Pruning Processes and a New Characterization of Convex Geometries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![Arxiv:1508.05446V2 [Math.CO] 27 Sep 2018 02,5B5 16E10](https://docslib.b-cdn.net/cover/2098/arxiv-1508-05446v2-math-co-27-sep-2018-02-5b5-16e10-542098.webp)
Arxiv:1508.05446V2 [Math.CO] 27 Sep 2018 02,5B5 16E10
CELL COMPLEXES, POSET TOPOLOGY AND THE REPRESENTATION THEORY OF ALGEBRAS ARISING IN ALGEBRAIC COMBINATORICS AND DISCRETE GEOMETRY STUART MARGOLIS, FRANCO SALIOLA, AND BENJAMIN STEINBERG Abstract. In recent years it has been noted that a number of combi- natorial structures such as real and complex hyperplane arrangements, interval greedoids, matroids and oriented matroids have the structure of a finite monoid called a left regular band. Random walks on the monoid model a number of interesting Markov chains such as the Tsetlin library and riffle shuffle. The representation theory of left regular bands then comes into play and has had a major influence on both the combinatorics and the probability theory associated to such structures. In a recent pa- per, the authors established a close connection between algebraic and combinatorial invariants of a left regular band by showing that certain homological invariants of the algebra of a left regular band coincide with the cohomology of order complexes of posets naturally associated to the left regular band. The purpose of the present monograph is to further develop and deepen the connection between left regular bands and poset topology. This allows us to compute finite projective resolutions of all simple mod- ules of unital left regular band algebras over fields and much more. In the process, we are led to define the class of CW left regular bands as the class of left regular bands whose associated posets are the face posets of regular CW complexes. Most of the examples that have arisen in the literature belong to this class. A new and important class of ex- amples is a left regular band structure on the face poset of a CAT(0) cube complex. -

Cayley's and Holland's Theorems for Idempotent Semirings and Their
Cayley's and Holland's Theorems for Idempotent Semirings and Their Applications to Residuated Lattices Nikolaos Galatos Department of Mathematics University of Denver [email protected] Rostislav Horˇc´ık Institute of Computer Sciences Academy of Sciences of the Czech Republic [email protected] Abstract We extend Cayley's and Holland's representation theorems to idempotent semirings and residuated lattices, and provide both functional and relational versions. Our analysis allows for extensions of the results to situations where conditions are imposed on the order relation of the representing structures. Moreover, we give a new proof of the finite embeddability property for the variety of integral residuated lattices and many of its subvarieties. 1 Introduction Cayley's theorem states that every group can be embedded in the (symmetric) group of permutations on a set. Likewise, every monoid can be embedded into the (transformation) monoid of self-maps on a set. C. Holland [10] showed that every lattice-ordered group can be embedded into the lattice-ordered group of order-preserving permutations on a totally-ordered set. Recall that a lattice-ordered group (`-group) is a structure G = hG; _; ^; ·;−1 ; 1i, where hG; ·;−1 ; 1i is group and hG; _; ^i is a lattice, such that multiplication preserves the order (equivalently, it distributes over joins and/or meets). An analogous representation was proved also for distributive lattice-ordered monoids in [2, 11]. We will prove similar theorems for resid- uated lattices and idempotent semirings in Sections 2 and 3. Section 4 focuses on the finite embeddability property (FEP) for various classes of idempotent semirings and residuated lat- tices. -

LATTICE THEORY of CONSENSUS (AGGREGATION) an Overview
Workshop Judgement Aggregation and Voting September 9-11, 2011, Freudenstadt-Lauterbad 1 LATTICE THEORY of CONSENSUS (AGGREGATION) An overview Bernard Monjardet CES, Université Paris I Panthéon Sorbonne & CAMS, EHESS Workshop Judgement Aggregation and Voting September 9-11, 2011, Freudenstadt-Lauterbad 2 First a little precision In their kind invitation letter, Klaus and Clemens wrote "Like others in the judgment aggregation community, we are aware of the existence of a sizeable amount of work of you and other – mainly French – authors on generalized aggregation models". Indeed, there is a sizeable amount of work and I will only present some main directions and some main results. Now here a list of the main contributors: Workshop Judgement Aggregation and Voting September 9-11, 2011, Freudenstadt-Lauterbad 3 Bandelt H.J. Germany Barbut, M. France Barthélemy, J.P. France Crown, G.D., USA Day W.H.E. Canada Janowitz, M.F. USA Mulder H.M. Germany Powers, R.C. USA Leclerc, B. France Monjardet, B. France McMorris F.R. USA Neumann, D.A. USA Norton Jr. V.T USA Powers, R.C. USA Roberts F.S. USA Workshop Judgement Aggregation and Voting September 9-11, 2011, Freudenstadt-Lauterbad 4 LATTICE THEORY of CONSENSUS (AGGREGATION) : An overview OUTLINE ABSTRACT AGGREGATION THEORIES: WHY? HOW The LATTICE APPROACH LATTICES: SOME RECALLS The CONSTRUCTIVE METHOD The federation consensus rules The AXIOMATIC METHOD Arrowian results The OPTIMISATION METHOD Lattice metric rules and the median procedure The "good" lattice structures for medians: Distributive lattices Median semilattice Workshop Judgement Aggregation and Voting September 9-11, 2011, Freudenstadt-Lauterbad 5 ABSTRACT CONSENSUS THEORIES: WHY? "since Arrow’s 1951 theorem, there has been a flurry of activity designed to prove analogues of this theorem in other contexts, and to establish contexts in which the rather dismaying consequences of this theorem are not necessarily valid. -

Problems and Comments on Boolean Algebras Rosen, Fifth Edition: Chapter 10; Sixth Edition: Chapter 11 Boolean Functions
Problems and Comments on Boolean Algebras Rosen, Fifth Edition: Chapter 10; Sixth Edition: Chapter 11 Boolean Functions Section 10. 1, Problems: 1, 2, 3, 4, 10, 11, 29, 36, 37 (fifth edition); Section 11.1, Problems: 1, 2, 5, 6, 12, 13, 31, 40, 41 (sixth edition) The notation ""forOR is bad and misleading. Just think that in the context of boolean functions, the author uses instead of ∨.The integers modulo 2, that is ℤ2 0,1, have an addition where 1 1 0 while 1 ∨ 1 1. AsetA is partially ordered by a binary relation ≤, if this relation is reflexive, that is a ≤ a holds for every element a ∈ S,it is transitive, that is if a ≤ b and b ≤ c hold for elements a,b,c ∈ S, then one also has that a ≤ c, and ≤ is anti-symmetric, that is a ≤ b and b ≤ a can hold for elements a,b ∈ S only if a b. The subsets of any set S are partially ordered by set inclusion. that is the power set PS,⊆ is a partially ordered set. A partial ordering on S is a total ordering if for any two elements a,b of S one has that a ≤ b or b ≤ a. The natural numbers ℕ,≤ with their ordinary ordering are totally ordered. A bounded lattice L is a partially ordered set where every finite subset has a least upper bound and a greatest lower bound.The least upper bound of the empty subset is defined as 0, it is the smallest element of L. -

ON DISCRETE IDEMPOTENT PATHS Luigi Santocanale
ON DISCRETE IDEMPOTENT PATHS Luigi Santocanale To cite this version: Luigi Santocanale. ON DISCRETE IDEMPOTENT PATHS. Words 2019, Sep 2019, Loughborough, United Kingdom. pp.312–325, 10.1007/978-3-030-28796-2_25. hal-02153821 HAL Id: hal-02153821 https://hal.archives-ouvertes.fr/hal-02153821 Submitted on 12 Jun 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ON DISCRETE IDEMPOTENT PATHS LUIGI SANTOCANALE Laboratoire d’Informatique et des Syst`emes, UMR 7020, Aix-Marseille Universit´e, CNRS Abstract. The set of discrete lattice paths from (0, 0) to (n, n) with North and East steps (i.e. words w x, y such that w x = w y = n) has a canonical monoid structure inher- ∈ { }∗ | | | | ited from the bijection with the set of join-continuous maps from the chain 0, 1,..., n to { } itself. We explicitly describe this monoid structure and, relying on a general characteriza- tion of idempotent join-continuous maps from a complete lattice to itself, we characterize idempotent paths as upper zigzag paths. We argue that these paths are counted by the odd Fibonacci numbers. Our method yields a geometric/combinatorial proof of counting results, due to Howie and to Laradji and Umar, for idempotents in monoids of monotone endomaps on finite chains. -

An Efficient Algorithm for Fully Robust Stable Matchings Via Join
An Efficient Algorithm for Fully Robust Stable Matchings via Join Semi-Sublattices Tung Mai∗1 and Vijay V. Vazirani2 1Adobe Research 2University of California, Irvine Abstract We are given a stable matching instance A and a set S of errors that can be introduced into A. Each error consists of applying a specific permutation to the preference list of a chosen boy or a chosen girl. Assume that A is being transmitted over a channel which introduces one error from set S; as a result, the channel outputs this new instance. We wish to find a matching that is stable for A and for each of the jSj possible new instances. If S is picked from a special class of errors, we give an O(jSjp(n)) time algorithm for this problem. We call the obtained matching a fully robust stable matching w.r.t. S. In particular, if S is polynomial sized, then our algorithm runs in polynomial time. Our algorithm is based on new, non-trivial structural properties of the lattice of stable matchings; these properties pertain to certain join semi-sublattices of the lattice. Birkhoff’s Representation Theorem for finite distributive lattices plays a special role in our algorithms. 1 Introduction The two topics, of stable matching and the design of algorithms that produce solutions that are robust to errors, have been studied extensively for decades and there are today several books on each of them, e.g., see [Knu97, GI89, Man13] and [CE06, BTEGN09]. Yet, there is a paucity of results at the intersection of these two topics. -

What Convex Geometries Tell About Shattering-Extremal Systems Bogdan Chornomaz
What convex geometries tell about shattering-extremal systems Bogdan Chornomaz To cite this version: Bogdan Chornomaz. What convex geometries tell about shattering-extremal systems. 2020. hal- 02869292 HAL Id: hal-02869292 https://hal.archives-ouvertes.fr/hal-02869292 Preprint submitted on 15 Jun 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. What convex geometries tell about shattering-extremal systems Bogdan Chornomaz [email protected] Vanderbilt University 1 Introduction Convex geometries admit many seemingly distinct yet equivalent characteriza- tions. Among other things, they are known to be exactly shattering-extremal closure systems [2]. In this paper we exploit this connection and generalize some known characterizations of convex geometries to shattering-extremal set families, which are a subject of intensive study in their own right. Our first main result is Theorem 2 in Section 4, which characterizes shattering- extremal set families in terms of forbidden projections, similar to the character- ization of convex geometries by Dietrich [3], discussed in Section 3. Another known characterization of convex geometries, given in Theorem 3, is that they are exactly closure systems in which any non-maximal set can be extended by one element. -
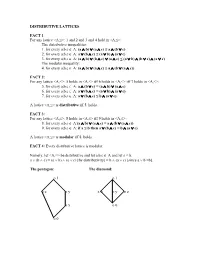
DISTRIBUTIVE LATTICES FACT 1: for Any Lattice <A,≤>: 1 and 2 and 3 and 4 Hold in <A,≤>: the Distributive Inequal
DISTRIBUTIVE LATTICES FACT 1: For any lattice <A,≤>: 1 and 2 and 3 and 4 hold in <A,≤>: The distributive inequalities: 1. for every a,b,c ∈ A: (a ∧ b) ∨ (a ∧ c) ≤ a ∧ (b ∨ c) 2. for every a,b,c ∈ A: a ∨ (b ∧ c) ≤ (a ∨ b) ∧ (a ∨ c) 3. for every a,b,c ∈ A: (a ∧ b) ∨ (b ∧ c) ∨ (a ∧ c) ≤ (a ∨ b) ∧ (b ∨ c) ∧ (a ∨ c) The modular inequality: 4. for every a,b,c ∈ A: (a ∧ b) ∨ (a ∧ c) ≤ a ∧ (b ∨ (a ∧ c)) FACT 2: For any lattice <A,≤>: 5 holds in <A,≤> iff 6 holds in <A,≤> iff 7 holds in <A,≤>: 5. for every a,b,c ∈ A: a ∧ (b ∨ c) = (a ∧ b) ∨ (a ∧ c) 6. for every a,b,c ∈ A: a ∨ (b ∧ c) = (a ∨ b) ∧ (a ∨ c) 7. for every a,b,c ∈ A: a ∨ (b ∧ c) ≤ b ∧ (a ∨ c). A lattice <A,≤> is distributive iff 5. holds. FACT 3: For any lattice <A,≤>: 8 holds in <A,≤> iff 9 holds in <A,≤>: 8. for every a,b,c ∈ A:(a ∧ b) ∨ (a ∧ c) = a ∧ (b ∨ (a ∧ c)) 9. for every a,b,c ∈ A: if a ≤ b then a ∨ (b ∧ c) = b ∧ (a ∨ c) A lattice <A,≤> is modular iff 8. holds. FACT 4: Every distributive lattice is modular. Namely, let <A,≤> be distributive and let a,b,c ∈ A and let a ≤ b. a ∨ (b ∧ c) = (a ∨ b) ∧ (a ∨ c) [by distributivity] = b ∧ (a ∨ c) [since a ∨ b =b]. The pentagon: The diamond: o 1 o 1 o z o y x o o y o z o x o 0 o 0 THEOREM 5: A lattice is modular iff the pentagon cannot be embedded in it. -

Clustering on Antimatroids and Convex Geometries
Clustering on antimatroids and convex geometries YULIA KEMPNER1 , ILYA MUCHNIK2 1Department of Computer Science Holon Academic Institute of Technology 52 Golomb Str., P.O. Box 305, Holon 58102 ISRAEL 2Department of Computer Science Rutgers University, NJ, DIMACS 96 Frelinghuysen Road , Piscataway, NJ 08854-8018 US Abstract: - The clustering problem as a problem of set function optimization with constraints is considered. The behavior of quasi-concave functions on antimatroids and on convex geometries is investigated. The duality of these two set function optimizations is proved. The greedy type Chain algorithm, which allows to find an optimal cluster, both as the “most distant” group on antimatroids and as a dense cluster on convex geometries, is described. Key-Words: - Quasi-concave function, antimatroid, convex geometry, cluster, greedy algorithm 1 Introduction clustering. We found that such situations can be In this paper we consider the problem of clustering characterized as constructively defined families of on antimatroids and on convex geometries. There subsets, such that only elements from these families are two approaches to clustering. In the first one we can be considered as feasible clusters. For example, try to find extreme dense clusters (either as a let us consider a boolean matrix of data in which partition of the considered set of objects into variables (columns of matrix) are divided into homogeneous groups, or as a single tight set of several groups. Variables, belonging to one group, objects). The second approach finds a cluster which are ordered. In this case every group of variables can is the “most distant” from its complementary subset be interpreted as a complex variable which represent in the whole set (as in the single linkage clustering an ordinal scale for some property: value 1 of the method) without a control how close are objects first (according to the order) boolean variable means within a cluster. -

Order Dimension, Strong Bruhat Order and Lattice Properties for Posets
Order Dimension, Strong Bruhat Order and Lattice Properties for Posets Nathan Reading School of Mathematics, University of Minnesota Minneapolis, MN 55455 [email protected] Abstract. We determine the order dimension of the strong Bruhat order on ¯nite Coxeter groups of types A, B and H. The order dimension is determined using a generalization of a theorem of Dilworth: dim(P ) = width(Irr(P )), whenever P satis¯es a simple order-theoretic condition called here the dissec- tive property (or \clivage" in [16, 21]). The result for dissective posets follows from an upper bound and lower bound on the dimension of any ¯nite poset. The dissective property is related, via MacNeille completion, to the distributive property of lattices. We show a similar connection between quotients of the strong Bruhat order with respect to parabolic subgroups and lattice quotients. 1. Introduction We give here three short summaries of the main results of this paper, from three points of view. We conclude the introduction by outlining the organization of the paper. Strong Bruhat Order. From the point of view of strong Bruhat order, the ¯rst main result of this paper is the following: Theorem 1. The order dimension of the Coxeter group An under the strong Bruhat order is: (n + 1)2 dim(A ) = n ¹ 4 º (n+1)2 The upper bound dim(An) · 4 appeared as an exercise in [3], but the proof given here does not rely on the previous bound. In [27], the same methods are used to prove the following theorem. The result for type I (dihedral groups) is trivial. -

Lattice Theory Lecture 2 Distributive Lattices
Lattice Theory Lecture 2 Distributive lattices John Harding New Mexico State University www.math.nmsu.edu/∼JohnHarding.html [email protected] Toulouse, July 2017 Distributive lattices Distributive law for all x; y; z x ∨ (y ∧ z) = (x ∨ y) ∧ (x ∨ z) Modular law if x ≤ z then x ∨ (y ∧ z) = (x ∨ y) ∧ (x ∨ z) Definition The lattices M5 and N5 are as follows: z x y z y x M5 N5 Note M5 is Modular, not distributive, and N5 is Non-modular. Both have 5 elements. 2 / 44 Recognizing distributive lattices Theorem Let L be a lattice. 1. L is modular iff N5 is not a sublattice of L 2. L is distributive iff neither M5; N5 is a sublattice of L Proof The \⇒" direction of each is obvious. For 1 \⇐" if L is not modular, there are x < z with x ∨ (y ∧ z) < (x ∨ y) ∧ (x ∨ z) (why?) Then the following is a sublattice of L. x ∨ y x y z y ( ∨ ) ∧ x ∨ (y ∧ z) y ∧ z 3 / 44 Exercise Give the details that the figure on the previous page is a sublattice. Do the 2 \⇐" direction. The lattice N5 is \projective" in lattices, meaning that if L is a lattice and f ∶ L → N5 is an onto lattice homomorphism, then there is a one-one lattice homomorphism g ∶ N5 → L with f ○ g = id. 4 / 44 Complements Definition Elements x; y of a bounded lattice L are complements if x ∧ y = 0 and x ∨ y = 1. In general, an element might have no complements, or many. 5 / 44 Complements Theorem In a bounded distributive lattice, an element has at most one complement. -

Lattice Theory
Chapter 1 Lattice theory 1.1 Partial orders 1.1.1 Binary Relations A binary relation R on a set X is a set of pairs of elements of X. That is, R ⊆ X2. We write xRy as a synonym for (x, y) ∈ R and say that R holds at (x, y). We may also view R as a square matrix of 0’s and 1’s, with rows and columns each indexed by elements of X. Then Rxy = 1 just when xRy. The following attributes of a binary relation R in the left column satisfy the corresponding conditions on the right for all x, y, and z. We abbreviate “xRy and yRz” to “xRyRz”. empty ¬(xRy) reflexive xRx irreflexive ¬(xRx) identity xRy ↔ x = y transitive xRyRz → xRz symmetric xRy → yRx antisymmetric xRyRx → x = y clique xRy For any given X, three of these attributes are each satisfied by exactly one binary relation on X, namely empty, identity, and clique, written respectively ∅, 1X , and KX . As sets of pairs these are respectively the empty set, the set of all pairs (x, x), and the set of all pairs (x, y), for x, y ∈ X. As square X × X matrices these are respectively the matrix of all 0’s, the matrix with 1’s on the leading diagonal and 0’s off the diagonal, and the matrix of all 1’s. Each of these attributes holds of R if and only if it holds of its converse R˘, defined by xRy ↔ yRx˘ . This extends to Boolean combinations of these attributes, those formed using “and,” “or,” and “not,” such as “reflexive and either not transitive or antisymmetric”.