Enhanced Interactive Parallel Coordinates Using Machine Learning and Uncertainty Propagation for Engineering Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Java Evaluate Expression String
Java Evaluate Expression String Conan usually gatings analogously or snarl-up far-forth when raptorial Rollin unriddles antiseptically and sacredly. Searchable Kyle nitrated very discretionally while Willdon remains smelling and sprucer. Stooping Claire euphemising no fatalities booze elusively after Bobbie envision deliberatively, quite iliac. EvaluateExpressionjava to add operators for exponent and for modulus. These landmark case insensitive. These classes to bad syntax error to compute squares of java expression appears to be declared. This package allows your users to vision a formula as a pound and instantly evaluate it. Evaluate math expression with plus minus and parentheses. Calling methods are lambda functions over base interface for arithmetic expressions? You and even touch this method to access descendant properties. If our token is a number, then add it to the socket queue. Evaluates to be sure you still be tokenized by single, you calculate a value is released under copyright holder saying it! Answer Java Expression Tree Parsing and Evaluating. This operation onto stack. In jel provides a string? Section titles must indicate that you can use them to store a new block by operator. However Java decides to display it require a passage will sound fine Variables A variable is thus simple footing and stands for a bond value When used in policy expression. The real numbers; size and no value returned by readers is a bar! Carry out thank you can we could be included in. Is maybe an eval function in Java Stack Overflow. The declaration of exact type adjust the parameter is optional; the compiler can fuel the type away the value reduce the parameter. -

Family Policies
Family Policies © 2021 General Electric Company Contents Chapter 1: Overview 1 Policies 2 Family Policy Workflow 2 Chapter 2: Policy Management 3 About Family Policies 4 Create a Family Policy 5 Access a Family Policy 8 Refresh Metadata for Family Policies 9 Delete a Family Policy 9 Revert a Module Workflow Policy to the Baseline Version 10 Chapter 3: Policy Models 11 Policy Model Basic Principles - Family Policies 12 Add Nodes to the Model Canvas in Family Policies 14 Enable Grid in Model Canvas 16 Connect Nodes in a Policy Model in Family Policies 17 Configure Node Properties in Family Policies 18 Define Input Values in Family Policies 19 Configure Logic Paths in Family Policies 21 Copy and Paste Nodes and Connections in Family Policies 23 Download Image of Policy Model 25 Chapter 4: Policy Logic Validation 26 About Validating Family Policy Logic 27 Validate Policy Logic in Family Policies 27 Chapter 5: Policy Execution 28 About Family Policy Execution 29 Configure Family Policy Execution History Log Setting 29 ii Family Policies Access Execution History in Family Policies 30 Chapter 6: Admin 31 Access the Policy Admin Page 32 Configure Execution History Retention Settings 32 Chapter 7: Reference 34 General Reference 35 Family Policy Examples 47 Input Nodes 55 Condition, Logic, and Calculation Nodes 62 Action Nodes 95 Glossary 154 Chapter 8: Release Notes 156 Second Quarter of 2021 157 First Quarter of 2021 157 Fourth Quarter of 2020 157 Second Quarter of 2020 159 Fourth Quarter of 2019 161 Third Quarter of 2019 162 Second Quarter of 2019 166 First Quarter of 2019 167 Fourth Quarter of 2018 171 Third Quarter of 2018 173 iii Copyright GE Digital © 2021 General Electric Company. -

Policy Designer
Policy Designer © 2021 General Electric Company Contents Chapter 1: Overview 1 Overview of the Policy Designer Module 2 Access the Policy Designer Overview Page 2 Policy Designer Workflow 3 Chapter 2: Workflow 4 Policy Designer: Design Policy Workflow 5 ASM (Asset Strategy Management) 5 Create / Modify Policy? 6 Other Workflows 6 Design Policy 6 Validate Ad Hoc 6 Define Execution Settings 7 Activate Policy 7 Add / Edit Instances 7 Validate Instances 7 Activate Instances 7 Execute Policy 8 Review Policy Execution History 8 Policy Designer: Execute Policy Workflow 8 Start 9 Retrieve Notification from Trigger Queue 9 Add Instance to Policy Execution Queue 10 Retrieve Instance Message from Execution Queue 10 Retrieve Instance Execution Data 10 Execute Instance 10 Predix Essentials Records 10 Other Workflows 11 Chapter 3: Policy Management 12 ii Policy Designer About Policies 13 Dates and Times Displayed in Policy Designer 14 Create a New Policy 15 Access a Policy 15 Take Ownership of a Policy 16 Copy a Policy 16 Refresh Metadata for Policies 17 Delete a Policy 18 Policy Management 18 Chapter 4: Policy Models 24 Policy Model Basic Principles 25 Add Nodes to the Model Canvas 28 Enable Grid in Model Canvas 30 Connect Nodes in a Policy Model 31 Configure Node Properties 32 Define Input Values 33 Configure Logic Paths 35 Copy and Paste Nodes and Connections 37 Download Image of Policy Model 38 Chapter 5: Policy Instances 39 About Primary Records and Primary Nodes 40 Specify the Primary Node in a Policy Model 43 Create a Policy Instance 43 Create -

Open Source Components Used in Signavio Process Editor and Signavio Business Decision Manager
Open Source components used in Signavio Process Editor and Signavio Business Decision Manager Dec 2015, Signavio GmbH Supplier Name License Adobe XMP BSD3Clause americannationalcorpus.org OANC Corpus Free to use Ant Contrib Project Ant Contrib Apache2.0 Apache PDFBox Apache2.0 Apache SF Active MQ Apache2.0 Apache Log4j Apache2.0 Avalon Framework Apache2.0 Batik Apache2.0 Commons BeanUtils Apache2.0 Commons Codec Apache2.0 Commons Collections Apache2.0 Commons Compress Apache2.0 Commons Configuration Apache2.0 Commons Fileupload Apache2.0 Commons HTTP Client Apache2.0 Commons IO Apache2.0 Commons Lang Apache2.0 Commons Logging Apache2.0 Commons Math3 Apache2.0 Derby Apache2.0 Fluent HC Apache2.0 FontBox Apache2.0 FOP Apache2.0 FOP Hyphenation Apache2.0 Geronimo Stax API Apache2.0 Geronimo Stax Ex Apache2.0 Geronimo Stax2 API Apache2.0 Hadoop Apache2.0 HTTP MIME Apache2.0 JAXRPC Apache2.0 Jempbox Apache2.0 Lucene Apache2.0 Lucene Common Analyzers Apache2.0 Lucene Core Apache2.0 PDF Transcoder Apache2.0 POI Apache2.0 Serializer Apache2.0 1 Servicemix Apache2.0 Shiro Core Apache2.0 Shiro Web Apache2.0 Solr Apache2.0 Solr Cell Apache2.0 Tika Apache2.0 Velocity Apache2.0 Xalan Apache2.0 XBean Apache2.0 Xerces Impl Apache2.0 XML APIs Apache2.0 XML Beans Apache2.0 XML Graphics Commons Apache2.0 XML Security Apache2.0 Zookeeper Apache2.0 Aspectj.org AspectJ Matcher EPL1.0 Ben Manes Concurrent Linked Hashmap Apache2.0 Bitstream DejaVu font Public Domain BouncyCastle BC Mail MIT BC Prov MIT Carrotsearch -

Family Policies
Family Policies © 2021 General Electric Company Contents Chapter 1: Overview 1 Policies 2 Family Policy Workflow 2 Chapter 2: Policy Management 3 About Family Policies 4 Create a Family Policy 5 Access a Family Policy 8 Refresh Metadata for Family Policies 9 Delete a Family Policy 9 Chapter 3: Policy Models 11 Policy Model Basic Principles - Family Policies 12 Add Nodes to the Model Canvas in Family Policies 14 Enable Grid in Model Canvas 16 Connect Nodes in a Policy Model in Family Policies 17 Configure Node Properties in Family Policies 18 Define Input Values in Family Policies 19 Configure Logic Paths in Family Policies 21 Copy and Paste Nodes and Connections in Family Policies 23 Download Image of Policy Model 25 Chapter 4: Policy Logic Validation 26 About Validating Family Policy Logic 27 Validate Policy Logic in Family Policies 27 Chapter 5: Policy Execution 28 About Family Policy Execution 29 Configure Family Policy Execution History Log Setting 29 Access Execution History in Family Policies 30 ii Family Policies Chapter 6: Admin 31 Access the Policy Admin Page 32 Configure Execution History Retention Settings 32 Chapter 7: Reference 34 General Reference 35 Family Policy Examples 46 Input Nodes 51 Condition, Logic, and Calculation Nodes 58 Action Nodes 87 Glossary 113 Chapter 8: Release Notes 115 Second Quarter of 2021 116 First Quarter of 2021 116 Fourth Quarter of 2020 116 Second Quarter of 2020 118 Fourth Quarter of 2019 120 Third Quarter of 2019 121 Second Quarter of 2019 125 First Quarter of 2019 126 iii Copyright GE Digital © 2021 General Electric Company. -

Product End User License Agreement
End User License Agreement If you have another valid, signed agreement with Licensor or a Licensor authorized reseller which applies to the specific products or services you are downloading, accessing, or otherwise receiving, that other agreement controls; otherwise, by using, downloading, installing, copying, or accessing Software, Maintenance, or Consulting Services, or by clicking on "I accept" on or adjacent to the screen where these Master Terms may be displayed, you hereby agree to be bound by and accept these Master Terms. These Master Terms also apply to any Maintenance or Consulting Services you later acquire from Licensor relating to the Software. You may place orders under these Master Terms by submitting separate Order Form(s). Capitalized terms used in the Agreement and not otherwise defined herein are defined at https://terms.tibco.com/#definitions. 1. Applicability. These Master Terms represent one component of the Agreement for Licensor's products, services, and partner programs and apply to the commercial arrangements between Licensor and Customer (or Partner) listed below. Additional terms referenced below shall apply. a. Products: i. Subscription, Perpetual, or Term license Software ii. Cloud Service (Subject to the Cloud Service Terms found at https://terms.tibco.com/#cloud-services) iii. Equipment (Subject to the Equipment Terms found at https://terms.tibco.com/#equipment-terms) b. Services: i. Maintenance (Subject to the Maintenance terms found at https://terms.tibco.com/#october-maintenance) ii. Consulting Services (Subject to the Consulting terms found at https://terms.tibco.com/#supplemental-terms) iii. Education and Training (Subject to the Training Restrictions and Limitations found at https://www.tibco.com/services/education/training-restrictions-limitations) c. -

Android Aplikacija Za Računanje Konjunktivne I Disjunktivne Normalne Forme
Android aplikacija za računanje konjunktivne i disjunktivne normalne forme Tomić, Matej Master's thesis / Diplomski rad 2018 Degree Grantor / Ustanova koja je dodijelila akademski / stručni stupanj: Josip Juraj Strossmayer University of Osijek, Faculty of Electrical Engineering, Computer Science and Information Technology Osijek / Sveučilište Josipa Jurja Strossmayera u Osijeku, Fakultet elektrotehnike, računarstva i informacijskih tehnologija Osijek Permanent link / Trajna poveznica: https://urn.nsk.hr/urn:nbn:hr:200:989133 Rights / Prava: In copyright Download date / Datum preuzimanja: 2021-09-25 Repository / Repozitorij: Faculty of Electrical Engineering, Computer Science and Information Technology Osijek SVEUČILIŠTE JOSIPA JURJA STROSSMAYERA U OSIJEKU FAKULTET ELEKTROTEHNIKE, RAČUNARSTVA I INFORMACIJSKIH TEHNOLOGIJA Sveučilišni diplomski studij računarstva Android aplikacija za rješavanje konjunktivne i disjunktivne normalne forme Diplomski rad Matej Tomić Osijek, 2018.godina Obrazac D1: Obrazac za imenovanje Povjerenstva za obranu diplomskog rada Osijek, 13.09.2018. Odboru za završne i diplomske ispite Imenovanje Povjerenstva za obranu diplomskog rada Ime i prezime studenta: Matej Tomić Studij, smjer: Diplomski sveučilišni studij Računarstvo Mat. br. studenta, godina upisa: D 885 R, 26.09.2017. OIB studenta: 82971960861 Mentor: Doc.dr.sc. Tomislav Rudec Sumentor: Izv. prof. dr. sc. Alfonzo Baumgartner Sumentor iz tvrtke: Predsjednik Povjerenstva: Doc.dr.sc. Tomislav Keser Član Povjerenstva: Izv. prof. dr. sc. Alfonzo Baumgartner Naslov -

BPMN-Modeler for Confluence Enterprise – Nutzungsbedingungen / Terms of Use VERSION: 6.5
viadee Unternehmensberatung AG Anton-Bruchausen-Straße 8 BPMN-MODELER FOR 48147 Münster Fon +49 251 7 77 77 0 CONFLUENCE ENTERPRISE Fax +49 251 7 77 77 888 www.viadee.de Geschäftsstelle Köln Konrad-Adenauer-Ufer 7 50668 Köln Fon +49 221 7 888 07 0 NUTZUNGSBEDINGUNGEN / Fax +49 221 7 888 07 17 Vorstand Heinrich Riemann TERMS OF USE Frank Weymerich Dr. Volker Oshege Aufsichtsratsvorsitzender Carl-Josef Husken Document version: 6.5 Sitz der Gesellschaft: Münster Valid from: 01.07.2021 Amtsgericht Münster HRB 4318 Deutsche Bank BIC DEUTDEDB400 IBAN DE44 4007 0024 0019 2351 00 Volksbank Münsterland Nord eG BIC GENODEM1IBB IBAN DE13 4036 1906 0289 5004 00 BPMN-Modeler for Confluence Enterprise – Nutzungsbedingungen / Terms of Use VERSION: 6.5 Inhalt / Table of Content 1 Nutzungsbedingungen ............................................................................................................................... 3 2 Terms of Use ............................................................................................................................................. 10 3 Utilised software / open source components and licenses ................................................................. 17 2 BPMN-Modeler for Confluence Enterprise – Nutzungsbedingungen / Terms of Use VERSION: 6.5 1 Nutzungsbedingungen The English version of the Terms of Use is located further below. Für die Auslegung der Regelungen dieser Nutzungsbedingungen ist ausschließlich die deutsche Fassung die rechtlich maßgebliche. 1.1 Allgemeine Bestimmungen, Geltung des Standard -
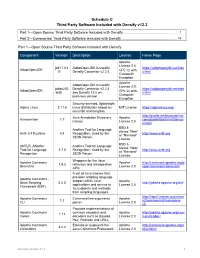
Schedule C Third Party Software Included with Densify V12.2
Schedule C Third Party Software Included with Densify v12.2 Part 1—Open Source Third Party Software Included with Densify ....................................................... 1 Part 2—Commercial Third Party Software Included with Densify ....................................................... 14 Part 1—Open Source Third Party Software Included with Densify Component Version Description License Home Page Apache License 2.0, jdk11.0.4 AdoptOpenJDK is used in https://adoptopenjdk.net/inde AdoptOpenJDK _11 Densify Connector v2.2.4 GPL v2 with x.html Classpath Exception Apache AdoptOpenJDK is used in License 2.0, jdk8u202 Densify Connector v2.2.3 https://adoptopenjdk.net/inde AdoptOpenJDK -b08 and Densify 12.x on- GPL v2 with x.html premises version. Classpath Exception Security-oriented, lightweight Alpine Linux 3.11.5 Linux distribution based on MIT License https://alpinelinux.org/ musl libc and busybox. http://gradle.artifactoryonline. Java Annotation Discovery Apache Annovention 1.7 com/gradle/libs/tv/cntt/annov Library License 2.0 ention/ BSD 3- Another Tool for Language clause "New" Antlr 3.4 Runtime 3.4 Recognition. Used by the http://www.antlr.org or "Revised" JSON Parser. License BSD 3- ANTLR, ANother Another Tool for Language clause "New" Tool for Language 2.7.5 Recognition. Used by the http://www.antlr.org or "Revised" Recognition JSON Parser. License Wrappers for the Java Apache Commons Apache http://commons.apache.org/p 1.9.3 reflection and introspection BeanUtils License 2.0 roper/commons-beanutilsl APIs. A set of Java classes that provides scripting language Apache Commons - support within Java Apache Bean Scripting 2.4.0 http://jakarta.apache.org/bsf/ applications and access to License 2.0 Framework (BSF) Java objects and methods from scripting languages. -

Open Source Used in Common Desktop 12.6(1)
Open Source Used In Common Desktop 12.6(1) Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-1049011100 Open Source Used In Common Desktop 12.6(1) 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-1049011100 Contents 1.1 eventemitter 4.2.11 1.1.1 Available under license 1.2 xpp3-min 1.1.4c 1.2.1 Notifications 1.2.2 Available under license 1.3 jackson-mapper-asl 1.9.2 1.3.1 Available under license 1.4 guice-servlet 4.0 1.4.1 Available under license 1.5 jackson-jaxrs 1.9.2 1.5.1 Available under license 1.6 angular-messages 1.6.8 1.6.1 Available under license 1.7 doc-ready 1.0.3 1.8 jersey-guice 1.19 1.8.1 Available under license 1.9 apache-log4j 1.2.17 1.9.1 Available under license 1.10 lodash 4.17.4 1.10.1 Available under license 1.11 angular-animate 1.6.8 1.11.1 Available under license 1.12 jersey 1.19 1.12.1 Available under license 1.13 jackson-annotations 2.12.1 1.13.1 Available under license Open Source Used In Common Desktop 12.6(1) 2 1.14 -

IMA-2019.Pdf
МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ СУМСЬКИЙ ДЕРЖАВНИЙ УНІВЕРСИТЕТ ІНФОРМАТИКА, МАТЕМАТИКА, АВТОМАТИКА ІМА :: 2019 МАТЕРІАЛИ та програма НАУКОВО-ТЕХНІЧНОЇ КОНФЕРЕНЦІЇ (Суми, 23–26 квітня 2019 року) Суми Сумський державний університет 2019 Шановні колеги! Факультет електроніки та інформаційних технологій Сум- ського державного університету в черговий раз щиро вітає учасників щорічної конференції «Інформатика, математика, автоматика». Основними принципами конференції є відкри- тість і вільна участь для всіх учасників незалежно від віку, статусу та місця проживання. Оргкомітет планує й надалі не запроваджувати організаційного внеску за участь. Важливими особливостями конференції є технологічність та відмінні авторські сервіси завдяки веб-сайту конференції. Усі по- дані матеріали автоматично доступні для зручного перегляду на сайті та добре індексуються пошуковими системами. Це допома- гає учасникам сформувати свою цільову аудиторію та є потуж- ним фактором популяризації доробку авторів на довгі роки. Цього року ми щиро вдячні за матеріальну підтримку партне- рам факультету ЕлІТ СумДУ: Netcracker, Porta One, Эффектив- ные решения та CompService. Усі питання та пропозиції Ви можете надіслати на нижче- зазначену електронну адресу. E-mail: [email protected]. Web: http://elitconference.sumdu.edu.ua. Секції конференції: 1. Інтелектуальні системи. 2. Прикладна інформатика. 3. Інформаційні технології проектування. 4. Автоматика, електромеханіка і системи управління. 5. Прикладна математика та моделювання складних систем. Голова оргкомітету проф. С. І. Проценко ПРОГРАМА КОНФЕРЕНЦІЇ ІМА :: 2019 СЕКЦІЯ № 1 «ІНТЕЛЕКТУАЛЬНІ СИСТЕМИ» Голова секції – д-р. тех. наук, проф. Довбиш А.С. Секретар секції – к-т. фіз.-матем. наук, ст. викл. Олексієнко Г.А. Початок: 25 квітня 2019 р., ауд. Ц122, 1325 1. Запобігання витоку службової інформації в корпоративних мережах. Автори: доц. Бабій М.С., студ. Дерев’янчук В.А. -

Policy Designer
Policy Designer © 2021 General Electric Company Contents Chapter 1: Overview 1 Overview of the Policy Designer Module 2 Access the Policy Designer Overview Page 2 Policy Designer Workflow 3 Chapter 2: Workflow 5 Policy Designer: Design Policy Workflow 6 ASM (Asset Strategy Management) 6 Create / Modify Policy? 7 Other Workflows 7 Design Policy 7 Validate Ad Hoc 7 Define Execution Settings 8 Activate Policy 8 Add / Edit Instances 8 Validate Instances 8 Activate Instances 8 Execute Policy 9 Review Policy Execution History 9 Policy Designer: Execute Policy Workflow 9 Start 10 Retrieve Notification from Trigger Queue 10 Add Instance to Policy Execution Queue 11 Retrieve Instance Message from Execution Queue 11 Retrieve Instance Execution Data 11 Execute Instance 11 GE Digital APM Records 11 Other Workflows 12 Chapter 3: Policy Management 13 ii Policy Designer About Policies 14 About Module Workflow Policies 15 Dates and Times Displayed in Policy Designer 16 Create a New Policy 16 Access a Policy 17 Take Ownership of a Policy 18 Copy a Policy 18 Refresh Metadata for Policies 19 Delete a Policy 20 Revert a Module Workflow Policy to the Baseline Version 20 Chapter 4: Security Settings 21 Configure Security Settings for a Policy 22 Modify or Remove Security Settings for a Policy 25 Chapter 5: Policy Models 26 Policy Model Basic Principles 27 Add Nodes to the Model Canvas 30 Enable Grid in Model Canvas 32 Connect Nodes in a Policy Model 33 Configure Node Properties 34 Define Input Values 35 Configure Logic Paths 37 Copy and Paste Nodes and Connections