Cover Song Synthesis by Analogy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Excesss Karaoke Master by Artist
XS Master by ARTIST Artist Song Title Artist Song Title (hed) Planet Earth Bartender TOOTIMETOOTIMETOOTIM ? & The Mysterians 96 Tears E 10 Years Beautiful UGH! Wasteland 1999 Man United Squad Lift It High (All About 10,000 Maniacs Candy Everybody Wants Belief) More Than This 2 Chainz Bigger Than You (feat. Drake & Quavo) [clean] Trouble Me I'm Different 100 Proof Aged In Soul Somebody's Been Sleeping I'm Different (explicit) 10cc Donna 2 Chainz & Chris Brown Countdown Dreadlock Holiday 2 Chainz & Kendrick Fuckin' Problems I'm Mandy Fly Me Lamar I'm Not In Love 2 Chainz & Pharrell Feds Watching (explicit) Rubber Bullets 2 Chainz feat Drake No Lie (explicit) Things We Do For Love, 2 Chainz feat Kanye West Birthday Song (explicit) The 2 Evisa Oh La La La Wall Street Shuffle 2 Live Crew Do Wah Diddy Diddy 112 Dance With Me Me So Horny It's Over Now We Want Some Pussy Peaches & Cream 2 Pac California Love U Already Know Changes 112 feat Mase Puff Daddy Only You & Notorious B.I.G. Dear Mama 12 Gauge Dunkie Butt I Get Around 12 Stones We Are One Thugz Mansion 1910 Fruitgum Co. Simon Says Until The End Of Time 1975, The Chocolate 2 Pistols & Ray J You Know Me City, The 2 Pistols & T-Pain & Tay She Got It Dizm Girls (clean) 2 Unlimited No Limits If You're Too Shy (Let Me Know) 20 Fingers Short Dick Man If You're Too Shy (Let Me 21 Savage & Offset &Metro Ghostface Killers Know) Boomin & Travis Scott It's Not Living (If It's Not 21st Century Girls 21st Century Girls With You 2am Club Too Fucked Up To Call It's Not Living (If It's Not 2AM Club Not -

Michael Jackson - Bad 25 (Deluxe 3CD+DVD Box Set)
Michael Jackson - Bad 25 (Deluxe 3CD+DVD Box Set) CD 1 – re-mastered CD 2 – Bonus Tracks, Demo, Rarities and 1. Bad Remixes 2. The Way You Make Me Feel 1. Don’t Be Messin’ Around 3. Speed Demon 2. I’m So Blue 4. Liberian Girl 3. Song Groove (A/K/A Abortion Papers) 5. Just Good Friends 4. Free 6. Another Part Of Me 5. Price Of Fame 7. Man In The Mirror 6. Al Capone 8. I Just Can’t Stop Lovin’ You 7. Streetwalker 9. Dirty Diana 8. Fly Away 10. Smooth Criminal 9. Todo Mi Amor Eres Tu (I Just Can't Stop 11. Leave Me Alone Loving You, Spanish Version) 10. Je Ne Veux Pas La Fin De Nous (I Just Can't Stop Loving You, French Version) 11. Bad (REMIX BY AFROJACK FEATURING PITBULL - DJ BUDDHA EDIT) 12. Speed Demon (REMIX BY NERO) 13. Bad (REMIX BY AFROJACK - CLUB MIX) CD 3 - CD Live at Wembley Stadium July DVD – Live at Wembley Stadium July 16, 16, 1988 1988 1. Wanna Be Startin' Somethin' 1. Wanna Be Startin' Somethin' 2. This Place Hotel 2. This Place Hotel 3. Another Part Of Me 3. Another Part Of Me 4. I Just Can't Stop Loving You 4. I Just Can't Stop Loving You 5. She's Out Of My Life 5. She's Out Of My Life 6. I Want You Back / The Love You Save / I'll 6. I Want You Back / The Love You Save / I'll Be There Be There 7. -

Michael Jackson the Perform a N C
MICHAEL JACKSON 101 THE PERFORMANCES MICHAEL JACKSON 101 THE PERFORMANCES &E Andy Healy MICHAEL JACKSON 101 THE PERFORMANCES . Andy Healy 2016 Michael gave the world a wealth of music. Songs that would become a part of our collective sound track. Under the Creative Commons licence you are free to share, copy, distribute and transmit this work with the proviso that the work not be altered in any way, shape or form and that all And for that the 101 series is dedicated to Michael written works are credited to Andy Healy as author. This Creative Commons licence does not and all the musicians and producers who brought the music to life. extend to the copyrights held by the photographers and their respective works. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. This special Performances supplement is also dedicated to the choreographers, dancers, directors and musicians who helped realise Michael’s vision. I do not claim any ownership of the photographs featured and all rights reside with the original copyright holders. Images are used under the Fair Use Act and do not intend to infringe on the copyright holders. By a fan for the fans. &E 101 hat makes a great performance? Is it one that delivers a wow factor? W One that stays with an audience long after the houselights have come on? One that stands the test of time? Is it one that signifies a time and place? A turning point in a career? Or simply one that never fails to give you goose bumps and leave you in awe? Michael Jackson was, without doubt, the consummate performer. -
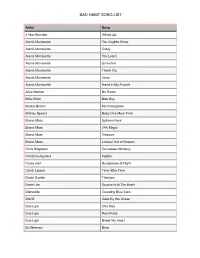
Bad Habit Song List
BAD HABIT SONG LIST Artist Song 4 Non Blondes Whats Up Alanis Morissette You Oughta Know Alanis Morissette Crazy Alanis Morissette You Learn Alanis Morissette Uninvited Alanis Morissette Thank You Alanis Morissette Ironic Alanis Morissette Hand In My Pocket Alice Merton No Roots Billie Eilish Bad Guy Bobby Brown My Prerogative Britney Spears Baby One More Time Bruno Mars Uptown Funk Bruno Mars 24K Magic Bruno Mars Treasure Bruno Mars Locked Out of Heaven Chris Stapleton Tennessee Whiskey Christina Aguilera Fighter Corey Hart Sunglasses at Night Cyndi Lauper Time After Time David Guetta Titanium Deee-Lite Groove Is In The Heart Dishwalla Counting Blue Cars DNCE Cake By the Ocean Dua Lipa One Kiss Dua Lipa New Rules Dua Lipa Break My Heart Ed Sheeran Blow BAD HABIT SONG LIST Artist Song Elle King Ex’s & Oh’s En Vogue Free Your Mind Eurythmics Sweet Dreams Fall Out Boy Beat It George Michael Faith Guns N’ Roses Sweet Child O’ Mine Hailee Steinfeld Starving Halsey Graveyard Imagine Dragons Whatever It Takes Janet Jackson Rhythm Nation Jessie J Price Tag Jet Are You Gonna Be My Girl Jewel Who Will Save Your Soul Jo Dee Messina Heads Carolina, Tails California Jonas Brothers Sucker Journey Separate Ways Justin Timberlake Can’t Stop The Feeling Justin Timberlake Say Something Katy Perry Teenage Dream Katy Perry Dark Horse Katy Perry I Kissed a Girl Kings Of Leon Sex On Fire Lady Gaga Born This Way Lady Gaga Bad Romance Lady Gaga Just Dance Lady Gaga Poker Face Lady Gaga Yoü and I Lady Gaga Telephone BAD HABIT SONG LIST Artist Song Lady Gaga Shallow Letters to Cleo Here and Now Lizzo Truth Hurts Lorde Royals Madonna Vogue Madonna Into The Groove Madonna Holiday Madonna Border Line Madonna Lucky Star Madonna Ray of Light Meghan Trainor All About That Bass Michael Jackson Dirty Diana Michael Jackson Billie Jean Michael Jackson Human Nature Michael Jackson Black Or White Michael Jackson Bad Michael Jackson Wanna Be Startin’ Something Michael Jackson P.Y.T. -

Michael Jackson Thriller Video Dance Version Mp3 Download Michael Jackson Thriller Video Dance Version Mp3 Download
michael jackson thriller video dance version mp3 download Michael jackson thriller video dance version mp3 download. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 67e14fe92ddac442 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. Download Michael Jackson - Michael Jackson's Vision (2009) Album. 1. Don't Stop 'Til You Get Enough 2. Dirty Diana 3. Smooth Criminal 4. Another Part of Me (Live) 5. Speed Demon 6. Come Together 7. Leave Me Alone 8. Liberian Girl 9. Black or White 10. Remember the Time 11. In the Closet 12. Rock With You 13. Jam 14. Heal the World 15. Give In to Me 16. Who Is It 17. Will You Be There 18. Gone Too Soon 19. Scream 20. Childhood (Theme from "Free Willy 2") [Michael Jackson's Vision] 21. You Are Not Alone 22. Earth Song 23. She's Out of My Life 24. They Don't Care About Us 25. -

Michael-Jackson-Speechless.Pdf
Michael Jackson Speechless Sheet Music Download michael jackson speechless sheet music pdf now available in our library. We give you 3 pages partial preview of michael jackson speechless sheet music that you can try for free. This music notes has been read 5798 times and last read at 2021-09-30 12:10:36. In order to continue read the entire sheet music of michael jackson speechless you need to signup, download music sheet notes in pdf format also available for offline reading. Ensemble: Mixed Level: Advanced [ READ SHEET MUSIC ] Other Sheet Music Human Nature Michael Jackson John Mayer From The Michael Jackson Tribute 2009 Human Nature Michael Jackson John Mayer From The Michael Jackson Tribute 2009 sheet music has been read 4797 times. Human nature michael jackson john mayer from the michael jackson tribute 2009 arrangement is for Advanced level. The music notes has 1 preview and last read at 2021-09-29 21:52:28. [ Read More ] Ben Michael Jackson Ben Michael Jackson sheet music has been read 4412 times. Ben michael jackson arrangement is for Early Intermediate level. The music notes has 5 preview and last read at 2021-09-30 17:44:02. [ Read More ] Thriller By Michael Jackson Thriller By Michael Jackson sheet music has been read 3301 times. Thriller by michael jackson arrangement is for Advanced level. The music notes has 1 preview and last read at 2021-09-30 08:26:14. [ Read More ] Michael Jackson Heal The World Michael Jackson Heal The World sheet music has been read 5930 times. Michael jackson heal the world arrangement is for Intermediate level. -

MICHAEL JACKSON 101 Greatest SONGS
MICHAEL JACKSON 101 101 GrEAtESt Songs MICHAEL JACKSON 101 101 GrEAtESt Songs &E Andy Healy MICHAEL JACKSON 101 101 GrEAtESt Songs . Andy Healy 2013 Dedicated first and foremost to Michael Jackson and the Jackson family for a lifetime of music. Under the Creative Commons licence you are free to share, copy, distribute and transmit this work with the proviso that the work not be altered in any way, shape or form and that all And to all the musicians, writers, arrangers, engineers and producers written works are credited to Andy Healy as author. This Creative Commons licence does not who shared their talents and brought these musical masterpieces into being. extend to the copyrights held by the photographers and their respective works. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. This book is also dedicated to the fans the world over - new, old, and yet to be - who by exploring the richness in the art will ensure Michael’s musical legacy I do not claim any ownership of the photographs featured and all rights reside with the original and influence continues on. copyright holders. Images are used under the Fair Use Act and do not intend to infringe on the copyright holders. Finally thanks to Trish who kept the encouragement coming and to all who welcomed this book with open arms. This is a book by a fan for the fans. &E any great books have been written about Michael’s music and artistry. This Mcollection of 101 Greatest Songs is by no means absolute, nor is in intended to be. -

Michael Jackson the Remixes
MICHAEL JACKSON 101 THE REMIXES MICHAEL JACKSON 101 THE REMIXES &E Andy Healy MICHAEL JACKSON 101 THE REMIXES . Andy Healy 2014 Michael gave the world a wealth of music. Songs that would become a part of our collective sound track. Under the Creative Commons licence you are free to share, copy, distribute and transmit this work with the proviso that the work not be altered in any way, shape or form and that all And for that the 101 series is dedicated to Michael written works are credited to Andy Healy as author. This Creative Commons licence does not and all the musicians and producers who brought the music to life. extend to the copyrights held by the photographers and their respective works. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. This special Remix Supplement is also dedicated to producers and remixers who brought their talents to broaden Michael’s reach and made us hear new things I do not claim any ownership of the photographs featured and all rights reside with the original in their reimaginings. copyright holders. Images are used under the Fair Use Act and do not intend to infringe on the copyright holders. By a fan for the fans. &E Official 349 Remixes mOST Remixed tRACKs 27 Remixes JAM stRangeR in 24 Remixes mOscOw 24 Remixes this time aROund they dOn’t caRe 20 Remixes abOut us 18 Remixes whO is it 16 Remixes scReam 16 Remixes in the clOset * includes 7” edits, 12” extended mixes, a cappella & Remixes he Remix. -

LETTERS to the EDITOR. Michael Jackson and the “Smooth Criminal
J Neurosurg Spine 30:415–416, 2019 Neurosurgical Forum LETTERS TO THE EDITOR Michael Jackson and the “Smooth References 1. Yagnick NS, Tripathi M, Mohindra S: How did Michael Criminal” music video: special Jackson challenge our understanding of spine biomechanics? effects J Neurosurg Spine 29:344–345, 2018 Disclosures TO THE EDITOR: I read with interest the article by The author reports no conflict of interest. Yagnick et al.1 (Yagnick NS, Tripathi M, Mohindra S: How did Michael Jackson challenge our understanding Correspondence of spine biomechanics? J Neurosurg Spine 29:344–345, Kevin Pike: [email protected]. September 2018). I felt that I should make you aware of the real history INCLUDE WHEN CITING regarding Michael Jackson’s “Smooth Criminal” dancing Published online December 21, 2018; DOI: 10.3171/2018.9.SPINE181165. technique and the “leaning effect” to which the authors of the article refer. The five dancers were all dressed in “fly belts” under Response their suit clothes, to which were attached fine piano wires We are humbled by Mr. Pike’s attention to our article at their hips. These wires extended through their jackets and we appreciate his description of the filming of the mu- and were connected to a fly arbor and then by cable to a set sic video “Smooth Criminal.” of pulleys overhead in the stage grid. It is possible to see The “antigravity” dance move featured in the music a subtle crease in Michael’s white jacket as he leans. The video became so popular that Michael Jackson wanted to cables extended across the network to another set of pul- re-create the move in live shows. -

Tableaux Main Character
TABLEAUX MAIN CHARACTER Michael Jackson A living presence in the show through video, whispers, laughter, urging, spoken and projected narrative, screaming, silhouettes, elemental forces, etc. Michael’s spirit is guiding the performers and the audience on the journey, culminating with the release from the grip of Mephisto, which leads everyone to reconnect with Michael’s spirit and his child-like heart. Michael is also represented through certain of his visual iconography – his iconic glove, hat, shoes and glasses – which are transformed into talismans meant to represent certain qualities possessed by Michael. He is the primary protagonist, our Guide. And through his music, lyrics and words, he is also our narrator. TABLEAUX The Vortex – Inspired by the first four verses of Beat It The four misfits who are referred to as the Heroes – Clumsy (slackliner), Shy (martial artist), Smarty Pants (juggler), and Sneaky (manipulation specialist) – get sucked into a Vortex after sneaking into the show. Time Tripping – Beat It Time goes crazy as we cross the metaphoric threshold into a magical world inspired by Michael’s imagination. High above the audience, rotating bungees churn to the funk- infused, drum and guitar-driven rhythms of Beat It. Hide & Seek – Leave Me Alone/Tabloid Junkie/Too Bad Mephisto, a malevolent machine made of radios, microphones, tungsten bulbs, televisions, cameras, and surveillance equipment, makes his first appearance along with the Tabloid Junkies, his dance corps and guards. Lost and Alone – Stranger in Moscow This scene is the Spanish web lament to loneliness of the Beggar Boy, a character in the song “Stranger in Moscow”, while Ngame, the Mother Moon character, watches over. -
2:18-Cv-18-4761
Case 2:18-cv-04761 Document 1 Filed 05/30/18 Page 1 of 18 Page ID #:1 1 KINSELLA WEITZMAN ISER KUMP & ALDISERT LLP Howard Weitzman (SBN 38723) 2 [email protected] Jonathan P. Steinsapir (SBN 226281) 3 [email protected] 808 Wilshire Boulevard, 3rd Floor 4 Santa Monica, California 90401 Telephone: 310.566.9800 5 Facsimile: 310.566.9850 6 Attorneys for Plaintiffs MJJ Productions, Inc., Optimum Productions, Inc., New 7 Horizons Trust III, LLC (d/b/a MIJAC Music), The Michael Jackson Company, 8 LLC, and MJJ Ventures, Inc. LLP 9 UNITED STATES DISTRICT COURT 10 CENTRAL DISTRICT OF CALIFORNIA LDISERT 11 A WESTERN DIVISION LOOR F & 90401 12 RD 3 , 310.566.9850 UMP UMP 13 AX AX K MJJ PRODUCTIONS, INC., a Case No. F ALIFORNIA • 14 California corporation, OPTIMUM C , OULEVARD SER PRODUCTIONS, INC., a California COMPLAINT FOR COPYRIGHT B I 15 corporation, NEW HORIZONS TRUST INFRINGEMENT ONICA III, LLC, a Delaware limited liability M ILSHIRE 16 company, d/b/a MIJAC MUSIC, THE DEMAND FOR JURY TRIAL W MICHAEL JACKSON COMPANY, ANTA EITZMAN EITZMAN 310.566.9800 S 17 LLC, a Delaware limited liability 808 W EL company, and MJJ VENTURES, INC., T 18 a California corporation, 19 Plaintiffs, INSELLA INSELLA K 20 vs. Deadline 21 THE WALT DISNEY COMPANY, a Delaware corporation, ABC, INC., a 22 Delaware corporation, and DOES 1 through 10, inclusive. 23 Defendants. 24 25 26 27 28 COMPLAINT FOR COPYRIGHT INFRINGEMENT Case 2:18-cv-04761 Document 1 Filed 05/30/18 Page 2 of 18 Page ID #:2 1 JURISDICTION AND VENUE 2 1. -
The Non-Verbal Vocalisations of Michael Jackson
Saying the Unsayable: The Non-verbal Vocalisations of Michael Jackson Melissa Campbell Lift your head up high And scream out to the world I know I am someone And let the truth unfurl 1 In Performing Rites, Simon Frith asks: ‘What is the relationship between the voice as a carrier of sounds, the singing voice, making “gestures”, and the voice as a carrier of words, the speaking voice, making “utterances”?’2 The voice is more than just another musical instrument, Frith writes, not just because it is capable of language, but because it is produced by the body itself, so it represents the physical presence of the singer in a way other instruments do only indirectly.3 This physicality ties the singer’s performance tightly to his or her persona. Frith argues that: a pop star is like a film star, taking on many parts but retaining an essential ‘personality’ that is common to all of them and is the basis of their popular appeal. For the pop star the “real me” is a promise that lies in the way we hear the voice.4 In that case, it is difficult ever to hear the ‘real Michael Jackson.’ His pop music is thematically orthodox, composed chiefly of macho dance numbers, romantic love songs and sappy ballads. Yet his public persona is much more ambiguous and disturbing. Is he an habitual child abuser, or a boy who never grew up? A surgically created Caucasian, or proud African-American? A loving family man, or an asexual deviant who created his kids in test-tubes and dangled his younger son from a hotel balcony? A persecuted tabloid victim, or a canny businessman who never misses an opportunity for self-promotion? 1 Michael Jackson, ‘Wannabe Startin’ Somethin’.’ 2 Simon Frith, Performing Rites: On the Value of Popular Music (Cambridge, MA: Harvard UP, 1996) 186.