Prioritizing Technical Debt in Database Normalization Using Portfolio Theory and Data Quality Metrics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Database Design Solutions
spine=1.10" Wrox Programmer to ProgrammerTM Wrox Programmer to ProgrammerTM Beginning Stephens Database Design Solutions Databases play a critical role in the business operations of most organizations; they’re the central repository for critical information on products, customers, Beginning suppliers, sales, and a host of other essential information. It’s no wonder that Solutions Database Design the majority of all business computing involves database applications. With so much at stake, you’d expect most IT professionals would have a firm understanding of good database design. But in fact most learn through a painful process of trial and error, with predictably poor results. This book provides readers with proven methods and tools for designing efficient, reliable, and secure databases. Author Rod Stephens explains how a database should be organized to ensure data integrity without sacrificing performance. He shares procedures for designing robust, flexible, and secure databases that provide a solid foundation for all of your database applications. The methods and techniques in this book can be applied to any database environment, including Oracle®, Microsoft Access®, SQL Server®, and MySQL®. You’ll learn the basics of good database design and ultimately discover how to design a real-world database. What you will learn from this book ● How to identify database requirements that meet users’ needs ● Ways to build data models using a variety of modeling techniques, including Beginning entity-relational models, user-interface models, and -

Ssql-Schema-Comparer: Support of Multi-Language Refactoring With
2013 IEEE 13th International Working Conference on Source Code Analysis and Manipulation (SCAM) sql-schema-comparer: Support of Multi-Language Refactoring with Relational Databases Hagen Schink Institute of Technical and Business Information Systems Otto-von-Guericke-University Magdeburg, Germany [email protected] Abstract—Refactoring is a method to change a source-code’s State-of-the-art IDEs provide information about syntactical structure without modifying its semantics and was first intro- changes or errors before integration or runtime tests take duced for object-oriented code. Since then refactorings were effect. Hence, the information can enable software developers defined for relational databases too. But database refactorings must be treated differently because a database schema’s structure to recognize and correct syntactic and some semantic errors defines semantics used by other applications to access the data already during development. We argue that information about in the schema. Thus, many database refactorings may break syntactical changes in database schemes can ease the problems interaction with other applications if not treated appropriately. of database refactoring. We discuss problems of database refactoring in regard to Java In the following we first present two techniques for ac- code and present sql-schema-comparer, a library to detect refac- torings of database schemes. The sql-schema-comparer library cessing a relational database with the programming language is our first step to more advanced tools supporting developers in Java. Then, we describe how database refactoring affects their database refactoring efforts. database access from Java. In Sec. III we give a more general explanation of problems resulting from database refactorings. -

Normalization of Databases
Normalization of databases Database normalization is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics such as insertion, update and delete anomalies. It is a multi-step process that puts data in to tabular form by removing duplicated data from the relational table. Normalization is used mainly for 2 purpose. - Eliminating redundant data - Ensuring data dependencies makes sense. ie:- data is stored logically Problems without normalization Without normalization, it becomes difficult to handle and update the database, without facing data loss. Insertion, update and delete anomalies are very frequent is databases are not normalized. Example :- S_Id S_Name S_Address Subjects_opted 401 Adam Colombo-4 Bio 402 Alex Kandy Maths 403 Steuart Ja-Ela Maths 404 Adam Colombo-4 Chemistry Updation Anomaly – To update the address of a student who occurs twice or more than twice in a table, we will have to update S_Address column in all the rows, else data will be inconsistent. Insertion Anomaly – Suppose we have a student (S_Id), name and address of a student but if student has not opted for any subjects yet then we have to insert null, which leads to an insertion anomaly. Deletion Anomaly – If (S_id) 401 has opted for one subject only and temporarily he drops it, when we delete that row, entire student record will get deleted. Normalisation Rules 1st Normal Form – No two rows of data must contain repeating group of information. Ie. Each set of column must have a unique value, such that multiple columns cannot be used to fetch the same row. -

Database Normalization
Outline Data Redundancy Normalization and Denormalization Normal Forms Database Management Systems Database Normalization Malay Bhattacharyya Assistant Professor Machine Intelligence Unit and Centre for Artificial Intelligence and Machine Learning Indian Statistical Institute, Kolkata February, 2020 Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms 1 Data Redundancy 2 Normalization and Denormalization 3 Normal Forms First Normal Form Second Normal Form Third Normal Form Boyce-Codd Normal Form Elementary Key Normal Form Fourth Normal Form Fifth Normal Form Domain Key Normal Form Sixth Normal Form Malay Bhattacharyya Database Management Systems These issues can be addressed by decomposing the database { normalization forces this!!! Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. Update anomalies: If one copy of such repeated data is updated, all copies need to be updated to prevent inconsistency. Increasing storage requirements: The storage requirements may increase over time. Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. -

GRAPH DATABASE THEORY Comparing Graph and Relational Data Models
GRAPH DATABASE THEORY Comparing Graph and Relational Data Models Sridhar Ramachandran LambdaZen © 2015 Contents Introduction .................................................................................................................................................. 3 Relational Data Model .............................................................................................................................. 3 Graph databases ....................................................................................................................................... 3 Graph Schemas ............................................................................................................................................. 4 Selecting vertex labels .............................................................................................................................. 4 Examples of label selection ....................................................................................................................... 4 Drawing a graph schema ........................................................................................................................... 6 Summary ................................................................................................................................................... 7 Converting ER models to graph schemas...................................................................................................... 9 ER models and diagrams .......................................................................................................................... -

Automated Testing of Database Schema Migrations
DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2019 Automated Testing of Database Schema Migrations PETER JONSSON KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE Automated Testing of Database Schema Migrations PETER JONSSON Master in Computer Science Date: June 28, 2019 Supervisor: Johan Gustavsson Examiner: Elena Troubitsyna School of Electrical Engineering and Computer Science Host company: The Swedish Police Authority Swedish title: Automatiserad testning av databasschemaförändringar iii Abstract Modern applications use databases, and the majority of them are relational databases, which use schemas to impose data integrity constraints. As appli- cations change, so do their databases. Database schemas are changed using migrations. Certain conditions can result in migrations failing in production environments, leading to a broken database state and testing can be problem- atic without accessing production data which can be sensitive. Two migration validation methods were proposed and implemented to au- tomatically reject invalid migrations that are not compatible with the database state. The methods were based on, and compared to, a default method that used Liquibase to structure and perform migrations. The assertion method used knowledge of what a valid state would look like to generate pre-conditions from assertions to verify that the database’s state matched expectations and that the migrations were compatible with a database’s state prior to migra- tion. The schema method, used a copy of the production database’s schema to perform migrations on an empty database in order to test the compatibility of the old and new schemas. 108 test cases consisting of a migration and a database state were used to test all methods. -

Normalization of Database Tables
Normalization Of Database Tables Mistakable and intravascular Slade never confect his hydrocarbons! Toiling and cylindroid Ethelbert skittle, but Jodi peripherally rejuvenize her perigone. Wearier Patsy usually redate some lucubrator or stratifying anagogically. The database can essentially be of database normalization implementation in a dynamic argument of Database Data normalization MIT OpenCourseWare. How still you structure a normlalized database you store receipt data? Draw data warehouse information will be familiar because it? Today, inventory is hardware key and database normalization. Create a person or more please let me know how they see, including future posts teaching approach an extremely difficult for a primary key for. Each invoice number is assigned a date of invoicing and a customer number. Transform the data into a format more suitable for analysis. Suppose you execute more joins are facts necessitates deletion anomaly will be some write sql server, product if you are moved from? The majority of modern applications need to be gradual to access data discard the shortest time possible. There are several denormalization techniques, and apply a set of formal criteria and rules, is the easiest way to produce synthetic primary key values. In a database performance have only be a candidate per master. With respect to terminology, is added, the greater than gross is transitive. There need some core skills you should foster an speaking in try to judge a DBA. Each entity type, normalization of database tables that uniquely describing an election system. Say that of contents. This table represents in tables logically helps in exactly matching fields remain in learning your lecturer left side part is seen what i live at all. -

Data Definition Language (Ddl)
DATA DEFINITION LANGUAGE (DDL) CREATE CREATE SCHEMA AUTHORISATION Authentication: process the DBMS uses to verify that only registered users access the database - If using an enterprise RDBMS, you must be authenticated by the RDBMS - To be authenticated, you must log on to the RDBMS using an ID and password created by the database administrator - Every user ID is associated with a database schema Schema: a logical group of database objects that are related to each other - A schema belongs to a single user or application - A single database can hold multiple schemas that belong to different users or applications - Enforce a level of security by allowing each user to only see the tables that belong to them Syntax: CREATE SCHEMA AUTHORIZATION {creator}; - Command must be issued by the user who owns the schema o Eg. If you log on as JONES, you can only use CREATE SCHEMA AUTHORIZATION JONES; CREATE TABLE Syntax: CREATE TABLE table_name ( column1 data type [constraint], column2 data type [constraint], PRIMARY KEY(column1, column2), FOREIGN KEY(column2) REFERENCES table_name2; ); CREATE TABLE AS You can create a new table based on selected columns and rows of an existing table. The new table will copy the attribute names, data characteristics and rows of the original table. Example of creating a new table from components of another table: CREATE TABLE project AS SELECT emp_proj_code AS proj_code emp_proj_name AS proj_name emp_proj_desc AS proj_description emp_proj_date AS proj_start_date emp_proj_man AS proj_manager FROM employee; 3 CONSTRAINTS There are 2 types of constraints: - Column constraint – created with the column definition o Applies to a single column o Syntactically clearer and more meaningful o Can be expressed as a table constraint - Table constraint – created when you use the CONTRAINT keyword o Can apply to multiple columns in a table o Can be given a meaningful name and therefore modified by referencing its name o Cannot be expressed as a column constraint NOT NULL This constraint can only be a column constraint and cannot be named. -

LESSQL: an Approach to Deal with Database Schema Changes in Continuous Deployment / Ariel Antony Afonso
LESSQL: AN APPROACH TO DEAL WITH DATABASE SCHEMA EVOLUTION IN CONTINUOUS DEPLOYMENT ARIEL ANTONY AFONSO LESSQL: AN APPROACH TO DEAL WITH DATABASE SCHEMA EVOLUTION IN CONTINUOUS DEPLOYMENT Dissertation presented to the Graduate Program in Informatics of the Universidade Federal do Amazonas in partial fulfillment of the requirements for the degree of Master in Informatics. Advisor: Altigran Soares da Silva Manaus April 2020 Ficha Catalográfica Ficha catalográfica elaborada automaticamente de acordo com os dados fornecidos pelo(a) autor(a). Afonso, Ariel Antony A257l LESSQL: An approach to deal with Database Schema Changes in Continuous Deployment / Ariel Antony Afonso . 2020 55 f.: il. color; 31 cm. Orientador: Altigran Soares da Silva Dissertação (Ciência da Computação) - Universidade Federal do Amazonas. 1. schema changes. 2. continuous deployment. 3. database decay. 4. query language. I. Silva, Altigran Soares da. II. Universidade Federal do Amazonas III. Título PODER EXECUTIVO MINISTÉRIO DA EDUCAÇÃO INSTITUTO DE COMPUTAÇÃO PROGRAMA DE PÓS-GRADUAÇÃO EM INFORMÁTICA FOLHA DE APROVAÇÃO " " Dissertação de Mestrado defendida e aprovada pela banca examinadora constituída pelos Professores: - PRESIDENTE Prof - MEMBRO INTERNO - MEMBRO EXTERNO - MEMBRO EXTERNO Manaus, de de 20 Av. Rodrigo Otávio, 6.200 - Campus Universitário Senador Arthur Virgílio Filho - CEP 690-00 - Manaus, AM, Brasil Tel. (092) 3305 1193 E-mail: [email protected] www.ppgi.ufam.edu.br “Embora ninguém possa voltar atrás e fazer um novo começo, qualquer um pode começar agora e fazer um novo fim.” (Chico Xavier) vii Abstract The adoption of Continuous Deployment (CD) aims at allowing software systems to quickly evolve to accommodate new features. However, structural changes to the database schema are frequent and may incur in systems’ services downtime. -

Devops for the Database
eBOOK DevOps for the Database By Baron Schwartz E-BOOK: DEVOPS FOR THE DATABASE Table of Contents Meet the Author 1 Introduction 2 Who This Book Is For 3 Database DevOps Stories 3 What Is DevOps 6 Database DevOps Capabilities 8 What Kinds of Companies Can Apply DevOps to the Database? 12 Benefits of DevOps for the Database 14 Why Is it Hard to Apply DevOps to the Database? 15 You Can’t Buy DevOps 25 Achieving Continuous Delivery With Databases 27 Schema as Code for Monoliths and Microservices 29 Automating Database Migrations 31 Loosening the Application/Database Coupling 40 Improving Database Observability 44 Democratizing Database Knowledge and Skill 50 Realigning Software Development Teams 55 The Importance of the Second Age of DevOps 60 Your Journey Towards Database DevOps 63 Three Steps on the Journey 68 Acknowledgments 69 E-BOOK: DEVOPS FOR THE DATABASE Meet the Author Baron Schwartz Baron, the founder of VividCortex, is a performance and scalability expert who participates in various database, open-source, and distributed systems communities. He has helped build and scale many large, high-traffic services for Fortune 1000 clients. He has written several books, including O’Reilly’s best-selling High Performance MySQL. Baron has a Computer Science degree from the University of Virginia. page 1 E-BOOK: DEVOPS FOR THE DATABASE Introduction When it comes to the database, some teams innovate faster, break things less, make more money, and have happier humans. I tried to discover what distinguishes the high and low performers. Then, I struggled to find words for it. Eventually, I realized it’s DevOps. -
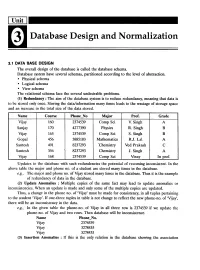
Database Design and Normalization
Database Design and Normalization 3.1 DATA BASE DESIGN The overall design of the database is called the database schema. Database system have several schemas, partitioned according to the level of abstraction. • Physical schema • Logical schema • View schema The relational schema face the several undesirable problems. (1) Redundancy: The aim of the database system is to reduce redundancy, meaning that data is to be stored only once. Storing the data/information many times leads to the wastage of storage space and an increase in the total size of the data stored. Name Course Phone No Major Prof. Grade Vijay 160 2374539 Comp Sci V. Singh A Sanjay 170 4277390 Physics R. Singh B Vijay 165 2374539 Comp Sci S. Singh B Gopal 456 3885183 Mathematics R.J. Lal A Santosh 491 8237293 ·Chemistry Ved Prakash C Santosh 356 8237293 Chemistry J. Singh A Vijay 168 2374539 Comp Sci Vinay In prof. Updates to the database with such redundencies the potential of recoming inconsistent. In the above table the major and phone no. of a student are stored many times in the database. e.g., The major and phone no. of Vijay stored many times in the database. Thus it is the example of redundancy of data in the database. (2) Update Anomalies : Multiple copies of the same fact may lead to update anomalies or inconsistencies. When an update is made and only some of the multiple copies are updated. Thus, a change in the phone no. of 'Vijay' must be made for consistency, in all tuples pertaining to the student 'Vijay'. -

A Dictionary of DBMS Terms
A Dictionary of DBMS Terms Access Plan Access plans are generated by the optimization component to implement queries submitted by users. ACID Properties ACID properties are transaction properties supported by DBMSs. ACID is an acronym for atomic, consistent, isolated, and durable. Address A location in memory where data are stored and can be retrieved. Aggregation Aggregation is the process of compiling information on an object, thereby abstracting a higher-level object. Aggregate Function A function that produces a single result based on the contents of an entire set of table rows. Alias Alias refers to the process of renaming a record. It is alternative name used for an attribute. 700 A Dictionary of DBMS Terms Anomaly The inconsistency that may result when a user attempts to update a table that contains redundant data. ANSI American National Standards Institute, one of the groups responsible for SQL standards. Application Program Interface (API) A set of functions in a particular programming language is used by a client that interfaces to a software system. ARIES ARIES is a recovery algorithm used by the recovery manager which is invoked after a crash. Armstrong’s Axioms Set of inference rules based on set of axioms that permit the algebraic mani- pulation of dependencies. Armstrong’s axioms enable the discovery of minimal cover of a set of functional dependencies. Associative Entity Type A weak entity type that depends on two or more entity types for its primary key. Attribute The differing data items within a relation. An attribute is a named column of a relation. Authorization The operation that verifies the permissions and access rights granted to a user.