Simple and Efficient Construction of Static Single Assignment Form
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Generalized Jump Threading in Libfirm
Institut für Programmstrukturen und Datenorganisation (IPD) Lehrstuhl Prof. Dr.-Ing. Snelting Generalized Jump Threading in libFIRM Masterarbeit von Joachim Priesner an der Fakultät für Informatik Erstgutachter: Prof. Dr.-Ing. Gregor Snelting Zweitgutachter: Prof. Dr.-Ing. Jörg Henkel Betreuender Mitarbeiter: Dipl.-Inform. Andreas Zwinkau Bearbeitungszeit: 5. Oktober 2016 – 23. Januar 2017 KIT – Die Forschungsuniversität in der Helmholtz-Gemeinschaft www.kit.edu Zusammenfassung/Abstract Jump Threading (dt. „Sprünge fädeln“) ist eine Compileroptimierung, die statisch vorhersagbare bedingte Sprünge in unbedingte Sprünge umwandelt. Bei der Ausfüh- rung kann ein Prozessor bedingte Sprünge zunächst nur heuristisch mit Hilfe der Sprungvorhersage auswerten. Sie stellen daher generell ein Performancehindernis dar. Die Umwandlung ist insbesondere auch dann möglich, wenn das Sprungziel nur auf einer Teilmenge der zu dem Sprung führenden Ausführungspfade statisch be- stimmbar ist. In diesem Fall, der den überwiegenden Teil der durch Jump Threading optimierten Sprünge betrifft, muss die Optimierung Grundblöcke duplizieren, um jene Ausführungspfade zu isolieren. Verschiedene aktuelle Compiler enthalten sehr unterschiedliche Implementierungen von Jump Threading. In dieser Masterarbeit wird zunächst ein theoretischer Rahmen für Jump Threading vorgestellt. Sodann wird eine allgemeine Fassung eines Jump- Threading-Algorithmus entwickelt, implementiert und in diverser Hinsicht untersucht, insbesondere auf Wechselwirkungen mit anderen Optimierungen wie If -

Polyhedral Compilation As a Design Pattern for Compiler Construction
Polyhedral Compilation as a Design Pattern for Compiler Construction PLISS, May 19-24, 2019 [email protected] Polyhedra? Example: Tiles Polyhedra? Example: Tiles How many of you read “Design Pattern”? → Tiles Everywhere 1. Hardware Example: Google Cloud TPU Architectural Scalability With Tiling Tiles Everywhere 1. Hardware Google Edge TPU Edge computing zoo Tiles Everywhere 1. Hardware 2. Data Layout Example: XLA compiler, Tiled data layout Repeated/Hierarchical Tiling e.g., BF16 (bfloat16) on Cloud TPU (should be 8x128 then 2x1) Tiles Everywhere Tiling in Halide 1. Hardware 2. Data Layout Tiled schedule: strip-mine (a.k.a. split) 3. Control Flow permute (a.k.a. reorder) 4. Data Flow 5. Data Parallelism Vectorized schedule: strip-mine Example: Halide for image processing pipelines vectorize inner loop https://halide-lang.org Meta-programming API and domain-specific language (DSL) for loop transformations, numerical computing kernels Non-divisible bounds/extent: strip-mine shift left/up redundant computation (also forward substitute/inline operand) Tiles Everywhere TVM example: scan cell (RNN) m = tvm.var("m") n = tvm.var("n") 1. Hardware X = tvm.placeholder((m,n), name="X") s_state = tvm.placeholder((m,n)) 2. Data Layout s_init = tvm.compute((1,n), lambda _,i: X[0,i]) s_do = tvm.compute((m,n), lambda t,i: s_state[t-1,i] + X[t,i]) 3. Control Flow s_scan = tvm.scan(s_init, s_do, s_state, inputs=[X]) s = tvm.create_schedule(s_scan.op) 4. Data Flow // Schedule to run the scan cell on a CUDA device block_x = tvm.thread_axis("blockIdx.x") 5. Data Parallelism thread_x = tvm.thread_axis("threadIdx.x") xo,xi = s[s_init].split(s_init.op.axis[1], factor=num_thread) s[s_init].bind(xo, block_x) Example: Halide for image processing pipelines s[s_init].bind(xi, thread_x) xo,xi = s[s_do].split(s_do.op.axis[1], factor=num_thread) https://halide-lang.org s[s_do].bind(xo, block_x) s[s_do].bind(xi, thread_x) print(tvm.lower(s, [X, s_scan], simple_mode=True)) And also TVM for neural networks https://tvm.ai Tiling and Beyond 1. -

Efficient Run Time Optimization with Static Single Assignment
i Jason W. Kim and Terrance E. Boult EECS Dept. Lehigh University Room 304 Packard Lab. 19 Memorial Dr. W. Bethlehem, PA. 18015 USA ¢ jwk2 ¡ tboult @eecs.lehigh.edu Abstract We introduce a novel optimization engine for META4, a new object oriented language currently under development. It uses Static Single Assignment (henceforth SSA) form coupled with certain reasonable, albeit very uncommon language features not usually found in existing systems. This reduces the code footprint and increased the optimizer’s “reuse” factor. This engine performs the following optimizations; Dead Code Elimination (DCE), Common Subexpression Elimination (CSE) and Constant Propagation (CP) at both runtime and compile time with linear complexity time requirement. CP is essentially free, whether the values are really source-code constants or specific values generated at runtime. CP runs along side with the other optimization passes, thus allowing the efficient runtime specialization of the code during any point of the program’s lifetime. 1. Introduction A recurring theme in this work is that powerful expensive analysis and optimization facilities are not necessary for generating good code. Rather, by using information ignored by previous work, we have built a facility that produces good code with simple linear time algorithms. This report will focus on the optimization parts of the system. More detailed reports on META4?; ? as well as the compiler are under development. Section 0.2 will introduce the scope of the optimization algorithms presented in this work. Section 1. will dicuss some of the important definitions and concepts related to the META4 programming language and the optimizer used by the algorithms presented herein. -

CS153: Compilers Lecture 19: Optimization
CS153: Compilers Lecture 19: Optimization Stephen Chong https://www.seas.harvard.edu/courses/cs153 Contains content from lecture notes by Steve Zdancewic and Greg Morrisett Announcements •HW5: Oat v.2 out •Due in 2 weeks •HW6 will be released next week •Implementing optimizations! (and more) Stephen Chong, Harvard University 2 Today •Optimizations •Safety •Constant folding •Algebraic simplification • Strength reduction •Constant propagation •Copy propagation •Dead code elimination •Inlining and specialization • Recursive function inlining •Tail call elimination •Common subexpression elimination Stephen Chong, Harvard University 3 Optimizations •The code generated by our OAT compiler so far is pretty inefficient. •Lots of redundant moves. •Lots of unnecessary arithmetic instructions. •Consider this OAT program: int foo(int w) { var x = 3 + 5; var y = x * w; var z = y - 0; return z * 4; } Stephen Chong, Harvard University 4 Unoptimized vs. Optimized Output .globl _foo _foo: •Hand optimized code: pushl %ebp movl %esp, %ebp _foo: subl $64, %esp shlq $5, %rdi __fresh2: movq %rdi, %rax leal -64(%ebp), %eax ret movl %eax, -48(%ebp) movl 8(%ebp), %eax •Function foo may be movl %eax, %ecx movl -48(%ebp), %eax inlined by the compiler, movl %ecx, (%eax) movl $3, %eax so it can be implemented movl %eax, -44(%ebp) movl $5, %eax by just one instruction! movl %eax, %ecx addl %ecx, -44(%ebp) leal -60(%ebp), %eax movl %eax, -40(%ebp) movl -44(%ebp), %eax Stephen Chong,movl Harvard %eax,University %ecx 5 Why do we need optimizations? •To help programmers… •They write modular, clean, high-level programs •Compiler generates efficient, high-performance assembly •Programmers don’t write optimal code •High-level languages make avoiding redundant computation inconvenient or impossible •e.g. -

Precise Null Pointer Analysis Through Global Value Numbering
Precise Null Pointer Analysis Through Global Value Numbering Ankush Das1 and Akash Lal2 1 Carnegie Mellon University, Pittsburgh, PA, USA 2 Microsoft Research, Bangalore, India Abstract. Precise analysis of pointer information plays an important role in many static analysis tools. The precision, however, must be bal- anced against the scalability of the analysis. This paper focusses on improving the precision of standard context and flow insensitive alias analysis algorithms at a low scalability cost. In particular, we present a semantics-preserving program transformation that drastically improves the precision of existing analyses when deciding if a pointer can alias Null. Our program transformation is based on Global Value Number- ing, a scheme inspired from compiler optimization literature. It allows even a flow-insensitive analysis to make use of branch conditions such as checking if a pointer is Null and gain precision. We perform experiments on real-world code and show that the transformation improves precision (in terms of the number of dereferences proved safe) from 86.56% to 98.05%, while incurring a small overhead in the running time. Keywords: Alias Analysis, Global Value Numbering, Static Single As- signment, Null Pointer Analysis 1 Introduction Detecting and eliminating null-pointer exceptions is an important step towards developing reliable systems. Static analysis tools that look for null-pointer ex- ceptions typically employ techniques based on alias analysis to detect possible aliasing between pointers. Two pointer-valued variables are said to alias if they hold the same memory location during runtime. Statically, aliasing can be de- cided in two ways: (a) may-alias [1], where two pointers are said to may-alias if they can point to the same memory location under some possible execution, and (b) must-alias [27], where two pointers are said to must-alias if they always point to the same memory location under all possible executions. -

Cross-Platform Language Design
Cross-Platform Language Design THIS IS A TEMPORARY TITLE PAGE It will be replaced for the final print by a version provided by the service academique. Thèse n. 1234 2011 présentée le 11 Juin 2018 à la Faculté Informatique et Communications Laboratoire de Méthodes de Programmation 1 programme doctoral en Informatique et Communications École Polytechnique Fédérale de Lausanne pour l’obtention du grade de Docteur ès Sciences par Sébastien Doeraene acceptée sur proposition du jury: Prof James Larus, président du jury Prof Martin Odersky, directeur de thèse Prof Edouard Bugnion, rapporteur Dr Andreas Rossberg, rapporteur Prof Peter Van Roy, rapporteur Lausanne, EPFL, 2018 It is better to repent a sin than regret the loss of a pleasure. — Oscar Wilde Acknowledgments Although there is only one name written in a large font on the front page, there are many people without which this thesis would never have happened, or would not have been quite the same. Five years is a long time, during which I had the privilege to work, discuss, sing, learn and have fun with many people. I am afraid to make a list, for I am sure I will forget some. Nevertheless, I will try my best. First, I would like to thank my advisor, Martin Odersky, for giving me the opportunity to fulfill a dream, that of being part of the design and development team of my favorite programming language. Many thanks for letting me explore the design of Scala.js in my own way, while at the same time always being there when I needed him. -

Value Numbering
SOFTWARE—PRACTICE AND EXPERIENCE, VOL. 0(0), 1–18 (MONTH 1900) Value Numbering PRESTON BRIGGS Tera Computer Company, 2815 Eastlake Avenue East, Seattle, WA 98102 AND KEITH D. COOPER L. TAYLOR SIMPSON Rice University, 6100 Main Street, Mail Stop 41, Houston, TX 77005 SUMMARY Value numbering is a compiler-based program analysis method that allows redundant computations to be removed. This paper compares hash-based approaches derived from the classic local algorithm1 with partitioning approaches based on the work of Alpern, Wegman, and Zadeck2. Historically, the hash-based algorithm has been applied to single basic blocks or extended basic blocks. We have improved the technique to operate over the routine’s dominator tree. The partitioning approach partitions the values in the routine into congruence classes and removes computations when one congruent value dominates another. We have extended this technique to remove computations that define a value in the set of available expressions (AVA IL )3. Also, we are able to apply a version of Morel and Renvoise’s partial redundancy elimination4 to remove even more redundancies. The paper presents a series of hash-based algorithms and a series of refinements to the partitioning technique. Within each series, it can be proved that each method discovers at least as many redundancies as its predecessors. Unfortunately, no such relationship exists between the hash-based and global techniques. On some programs, the hash-based techniques eliminate more redundancies than the partitioning techniques, while on others, partitioning wins. We experimentally compare the improvements made by these techniques when applied to real programs. These results will be useful for commercial compiler writers who wish to assess the potential impact of each technique before implementation. -

Global Value Numbering Using Random Interpretation
Global Value Numbering using Random Interpretation Sumit Gulwani George C. Necula [email protected] [email protected] Department of Electrical Engineering and Computer Science University of California, Berkeley Berkeley, CA 94720-1776 Abstract General Terms We present a polynomial time randomized algorithm for global Algorithms, Theory, Verification value numbering. Our algorithm is complete when conditionals are treated as non-deterministic and all operators are treated as uninter- Keywords preted functions. We are not aware of any complete polynomial- time deterministic algorithm for the same problem. The algorithm Global Value Numbering, Herbrand Equivalences, Random Inter- does not require symbolic manipulations and hence is simpler to pretation, Randomized Algorithm, Uninterpreted Functions implement than the deterministic symbolic algorithms. The price for these benefits is that there is a probability that the algorithm can report a false equality. We prove that this probability can be made 1 Introduction arbitrarily small by controlling various parameters of the algorithm. Detecting equivalence of expressions in a program is a prerequi- Our algorithm is based on the idea of random interpretation, which site for many important optimizations like constant and copy prop- relies on executing a program on a number of random inputs and agation [18], common sub-expression elimination, invariant code discovering relationships from the computed values. The computa- motion [3, 13], induction variable elimination, branch elimination, tions are done by giving random linear interpretations to the opera- branch fusion, and loop jamming [10]. It is also important for dis- tors in the program. Both branches of a conditional are executed. At covering equivalent computations in different programs, for exam- join points, the program states are combined using a random affine ple, plagiarism detection and translation validation [12, 11], where combination. -

Phase-Ordering in Optimizing Compilers
Phase-ordering in optimizing compilers Matthieu Qu´eva Kongens Lyngby 2007 IMM-MSC-2007-71 Technical University of Denmark Informatics and Mathematical Modelling Building 321, DK-2800 Kongens Lyngby, Denmark Phone +45 45253351, Fax +45 45882673 [email protected] www.imm.dtu.dk Summary The “quality” of code generated by compilers largely depends on the analyses and optimizations applied to the code during the compilation process. While modern compilers could choose from a plethora of optimizations and analyses, in current compilers the order of these pairs of analyses/transformations is fixed once and for all by the compiler developer. Of course there exist some flags that allow a marginal control of what is executed and how, but the most important source of information regarding what analyses/optimizations to run is ignored- the source code. Indeed, some optimizations might be better to be applied on some source code, while others would be preferable on another. A new compilation model is developed in this thesis by implementing a Phase Manager. This Phase Manager has a set of analyses/transformations available, and can rank the different possible optimizations according to the current state of the intermediate representation. Based on this ranking, the Phase Manager can decide which phase should be run next. Such a Phase Manager has been implemented for a compiler for a simple imper- ative language, the while language, which includes several Data-Flow analyses. The new approach consists in calculating coefficients, called metrics, after each optimization phase. These metrics are used to evaluate where the transforma- tions will be applicable, and are used by the Phase Manager to rank the phases. -
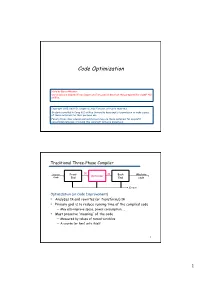
Code Optimization
Code Optimization Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon’s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students enrolled in Comp 412 at Rice University have explicit permission to make copies of these materials for their personal use. Faculty from other educational institutions may use these materials for nonprofit educational purposes, provided this copyright notice is preserved. Traditional Three-Phase Compiler Source Front IR IR Back Machine Optimizer Code End End code Errors Optimization (or Code Improvement) • Analyzes IR and rewrites (or transforms) IR • Primary goal is to reduce running time of the compiled code — May also improve space, power consumption, … • Must preserve “meaning” of the code — Measured by values of named variables — A course (or two) unto itself 1 1 The Optimizer IR Opt IR Opt IR Opt IR... Opt IR 1 2 3 n Errors Modern optimizers are structured as a series of passes Typical Transformations • Discover & propagate some constant value • Move a computation to a less frequently executed place • Specialize some computation based on context • Discover a redundant computation & remove it • Remove useless or unreachable code • Encode an idiom in some particularly efficient form 2 The Role of the Optimizer • The compiler can implement a procedure in many ways • The optimizer tries to find an implementation that is “better” — Speed, code size, data space, … To accomplish this, it • Analyzes the code to derive knowledge -

Dataflow Analysis: Constant Propagation
Dataflow Analysis Monday, November 9, 15 Program optimizations • So far we have talked about different kinds of optimizations • Peephole optimizations • Local common sub-expression elimination • Loop optimizations • What about global optimizations • Optimizations across multiple basic blocks (usually a whole procedure) • Not just a single loop Monday, November 9, 15 Useful optimizations • Common subexpression elimination (global) • Need to know which expressions are available at a point • Dead code elimination • Need to know if the effects of a piece of code are never needed, or if code cannot be reached • Constant folding • Need to know if variable has a constant value • So how do we get this information? Monday, November 9, 15 Dataflow analysis • Framework for doing compiler analyses to drive optimization • Works across basic blocks • Examples • Constant propagation: determine which variables are constant • Liveness analysis: determine which variables are live • Available expressions: determine which expressions are have valid computed values • Reaching definitions: determine which definitions could “reach” a use Monday, November 9, 15 Example: constant propagation • Goal: determine when variables take on constant values • Why? Can enable many optimizations • Constant folding x = 1; y = x + 2; if (x > z) then y = 5 ... y ... • Create dead code x = 1; y = x + 2; if (y > x) then y = 5 ... y ... Monday, November 9, 15 Example: constant propagation • Goal: determine when variables take on constant values • Why? Can enable many optimizations • Constant folding x = 1; x = 1; y = x + 2; y = 3; if (x > z) then y = 5 if (x > z) then y = 5 ... y ... ... y ... • Create dead code x = 1; y = x + 2; if (y > x) then y = 5 .. -

Improving the Compilation Process Using Program Annotations
POLITECNICO DI MILANO Corso di Laurea Magistrale in Ingegneria Informatica Dipartimento di Elettronica, Informazione e Bioingegneria Improving the Compilation process using Program Annotations Relatore: Prof. Giovanni Agosta Correlatore: Prof. Lenore Zuck Tesi di Laurea di: Niko Zarzani, matricola 783452 Anno Accademico 2012-2013 Alla mia famiglia Alla mia ragazza Ai miei amici Ringraziamenti Ringrazio in primis i miei relatori, Prof. Giovanni Agosta e Prof. Lenore Zuck, per la loro disponibilità, i loro preziosi consigli e il loro sostegno. Grazie per avermi seguito sia nel corso della tesi che della mia carriera universitaria. Ringrazio poi tutti coloro con cui ho avuto modo di confrontarmi durante la mia ricerca, Dr. Venkat N. Venkatakrishnan, Dr. Rigel Gjomemo, Dr. Phu H. H. Phung e Giacomo Tagliabure, che mi sono stati accanto sin dall’inizio del mio percorso di tesi. Voglio ringraziare con tutto il cuore la mia famiglia per il prezioso sup- porto in questi anni di studi e Camilla per tutto l’amore che mi ha dato anche nei momenti più critici di questo percorso. Non avrei potuto su- perare questa avventura senza voi al mio fianco. Ringrazio le mie amiche e i miei amici più cari Ilaria, Carolina, Elisa, Riccardo e Marco per la nostra speciale amicizia a distanza e tutte le risate fatte assieme. Infine tutti i miei conquilini, dai più ai meno nerd, per i bei momenti pas- sati assieme. Ricorderò per sempre questi ultimi anni come un’esperienza stupenda che avete reso memorabile. Mi mancherete tutti. Contents 1 Introduction 1 2 Background 3 2.1 Annotated Code . .3 2.2 Sources of annotated code .