Universidade Federal Do Amazonas Instituto De Computaç˜Ao Programa De Pós-Graduaç˜Ao Em Informática Recognition and Linkin
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bluetooth Kompatibilitätsliste Für Den Falk F10
Bluetooth Kompatibilitätsliste für den Falk F10 Der Falk F10 ist mit der Bluetoothfunktion ausgestattet. In wenigen Schritten kann Ihr Navigationsgerät als Freisprecheinrichtung für Ihr Mobiltelefon umgewandelt werden. Die folgende Liste enthält alle auf Funktion getesteten Mobiltelefone. Die Kompatibilität weiterer Telefone ist möglich. Abbildung ähnlich Mobiltelefon Anrufe Import Anzeige Ein-/ Aus- Neue Nr. / Name Auflegen Kontakte Anruflisten SMS gehend SMS Anrufer Apple iPhone Y / Y Y Y Y X X Y / Y BlackBerry 7100g Y / Y Y Y X X X Y / X BlackBerry 7130g Y / Y Y Y X X X Y / X BlackBerry 7290 Y / Y Y X X X X Y / X BlackBerry 8100 Y / Y Y X X X X Y / X BlackBerry 8300 Y / Y Y Y Y X X Y / X BlackBerry 8700g Y / Y Y Y X X X Y / X BlackBerry 8800 Y / Y Y Y X X X Y / X Dopod 585 Y / Y Y X X X X Y / X Dopod 586W Y / Y Y X X X X Y / Y Dopod CHT 9000 Y / Y Y Y Y X X Y / X Dopod S300 Y / Y Y Y Y X X Y / Y Dopod 838 Y / Y Y Y Y X X Y / Y ETEN X500 Y / Y Y Y Y X X Y / Y ETEN G500 Y / Y Y Y Y X X Y / Y HP iPAQ 6365 Y / Y Y X X X X Y / X HP iPAQ rw6828 Y / Y Y Y Y X X Y / X HTC Touch Y / Y Y Y Y X X Y / Y HTC TyTN II Y / Y Y Y Y X X Y / Y LG KE500 Y / Y Y X X X X Y / X LG KE970 Y / Y Y X X X X Y / X LG KU800 Y / Y Y X X X X Y / X LG KU970 Y / Y Y X X X X Y / X LG KE790 Y / Y Y X X X X Y / X LG KE290 Y / Y Y Y X X X Y / X LG KE600 Y / Y Y Y X Y X Y / Y LG KE800 Y / Y Y Y X Y X Y / Y LGKS20 Y / Y Y X X X X Y / X Motorola A1200 Y / Y Y Y Y Y X Y / Y Motorola A630 Y / Y Y Y Y Y Y Y / Y Motorola E1 Y / Y Y Y Y Y Y Y / X Bluetooth Kompatibilitätsliste für den Falk F10 Complete Mobiltelefon Anrufe Import Anzeige Ein-/ Aus- Neue Nr. -

Cell Phones and Pdas
eCycle Group - Check Prices Page 1 of 19 Track Your Shipment *** Introductory Print Cartridge Version Not Accepted February 4, 2010, 2:18 pm Print Check List *** We pay .10 cents for all cell phones NOT on the list *** To receive the most for your phones, they must include the battery and back cover. Model Price Apple Apple iPhone (16GB) $50.00 Apple iPhone (16GB) 3G $75.00 Apple iPhone (32GB) 3G $75.00 Apple iPhone (4GB) $20.00 Apple iPhone (8GB) $40.00 Apple iPhone (8GB) 3G $75.00 Audiovox Audiovox CDM-8930 $2.00 Audiovox PPC-6600KIT $1.00 Audiovox PPC-6601 $1.00 Audiovox PPC-6601KIT $1.00 Audiovox PPC-6700 $2.00 Audiovox PPC-XV6700 $5.00 Audiovox SMT-5500 $1.00 Audiovox SMT-5600 $1.00 Audiovox XV-6600WOC $2.00 Audiovox XV-6700 $3.00 Blackberry Blackberry 5790 $1.00 Blackberry 7100G $1.00 Blackberry 7100T $1.00 Blackberry 7105T $1.00 Blackberry 7130C $2.00 http://www.ecyclegroup.com/checkprices.php?content=cell 2/4/2010 eCycle Group - Check Prices Page 2 of 19 Search for Pricing Blackberry 7130G $2.50 Blackberry 7290 $3.00 Blackberry 8100 $19.00 Blackberry 8110 $18.00 Blackberry 8120 $19.00 Blackberry 8130 $2.50 Blackberry 8130C $6.00 Blackberry 8220 $22.00 Blackberry 8230 $15.00 Blackberry 8300 $23.00 Blackberry 8310 $23.00 Blackberry 8320 $28.00 Blackberry 8330 $5.00 Blackberry 8350 $20.00 Blackberry 8350i $45.00 Blackberry 8520 $35.00 Blackberry 8700C $6.50 Blackberry 8700G $8.50 Blackberry 8700R $7.50 Blackberry 8700V $6.00 Blackberry 8703 $1.00 Blackberry 8703E $1.50 Blackberry 8705G $1.00 Blackberry 8707G $5.00 Blackberry 8707V -

Zcover™ Announces Gloveone Silicone Protective Cases for the First Mobile Phone with Itunes Motorola ROKR® Now Available for Shipping
NEWS Richmond BC, Canada November 16, 2005 zCover™ Announces gloveOne Silicone Protective Cases for The First Mobile Phone with iTunes Motorola ROKR® Now Available for Shipping zCover Inc, the leading manufacturer of fashionable silicone protective cases has announced today the release of their gloveOne series Fashionable Silicone Protective Case for the first mobile phone with iTunes Motorola ROKR® today zCover leads the way in manufacturing a high quality product that is always ready for the ever changing market of technology. For the consumer of the Motorola ROKR® with iTunes, zCover has you covered with their gloveOne cases now available for shipping. zCover is offering a selection of 4 colors to the consumer. Each zCover “gloveOne” retail pack contains one protective case and a new designed removable rotary one-button-release cell phone belt clip. “gloveOne is a mature product line of zCover for all kinds of smart phones and PDAs. The development of such an extensive line of new gloveOne protective cases for the first mobile phone with iTunes, demonstrates our ability to lead the way in fashionable silicone protective cases." said Sean Sa, vice president of ZCOVER INC. “ROKR users want their ROKR to be as unique and colourful as their iPod and their music collection, and be able to change the look of your ROKR in the iPod’s way, zCover is the way for your fashion and your style, all while keeping your investment safe from scratches.” The gloveOne stylish and contoured design allows you to show off your unique personality and provides serious protection from scratching the surface of your ROKR. -
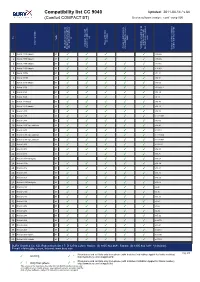
BURY Compatibility List Generator
Compatibility list CC 9040 Updated: 2011-04-14 / v.64 (Comfort COMPACT BT) Device software version: comf_comp V05 on No key keys tags) Profile activation service provider Phone s REDIAL / private mode with Activation Bluetooth connection with device Bluetooth connection to used to test/ Comments after ignition is switched Access to mobile phone voice-dial function (voice the last connected phone Bluetooth device / phones Possibility to switch car kit Version of phone software 1 Nokia 2323 classic hf ✓ ✓ ✓ ✓ v 06.46 2 Nokia 2330 classic hf ✓ ✓ ✓ ✓ v 06.46 3 Nokia 2700 classic hf ✓ ✓ ✓ ✓ ✓ v 07.15 4 Nokia 2730 classic hf ✓ ✓ ✓ ✓ ✓ v 10.40 5 Nokia 3109c hf ✓ ✓ ✓ ✓ ✓ v07.21 6 Nokia 3110c hf ✓ ✓ ✓ ✓ ✓ v04.91 7 Nokia 3120 classic hf ✓ ✓ ✓ ✓ ✓ v10.00 8 Nokia 3230 hf ✓ ✓ ✓ ✓ ✓ v3.0505.2 9 Nokia 3250 hf ✓ ✓ ✓ ✓ ✓ v03.24 10 Nokia 3650 hf ✓ ✓ ✓ ✓ ✓ v4.13 11 Nokia 3710 fold hf ✓ ✓ ✓ ✓ ✓ v03.80 12 Nokia 3720 classic hf ✓ ✓ ✓ ✓ ✓ v09.10 13 Nokia 5200 hf ✓ ✓ ✓ ✓ ✓ v03.92 14 Nokia 5230 hf ✓ ✓ ✓ ✓ ✓ v 12.0.089 15 Nokia 5300 hf ✓ ✓ ✓ ✓ ✓ v05.00 16 Nokia 5310 XpressMusic hf ✓ ✓ ✓ ✓ ✓ v09.42 17 Nokia 5500 hf ✓ ✓ ✓ ✓ ✓ v 03.18 18 Nokia 5530 XpressMusic hf ✓ ✓ ✓ ✓ ✓ v 11.0.054 19 Nokia 5630 XpressMusic hf ✓ ✓ ✓ ✓ ✓ v 012.008 20 Nokia 5700 hf ✓ ✓ ✓ ✓ ✓ v 03.83.1 21 Nokia 6103 hf ✓ ✓ ✓ ✓ ✓ v04.90 22 Nokia 6021 hf ✓ ✓ ✓ ✓ ✓ v03.87 23 Nokia 6110 Navigator hf ✓ ✓ ✓ v03.58 24 Nokia 6124c hf ✓ ✓ ✓ ✓ ✓ v04.34 25 Nokia 6125 hf ✓ ✓ ✓ ✓ ✓ v03.71 26 Nokia 6131 hf ✓ ✓ ✓ ✓ v03.70 27 Nokia 6151 hf ✓ ✓ ✓ ✓ ✓ v03.56 28 Nokia 6210 Navigator hf ✓ ✓ ✓ ✓ ✓ v03.08 29 Nokia 6230 hf ✓ ✓ ✓ ✓ ✓ v5.40 30 Nokia 6230i hf ✓ ✓ ✓ ✓ ✓ v3.30 31 Nokia 6233 hf ✓ ✓ ✓ ✓ ✓ v03.70 32 Nokia 6234 hf ✓ ✓ ✓ ✓ ✓ v3.50 33 Nokia 6270 hf ✓ ✓ ✓ ✓ ✓ v3.66 34 Nokia 6280 hf ✓ ✓ ✓ ✓ ✓ v4.25 35 Nokia 6288 hf ✓ ✓ ✓ ✓ ✓ v05.92 36 Nokia 6300 hf ✓ ✓ ✓ ✓ ✓ v 04.70 37 Nokia 6300i hf ✓ ✓ ✓ ✓ ✓ v03.41 38 Nokia 6301 hf ✓ ✓ ✓ ✓ ✓ v 04.61 39 Nokia 6303 classic hf ✓ ✓ ✓ ✓ ✓ v 08.90 40 Nokia 6303i classic hf ✓ ✓ ✓ ✓ ✓ v 07.10 BURY GmbH & Co. -

The Symbiotic Relationship Between App Developers and Platforms: a Ten-Year Retrospective Preface
The Symbiotic Relationship Between App Developers and Platforms: A Ten-Year Retrospective Preface It is often easy to forget the journey once we arrive at the destination. We forget the bumps in the road and often overlook factors that made the trip possible. The app economy’s trajectory is no different. In nearly a decade of existence, the app ecosystem has grown exponentially alongside the rise of the smartphone. Valued at $950 billion,i the app economy is driven by app developers and innovators who depend on platforms like Apple’s App Store to reach consumers around the globe. In 2017 alone, 3.4 billion people spent 1.6 trillion hours using apps across a variety of platforms,ii and the reach of software applications continues to grow. This paper offers a look at the journey and the symbiotic relationship between app developers and platforms that drive the app economy. I. Introduction Much has changed for consumers and developers since the early days of software applications. In the early 1990s, consumers were tasked with the challenge of locating and then traveling to a brick-and-mortar store that happened to sell software. Once internet connectivity became a standard feature in most private residences, consumers began to download applications from the comfort of their homes without having to step foot in a physical store. Still, the golden age of PC software pales in comparison to the size and scale of the mobile app revolution during which software developers evolved into app developers. Today, software titles in Apple’s App Store for iOS and Mac exceed 1.5 million.iii Before the ubiquity of mobile platforms, the software ecosystem ran on personal computers. -

We've Got Christmas Wrapped
November 2005 Press Release We’ve got Christmas wrapped up! Whatever you’re into for Christmas, everyone loves a new mobile phone. It’s the one thing, along with your keys and wallet that you never leave home without - making it the perfect present! The Carphone Warehouse has got more exciting and stylish handsets than ever before – all at amazingly low prices – keeping your friends and family merry this Christmas. With pre-pay handsets from an incredible £19.99 (plus £10 top up) Christmas has never been easier. For a truly unique gift this year, take advantage of the new Golden Ticket initiative exclusively from The Carphone Warehouse. This is the ultimate Christmas idea that keeps friends and family talking all year round. It gives you the chance to buy one of the latest handsets with line rental paid up front for a whole year making it easy for them to stay in touch while saving money at the same time. And get your hands on the number one must have for all fashion fans this Christmas – the Motorola Pink Razr – available exclusively at The Carphone Warehouse for a limited period. Spread festive joy under the Christmas tree – with the best fashion phones, music phones cameraphones and mobile accessories for all your family and friends. See below for the latest Christmas present ideas at the most competitive prices on the high-street…. Best value buys for Christmas - The Motorola C139 and Nokia 1100 for JUST £19.99 The Carphone Warehouse is the ultimate destination for the best priced phones this Christmas. -

Sony Smart Wireless Headset Pro – Compatibility with Other Brands
Last updated: June 29, 2012 Sony Smart Wireless Headset pro – Compatibility with other brands Independent testing has confirmed that this device works with Bluetooth™ enabled phones from other manufacturers such as iPhone, Motorola, Samsung and HTC. All of the products listed below, even with partial compatibility, have full Bluetooth™ functionality. Model / Android device Widgets/Applications: Comment Compatible Apple iPhone 3G No track information displayed. Notifications, call Partial log and media title not available Apple iPhone 3GS Notifications, call log and media title not available Partial Apple iPhone 4 Notifications, call log and media title not available Partial Apple iPhone 4S Notifications, call log and media title not available Partial Blackberry 9380 Notifications, call log and media title not available Partial Blackberry 8520 Curve No track information displayed. Notifications, call Partial log and media title not available Blackberry 9105 Pearl 3G Notifications, call log and media title not available Partial Blackberry 9300 Curve 3G Notifications, call log and media title not available Partial Blackberry 9700 Bold Notifications, call log and media title not available Partial Blackberry 9780 Bold Notifications, call log and media title not available Partial Blackberry 9800 Torch Notifications, call log and media title not available Partial Blackberry 9860 Torch Notifications, call log and media title not available Partial Blackberry 9900 Bold Notifications, call log and media title not available Partial Blackberry Playbook -

Off Your ROKR
More reviews online at Review www.mobilechoiceuk.com Motorola ROKR E8 Price: From free on contract Motorola ROKR E8 www.motorola.com Size 115x53x10.6mm Weight 100g Display 262,000 colours Resolution 240x320 pixels Camera Two megapixels Video recording/playback/ streaming Yes/yes/yes Video calling Yes Audio playback MP3, AAC Ringtones MP3, AAC FM radio Yes Connectivity Bluetooth, USB, A2DP Off your ROKR Operating system N/A Internal memory 2GB Memory card slot microSD Motorola’s new ROKR E8 is a music phone with attitude, and boasts a clever Messaging SMS, MMS, IM, touch-screen interface and some neat features. But is it too big to be a hit? email Internet browser WAP/ xHTML/HTML Java Yes T has been a tumultuous year for façade are the regularly-spaced Music capabilities Games Yes Motorola, with high-profile dimples that sit in the centre of each The ROKR E8’s music player has Data speed EDGE boardroom wrangles more virtual key. some real strengths and some I Frequency Quad-band common than its high-profile phone The ROKR E8 is the latest phone obvious weaknesses. Talktime 300 minutes launches. However, the manufacturer to sport a touch-screen keypad. As you’d expect, it’s a marked Standby 300 hours is hoping to draw attention back to There are no raised keys, but it’s a improvement on the original ROKR. the technology with its two major haptic keypad, so it vibrates when Essential music features include a Features summer launches; the MOTO Z10 you touch a virtual key. 3.5mm headset port, 2GB of Haptic touch-screen and the ROKR E8. -
CK5050(P) Matrix
Bluetooth firmware Version 1.60 yes = Feature is supported and confirmed. n o = Feature is not supported by the Kenwood Bluetooth Module. n /a = Feature is not supported by the Phone. Phone connection Pick-up Reject Phonebook SIM contacts Call register Pick-up second Refuse second Switch call in Hang-up active Display Enable to use Enable to Enable to Dial Private Display Phonebook Enable to use Enable to Notify about Phone to KENWOOD and Hang- Redial incoming automatic automatic automatic call in three call in three three way call in three network AVRCP Target read SMS read SMS Phone number mode battery level transfer A2DP profile send SMS new SMS Bluetooth Model up a call call synchronisation synchronisation synchronisation way calling way calling calling way calling level profile from SIM card from phone Apple iPhone 1.1.4 (4A102) yes yes yes yes yes yes yes n/a yes yes yes yes yes yes yes n/a n/a n/a n/a n/a n/a n/a Apple iPhone 1.1.4 (4A102) Apple iPhone AT&T 1.0.2 (1C28) yes yes yes yes yes yes yes n/a yes yes yes yes yes yes yes n/a n/a n/a n/a n/a n/a n/a Apple iPhone AT&T 1.0.2 (1C28) AU W54S yes yes yes yes yes yes n/a n/a n/a no n/a no no yes yes yes no no n/a n/a n/a n/a AU W54S BenQ-Siemens CL71 1.16 yes yes yes yes no no n/a n/a n/a no n/a n/a n/a n/a n/a yes n/a n/a n/a n/a n/a n/a BenQ-Siemens CL71 1.16 BenQ-Siemens EF61 1 yes yes yes yes yes no no no no yes yes yes yes n/a n/a no n/a n/a n/a n/a n/a n/a BenQ-Siemens EF61 1 Blackberry 7105t V4.0.2.49 no yes yes yes yes yes no no n/a yes yes no no yes yes n/a n/a n/a n/a -

Loa Performer Versio 8 Mobile Ba Ki G Module
LOA PERFORMER VERSIO 8 MOBILE BAKIG MODULE LPF provides the following technologies for sending SMS messages to mobile phone users: 1. EDGE/GSM/GPRS by use of Modem 2. SMPP by a bulk SMS Service Provider Below are the requirements for each of the above technologies. GEERAL REQUIREMETS: • Loan Performer version 8 or later. • LPF Mobile on the client’s cell phone. See the “LPF Mobile Installation Guide”. • LPF Mobile Banking License. This goes at 20% on top of the normal license plus 1$ per account. The demo database allows you to create 10 accounts for testing purposes. EDGE/GSM/GPRS (for Sending and Receiving SMS) • Compatible EDGE/GSM/GPRS Modem with Sim Card • Reliable Mobile Telephone network • Java/Wap enabled mobile phones (cell phones) SMPP (Optional) The bulk SMS Service provider gives the following details (to be entered at Configuration): • Server URL • Port • Username • Password ITER-MFI TRASACTIOS (I ADDITIO TO THE ABOVE REQUIREMETS): • Reliable Internet Connection 512kbps or higher upload/download Inter-MFI transactions are possible between different Loan Performer databases, either as separate branches of a single institution or between different institutions that use Loan Performer. COMPATIBLE EDGE/GSM/GPRS MODEMS Falcom Wavecom SAMBA 3G SAMBA 75 SAMBA 75i Fastrack Fastrack Windows (USB only) (USB only) (USB only) Supreme USB Supreme Serial 2008 x64 Supported Supported Supported Not Supported Supported (serial) 2008 x86 Supported Supported Supported Supported Supported (serial) Not Not Not 2003 x64 Not Supported Supported -

Written Statement of Barbara S. Esbin Senior Fellow and Director of the Center for Communications and Competition Policy the Pr
Written Statement of Barbara S. Esbin Senior Fellow and Director of the Center for Communications and Competition Policy The Progress & Freedom Foundation Before the Senate Committee on Commerce, Science & Transportation Hearing on “The Consumer Wireless Experience” June 17, 2009 Written Statement of Barbara S. Esbin Senior Fellow and Director of the Center for Communications and Competition Policy The Progress & Freedom Foundation Before the Senate Committee on Commerce, Science & Transportation Hearing on “The Consumer Wireless Experience” June 17, 2009 I. Introduction ............................................................................................................. 1 II. The Wireless Service and Handset Markets are Thriving ...................................... 2 III. Calls for Exclusive Handset Prohibitions Overstate the Harms and Understate the Pro-Competitive Benefits........................................................................................ 6 A. The iPhone is an Example of a Successful Exclusive Distribution Arrangement ............................................................................................... 8 B. The Harms of Exclusive Arrangements are Overstated ............................ 10 C. The Benefits of Exclusive Handset Arrangements Are Increased Innovation and Competition ..................................................................... 13 IV. Competition Should be Protected, not Competitors ............................................. 16 V. Existing FCC Policy and Rules Correctly -

Motorola ROKR E8
Motorola ROKR E8 O verview Dont let this candy bar fool you! From the innovative morphing key pad designed specically for the camera, music and phone function, to the haptic response of the keypad, to the scrolling track wheel and built-in FM radio, the Motorola ROKR E8 is awe-inspiring. The brilliant display, highlighted by the ROKR E8 phones glasslike casing, is perfect for browsing in full HTML and for showing o. Enjoy the 2 GB of on-board memory with the loaded music player for the music lover in you. Additional Features Rogers Music Player and Motorola music player Text, instant and multimedia messaging Embedded games and ring tunes Accessories: battery, Micro Data cable, travel charger, stereo headset, and Motorola Phone Tool Real Audio 8 Sipro (ACELP®.net), Real Audio 10 Key Features 2.0 MP camera with 8 x digital zoom, multi-shot feature, video capture and playback Song ID feature that recognizes and displays tune information ModeShift technology that transforms device from phone to music player Expandable memory up to 4 GB with 2 GB onboard memory Quad-band EDGE with Stereo Bluetooth® Battery Life 6 Hours Talk time 10 Days Standby Time Specifications Display Size & Weight Type TFT Screen Height Resolution 240 x 320 pixels 4.5 in (115mm) Colour Yes (262,000) Width 2.1 in (53 mm) Memory Depth Internal Memory Storage 2 MB 0.4 in (10.6 mm) Expandable Memory Storage Up to 8 GB Weight Memory Format MicroSD 3.7 oz (106 g) Wireless Technology GSM/GPRS/EDGE 850/900/1800/1900 MHz Bluetooth Technology Stereo Note: Specications are subject to change without prior notice.