Optimizations Last Time • Loop Invariant
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Efficient Run Time Optimization with Static Single Assignment
i Jason W. Kim and Terrance E. Boult EECS Dept. Lehigh University Room 304 Packard Lab. 19 Memorial Dr. W. Bethlehem, PA. 18015 USA ¢ jwk2 ¡ tboult @eecs.lehigh.edu Abstract We introduce a novel optimization engine for META4, a new object oriented language currently under development. It uses Static Single Assignment (henceforth SSA) form coupled with certain reasonable, albeit very uncommon language features not usually found in existing systems. This reduces the code footprint and increased the optimizer’s “reuse” factor. This engine performs the following optimizations; Dead Code Elimination (DCE), Common Subexpression Elimination (CSE) and Constant Propagation (CP) at both runtime and compile time with linear complexity time requirement. CP is essentially free, whether the values are really source-code constants or specific values generated at runtime. CP runs along side with the other optimization passes, thus allowing the efficient runtime specialization of the code during any point of the program’s lifetime. 1. Introduction A recurring theme in this work is that powerful expensive analysis and optimization facilities are not necessary for generating good code. Rather, by using information ignored by previous work, we have built a facility that produces good code with simple linear time algorithms. This report will focus on the optimization parts of the system. More detailed reports on META4?; ? as well as the compiler are under development. Section 0.2 will introduce the scope of the optimization algorithms presented in this work. Section 1. will dicuss some of the important definitions and concepts related to the META4 programming language and the optimizer used by the algorithms presented herein. -

CS153: Compilers Lecture 19: Optimization
CS153: Compilers Lecture 19: Optimization Stephen Chong https://www.seas.harvard.edu/courses/cs153 Contains content from lecture notes by Steve Zdancewic and Greg Morrisett Announcements •HW5: Oat v.2 out •Due in 2 weeks •HW6 will be released next week •Implementing optimizations! (and more) Stephen Chong, Harvard University 2 Today •Optimizations •Safety •Constant folding •Algebraic simplification • Strength reduction •Constant propagation •Copy propagation •Dead code elimination •Inlining and specialization • Recursive function inlining •Tail call elimination •Common subexpression elimination Stephen Chong, Harvard University 3 Optimizations •The code generated by our OAT compiler so far is pretty inefficient. •Lots of redundant moves. •Lots of unnecessary arithmetic instructions. •Consider this OAT program: int foo(int w) { var x = 3 + 5; var y = x * w; var z = y - 0; return z * 4; } Stephen Chong, Harvard University 4 Unoptimized vs. Optimized Output .globl _foo _foo: •Hand optimized code: pushl %ebp movl %esp, %ebp _foo: subl $64, %esp shlq $5, %rdi __fresh2: movq %rdi, %rax leal -64(%ebp), %eax ret movl %eax, -48(%ebp) movl 8(%ebp), %eax •Function foo may be movl %eax, %ecx movl -48(%ebp), %eax inlined by the compiler, movl %ecx, (%eax) movl $3, %eax so it can be implemented movl %eax, -44(%ebp) movl $5, %eax by just one instruction! movl %eax, %ecx addl %ecx, -44(%ebp) leal -60(%ebp), %eax movl %eax, -40(%ebp) movl -44(%ebp), %eax Stephen Chong,movl Harvard %eax,University %ecx 5 Why do we need optimizations? •To help programmers… •They write modular, clean, high-level programs •Compiler generates efficient, high-performance assembly •Programmers don’t write optimal code •High-level languages make avoiding redundant computation inconvenient or impossible •e.g. -

Precise Null Pointer Analysis Through Global Value Numbering
Precise Null Pointer Analysis Through Global Value Numbering Ankush Das1 and Akash Lal2 1 Carnegie Mellon University, Pittsburgh, PA, USA 2 Microsoft Research, Bangalore, India Abstract. Precise analysis of pointer information plays an important role in many static analysis tools. The precision, however, must be bal- anced against the scalability of the analysis. This paper focusses on improving the precision of standard context and flow insensitive alias analysis algorithms at a low scalability cost. In particular, we present a semantics-preserving program transformation that drastically improves the precision of existing analyses when deciding if a pointer can alias Null. Our program transformation is based on Global Value Number- ing, a scheme inspired from compiler optimization literature. It allows even a flow-insensitive analysis to make use of branch conditions such as checking if a pointer is Null and gain precision. We perform experiments on real-world code and show that the transformation improves precision (in terms of the number of dereferences proved safe) from 86.56% to 98.05%, while incurring a small overhead in the running time. Keywords: Alias Analysis, Global Value Numbering, Static Single As- signment, Null Pointer Analysis 1 Introduction Detecting and eliminating null-pointer exceptions is an important step towards developing reliable systems. Static analysis tools that look for null-pointer ex- ceptions typically employ techniques based on alias analysis to detect possible aliasing between pointers. Two pointer-valued variables are said to alias if they hold the same memory location during runtime. Statically, aliasing can be de- cided in two ways: (a) may-alias [1], where two pointers are said to may-alias if they can point to the same memory location under some possible execution, and (b) must-alias [27], where two pointers are said to must-alias if they always point to the same memory location under all possible executions. -

Value Numbering
SOFTWARE—PRACTICE AND EXPERIENCE, VOL. 0(0), 1–18 (MONTH 1900) Value Numbering PRESTON BRIGGS Tera Computer Company, 2815 Eastlake Avenue East, Seattle, WA 98102 AND KEITH D. COOPER L. TAYLOR SIMPSON Rice University, 6100 Main Street, Mail Stop 41, Houston, TX 77005 SUMMARY Value numbering is a compiler-based program analysis method that allows redundant computations to be removed. This paper compares hash-based approaches derived from the classic local algorithm1 with partitioning approaches based on the work of Alpern, Wegman, and Zadeck2. Historically, the hash-based algorithm has been applied to single basic blocks or extended basic blocks. We have improved the technique to operate over the routine’s dominator tree. The partitioning approach partitions the values in the routine into congruence classes and removes computations when one congruent value dominates another. We have extended this technique to remove computations that define a value in the set of available expressions (AVA IL )3. Also, we are able to apply a version of Morel and Renvoise’s partial redundancy elimination4 to remove even more redundancies. The paper presents a series of hash-based algorithms and a series of refinements to the partitioning technique. Within each series, it can be proved that each method discovers at least as many redundancies as its predecessors. Unfortunately, no such relationship exists between the hash-based and global techniques. On some programs, the hash-based techniques eliminate more redundancies than the partitioning techniques, while on others, partitioning wins. We experimentally compare the improvements made by these techniques when applied to real programs. These results will be useful for commercial compiler writers who wish to assess the potential impact of each technique before implementation. -

Global Value Numbering Using Random Interpretation
Global Value Numbering using Random Interpretation Sumit Gulwani George C. Necula [email protected] [email protected] Department of Electrical Engineering and Computer Science University of California, Berkeley Berkeley, CA 94720-1776 Abstract General Terms We present a polynomial time randomized algorithm for global Algorithms, Theory, Verification value numbering. Our algorithm is complete when conditionals are treated as non-deterministic and all operators are treated as uninter- Keywords preted functions. We are not aware of any complete polynomial- time deterministic algorithm for the same problem. The algorithm Global Value Numbering, Herbrand Equivalences, Random Inter- does not require symbolic manipulations and hence is simpler to pretation, Randomized Algorithm, Uninterpreted Functions implement than the deterministic symbolic algorithms. The price for these benefits is that there is a probability that the algorithm can report a false equality. We prove that this probability can be made 1 Introduction arbitrarily small by controlling various parameters of the algorithm. Detecting equivalence of expressions in a program is a prerequi- Our algorithm is based on the idea of random interpretation, which site for many important optimizations like constant and copy prop- relies on executing a program on a number of random inputs and agation [18], common sub-expression elimination, invariant code discovering relationships from the computed values. The computa- motion [3, 13], induction variable elimination, branch elimination, tions are done by giving random linear interpretations to the opera- branch fusion, and loop jamming [10]. It is also important for dis- tors in the program. Both branches of a conditional are executed. At covering equivalent computations in different programs, for exam- join points, the program states are combined using a random affine ple, plagiarism detection and translation validation [12, 11], where combination. -
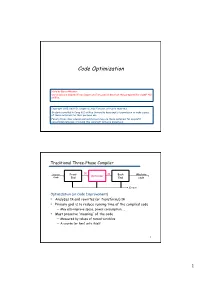
Code Optimization
Code Optimization Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon’s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students enrolled in Comp 412 at Rice University have explicit permission to make copies of these materials for their personal use. Faculty from other educational institutions may use these materials for nonprofit educational purposes, provided this copyright notice is preserved. Traditional Three-Phase Compiler Source Front IR IR Back Machine Optimizer Code End End code Errors Optimization (or Code Improvement) • Analyzes IR and rewrites (or transforms) IR • Primary goal is to reduce running time of the compiled code — May also improve space, power consumption, … • Must preserve “meaning” of the code — Measured by values of named variables — A course (or two) unto itself 1 1 The Optimizer IR Opt IR Opt IR Opt IR... Opt IR 1 2 3 n Errors Modern optimizers are structured as a series of passes Typical Transformations • Discover & propagate some constant value • Move a computation to a less frequently executed place • Specialize some computation based on context • Discover a redundant computation & remove it • Remove useless or unreachable code • Encode an idiom in some particularly efficient form 2 The Role of the Optimizer • The compiler can implement a procedure in many ways • The optimizer tries to find an implementation that is “better” — Speed, code size, data space, … To accomplish this, it • Analyzes the code to derive knowledge -

Redundant Computation Elimination Optimizations
Redundant Computation Elimination Optimizations CS2210 Lecture 20 CS2210 Compiler Design 2004/5 Redundancy Elimination ■ Several categories: ■ Value Numbering ■ local & global ■ Common subexpression elimination (CSE) ■ local & global ■ Loop-invariant code motion ■ Partial redundancy elimination ■ Most complex ■ Subsumes CSE & loop-invariant code motion CS2210 Compiler Design 2004/5 Value Numbering ■ Goal: identify expressions that have same value ■ Approach: hash expression to a hash code ■ Then have to compare only expressions that hash to same value CS2210 Compiler Design 2004/5 1 Example a := x | y b := x | y t1:= !z if t1 goto L1 x := !z c := x & y t2 := x & y if t2 trap 30 CS2210 Compiler Design 2004/5 Global Value Numbering ■ Generalization of value numbering for procedures ■ Requires code to be in SSA form ■ Crucial notion: congruence ■ Two variables are congruent if their defining computations have identical operators and congruent operands ■ Only precise in SSA form, otherwise the definition may not dominate the use CS2210 Compiler Design 2004/5 Value Graphs ■ Labeled, directed graph ■ Nodes are labeled with ■ Operators ■ Function symbols ■ Constants ■ Edges point from operator (or function) to its operands ■ Number labels indicate operand position CS2210 Compiler Design 2004/5 2 Example entry receive n1(val) i := 1 1 B1 j1 := 1 i3 := φ2(i1,i2) B2 j3 := φ2(j1,j2) i3 mod 2 = 0 i := i +1 i := i +3 B3 4 3 5 3 B4 j4:= j3+1 j5:= j3+3 i2 := φ5(i4,i5) j3 := φ5(j4,j5) B5 j2 > n1 exit CS2210 Compiler Design 2004/5 Congruence Definition ■ Maximal relation on the value graph ■ Two nodes are congruent iff ■ They are the same node, or ■ Their labels are constants and the constants are the same, or ■ They have the same operators and their operands are congruent ■ Variable equivalence := x and y are equivalent at program point p iff they are congruent and their defining assignments dominate p CS2210 Compiler Design 2004/5 Global Value Numbering Algo. -

A Simple Graph-Based Intermediate Representation
A Simple Graph-Based Intermediate Representation Cliff Click Michael Paleczny [email protected] [email protected] understand, and easy to extend. Our goal is a repre- Abstract sentation that is simple and light weight while allowing We present a graph-based intermediate representation easy expression of fast optimizations. (IR) with simple semantics and a low-memory-cost C++ This paper discusses the intermediate representa- implementation. The IR uses a directed graph with la- beled vertices and ordered inputs but unordered outputs. tion (IR) used in the research compiler implemented as Vertices are labeled with opcodes, edges are unlabeled. part of the author’s dissertation [8]. The parser that We represent the CFG and basic blocks with the same builds this IR performs significant parse-time optimi- vertex and edge structures. Each opcode is defined by a zations, including building a form of Static Single As- C++ class that encapsulates opcode-specific data and be- signment (SSA) at parse-time. Classic optimizations havior. We use inheritance to abstract common opcode such as Conditional Constant Propagation [23] and behavior, allowing new opcodes to be easily defined from Global Value Numbering [20] as well as a novel old ones. The resulting IR is simple, fast and easy to use. global code motion algorithm [9] work well on the IR. These topics are beyond the scope of this paper but are 1. Introduction covered in Click’s thesis. Intermediate representations do not exist in a vac- The intermediate representation is a graph-based, uum. They are the stepping stone from what the pro- object-oriented structure, similar in spirit to an opera- grammer wrote to what the machine understands. -

Global Value Numbering
Reuse Optimization Local Value Numbering Announcement Idea − HW2 is due Monday! I will not accept late HW2 turnins − Each variable, expression, and constant is assigned a unique number − When we encounter a variable, expression or constant, see if it’s already Idea been assigned a number − Eliminate redundant operations in the dynamic execution of instructions − If so, use the value for that number How do redundancies arise? − If not, assign a new number − Loop invariant code (e.g., index calculation for arrays) − Same number ⇒ same value − Sequence of similar operations (e.g., method lookup) b → #1 #3 − Same value be generated in multiple places in the code Example a := b + c c → #2 b + c is #1 + # 2 → #3 Types of reuse optimization d := b a → #3 − Value numbering b := a − Common subexpression elimination d → #1 e := d + c a is − Partial redundancy elimination d + c #1 + # 2 → #3 e → #3 CS553 Lecture Value Numbering 2 CS553 Lecture Value Numbering 3 Local Value Numbering (cont) Global Value Numbering Temporaries may be necessary How do we handle control flow? b → #1 a := b + c c → #2 w = 5 w = 8 a := b b + c is #1 + # 2 → #3 x = 5 x = 8 d := a + c a → #3 #1 a + c is #1 + # 2 → #3 w → #1 w → #2 d → #3 y = w+1 x → #1 x → #2 z = x+1 . b → #1 t := b + c c → #2 a := b b + c is #1 + # 2 → #3 d := b + c t t → #3 a → #1 a + c is #1 + # 2 → #3 d → #3 CS553 Lecture Value Numbering 4 CS553 Lecture Value Numbering 5 1 Global Value Numbering (cont) Role of SSA Form Idea [Alpern, Wegman, and Zadeck 1988] SSA form is helpful − Partition program variables into congruence classes − Allows us to avoid data-flow analysis − All variables in a particular congruence class have the same value − Variables correspond to values − SSA form is helpful a = b a1 = b . -

GVN Notes for Slides
This talk is divided into 7 parts. Part 1 begins with a quick look at the SSA optimization framework and global value numbering. Part 2 describes a well known brute force algorithm for GVN. Part 3 modifies this to arrive at an efficient sparse algorithm. Part 4 unifies the sparse algorithm with a wide range of additional analyses. Parts 5-7 put it all together, present measurements and suggest conclusions. PLDI’02 17 June 2002 2-1/34 The framework of an SSA based global optimizer can be rep- resented as a pipeline of processing stages. The intermediate representation of a routine flows in at the top and is first trans- lated to static single assignment form. The SSA form IR is now processed by a number of passes, one of which is global value numbering. The results of GVN are used to transform the IR. Finally the IR is translated out of SSA form, and optimized IR flows out of the pipeline. PLDI’02 17 June 2002 3-1/34 These are the basic notions of value numbering. A value is a constant or an SSA variable. The values of a routine can be partitioned into congruence classes. Congruent values are guar- anteed to be identical for any possible execution of the routine. Every congruence class has a representative value called a leader. PLDI’02 17 June 2002 4-1/34 GVN is an analysis phase - it does not transform IR. Its input is the SSA form IR of a routine. It produces 4 outputs: the congruence classes of the routine, the values in every congruence class, the leader of every congruence class and the congruence class of every value. -

Optimization Compiler Passes Optimizations the Role of The
Analysis Synthesis of input program of output program Compiler (front -end) (back -end) character Passes stream Intermediate Lexical Analysis Code Generation token intermediate Optimization stream form Syntactic Analysis Optimization abstract intermediate Before and after generating machine syntax tree form code, devote one or more passes over the program to “improve” code quality Semantic Analysis Code Generation annotated target AST language 2 The Role of the Optimizer Optimizations • The compiler can implement a procedure in many ways • The optimizer tries to find an implementation that is “better” – Speed, code size, data space, … Identify inefficiencies in intermediate or target code Replace with equivalent but better sequences To accomplish this, it • Analyzes the code to derive knowledge about run-time • equivalent = "has the same externally visible behavior – Data-flow analysis, pointer disambiguation, … behavior" – General term is “static analysis” Target-independent optimizations best done on IL • Uses that knowledge in an attempt to improve the code – Literally hundreds of transformations have been proposed code – Large amount of overlap between them Target-dependent optimizations best done on Nothing “optimal” about optimization target code • Proofs of optimality assume restrictive & unrealistic conditions • Better goal is to “usually improve” 3 4 Traditional Three-pass Compiler The Optimizer (or Middle End) IR Source Front Middle IR Back Machine IROpt IROpt IROpt ... IROpt IR Code End End End code 1 2 3 n Errors Errors Modern -

Redundancy Elimination 6 November 2009 Lecturer: Andrew Myers
CS 4120 Lecture 27 Redundancy Elimination 6 November 2009 Lecturer: Andrew Myers An optimization aims at redundancy elimination if it prevents the same computation from being done twice. 1 Local value numbering Local value numbering is a redundancy elimination optimization. It is called a “local” optimization because it is performed on a single basic block. It can as easily be applied to an extended basic block (EBB), which is a sequence of nodes in which some nodes are allowed to have exit edges, as depicted in Figure 1. More generally, it can be applied to any tree-like subgraph in which all nodes have only one predecessor and there is a single node that dominates all other nodes. Each path through such a subgraph forms an EBB. Figure 1: Extended basic block The idea of value numbering is to label each computed expression a distinct identifier (a “number”), such that a recomputation of the same expression is assigned the same number. If an expression is labeled with the same number as a variable, the variable can be used in place of the expression. Value numbering overlaps but does not completely subsume constant propagation and common subexpression elimination. For example, every expression and variable in the following the code has been given a number. Expres- sions with the same number must compute the same value. a2 = (i1 + 5)2 j1 = i1 b2 = 5 + j1 i2 = i1 + 5 if c4 = (i2 + 1)3 goto L1 d3 = (i2 + 1)3 To do this numbering, we start at the beginning of the EBB and assign numbers to expressions as they are encountered.