Lessons Learned in Version Control
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pragmatic Version Control Using Subversion
What readers are saying about Pragmatic Version Control using Subversion I expected a lot, but you surprised me with even more. Hav- ing used CVS for years I hesitated to try Subversion until now, although I knew it would solve many of the shortcom- ings of CVS. After reading your book, my excuses to stay with CVS disappeared. Oh, and coming from the Pragmatic Bookshelf this book is fun to read too. Thanks Mike. Steffen Gemkow Managing Director, ObjectFab GmbH I’m a long-time user of CVS and I’ve been skeptical of Sub- version, wondering if it would ever be “ready for prime time.” Until now. Thanks to Mike Mason for writing a clear, con- cise, gentle introduction to this new tool. After reading this book, I’m actually excited about the possibilities for version control that Subversion brings to the table. David Rupp Senior Software Engineer, Great-West Life & Annuity This was exactly the Subversion book I was waiting for. As a long-time Perforce and CVS user and administrator, and in my role as an agile tools coach, I wanted a compact book that told me just what I needed to know. This is it. Within a couple of hours I was up and running against remote Subversion servers, and setting up my own local servers too. Mike uses a lot of command-line examples to guide the reader, and as a Windows user I was worried at first. My fears were unfounded though—Mike’s examples were so clear that I think I’ll stick to using the command line from now on! I thoroughly recommend this book to anyone getting started using or administering Subversion. -

Version Control 101 Exported from Please Visit the Link for the Latest Version and the Best Typesetting
Version Control 101 Exported from http://cepsltb4.curent.utk.edu/wiki/efficiency/vcs, please visit the link for the latest version and the best typesetting. Version Control 101 is created in the hope to minimize the regret from lost files or untracked changes. There are two things I regret. I should have learned Python instead of MATLAB, and I should have learned version control earlier. Version control is like a time machine. It allows you to go back in time and find out history files. You might have heard of GitHub and Git and probably how steep the learning curve is. Version control is not just Git. Dropbox can do version control as well, for a limited time. This tutorial will get you started with some version control concepts from Dropbox to Git for your needs. More importantly, some general rules are suggested to minimize the chance of file losses. Contents Version Control 101 .............................................................................................................................. 1 General Rules ................................................................................................................................... 2 Version Control for Files ................................................................................................................... 2 DropBox or Google Drive ............................................................................................................. 2 Version Control on Confluence ................................................................................................... -

Common Tools for Team Collaboration Problem: Working with a Team (Especially Remotely) Can Be Difficult
Common Tools for Team Collaboration Problem: Working with a team (especially remotely) can be difficult. ▹ Team members might have a different idea for the project ▹ Two or more team members could end up doing the same work ▹ Or a few team members have nothing to do Solutions: A combination of few tools. ▹ Communication channels ▹ Wikis ▹ Task manager ▹ Version Control ■ We’ll be going in depth with this one! Important! The tools are only as good as your team uses them. Make sure all of your team members agree on what tools to use, and train them thoroughly! Communication Channels Purpose: Communication channels provide a way to have team members remotely communicate with one another. Ideally, the channel will attempt to emulate, as closely as possible, what communication would be like if all of your team members were in the same office. Wait, why not email? ▹ No voice support ■ Text alone is not a sufficient form of communication ▹ Too slow, no obvious support for notifications ▹ Lack of flexibility in grouping people Tools: ▹ Discord ■ discordapp.com ▹ Slack ■ slack.com ▹ Riot.im ■ about.riot.im Discord: Originally used for voice-chat for gaming, Discord provides: ▹ Voice & video conferencing ▹ Text communication, separated by channels ▹ File-sharing ▹ Private communications ▹ A mobile, web, and desktop app Slack: A business-oriented text communication that also supports: ▹ Everything Discord does, plus... ▹ Threaded conversations Riot.im: A self-hosted, open-source alternative to Slack Wikis Purpose: Professionally used as a collaborative game design document, a wiki is a synchronized documentation tool that retains a thorough history of changes that occured on each page. -

Sistemas De Control De Versiones De Última Generación (DCA)
Tema 10 - Sistemas de Control de Versiones de última generación (DCA) Antonio-M. Corbí Bellot Tema 10 - Sistemas de Control de Versiones de última generación (DCA) II HISTORIAL DE REVISIONES NÚMERO FECHA MODIFICACIONES NOMBRE Tema 10 - Sistemas de Control de Versiones de última generación (DCA) III Índice 1. ¿Qué es un Sistema de Control de Versiones (SCV)?1 2. ¿En qué consiste el control de versiones?1 3. Conceptos generales de los SCV (I) 1 4. Conceptos generales de los SCV (II) 2 5. Tipos de SCV. 2 6. Centralizados vs. Distribuidos en 90sg 2 7. ¿Qué opciones tenemos disponibles? 2 8. ¿Qué podemos hacer con un SCV? 3 9. Tipos de ramas 3 10. Formas de integrar una rama en otra (I)3 11. Formas de integrar una rama en otra (II)4 12. SCV’s con los que trabajaremos 4 13. Git (I) 5 14. Git (II) 5 15. Git (III) 5 16. Git (IV) 6 17. Git (V) 6 18. Git (VI) 7 19. Git (VII) 7 20. Git (VIII) 7 21. Git (IX) 8 22. Git (X) 8 23. Git (XI) 9 Tema 10 - Sistemas de Control de Versiones de última generación (DCA) IV 24. Git (XII) 9 25. Git (XIII) 9 26. Git (XIV) 10 27. Git (XV) 10 28. Git (XVI) 11 29. Git (XVII) 11 30. Git (XVIII) 12 31. Git (XIX) 12 32. Git. Vídeos relacionados 12 33. Mercurial (I) 12 34. Mercurial (II) 12 35. Mercurial (III) 13 36. Mercurial (IV) 13 37. Mercurial (V) 13 38. Mercurial (VI) 14 39. -

Microservices and Monorepos
Microservices and Monorepos Match made in heaven? Sven Erik Knop, Perforce Software Overview . Microservices refresher . Microservices and versioning . What are Monorepos and why use them? . These two concepts seem to contradict – why mix them together? . The magic of narrow cloning . A match made in heaven! 2 Why Microservices? . Monolithic approach: App 3 Database Microservices approach . Individual Services 4 DB DB Database Versioning Microservices . Code . Executables and Containers . Configuration . Natural choice: individual repositories for each service Git . But: • Security • Visibility • Refactoring • Single change id to rule them all? 5 Monorepo . Why would you use a monorepo? . Who is using monorepos? . How would you use a monorepo? 6 Monorepos: Why would you do this? . Single Source of Truth for all projects . Simplified security . Configuration and Refactoring across entire application . Single change id across all projects . Examples: • Google, Facebook, Twitter, Salesforce, ... 7 Single change across projects change 314156 8 Monorepos: Antipatterns User workspace User workspace 9 Monorepos – view mapping User workspace . Map one or more services . Users only access files they need . Simplified pushing of changes 10 What does this have to do with Git? . Git does not support Monorepos • Limitations on number and size of files, history, contributing users • Companies have tried and failed . Android source spread over a thousand Git repositories • Requires repo and gerrit to work with 11 How can we square this circle? https://en.wikipedia.org/wiki/Squaring_the_circle 12 Narrow cloning! . Clone individual projects/services . Clone a group of projects into a single repo 13 Working with narrowly cloned repos . Users work normally in Git . Fetch and push changes from and to monorepo . -

Version Control – Agile Workflow with Git/Github
Version Control – Agile Workflow with Git/GitHub 19/20 November 2019 | Guido Trensch (JSC, SimLab Neuroscience) Content Motivation Version Control Systems (VCS) Understanding Git GitHub (Agile Workflow) References Forschungszentrum Jülich, JSC:SimLab Neuroscience 2 Content Motivation Version Control Systems (VCS) Understanding Git GitHub (Agile Workflow) References Forschungszentrum Jülich, JSC:SimLab Neuroscience 3 Motivation • Version control is one aspect of configuration management (CM). The main CM processes are concerned with: • System building • Preparing software for releases and keeping track of system versions. • Change management • Keeping track of requests for changes, working out the costs and impact. • Release management • Preparing software for releases and keeping track of system versions. • Version control • Keep track of different versions of software components and allow independent development. [Ian Sommerville,“Software Engineering”] Forschungszentrum Jülich, JSC:SimLab Neuroscience 4 Motivation • Keep track of different versions of software components • Identify, store, organize and control revisions and access to it • Essential for the organization of multi-developer projects is independent development • Ensure that changes made by different developers do not interfere with each other • Provide strategies to solve conflicts CONFLICT Alice Bob Forschungszentrum Jülich, JSC:SimLab Neuroscience 5 Content Motivation Version Control Systems (VCS) Understanding Git GitHub (Agile Workflow) References Forschungszentrum Jülich, -
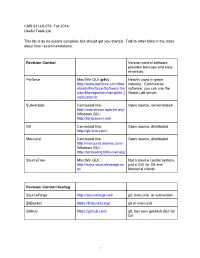
Useful Tools for Game Making
CMS.611J/6.073 Fall 2014 Useful Tools List This list is by no means complete, but should get you started. Talk to other folks in the class about their recommendations. Revision Control Version control software, provides backups and easy reversion. Perforce Mac/Win GUI (p4v): Heavily used in game http://www.perforce.com/dow industry. Commercial nloads/Perforce-Software-Ver software; you can use the sion-Management/complete_l Game Lab server. ist/Customer Subversion Command line: Open source, server-based http://subversion.apache.org/ Windows GUI: http://tortoisesvn.net/ Git Command line: Open source, distributed http://git-scm.com/ Mercurial Command line: Open source, distributed http://mercurial.selenic.com/ Windows GUI: http://tortoisehg.bitbucket.org/ SourceTree Mac/Win GUI: Not a source control system, http://www.sourcetreeapp.co just a GUI for Git and m/ Mercurial clients Revision Control Hosting SourceForge http://sourceforge.net/ git, mercurial, or subversion BitBucket https://bitbucket.org/ git or mercurial GitHub https://github.com/ git, has own (painful) GUI for Git 1 Image Editing MSPaint Windows, pre-installed Surprisingly useful quick pixel art editor (esp for prototypes) Paint.NET Windows, About as easy as MSPaint, but http://www.getpaint.net/download much more powerful .html Photoshop Mac, Windows New Media Center, 26-139 GIMP Many platforms, Easier than photoshop, at http://www.gimp.org/downloads/ least. Sound GarageBand Mac New Media Center, 26-139 Audacity Many platforms, Free, open source. http://audacity.sourceforge.ne -

Distributed Revision Control with Mercurial
Distributed revision control with Mercurial Bryan O’Sullivan Copyright c 2006, 2007 Bryan O’Sullivan. This material may be distributed only subject to the terms and conditions set forth in version 1.0 of the Open Publication License. Please refer to Appendix D for the license text. This book was prepared from rev 028543f67bea, dated 2008-08-20 15:27 -0700, using rev a58a611c320f of Mercurial. Contents Contents i Preface 2 0.1 This book is a work in progress ...................................... 2 0.2 About the examples in this book ..................................... 2 0.3 Colophon—this book is Free ....................................... 2 1 Introduction 3 1.1 About revision control .......................................... 3 1.1.1 Why use revision control? .................................... 3 1.1.2 The many names of revision control ............................... 4 1.2 A short history of revision control .................................... 4 1.3 Trends in revision control ......................................... 5 1.4 A few of the advantages of distributed revision control ......................... 5 1.4.1 Advantages for open source projects ............................... 6 1.4.2 Advantages for commercial projects ............................... 6 1.5 Why choose Mercurial? .......................................... 7 1.6 Mercurial compared with other tools ................................... 7 1.6.1 Subversion ............................................ 7 1.6.2 Git ................................................ 8 1.6.3 -

Scaling Git with Bitbucket Data Center
Scaling Git with Bitbucket Data Center Considerations for large teams switching to Git Contents What is Git, why do I want it, and why is it hard to scale? 01 Scaling Git with Bitbucket Data Center 05 What about compliance? 11 Why choose Bitbucket Data Center? 13 01 What is Git, why do I want it, and why is it hard to scale? So. Your software team is expanding and taking on more high-value projects. That’s great news! The bad news, however, is that your centralized version control system isn’t really cutting it anymore. For growing IT organizations, Some of the key benefits Codebase safety moving to a distributed version control system is now of adopting Git are: Git is designed with maintaining the integrity considered an inevitable shift. This paper outlines some of managed source code as a top priority, using secure algorithms to preserve your code, change of the benefits of Git as a distributed version control system history, and traceability against both accidental and how Bitbucket Data Center can help your company scale and malicious change. Distributed development its Git-powered operations smoothly. Community Distributed development gives each developer a working copy of the full repository history, Git has become the expected version control making development faster by speeding up systems in many circles, and is very popular As software development increases in complexity, and the commit process and reducing developers’ among open source projects. This means its easy development teams become more globalized, centralized interdependence, as well as their dependence to take advantage of third party libraries and on a network connection. -

Hg Mercurial Cheat Sheet Serge Y
Hg Mercurial Cheat Sheet Serge Y. Stroobandt Copyright 2013–2020, licensed under Creative Commons BY-NC-SA #This page is work in progress! Much of the explanatory text still needs to be written. Nonetheless, the basic outline of this page may already be useful and this is why I am sharing it. In the mean time, please, bare with me and check back for updates. Distributed revision control Why I went with Mercurial • Python, Mozilla, Java, Vim • Mercurial has been better supported under Windows. • Mercurial also offers named branches Emil Sit: • August 2008: Mercurial offers a comfortable command-line experience, learning Git can be a bit daunting • December 2011: Git has three “philosophical” distinctions in its favour, as well as more attention to detail Lowest common denominator It is more important that people start using dis- tributed revision control instead of nothing at all. The Pro Git book is available online. Collaboration styles • Mercurial working practices • Collaborating with other people Use SSH shorthand 1 Installation $ sudo apt-get update $ sudo apt-get install mercurial mercurial-git meld Configuration Local system-wide configuration $ nano .bashrc export NAME="John Doe" export EMAIL="[email protected]" $ source .bashrc ~/.hgrc on a client user@client $ nano ~/.hgrc [ui] username = user@client editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = 2 ~/.hgrc on the server user@server $ nano ~/.hgrc [ui] username = user@server editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = [hooks] changegroup = hg update >&2 Initiating One starts with initiate a new repository. -

Branching Strategies with Distributed Version Control in Agile Projects
Branching Strategies with Distributed Version Control in Agile Projects David Arve March 2, 2010 Abstract Branching strategies play an integral part in traditional software de- velopment. In Agile projects however branching is seen as the opposite to embracing change and therefor given little attention. This paper describes what branching strategies would support an agile workflow. It also describes how a distributed version control tool will fit better around these branching strategies then a centralized tool. This pa- per puts forth some original work on what branching strategies and team organization that fully takes advantage of a distributed version control tool. This paper aims to describe how a distributed version control can support agile teams with advanced branching strategies without slowing down or complicating the lightweight agile processes. 1 Introduction Software development is a process that produces a massive amount of highly complicated content. All of this content is produced by teams that range from just a few developers up to several thousands. It is obvious that this process needs to be highly coordinated. The coordination of this content is a part of Software configuration management (SCM). Traditionally this has been done by a centralized version control tool. [2] Branching strategies have not gained a lot of popularity in agile teams. [3] In recent years several new version control tools have emerged. These new tools break with the standard model of centralized version control (CVC) made popular by tools like CVS [9] and Subversion[6]. The new tools are based on a distributed model. Recent tools include Arch [5], Bazaar [8], BitKeeper [7] and Git [11]. -

An Introduction to Mercurial Version Control Software
An Introduction to Mercurial Version Control Software CS595, IIT [Doc Updated by H. Zhang] Oct, 2010 Satish Balay [email protected] Outline ● Why use version control? ● Simple example of revisioning ● Mercurial introduction - Local usage - Remote usage - Normal user workflow - Organizing repositories [clones] ● Further Information ● [Demo] What do we use Version Control for? ● Keep track of changes to files ● Enable multiple users editing files simultaneously ● Go back and check old changes: * what was the change * when was the change made * who made the change * why was the change made ● Manage branches [release versions vs development] Simple Example of Revisioning main.c File Changes File Version 0 1 2 3 Delta Simple Example Cont. main.c 0 1 2 3 makefilemain.c 0 1 Repository -1 0 1 2 3 Version Changeset Concurrent Changes to a File by Multiple Users & Subsequent Merge of Changes Line1 Line1 Line1 Line1 Line2 UserA Line2 UserA Line3 Line2 Line3 Line2 Line4 Line3 UserB Line3 Line4 Line4 UserB Line4 Initial file UserA edit UserB edit Merge edits by both users Merge tools: r-2 ● kdiff3 Branch Merge ● meld r-4 Merge types: ● 2-way r-1 ● 3-way Revision Graph r-3 Some Definitions ● Delta: a single change [to a file] ● Changeset: a collection of deltas [perhaps to multiple files] that are collectively tracked. This captures a snapshot of the current state of the files [as a revision] ● Branch: Concurrent development paths for the same sources ● Merge: Joining changes done in multiple branches into a single path. ● Repository: collection of files we intend to keep track of.