Exploratory Study of Slack Q&A Chats As a Mining Source For
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
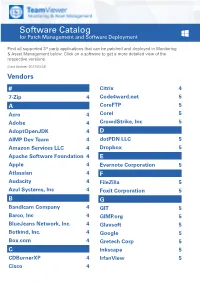
Software Catalog for Patch Management and Software Deployment
Software Catalog for Patch Management and Software Deployment Find all supported 3rd party applications that can be patched and deployed in Monitoring & Asset Management below. Click on a software to get a more detailed view of the respective versions. (Last Update: 2021/03/23) Vendors # Citrix 4 7-Zip 4 Code4ward.net 5 A CoreFTP 5 Acro 4 Corel 5 Adobe 4 CrowdStrike, Inc 5 AdoptOpenJDK 4 D AIMP Dev Team 4 dotPDN LLC 5 Amazon Services LLC 4 Dropbox 5 Apache Software Foundation 4 E Apple 4 Evernote Corporation 5 Atlassian 4 F Audacity 4 FileZilla 5 Azul Systems, Inc 4 Foxit Corporation 5 B G Bandicam Company 4 GIT 5 Barco, Inc 4 GIMP.org 5 BlueJeans Network, Inc. 4 Glavsoft 5 Botkind, Inc. 4 Google 5 Box.com 4 Gretech Corp 5 C Inkscape 5 CDBurnerXP 4 IrfanView 5 Cisco 4 Software Catalog for Patch Management and Software Deployment J P Jabra 5 PeaZip 10 JAM Software 5 Pidgin 10 Juraj Simlovic 5 Piriform 11 K Plantronics, Inc. 11 KeePass 5 Plex, Inc 11 L Prezi Inc 11 LibreOffice 5 Programmer‘s Notepad 11 Lightning UK 5 PSPad 11 LogMeIn, Inc. 5 Q M QSR International 11 Malwarebytes Corporation 5 Quest Software, Inc 11 Microsoft 6 R MIT 10 R Foundation 11 Morphisec 10 RarLab 11 Mozilla Foundation 10 Real 11 N RealVNC 11 Neevia Technology 10 RingCentral, Inc. 11 NextCloud GmbH 10 S Nitro Software, Inc. 10 Scooter Software, Inc 11 Nmap Project 10 Siber Systems 11 Node.js Foundation 10 Simon Tatham 11 Notepad++ 10 Skype Technologies S.A. -

CCIA Comments in ITU CWG-Internet OTT Open Consultation.Pdf
CCIA Response to the Open Consultation of the ITU Council Working Group on International Internet-related Public Policy Issues (CWG-Internet) on the “Public Policy considerations for OTTs” Summary. The Computer & Communications Industry Association welcomes this opportunity to present the views of the tech sector to the ITU’s Open Consultation of the CWG-Internet on the “Public Policy considerations for OTTs”.1 CCIA acknowledges the ITU’s expertise in the areas of international, technical standards development and spectrum coordination and its ambition to help improve access to ICTs to underserved communities worldwide. We remain supporters of the ITU’s important work within its current mandate and remit; however, we strongly oppose expanding the ITU’s work program to include Internet and content-related issues and Internet-enabled applications that are well beyond its mandate and core competencies. Furthermore, such an expansion would regrettably divert the ITU’s resources away from its globally-recognized core competencies. The Internet is an unparalleled engine of economic growth enabling commerce, social development and freedom of expression. Recent research notes the vast economic and societal benefits from Rich Interaction Applications (RIAs), a term that refers to applications that facilitate “rich interaction” such as photo/video sharing, money transferring, in-app gaming, location sharing, translation, and chat among individuals, groups and enterprises.2 Global GDP has increased US$5.6 trillion for every ten percent increase in the usage of RIAs across 164 countries over 16 years (2000 to 2015).3 However, these economic and societal benefits are at risk if RIAs are subjected to sweeping regulations. -
Download Windows Live Messenger for Linux Ubuntu
Download windows live messenger for linux ubuntu But installing applications in Ubuntu that were originally made for I found emescene to be the best Msn Messenger for Ubuntu Linux so far. It really gives you the feel as if you are using Windows Live Messenger. Its builds are available for Archlinux, Debian, Ubuntu, Fedora, Mandriva and Windows. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger and Google Talk. While finding MSN Messenger for Linux / Ubuntu, I found different emesene is also available and could be downloaded and installed for. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger. A simple & beautiful app for Facebook Messenger. OS X, Windows & Linux By downloading Messenger for Desktop, you acknowledge that it is not an. An alternative MSN Messenger chat client for Linux. It allows Linux users to chat with friends who use MSN Messenger in Windows or Mac OS. The strength of. Windows Live Messenger is an instant messenger application that For more information on installing applications, see InstallingSoftware. sudo apt-get install chromium-browser. 2. After the installation is Windows Live Messenger running in LinuxMint / Ubuntu. You can close the. Linux / X LAN Messenger for Debian/Ubuntu LAN Messenger for Fedora/openSUSE Download LAN Messenger for Windows. Windows installer A MSN Messenger / Live Messenger client for Linux, aiming at integration with the KDE desktop Ubuntu: Ubuntu has KMess in its default repositories. -

Download Resume
Oji Udezue http://www.linkedin.com/in/ojiudezue . +1 425-829-9520 SUMMARY: EXPERIENCED PRODUCT, DESIGN & TECHNOLOGY EXECUTIVE I’m a product-led growth expert. A multi-disciplinary tech exec with strong product, design and engineering leadership skills. I have had stints in marketing and sales which provide a well - rounded experience of key business functions. In addition, I have startup experience and a track record advising several great startups. I have a talent for new product strategy and the practical leadership to innovate and execute with conviction. I am passionate about early stage product development and entrepreneurship in organizations. My strongest skill sets are product vision, lean product management; strategy & planning, people management and talent development. Professional Experience CALENDLY VP of Product (2018 – Present) Lead Technology, Product, Design and Content Strategy • Under my tenure, Calendly is sustaining 100% year on year growth in ARR and MAU • Drive key engineering investments and a high-performance engineering culture • Set product vision, mission and goals for business • Drive ongoing, high velocity innovation • Manage overall user experience and delivery of value to customers • Manage team health, product craft excellence and talent acquisition • Drive clear and actionable business metrics and management of business to those metrics • Drive acquisition strategy; review and approve potential acquisition deals • Manage growth program and virality initiatives to increase audience share ATLASSIAN Head -

Hipchat Data Center
HipChat Data Center *Announcement* HipChat has reached end of life with Cloud, Data Center and Server being discontinued from 15th February 2019. Although Atlassian are ceasing their team communication products, if you have an existing Hipchat Server or Hipchat Data Center license, you can continue to use Hipchat until the end of life date for your particular version: • Hipchat Data Center (v3.0): June 22nd, 2019 • Hipchat Data Center (v3.1): September 26th, 2019 • Hipchat Server (v2.1): December 8th, 2018 • Hipchat Server (v2.2): May 30th, 2019 • Hipchat Server (v2.4): June 30th, 2020 Still have questions on what that means for you? Learn more about Atlassian’s new partnership with Slack or get in touch for additional information today. Atlassian’s HipChat Data Center is an on-premise corporate instant messaging (chat) application. It allows members of your organisation to enjoy secure, spontaneous communications without worrying about loss of data or conversation history. As with all Atlassian Data Center applications, HipChat features enterprise grade scalability and high availability. It is a flexible, customisable chat solution that limits unnecessary email and phone traffic, eases record-keeping, works across all common operating systems, browsers, and mobile platforms, and maintains a fully searchable record of any relevant technical and commercial information. HipChat makes it easy to involve colleagues in conversations and set up chat rooms, and it integrates seamlessly with Jira and the other applications within Atlassian’s software suite. As with all Atlassian Data Center products, HipChat Data Center can be deployed on multiple application servers (active-active clustering), which brings greater scalability and resilience. -
Moving Your Team from Hipchat to Slack: Part One
Moving Your Team from HipChat to Slack: Part One In late July 2018, Atlassian announced it would be entering a “strategic partnership” with Slack. HipChat will shut down for good on February 15, 2019, which means that businesses using the service must be fully transitioned to Slack (or another collaboration platform) before that date. This news came as quite a shock to HipChat users, given Atlassian’s stated commitment to carving out its own corner of the busy real-time team communications market (the company released Stride, a new workplace communications product, just a few months ago). But Atlassian’s sudden and dramatic about-face was an inevitable reaction to the pressures of its chosen marketplace. Image: Slack’s Twitter announcement [email protected] 1 www.teampay.co Why Slack won Unlike Atlassian, Slack has been gaining market share at a remarkable rate: the company boasted in May that it had reached over eight million daily users and that 65% of the Fortune 100 companies were now paid Slack subscribers. Source: Slack Slack’s impressively broad integration options are a core component of its success; users of InVision, Trello, GitHub, Salesforce and many other popular SaaS platforms can install plug-and-play apps to link these platforms with Slack. That makes it a much “stickier” team collaboration option than, say, HipChat (which has a far smaller pool of available integrations) and greatly reduces customer churn. Whatever commercial software products and platforms you work with, there’s likely to be an app for that in Slack’s App Directory. Even direct competitors Google and Microsoft have worked with Slack to develop integration apps for their products. -

Chatops: Automate IT Operations Using Chatbots
International Conference On Emanations in Modern Technology and Engineering (ICEMTE-2017) ISSN: 2321-8169 Volume: 5 Issue: 3 360 - 362 ____________________________________________________________________________________________________________________ ChatOps: Automate IT operations using Chatbots Prof.AartiPuthran Mr.RiteshPuthran Assistant Professor Project Lead Shree L. R. Tiwari College of Engineering, Mira road. L&T Infotech [email protected] [email protected] ABSTRACT: In this era of smartphones and tablets, Chat apps are gaining significant acceptance in the consumer facing market as one of the most used medium of communication across all age groups. With Messenger app companies like Whatsapp and Snapchat being values upwards of Billions of dollars in valuations, there is also an increase in use of enterprise chat messengers as a medium for communication between teams in an organization. Enterprise chat messengers like Slack, HipChat have significantly changed the way traditional enterprise messenger are used. With it being a very open platform allowing to be extended to the fullest extent. There are developers developing cool integrations with can be used to enhance team's productivity and to automate stuff using Chat bots. Chat bots can be used to automate mundane activities of the IT operations team hence achieving productivity boost and transparency across teams involved. Use of chat bots to automate IT operations is popularly known as ChatOps.This paper’s intent is to evaluate ChatOps using open source software’s and to review the benefits of using it from an IT team's perspective. KEYWORDS: ChatOps, chat bots, it automation, automation, messenger, chat __________________________________________________*****_________________________________________________ I. EVOLUTION OF THE INSTANT Then in the year 2009 Whatsapp was launched and it MESSENGER. -

Software Bots
Editor: Christof Ebert SOFTWARE Vector Consulting Services TECHNOLOGY [email protected] Software Bots Carlene Lebeuf, Margaret-Anne Storey, and Alexey Zagalsky From the Editor Bots have become a common user interface for software services. Many people prefer bots to real persons owing to bots’ perceivable passionate “personality.” The Turing test obviously has been passed. However, bots’ involvement in social net- works and fake emails in elections exposed major risks. A lot still must be done, in- cluding some indication that “you’re now talking with a bot.” Here, Carlene Lebeuf, Margaret-Anne Storey, and Alexey Zagalsky discuss current bot technology and present a practical case study on how to use bots in software engineering. I look forward to hearing from both readers and prospective authors about advances in software technologies. —Christof Ebert FROM COMPUTER PROGRAMS’ intended to fool users into believing Bots and Software earliest days, people have dreamed they’re interacting with a real person, Development about programs that act, talk, and but many bots do have a pleasant, en- Bots are rapidly becoming a de facto think like humans. Such programs gaging personality. interface for interacting with soft- could not only automate tasks that Bots typically reside on platforms ware services. This is due partly to humans perform but also work with on which users work or play with the widespread adoption of messag- humans to solve intellectual tasks other users. They also frequently ing platforms (for example, Facebook that can’t be entirely automated. integrate secondary services into Messenger for social networking Even as far back as 1966, the hope communication channels, providing and Slack for developer communi- was for these programs to pass the a conduit between users and other cation), and partly to the advance- Turing test,1 in which humans are tools. -

Customizations and Expression Breakdowns in Ecosystems of Communication Apps Carla Griggio, Joanna Mcgrenere, Wendy Mackay
Customizations and Expression Breakdowns in Ecosystems of Communication Apps Carla Griggio, Joanna Mcgrenere, Wendy Mackay To cite this version: Carla Griggio, Joanna Mcgrenere, Wendy Mackay. Customizations and Expression Breakdowns in Ecosystems of Communication Apps. Proceedings of the ACM on Human-Computer Interaction , Association for Computing Machinery (ACM), 2019, 3 (CSCW), pp.26. 10.1145/3359128. hal- 02295535 HAL Id: hal-02295535 https://hal.archives-ouvertes.fr/hal-02295535 Submitted on 24 Sep 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Customizations and Expression Breakdowns in Ecosystems of Communication Apps CARLA F. GRIGGIO, LRI, Univ. Paris-Sud, CNRS, Inria, Université Paris-Saclay, France and The University 26 of Tokyo, Japan JOANNA MCGRENERE, Dept of Computer Science University of British Columbia, Canada and LRI, Univ. Paris-Sud, CNRS, Inria, Université Paris-Saclay, France WENDY E. MACKAY, LRI, Univ. Paris-Sud, CNRS, Inria, Université Paris-Saclay, France The growing adoption of emojis, stickers and GIFs suggests a corresponding demand for rich, personalized expression in messaging apps. Some people customize apps to enable more personal forms of expression, yet we know little about how such customizations shape everyday communication. -

A Perfectly Good Hour
A PERFECTLY GOOD HOUR 1. Social Capital 2. Social Intelligence 3. Listening 4. Identity 5. Language & Cursing 6. Nonverbal Communication 7. Satisfying Relationships 8. Consummate Love 9. Conflict Management 10. Styles of Parenting/Leading Modern Social Commentary Cartoons by David Hawker from PUNCH Magazine, 1981 A PERFECTLY GOOD HOUR Feel free to voice your opinion and to disagree. This is not a friction- free zone. AND, please do demonstrate social intelligence. Let’s Get Better Acquainted If you match this descriptor, keep your 1. You belong to an LLI Special Interest Group video on and unmute. 2. You are fluent in another language 3. You’ve received your flu shot If you don’t match this 4. You attended the LLI class on nanotechnology descriptor, temporarily 5. You have grandchildren stop your video. 6. You (have) participate(d) in Great Decisions 7. You have a pet 8. You play a musical instrument 9. You are/have been on the LLI Board 10. You think this is a fun poll How fortunate we are that during this global pandemic, we can stay home, attending LLI classes, reading, creating, baking, taking walks, and talking with our loved one. The last six months have exposed and magnified long standing inequities -- in our communities, in our hospitals, in our workplaces, and in schools. Too many of our school districts lack a fair share of resources to address the pandemic’s challenges; not every student can be taught remotely with attention to their need for social and emotional safe learning spaces. The current circumstances are poised to exacerbate existing disparities in academic opportunity and performance, particularly between white communities and communities of color. -

Patch Management Vendor and Application List
Patch Management Vendor and Application List Vendor Application 7-Zip 7-Zip 7-Zip 3 7-Zip 7-Zip 4 7-Zip 7-Zip 9 7-Zip 7-Zip 15 7-Zip 7-Zip 16 7-Zip 7-Zip 18 Acro Software Acro Software CutePDF Writer 2 Acro Software CutePDF Writer 3 Adobe Adobe Acrobat 5 Adobe Acrobat 6 Adobe Acrobat 7 Adobe Acrobat 8 Adobe Acrobat 9 Adobe Acrobat X Adobe Acrobat XI Adobe Acrobat DC Adobe Acrobat DC 17 Adobe Acrobat DC 18 Adobe Acrobat DC 19 Adobe Adobe Photoshop 11 Adobe Adobe Photoshop 12 Adobe Adobe Photoshop 13 Adobe Adobe Photoshop 15 Adobe Adobe Photoshop 16 Adobe After Effects 13.5 Adobe AIR Adobe AIR 2 Adobe AIR 3 Adobe AIR 4 Adobe AIR 13 Adobe AIR 14 Adobe AIR 15 Adobe AIR 16 Adobe AIR 17 Adobe AIR 18 Adobe AIR 19 Adobe AIR 20 Adobe AIR 21 Adobe AIR 22 Adobe AIR 23 Adobe AIR 24 Adobe AIR 25 Adobe AIR 26 Adobe AIR 27 Adobe AIR 28 Adobe AIR 30 Adobe AIR 31 Adobe AIR 32 Adobe Bridge 4 Adobe Bridge 5 Adobe Bridge CC Adobe Creative Cloud 3 Adobe Creative Cloud 4 Adobe Digital Editions 1 Adobe Digital Editions 2 Adobe Digital Editions 3 Adobe Digital Editions 4 Adobe Distiller 5 Adobe Distiller 6 Adobe Distiller 7 Adobe Dreamweaver 16 Adobe Elements 5 Adobe Elements 6 Adobe Elements 7 Adobe Fireworks CS6 Adobe Flash PPAPI MSI Adobe Flash Plugin MSI Adobe Flash MSI Adobe Flash Plugin Adobe Flash 5 Adobe Flash 6 Adobe Flash Plugin 6 Adobe Flash 7 Adobe Flash Plugin 7 Adobe Flash 8 Adobe Flash Plugin 8 Adobe Flash 9 Adobe Flash Plugin 9 Adobe Flash 10 Adobe Flash Plugin 10 Adobe Flash 11 Adobe Flash Plugin 11 Adobe Flash 12 Adobe Flash Plugin 12 Adobe -
How to Build Your Own Chat Bot in Slack
How to Build Your + Own Chat Bot in Slack What Is a Bot? Bots are tiny programs that live in your apps and respond to your commands to look up facts, send notifications, and more automatically for you. For example, type a command like ‘/giphy volcano’ to instruct the bot to find what you're looking for (a volcano gif from Giphy, in this case). Bots are the big new thing in chat tools such as Facebook Messenger, Slack, and Skype, as well as in personal voice assistants, such as Amazon Alexa. What Do You Need to Build a Bot? You only need 3 things to build a bot: + + ICON A PLACE TO A BOT TO READ AN APP TO DO SOMETHING TYPE YOUR TEXT YOUR TEXT WITH YOUR TEXT Chat apps, like Slack, are the perfect place for bots. They include both a text box to type commands into and a conversation view to see what the bot replies. Pre-built integrations from Zapier help you connect your apps and pass data between them. Using Zaps, or integrations inside Zapier, you can connect Slack to hundreds of other apps just by clicking through a simple wizard. What Types of Bots Can I Build? Slackbot Replies The simplest bots come built into TIP your Slack settings. You add a phrase for the Slackbot to watch for, and then tell it how to respond. To make a Slackbot Reply, go to slack.com/customize/slackbot and For example, tell Slackbot to watch add the phrase and response you for messages that say ‘office security want.