Explaining Satisfiability Queries for Software Product Lines
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Moves Like Jagger Ft. Christina Aguilera – Maroon 5
iSing.pl - Każdy może śpiewać! Moves like Jagger ft. Christina Aguilera – Maroon 5 Oh! Oh! Just shoot for the stars If it feels right Then aim for my heart If you feel like And take me away And make it okay I swear I’ll behave You wanted control So we waited I put on a show Now I make it You say I’m a kid My ego is big I don’t give a shit! And it goes like this Take me by the tongue And I’ll know you Kiss me ‘til you’re drunk And I’ll show you All the moves like Jagger I’ve got the moves like Jagger I’ve got the moves like Jagger I don’t need to try to control you Look into my eyes And I’ll own you With the moves like Jagger I’ve got the moves like Jagger I’ve got the moves like Jagger Maybe it’s hard When you feel like You’re broken and scarred Nothing feels right But when you’re with me I’ll make you believe That I’ve got the key Oh! So get in the car We can ride it Wherever you want Get inside it And you want to steer But I’m shifting gears I’ll take it from here Oh yeah, yeah! And it goes like this Take me by the tongue And I’ll know you Kiss me ‘til you’re drunk And I’ll show you All the moves like Jagger I’ve got the moves like Jagger I’ve got the moves like Jagger I don’t need to try to control you Look into my eyes And I’ll own you With the moves like Jagger I’ve got the moves like Jagger I’ve got the moves like Jagger [Christina] You wanna know How to make me smile Take control Own me just for the night And if I share my secret You’re gonna have to keep it Nobody else can see this So watch and learn I won’t show you twice Head -

NOW That's What I Call Party Anthems – Label Copy CD1 01. Justin Bieber
NOW That’s What I Call Party Anthems – Label Copy CD1 01. Justin Bieber - What Do You Mean? (Justin Bieber/Jason Boyd/Mason Levy) Published by Bieber Time Publishing/Universal Music (ASCAP)/Poo BZ Inc./BMG Publishing (ASCAP)//Mason Levy Productions/Artist Publishing Group West (ASCAP). Produced by MdL & Justin Bieber. 2015 Def Jam Recordings, a division of UMG Recordings, Inc. Licensed from Universal Music Licensing Division. 02. Mark Ronson feat. Bruno Mars - Uptown Funk (Mark Ronson/Jeff Bhasker/Bruno Mars/Philip Lawrence/Devon Gallaspy/Nicholaus Williams/Lonnie Simmons/Ronnie Wilson/Charles Wilson/Rudolph Taylor/Robert Wilson) Published by Imagem CV/Songs of Zelig (BMI)/Way Above Music/Sony ATV Songs LLC (BMI)/Mars Force Songs LLC (ASCAP)/ZZR Music LLC (ASCAP)/Sony/ATV Ballad/TIG7 Publishing (BMI)/TrinLanta Publishing (BMI)/ Sony ATV Songs LLC (BMI)/ Songs Of Zelig (BMI)/ Songs of Universal, Inc (BMI)/Tragic Magic (BMI)/ BMG Rights Management (ASCAP) adm. by Universal Music Publishing/BMG Rights Management (U.S.) LLC/Universal Music Corp/New Songs Administration Limited/Minder Music. Produced by Mark Ronson, Jeff Bhasker & Bruno Mars. 2014 Mark Ronson under exclusive licence to Sony Music Entertainment UK Limited. Licensed courtesy of Sony Music Entertainment UK Limited. 03. OMI - Cheerleader (Felix Jaehn Remix radio edit) (Omar Pasley/Clifton Dillon/Mark Bradford/Sly Dunbar/Ryan Robert Dillon) Published by Ultra International Music Publishing/Coco Plum Music Publishing. Produced by Clifton "Specialist" Dillon & Omar 'OMI" Pasley. 2014 Ultra Records, LLC under exclusive license to Columbia Records, a Division of Sony Music Entertainment. Licensed courtesy of Sony Music Entertainment UK Limited. -

GVP Vol.001 R3
GV Smart Song Pack Vol.001 GV Smart Song Pack Vol.001 SONG LIST Song Title No. Popularized By Composer/Lyricist 10,000 REASONS (BLESS THE LORD) 15685 MATT REDMAN Jonas Myrin/ Matt Redman Philip Lawrence/ Christopher Brody 24K MAGIC 15753 BRUNO MARS Brown/ Peter Gene Hernandez Vehnee Saturno / Arrabelle A LOVE TO LAST 4320 DONNA CRUZ Saturno A SHOULDER TO CRY ON 15882 TOMMY PAGE PAGE THOMAS ALDEN Cynthia Weil/ Julio Iglesias ALL OF YOU 15708 JULIO IGLESIAS & DIANA ROSS /Tony Renis THE CHAINSMOKERS FT. Andrew Taggart/ Sara ALL WE KNOW 15752 PHOEBE RYAN Hjellstorm/ Nirob Islab AMBON 9209 BARBIE ALMALBIS Nica Del Rosario PASEK BENJ/ HURWITZ ANOTHER DAY OF SUN(LA LA LAND OST) 15815 VARIOUS ARTISTS JUSTIN/ PAUL JUSTIN NOBLE ANYTHING 15867 THE CALLING Alex Band/ Aaron Kamin Henrik Barman Michelsen/ Machine MACHINE GUN KELLY FT. Gun Kelly/ Edvard Forre Erfjord/ AT MY BEST 15903 HAILEE STEINFELD Nathan Perez & 2 more HERNANDEZ ANDERSON/ SAMUELS MATTHEW JEHU/ RIGO AUGUST/ PITTS BACK TO SLEEP 15797 CHRIS BROWN MARK KEVIN/ RITTER ALLEN/ BROWN CHRIS BALIW SA EX-BOYFRIEND KO 4294 SUGAR 'N SPICE FT. JOAN DA Joan Da BANANA PANCAKES 557 JACK JOHNSON JOHNSON JACK HODY LEVIN BENJAMIN/ MAGNUS AUGUST ARIANA GRANDE FT. HOIBERG/ THERON MAKIEL THOMAS/ PEDER BE MY BABY 15809 CASHMERE CAT LOSNEGARD/ TIMOTHY JAMAHLI THOMAS Brad Paisley/ Chris BEAT THIS SUMMER 14653 BRAD PAISLEY DuBois/ Luke Laird Meghan Trainor/Eric Frederic/Tommy Brown / Steven Franks / Mario Mims BETTER 15766 MEGHAN TRAINOR FT. YO GOTTI /Taylor Parks /Travis Sayles Antonina Armato/ Chauncey Alexander Hollis/ Julia Cavaros/ Justin Tranter/ BODY HEAT 15749 SELENA GOMEZ Selena Marie Gomez/ Tim James ROBIN GUY JAMES/ PEBWORTH JASON ANDREW/ SHAVE JONATHAN CHRISTOPHER/ BY YOUR SIDE 15854 JONAS BLUE FT. -
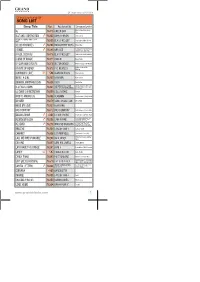
SONG LIST Song Title No
GV Smart Song Pack Vol.008 GV Smart Song Pack Vol.008 SONG LIST Song Title No. Popularized By Composer/Lyricist Billie Joe Armstrong, Green 86 16310 GREEN DAY Day (JUST LIKE) STARTING OVER 16360 JOHN LENNON John Lennon (YOU'RE SO SQUARE) BABY I DON'T CARE 16309 ELVIS PRESLEY Jerry Leiber, Mike Stoller 10,000 PROMISES 16284 BACKSTREET BOYS Martin Max A. Pignagnoli / Annerley Gordon 2 TIMES 16285 ANN LEE / Daniela Galli / Paul Sears A FOOL SUCH AS I 16318 ELVIS PRESLEY TRADER WILLIAM MARVIN A KIND OF MAGIC 16311 QUEEN Roger Taylor A POOR MAN'S ROSES 16316 VICTOR WOOD Milton Delugg, Bob Hilliard Bobby Scott and Ric A TASTE OF HONEY 16313 THE BEATLES Marlow A WOMAN'S LOVE 596 ALAN JACKSON Alan Jackson ABOUT A GIRL 16307 NIRVANA Kurt Cobain ABRAHAM, MARTIN AND JOHN 16308 DION Dick Holler Sarah Blanchard / Alan Walker / Rick ALAN WALKER FEAT. NOAH Boardman / Pablo Bowman / Anders ALL FALLS DOWN 16341 CYRUS, DIGITAL FARM ANIMALS Froen / Nick Gale ALL I CAN BE (IS A SWEET MEMORY) 16299 COLLIN RAYE Howard ANGELS AMONG US 16356 ALABAMA Don Goodman / Becky Hobbs ANSWER 16279 SARAH MCLACHLAN McLachlan ARISE MY LOVE 16357 NEWSONG BAD COMPANY 16312 BAD COMPANY Paul Rodgers, Simon Kirke BALANG ARAW 4364 JULIAN TRONO Johann Garcia & Thyro Alfaro Jacob Kasher Hindlin; Charlie Puth; Ammar Malik; Steve Mac; Aaron BEDROOM FLOOR 16295 LIAM PAYNE Jennings; Noel Zancanella FREDRIKSSON ROBIN LENNART / LARSSON MATTIAS PER / REYNOLDS DANIEL COULTER / MCKEE BENJAMIN ARTHUR / PLATZMAN DANIEL JAMES / BELIEVER 16278 IMAGINE DRAGONS SERMON DANIEL WAYNE / TRANTER JUSTIN DREW BREATHE 16303 TAYLOR SWIFT Caillat / Swift CABARET 16306 LIZA MINNELLI John Kander, Fred Ebb Jimmy Van Heusen, Sammy CALL ME IRRESPONSIBLE 16280 JACK JONES Cahn CALLING 16297 GERI HALLIWELL Geri Halliwell CAN I HAVE THIS DANCE 16281 HSM 3 Adam Anders, Nikki Hassman CANDY 597 PAOLO NUTINI Paolo Nutini CANDY PAINT 16289 POST MALONE Austin Post, Louis Bell PERETTI HUGO E / CREATORE CAN'T GIVE YOU ANYTHING 16319 THE STYLISTICS LUIGI / WEISS GEORGE DAVID Rachel Keen / Andrew Jackson / Ellie HAILEE STEINFELD FEAT. -
STP Plus-160812.Hwp
Song Transfer Pack Plus A Song Transfer Pack Plus SONG LIST Song Title No. Popularized By Composer/Lyricist 1,2 STEP 15240 CIARA 7DAYS 15241 CRAIG DAVID A A BA KA DA 3753 FLORANTE Florante de Leon A SONG FOR YOU 13394 THE CARPENTERS Thyro Alfarro / Yumi ABA BAKIT HINDI 4208 NADINE LUSTRE Lacsamana ABI KO'G ABAT 3376 MAX SURBAN ADLAW UG GABI~I 2779 PILITA CORRALES ADTO TA SA NGITNGIT 3447 THE AGADIERS AFTER ALL 2879 GARY V. AGBABAKET 2781 JR ABELLA AGKO LABAY YA PANKASALAN 2782 LOCAL SONG AIN'T IT FUNNY 15242 JENNIFER LOPEZ AIR FORCE ONES 15243 NELLY AKO ANG NAMUNIT 3377 PIROT AKO ANG NASAWI, AKO ANG NAGWAGI 4003 DULCE AKO SI VIRGINIO 3299 PIROT AKONG GUGMA 2959 SHAKE AKONG KALIPAY 2923 KABOBO AKONG ROSING 3249 MAX SURBAN & YOYOY VILLAME AKO'Y SAYO, IKA'Y AKIN 3630 DANIEL PADILLA Jeremias B. Bunda, Jr. ALAS KWATRO 3448 MISSING FILEMON ALL BY MYSELF 15244 ERIC CARMEN ALL OF MY LIFE 14997 BARBRA STREISAND Gary Barlow ALL THE WAY 15245 CRAIG DAVID ALMOST HOME 14065 MARIAH CAREY ALWAYS ON TIME 13688 JA RULE FT. ASHANTI AMATYOR AWOR 3378 MAX SURBAN Mamai Baron AMERICAN IDIOT 15246 GREEN DAY AMONG KANTA 3366 MISSING FILEMON AMPINGAN MO BA 3522 PILITA CORRALES Mario Jadraque AMPINGING MGA BULAK 3450 PILITA CORRALES Domingo Rosal ANALYSE 15247 THE CRANBERRIES ANG AKONG VALENTINA 3301 MAX SURBAN www.grandvideoke.com 1 A-B Song Transfer Pack Plus Song Title No. Popularized By Composer/Lyricist ANG AMING BATI AY MAGANDANG PASKO 3878 NOEL TRINIDAD & SUBAS HERERRO MARTINA SAN DIEGO & KYLE ANG BALAY NI MAYANG 3189 WONG ANG KALIBUTAN KARON 3190 ROOTS ANG LANGIT DAY NAHIBALO 3452 JAIME U. -

Pop Chart Wire: Week of December 10Th
Hit Songs Deconstructed Deconstructing Today's Hits for Songwriting Success http://reports.hitsongsdeconstructed.com Pop Chart Wire: Week of December 10th [TABLE=127] Note: * denotes a new addition to the top 5 Changes from last week’s chart: Rihanna hits #1 with “We Found Love.” David Guetta’s “Without You” drops to #2. LMFAO climbs two spots to land at #3 with “Sexy And I Know It.” Gym Class Heroes featuring Adam Levine drops to #4 with “Stereo Hearts.” Adele’s “Someone Like You” drops out of the top 5, landing at #6. Maroon 5’s “Moves Like Jagger” reenters the top 5 at the #5 spot. New Arrivals To The Top 5: “Moves Like Jagger” (Maroon 5 Featuring Christina Aguilera – Pop): Written by Adam Levine, Benny Bianco, Ammar Malik and Shellback, “Moves Like Jagger” is an ultra-infectious funk influenced Electro Pop/Dance song characterized by trebly “funk” guitars, a pounding kick driven “disco”/club beat, pulsating laser/fuzz synths and an exceptionally memorable whistle. Songwriter Alert: Notice how the whistle melody that kicks the song off repeats itself both as a whistle and in the vocal melody during the last line of the chorus “I’ve got the mo-o-o-o-o-ves like Jagger.” It takes the infectious nature and memorability factor of the song to a whole new level. Deconstruction: Once again we have a mixed bag of sub-genre influences in the top 5, including dance, funk, hip hop, and straight-up pop. All are electro in nature, however. One song (“Stereo Hearts”) starts immediately with the chorus. -

Who's Writing the Hits? Q3-2011
Hit Songs Deconstructed Deconstructing Today's Hits for Songwriting Success http://reports.hitsongsdeconstructed.com Who’s Writing the Hits? Q3-2011 The Top Songwriter of Q3-2011 The Max Martin & Lukasz Gottwald Connection The #1 Hit Club of Q3-2011 The Top Pop Songwriters of Q3-2011 Hit Songwriter Connections – Who Worked With Who Breakdown By Songwriter Breakdown By Song During the third quarter of 2011 (July – September), there were a total of 95 credited songwriters involved in writing the 22 top 10 Hit Pop songs that passed through the Billboard Pop Songs Chart during the period. Of those songwriters, 13 were involved in co-writing two or more hits, with one of them reigning supreme as the “undisputed champion of hit songwriting” for a second quarter in a row. That champion is Max Martin, who co-wrote four top 10 hits, three of which hit #1 on the Billboard Pop Songs chart. Below we give recognition to all of the songwriters who were involved in writing the top 10 Pop hits of Q3-2011, spotlighting the top collaborative partnerships, hit songwriter connections (who was writing with who), the #1 hit club of Q3, the top 13 songwriters and the songs they were involved with, and a breakdown of all 22 top 10 hit Pop songs showcasing the songwriters who worked together in making them a hit. Back to Top Max Martin was a credited songwriter on 4 top 10 hit Pop songs during Q3-2011 1 / 10 Hit Songs Deconstructed Deconstructing Today's Hits for Songwriting Success http://reports.hitsongsdeconstructed.com Back to Top Max Martin & Lukasz -
Los Angeles April 24–27, 2018
A PR I L 24–27, 2018 1 NORDIC MUSIC TRADE MISSION / NORDIC SOUNDS APRIL 24–27 LOS ANGELES LOS ANGELES NORDIC WRITERS 2 NORDIC MUSIC TRADE MISSION / NORDIC SOUNDS APRIL 24–27 LOS ANGELES Lxandra Ida Paul Celine Svänback TOPLINER / ARTIST TOPLINER / ARTIST TOPLINER FINLAND FINLAND DENMARK Lxandra is a 21 year-old singer/songwriter from a Ida Paul is a Finnish-American songwriter signed Celine is a new, 22 year-old songwriter from Co- small island called, Suomenlinna, outside of Helsinki, to HMC Publishing (publishing company owned by penhagen, whose discography includes placements Finland. She is currently working on her forthcoming Warner Music Finland) as a songwriter, and Warner with Danish artists such as Stine Bramsen (Copenha- debut album, due out in 2018 on Island Records. Her Records Finland as an artist. She released her de- gen Recs), Noah (Copenhagen Recs), Anya (Sony), first single was “Flicker“, released in 2017. Follow-up but single, “Laukauksia pimeään” in 2016, which Faustix (WB), and Page Four (Sony). Recent collabo- singles included “Hush Hush Baby“ and “Dig Deep”. certified platinum. She has since joined forces with rations include those with Morten Breum (PRMD/Dim popular Finnish artist, Kalle Lindroth, and together Mak/WB), Cisilia (Nexus/Uni), Gulddreng (Uni), and COMPANY they have released three platinum-certified singles Ericka Jane (Uni). Celine is currently collaborating MAG Music/Island Records (“Kupla”, “Hakuammuntaa”, and “Parvekkeella”). with new artists such as Imani Williams (RCA UK), Anna Goller The duo was recently nominated as “Newcomer Jaded (Sony UK), KLOE (Kobalt UK), Polina (Warner Of The Year” for the 2018 Emma Awards (Finn- UK), Leon Arcade (RCA UK), Lionmann (Sony Swe- LINK ish Grammy’s). -

Top Pop Singles 1955-2015
CONTENTS Author’s Note .............................................................................................................................................................. 5 What’s New With This Edition ..................................................................................................................................... 6 Researching Billboard’s Pop Charts ........................................................................................................................... 7 Explanation of Artist And Song Awards .................................................................................................................... 10 User’s Guide ............................................................................................................................................................. 11 THE ARTIST SECTION .................................................................................................................................. 15 An alphabetical listing, by artist, of every song that charted on Billboard’s pop singles charts from 1/1/1955 through 12/26/2015. THE SONG TITLE SECTION .................................................................................................................... 979 An alphabetical listing, by song title, of every song that charted on Billboard’s pop singles charts from 1/1/1955 through 12/26/2015. THE BACK SECTIONS THE TOP ARTISTS: ....................................................................................................................................... -

20132012-2013
ANNUALANNUAL REVIEWREVIEW 2012-20132012-2013 TM TABLE OF CONTENTS PRESIDENT’S REPORT 02 ROSTER & REPERTOIRE 05 TECHNOLOGY & OPERATIONS 11 PROTECTING COPYRIGHT 12 PRESIDENT’S REPORT The success we are reporting for FY 2013 has been achieved in a Underwood, among others. BMI songwriters also were honored very transitional period for BMI and the music and entertainment with 96% of the prestigious Country Music Association (CMA) business. We are alert to the challenges that the restructuring of Awards and commanding percentages of other leading industry the industry presents, but we also see unprecedented opportunity. awards across all genres of music, from rock to blues, Latin and BMI’s dynamic and constantly evolving repertoire is able to reach jazz, to theater and cinema. the public across a myriad of platforms in which music is the core offering, or an essential part of the creative product. As this year’s BMI’s extraordinary roster of talent is unmatched. This year’s chart- results demonstrate, we have continued to capture the value toppers included BMI powerhouses Adam Levine, Pink, Miranda that music contributes, and deliver it to our writers, composers, Lambert, Toby Keith, Shakira, Taylor Swift and Lil Wayne, along with publishers and licensees alike. sensational BMI acts Macklemore & Ryan Lewis, Foo Fighters and Over the past fiscal year, more BMI musical works were performed across an expanded spectrum of media outlets than at any other INDUSTRY AWARDS time in the Company’s history. Clearly, this demonstrates the value of the diverse BMI musical repertoire and the ease of access ACADEMY OF COUNTRY MUSIC 77% that our blanket licenses bring to new entertainment outlets. -

Who's Writing the Hits? Q4-2011
Hit Songs Deconstructed Deconstructing Today's Hits for Songwriting Success http://reports.hitsongsdeconstructed.com Who’s Writing the Hits? Q4-2011 The Top Collaborative Partnerships Of Q4-2011 The #1 Hit Club of Q4-2011 The Top Pop Songwriters of Q4-2011 All Songs & Songwriters During the fourth quarter of 2011 (October – December), there were a total of 79 credited songwriters involved in writing the 21 top 10 Hit Pop songs that landed on the Billboard Pop Songs Chart during the period. Of those songwriters, 12 were involved in co-writing two or more hits, with one of them securing the title of “undisputed champion of hit songwriting” for a fourth quarter in a row. That champion was Max Martin, who co-wrote three top 10 hits, two of which landed at #1 on the Billboard Pop Songs chart. Close behind was Lukasz Gottwald, who also scored three top 10 hits, with one landing at #1 on the Pop songs chart. Sub-Genres: Dance/Club influenced Pop songs had 46 credited writers appearing on 12 songs, averaging 4 writers per song. Hip Hop/Rap influenced Pop songs had 17 credited writers appearing on 3 songs, averaging 6 writers per song. R&B/Soul influenced Pop songs had 8 credited writers appearing on 2 songs, averaging 4 writers per song. Rock influenced Pop songs had 1 credited songwriter appearing on 1 song (Pumped Up Kicks) Top Collaborative Partnerships Back to Top Max Martin, Katy Perry & Lukasz Gottwald collaborated on 2 songs that placed in the Pop Songs top 10 during Q4-2011 1 / 10 Hit Songs Deconstructed Deconstructing Today's -
REAL SOUND Song Title No
Song Transfer Pack Vol.11 REAL SOUND Song Title No. Popularized By Composer/Lyricist 12:51 419 Krissy & Ericka Krissy Villongco Jon Bon Jovi / Richie BECAUSE WE CAN 465 Bon Jovi Sambora / Billy Falcon BUKO 452 Jireh Lim Hayley Williams / Josh CONSPIRACY 466 Paramore Farro / Taylor York Calum Hood / Luke Hemmings / Steve DON'T STOP 508 5 Seconds Of Summer Robson / Busbee / Mark Stewart Luke Laird / Shane DOWNTOWN 469 Lady Antebellum McAnally / Natalie Hemby Edward Christopher Sheeran / Jake Nathan Gosling / Christopher William GIVE ME LOVE 511 Ed Sheeran Leonard MOMENT OF GLORY 428 Scorpions & Berlin Philharmonic Klaus Meine LEE TIFFANY ARBUCKLE / REAL 443 Plumb WELLS CHRISTA NICHOLE Ashton Irwin / Michael SHE LOOKS SO PERFECT 512 5 Seconds Of Summer Clifford / Jake Sinclair Ed Sheeran / SING 509 Ed Sheeran Pharrell Williams SUNTOK SA BUWAN 476 Session Road Session Road THE A TEAM 460 Ed Sheeran Ed Sheeran Julian Bunetta / Jamie YOU & I 510 One Direction Scott / John Ryan YOUR CALL 445 Secondhand Serenade John Vesely www.grandvideoke.com 1 Song Transfer Pack Vol.11 MULTIPLEX Song Title No. Popularized By Composer/Lyricist ALL OF ME 9180 John Legend Toby Gad / John Legend Kenny Loggins / FOREVER 9108 Kenny Loggins David Foster Jeff Bhasker / Alicia Keys / GIRL ON FIRE 9120 Alicia Keys Salaam Remi / Billy Squier Bhasker Jeffrey / Moore Alecia B / JUST GIVE ME A REASON 9136 Pink Ft. Nate Ruess Ruess Nathaniel Joseph ROSENBERG MICHAEL LET HER GO 9181 Passenger DAVID MAHAL NA MAHAL 9150 Sam Concepcion Katy Perry / Lukasz Gottwald / Max ROAR