicated topic in and of itself, is very similar to the first; the address the host CPU and is beyond the scope of this paper. -

Metro User Guide Metro User Guide Table of Contents
Metro User Guide Metro User Guide Table of Contents Preface .............................................................................................................................. x 1. Introduction to Metro ....................................................................................................... 1 1.1. Required Software ................................................................................................ 1 1.2. What is WSIT? .................................................................................................... 1 1.2.1. Bootstrapping and Configuration ................................................................... 2 1.2.2. Message Optimization Technology ................................................................ 3 1.2.3. Reliable Messaging Technology .................................................................... 4 1.2.4. Security Technology ................................................................................... 4 1.3. How Metro Relates to .NET Windows Communication Foundation (WCF) ...................... 5 1.4. Metro Specifications ............................................................................................. 5 1.4.1. Bootstrapping and Configuration Specifications ............................................... 7 1.4.2. Message Optimization Specifications ............................................................. 8 1.4.3. Reliable Messaging Specifications ............................................................... 10 1.4.4. Security Specifications -

Jakarta Concurrency 2.0 Specification Document
Jakarta Concurrency Jakarta Concurrency Team, https://projects.eclipse.org/projects/ee4j.cu 2.0, 2020-10-08T19:20:31Z Table of Contents Eclipse Foundation Specification License . 1 Disclaimers. 2 Jakarta Concurrency Specification, Version 2.0 . 3 1. Introduction. 4 1.1. Overview . 4 1.2. Goals of this specification. 4 1.3. Other Java Platform and Jakarta Specifications . 4 1.4. Concurrency Utilities for Java EE Expert Group at the JCP . 5 1.5. Document Conventions. 5 2. Overview . 6 2.1. Container-Managed vs. Unmanaged Threads . 6 2.2. Application Integrity . 6 2.3. Container Thread Context . 7 2.3.1. Contextual Invocation Points. 8 2.3.1.1. Optional Contextual Invocation Points . 8 2.3.2. Contextual Objects and Tasks . 8 2.3.2.1. Tasks and Jakarta Contexts and Dependency Injection (CDI) . 9 2.4. Usage with Jakarta Connectors . 9 2.5. Security . 10 3. Managed Objects . 11 3.1. ManagedExecutorService. 11 3.1.1. Application Component Provider’s Responsibilities . 11 3.1.1.1. Usage Example. 12 3.1.2. Application Assembler’s Responsibilities . 18 3.1.3. Deployer’s Responsibilities. 18 3.1.4. Jakarta EE Product Provider’s Responsibilities. 18 3.1.4.1. ManagedExecutorService Configuration Attributes. 19 3.1.4.2. Configuration Examples . 19 3.1.4.3. Default ManagedExecutorService. 22 3.1.5. System Administrator’s Responsibilities. 22 3.1.6. Lifecycle . 22 3.1.6.1. Jakarta EE Product Provider Requirements . 23 3.1.7. Quality of Service . 24 3.1.8. Transaction Management. 24 3.1.8.1. Jakarta EE Product Provider Requirements . -

Interprocess Communication
06 0430 CH05 5/22/01 10:22 AM Page 95 5 Interprocess Communication CHAPTER 3,“PROCESSES,” DISCUSSED THE CREATION OF PROCESSES and showed how one process can obtain the exit status of a child process.That’s the simplest form of communication between two processes, but it’s by no means the most powerful.The mechanisms of Chapter 3 don’t provide any way for the parent to communicate with the child except via command-line arguments and environment variables, nor any way for the child to communicate with the parent except via the child’s exit status. None of these mechanisms provides any means for communicating with the child process while it is actually running, nor do these mechanisms allow communication with a process outside the parent-child relationship. This chapter describes means for interprocess communication that circumvent these limitations.We will present various ways for communicating between parents and chil- dren, between “unrelated” processes, and even between processes on different machines. Interprocess communication (IPC) is the transfer of data among processes. For example, a Web browser may request a Web page from a Web server, which then sends HTML data.This transfer of data usually uses sockets in a telephone-like connection. In another example, you may want to print the filenames in a directory using a command such as ls | lpr.The shell creates an ls process and a separate lpr process, connecting 06 0430 CH05 5/22/01 10:22 AM Page 96 96 Chapter 5 Interprocess Communication the two with a pipe, represented by the “|” symbol.A pipe permits one-way commu- nication between two related processes.The ls process writes data into the pipe, and the lpr process reads data from the pipe.