Functional Genomic Analysis of Novel Microdeletions And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding the Impact of 1Q21.1 Copy Number Variant
Understanding the impact of 1q21.1 copy number variant Article (Published Version) Havard, Chansonette, Strong, Emma, Mercier, Eloi, Colnaghi, Rita, Alcantara, Diana Rita Ralha, Chow, Eva, Martell, Sally, Tyson, Christine, Hrynchak, Monica, McGillivray, Barbara, Hamilton, Sara, Marles, Sandra, Mhanni, Aziz, Dawson, Angelika J, Pavlidis, Paul et al. (2011) Understanding the impact of 1q21.1 copy number variant. Orphanet Journal of Rare Diseases, 6 (54). pp. 1-12. ISSN 1750-1172 This version is available from Sussex Research Online: http://sro.sussex.ac.uk/id/eprint/41577/ This document is made available in accordance with publisher policies and may differ from the published version or from the version of record. If you wish to cite this item you are advised to consult the publisher’s version. Please see the URL above for details on accessing the published version. Copyright and reuse: Sussex Research Online is a digital repository of the research output of the University. Copyright and all moral rights to the version of the paper presented here belong to the individual author(s) and/or other copyright owners. To the extent reasonable and practicable, the material made available in SRO has been checked for eligibility before being made available. Copies of full text items generally can be reproduced, displayed or performed and given to third parties in any format or medium for personal research or study, educational, or not-for-profit purposes without prior permission or charge, provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way. -
Genetic Screens in Isogenic Mammalian Cell Lines Without Single Cell Cloning
ARTICLE https://doi.org/10.1038/s41467-020-14620-6 OPEN Genetic screens in isogenic mammalian cell lines without single cell cloning Peter C. DeWeirdt1,2, Annabel K. Sangree1,2, Ruth E. Hanna1,2, Kendall R. Sanson1,2, Mudra Hegde 1, Christine Strand 1, Nicole S. Persky1 & John G. Doench 1* Isogenic pairs of cell lines, which differ by a single genetic modification, are powerful tools for understanding gene function. Generating such pairs of mammalian cells, however, is labor- 1234567890():,; intensive, time-consuming, and, in some cell types, essentially impossible. Here, we present an approach to create isogenic pairs of cells that avoids single cell cloning, and screen these pairs with genome-wide CRISPR-Cas9 libraries to generate genetic interaction maps. We query the anti-apoptotic genes BCL2L1 and MCL1, and the DNA damage repair gene PARP1, identifying both expected and uncharacterized buffering and synthetic lethal interactions. Additionally, we compare acute CRISPR-based knockout, single cell clones, and small- molecule inhibition. We observe that, while the approaches provide largely overlapping information, differences emerge, highlighting an important consideration when employing genetic screens to identify and characterize potential drug targets. We anticipate that this methodology will be broadly useful to comprehensively study gene function across many contexts. 1 Genetic Perturbation Platform, Broad Institute of MIT and Harvard, 75 Ames Street, Cambridge, MA 02142, USA. 2These authors contributed equally: Peter C. DeWeirdt, -

Supporting Information for Proteomics DOI 10.1002/Pmic.200400896
Supporting Information for Proteomics DOI 10.1002/pmic.200400896 Odette Prat, Frdric Berenguer, Vronique Malard, Emmanuelle Tavan, Nicole Sage, Grard Steinmetz and Eric Quemeneur Transcriptomic and proteomic responses of human renal HEK293 cells to uranium toxicity ª 2004 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim www.proteomics-journal.de Table 1 : Differentially expressed genes in HEK293 cells treated with uranium at CI50 , CI30 and CI20. GENE ID GENE DESCRIPTION CI50 CI30 CI20 AANAT arylalkylamine N-acetyltransferase 1.66 AASDHPPT aminoadipate-semialdehyde dehydrogenase-phosphopantetheinyl transferase -1.73 ABCC8 ATP-binding cassette, sub-family C (CFTR/MRP), member 8 2.96 2.9 ABCF2 ATP-binding cassette, sub-family F (GCN20), member 2 1.86 ACAT2 acetyl-Coenzyme A acetyltransferase 2 (acetoacetyl Coenzyme A thiolase) -2.47 ACTB actin, beta -2.12 ACTR2 ARP2 actin-related protein 2 homolog (yeast) -1.94 ADAR adenosine deaminase, RNA-specific 1.87 1.92 ADNP activity-dependent neuroprotector -1.03 ADPRTL1 ADP-ribosyltransferase (NAD+; poly (ADP-ribose) polymerase)-like 1 1.48 2.31 2.1 AKAP1 A kinase (PRKA) anchor protein 1 1.59 AKR1C3 aldo-keto reductase family 1, member C3 -1.37 (3-alpha hydroxysteroid dehydrogenase, type II) ALS2CR3 amyotrophic lateral sclerosis 2 (juvenile) chromosome region, candidate 3 -1.21 APBB1 amyloid beta (A4) precursor protein-binding, family B, member 1 (Fe65) 4.41 APC adenomatosis polyposis coli -1.66 APP amyloid beta (A4) precursor protein (protease nexin-II, Alzheimer disease) -1.32 APPBP1 amyloid beta precursor -
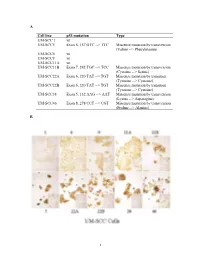
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Manual Annotation and Analysis of the Defensin Gene Cluster in the C57BL
BMC Genomics BioMed Central Research article Open Access Manual annotation and analysis of the defensin gene cluster in the C57BL/6J mouse reference genome Clara Amid*†1, Linda M Rehaume*†2, Kelly L Brown2,3, James GR Gilbert1, Gordon Dougan1, Robert EW Hancock2 and Jennifer L Harrow1 Address: 1Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Hinxton, Cambridgeshire CB10 1SA, UK, 2University of British Columbia, Centre for Microbial Disease & Immunity Research, 2259 Lower Mall, Vancouver, BC, V6T 1Z4, Canada and 3Department of Rheumatology and Inflammation Research, Göteborg University, Guldhedsgatan 10, S-413 46 Göteborg, Sweden Email: Clara Amid* - [email protected]; Linda M Rehaume* - [email protected]; Kelly L Brown - [email protected]; James GR Gilbert - [email protected]; Gordon Dougan - [email protected]; Robert EW Hancock - [email protected]; Jennifer L Harrow - [email protected] * Corresponding authors †Equal contributors Published: 15 December 2009 Received: 15 May 2009 Accepted: 15 December 2009 BMC Genomics 2009, 10:606 doi:10.1186/1471-2164-10-606 This article is available from: http://www.biomedcentral.com/1471-2164/10/606 © 2009 Amid et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Host defense peptides are a critical component of the innate immune system. Human alpha- and beta-defensin genes are subject to copy number variation (CNV) and historically the organization of mouse alpha-defensin genes has been poorly defined. -

The Mutational Landscape of Myeloid Leukaemia in Down Syndrome
cancers Review The Mutational Landscape of Myeloid Leukaemia in Down Syndrome Carini Picardi Morais de Castro 1, Maria Cadefau 1,2 and Sergi Cuartero 1,2,* 1 Josep Carreras Leukaemia Research Institute (IJC), Campus Can Ruti, 08916 Badalona, Spain; [email protected] (C.P.M.d.C); [email protected] (M.C.) 2 Germans Trias i Pujol Research Institute (IGTP), Campus Can Ruti, 08916 Badalona, Spain * Correspondence: [email protected] Simple Summary: Leukaemia occurs when specific mutations promote aberrant transcriptional and proliferation programs, which drive uncontrolled cell division and inhibit the cell’s capacity to differentiate. In this review, we summarize the most frequent genetic lesions found in myeloid leukaemia of Down syndrome, a rare paediatric leukaemia specific to individuals with trisomy 21. The evolution of this disease follows a well-defined sequence of events and represents a unique model to understand how the ordered acquisition of mutations drives malignancy. Abstract: Children with Down syndrome (DS) are particularly prone to haematopoietic disorders. Paediatric myeloid malignancies in DS occur at an unusually high frequency and generally follow a well-defined stepwise clinical evolution. First, the acquisition of mutations in the GATA1 transcription factor gives rise to a transient myeloproliferative disorder (TMD) in DS newborns. While this condition spontaneously resolves in most cases, some clones can acquire additional mutations, which trigger myeloid leukaemia of Down syndrome (ML-DS). These secondary mutations are predominantly found in chromatin and epigenetic regulators—such as cohesin, CTCF or EZH2—and Citation: de Castro, C.P.M.; Cadefau, in signalling mediators of the JAK/STAT and RAS pathways. -

Adult Acute Myeloid Leukemia with Trisomy 11 As the Sole Abnormality
Letters to the Editor 2254 Adult acute myeloid leukemia with trisomy 11 as the sole abnormality is characterized by the presence of five distinct gene mutations: MLL-PTD, DNMT3A, U2AF1, FLT3-ITD and IDH2 Leukemia (2016) 30, 2254–2258; doi:10.1038/leu.2016.196 sequencing approach at the DNA level were also analyzed at the RNA level by visual inspection of the BAM files. The clinical characteristics and outcomes of 23 patients with Trisomy of chromosome 11 (+11) is the second most common sole +11 are summarized in Table 1. The patients were isolated trisomy in acute myeloid leukemia (AML) patients.1 The presence of +11 is associated with intermediate2,3 or poor 4–6 Table 1. Pretreatment clinical and molecular characteristics and patient outcomes. Whereas the clinical characteristics of solitary outcome of patients with acute myeloid leukemia (AML) and sole +11 +11 have been well established,4–6 relatively little is known about the mutational landscape of sole +11 AML in the age of next- Characteristica Sole +11 AML (n = 23) generation sequencing techniques that allow examination of multiple genes relevant to AML pathogenesis.6 So far, the most Age, years Median 71 common molecular feature in AML with isolated +11 is the – presence of a partial tandem duplication of the MLL (KMT2A) gene Range 25 84 (MLL-PTD), which is detectable in up to 90% of patients.7 Age group, n (%) Furthermore, a frequent co-occurrence of the FLT3 internal o60 years 18 (78) tandem duplication (FLT3-ITD) with MLL-PTD has been reported.8 ⩾ 60 years 5 (22) The aim of our study was to better characterize the mutational Female sex, n (%) 5 (22) landscape of adult AML patients with sole +11. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Genetic Analysis of Hereditary Sensory, Motor and Autonomic
Genetic analysis of hereditary sensory, motor and autonomic neuropathies, including a rat model Ming-Jen Lee A thesis submitted to the University of London for the degree of Doctor of Philosophy August 2002 Institute of Neurology University of London ProQuest Number: 10016056 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest. ProQuest 10016056 Published by ProQuest LLC(2016). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 To my wife and my parents Who supported me throughout my studies. Acknowledgements I would like to thank Dr. Mike Groves and Professor Francesco Scaravilli, for their help in the animal breeding and phenotype characterization. I am also indebted to Dr. Dennis Stephenson, MacLaughlin Institute, Grate Fall, Montana, USA. for advice on positional cloning and on the construction of the rat/mouse/human comparative genetic map. His idea on BLAST searches between Celera mouse genome database and rat markers, made a breakthrough in selecting candidate genes, which lead me to identify the m f gene. I am grateful to Dr. Pete Dixon and Dr. Mary Davis for their advice on genetic linkage and physical mapping. -

Mapping DNA Structural Variation in Dogs
Downloaded from genome.cshlp.org on October 3, 2021 - Published by Cold Spring Harbor Laboratory Press Resource Mapping DNA structural variation in dogs Wei-Kang Chen,1,4 Joshua D. Swartz,1,4,5 Laura J. Rush,2 and Carlos E. Alvarez1,3,6 1Center for Molecular and Human Genetics, The Research Institute at Nationwide Children’s Hospital, Columbus, Ohio 43205, USA; 2Department of Veterinary Biosciences, The Ohio State University, Columbus, Ohio 43210, USA; 3Department of Pediatrics, The Ohio State University College of Medicine, Columbus, Ohio 43210, USA DNA structural variation (SV) comprises a major portion of genetic diversity, but its biological impact is unclear. We propose that the genetic history and extraordinary phenotypic variation of dogs make them an ideal mammal in which to study the effects of SV on biology and disease. The hundreds of existing dog breeds were created by selection of extreme morphological and behavioral traits. And along with those traits, each breed carries increased risk for different diseases. We used array CGH to create the first map of DNA copy number variation (CNV) or SV in dogs. The extent of this variation, and some of the gene classes affected, are similar to those of mice and humans. Most canine CNVs affect genes, including disease and candidate disease genes, and are thus likely to be functional. We identified many CNVs that may be breed or breed class specific. Cluster analysis of CNV regions showed that dog breeds tend to group according to breed classes. Our combined findings suggest many CNVs are (1) in linkage disequilibrium with flanking sequence, and (2) associated with breed-specific traits. -

UNIVERSITY of CALIFORNIA RIVERSIDE Investigations Into The
UNIVERSITY OF CALIFORNIA RIVERSIDE Investigations into the Role of TAF1-mediated Phosphorylation in Gene Regulation A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Cell, Molecular and Developmental Biology by Brian James Gadd December 2012 Dissertation Committee: Dr. Xuan Liu, Chairperson Dr. Frank Sauer Dr. Frances M. Sladek Copyright by Brian James Gadd 2012 The Dissertation of Brian James Gadd is approved Committee Chairperson University of California, Riverside Acknowledgments I am thankful to Dr. Liu for her patience and support over the last eight years. I am deeply indebted to my committee members, Dr. Frank Sauer and Dr. Frances Sladek for the insightful comments on my research and this dissertation. Thanks goes out to CMDB, especially Dr. Bachant, Dr. Springer and Kathy Redd for their support. Thanks to all the members of the Liu lab both past and present. A very special thanks to the members of the Sauer lab, including Silvia, Stephane, David, Matt, Stephen, Ninuo, Toby, Josh, Alice, Alex and Flora. You have made all the years here fly by and made them so enjoyable. From the Sladek lab I want to thank Eugene, John, Linh and Karthi. Special thanks go out to all the friends I’ve made over the years here. Chris, Amber, Stephane and David, thank you so much for feeding me, encouraging me and keeping me sane. Thanks to the brothers for all your encouragement and prayers. To any I haven’t mentioned by name, I promise I haven’t forgotten all you’ve done for me during my graduate years. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase