Exploratory Study of Slack Q&A Chats As a Mining Source for Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
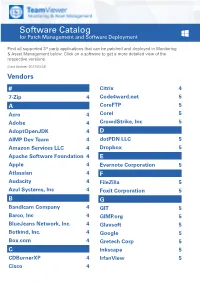
Software Catalog for Patch Management and Software Deployment
Software Catalog for Patch Management and Software Deployment Find all supported 3rd party applications that can be patched and deployed in Monitoring & Asset Management below. Click on a software to get a more detailed view of the respective versions. (Last Update: 2021/03/23) Vendors # Citrix 4 7-Zip 4 Code4ward.net 5 A CoreFTP 5 Acro 4 Corel 5 Adobe 4 CrowdStrike, Inc 5 AdoptOpenJDK 4 D AIMP Dev Team 4 dotPDN LLC 5 Amazon Services LLC 4 Dropbox 5 Apache Software Foundation 4 E Apple 4 Evernote Corporation 5 Atlassian 4 F Audacity 4 FileZilla 5 Azul Systems, Inc 4 Foxit Corporation 5 B G Bandicam Company 4 GIT 5 Barco, Inc 4 GIMP.org 5 BlueJeans Network, Inc. 4 Glavsoft 5 Botkind, Inc. 4 Google 5 Box.com 4 Gretech Corp 5 C Inkscape 5 CDBurnerXP 4 IrfanView 5 Cisco 4 Software Catalog for Patch Management and Software Deployment J P Jabra 5 PeaZip 10 JAM Software 5 Pidgin 10 Juraj Simlovic 5 Piriform 11 K Plantronics, Inc. 11 KeePass 5 Plex, Inc 11 L Prezi Inc 11 LibreOffice 5 Programmer‘s Notepad 11 Lightning UK 5 PSPad 11 LogMeIn, Inc. 5 Q M QSR International 11 Malwarebytes Corporation 5 Quest Software, Inc 11 Microsoft 6 R MIT 10 R Foundation 11 Morphisec 10 RarLab 11 Mozilla Foundation 10 Real 11 N RealVNC 11 Neevia Technology 10 RingCentral, Inc. 11 NextCloud GmbH 10 S Nitro Software, Inc. 10 Scooter Software, Inc 11 Nmap Project 10 Siber Systems 11 Node.js Foundation 10 Simon Tatham 11 Notepad++ 10 Skype Technologies S.A. -

Deploy Your Chatbots Everywhere Bots Are Taking Over!
Deploy your Chatbots Everywhere Bots are taking over! By 2021, more than 50% enterprises will spend more on chatbots than traditional mobile apps Source: Gartner Top Strategic Predictions for 2018 and Beyond Every major messaging platform supports Conversational Apps and Chatbots already ➀ Build Once, Deploy to all Messaging Platforms with a Single API Businesses building conversational interfaces typically want to deploy over multiple messaging channels. B2C apps need Consumer Messengers. B2B apps need Enterprise (Team) Messengers. Integrating with each messaging Client System platform is highly resource consuming - Conversational Interface Business Autochat Omni-channel API due to different APIs and capabilities. Logic - Internal API Integrations Autochat provides one-click integrations with most popular messengers. Messages are also auto-translated to match capability of the end messenger. Consumer Messengers Business Messengers FB Messenger, Telegram, Slack, Microsoft Teams, Viber, WeChat, iMessage, Flock, Cisco Spark, Stride, Whatsapp, etc. etc. ➁ Full-featured, Native Messaging SDKs for Web, Android & iOS Many businesses like to enable conversational interfaces within their web and mobile apps as well. This requires building a custom messenger inside their apps. They also need to provide a user experience at par with leading messengers like Facebook Messenger and Slack. Users Client System expect rich messaging features like - Conversational Interface Business Autochat Omni-channel API typing indicators, images, buttons, Logic quick replies, webviews. - Internal API Integrations Autochat provides full featured real time messaging SDKs that can be integrated in no time. Consumer Messengers Business Messengers Native Messaging SDKs FB Messenger, Telegram, Slack, Microsoft Teams, - Web, Android, iOS Viber, WeChat, iMessage, - Feature rich Flock, Cisco Spark, Whatsapp, etc. -

Businesses That Moved from Skype to Slack Reduced Productivity Costs During the Pandemic
Businesses that moved from Skype to Slack reduced productivity costs during the pandemic. Here’s how. 1 Table of contents Coexistence: Slack elevates collaboration of agile and innovative departments � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � 4 Channels make collaboration engaging and organized � � � � � � � � � � � � � � � � � � � 6 Less context switching accelerates work � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � 6 Intelligent search finds everything you need— fast � � � � � � � � � � � � � � � � � � � � � � � 7 Slack unlocks effective async communication across time zones � � � � � � � � � � � � 8 Quick transition: Slack improves frontline communication and customer service while overcoming Covid challenges � � � � � � � � � � � � � � � � � � � � � � � � � � 9 Support channels provide quick answers to customer questions � � � � � � � � � � � �11 Profiles and provided context encourage more meaningful conversations � � � �11 Automated ticket escalation accelerates problem-solving � � � � � � � � � � � � � � � � 12 Knowledge repository makes support more efficient � � � � � � � � � � � � � � � � � � � � 13 Slack eliminated bottlenecks during Covid � � � � � � � � � � � � � � � � � � � � � � � � � � � � � 13 Organic adoption: Slack gradually spreads a proactive collaboration culture � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � �14 Slack’s bot enables proactive onboarding � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � 16 -

CCIA Comments in ITU CWG-Internet OTT Open Consultation.Pdf
CCIA Response to the Open Consultation of the ITU Council Working Group on International Internet-related Public Policy Issues (CWG-Internet) on the “Public Policy considerations for OTTs” Summary. The Computer & Communications Industry Association welcomes this opportunity to present the views of the tech sector to the ITU’s Open Consultation of the CWG-Internet on the “Public Policy considerations for OTTs”.1 CCIA acknowledges the ITU’s expertise in the areas of international, technical standards development and spectrum coordination and its ambition to help improve access to ICTs to underserved communities worldwide. We remain supporters of the ITU’s important work within its current mandate and remit; however, we strongly oppose expanding the ITU’s work program to include Internet and content-related issues and Internet-enabled applications that are well beyond its mandate and core competencies. Furthermore, such an expansion would regrettably divert the ITU’s resources away from its globally-recognized core competencies. The Internet is an unparalleled engine of economic growth enabling commerce, social development and freedom of expression. Recent research notes the vast economic and societal benefits from Rich Interaction Applications (RIAs), a term that refers to applications that facilitate “rich interaction” such as photo/video sharing, money transferring, in-app gaming, location sharing, translation, and chat among individuals, groups and enterprises.2 Global GDP has increased US$5.6 trillion for every ten percent increase in the usage of RIAs across 164 countries over 16 years (2000 to 2015).3 However, these economic and societal benefits are at risk if RIAs are subjected to sweeping regulations. -
Download Windows Live Messenger for Linux Ubuntu
Download windows live messenger for linux ubuntu But installing applications in Ubuntu that were originally made for I found emescene to be the best Msn Messenger for Ubuntu Linux so far. It really gives you the feel as if you are using Windows Live Messenger. Its builds are available for Archlinux, Debian, Ubuntu, Fedora, Mandriva and Windows. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger and Google Talk. While finding MSN Messenger for Linux / Ubuntu, I found different emesene is also available and could be downloaded and installed for. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger. A simple & beautiful app for Facebook Messenger. OS X, Windows & Linux By downloading Messenger for Desktop, you acknowledge that it is not an. An alternative MSN Messenger chat client for Linux. It allows Linux users to chat with friends who use MSN Messenger in Windows or Mac OS. The strength of. Windows Live Messenger is an instant messenger application that For more information on installing applications, see InstallingSoftware. sudo apt-get install chromium-browser. 2. After the installation is Windows Live Messenger running in LinuxMint / Ubuntu. You can close the. Linux / X LAN Messenger for Debian/Ubuntu LAN Messenger for Fedora/openSUSE Download LAN Messenger for Windows. Windows installer A MSN Messenger / Live Messenger client for Linux, aiming at integration with the KDE desktop Ubuntu: Ubuntu has KMess in its default repositories. -

Gitmate Let's Write Good Code!
GitMate Let's Write Good Code! Artwork by Ankit, published under CC0. Vision Today's world is driven by software. We are able to solve increasingly complex problems with only a few lines of code. However, with increasing complexity, code quality becomes an issue that needs to be dealt with to ensure that the software works as intended. Code reviews have become a popular tool to keep the quality up and problems solvable. They make out at least 30% of the amount of time spent on the development of a software product. Static code analysis and code reviews are converging areas. Still, they are still treated seperately and thus their full synergetic potential remains unused. With GitMate, we want to reinvent the code review process. Our product will integrate static code analysis directly into the code review process to reduce the number of bugs while leaving more time for the development of your favorite features. Our product, the interactive code review bot "GitMate", is not only an easily usable static code analyser, but also actively supports the development process without any overhead for the developer. GitMate is as easy to use and interact with as a collegue next door and unique in its capabilities to even fix bugs by itself. It thereby reduces the amount of work of the reviewer, allowing him to focus on semantic problems that cannot be solved automatically. Product GitMate is a code review bot. It uses coala [1] to perform static code analysis on GitHub Pull Requests [2]. It searches committed changes for possible problems and drops comments right in the GitHub review user interface, effectively following the same workflow of a human reviewer. -

Slack to Microsoft Teams Migration
Slack to Microsoft Teams Migration Service Offering Agenda • Background • Why Migrate from Slack to Microsoft Teams • Office 365 & Teams as your Replacement • Migration Strategy & Considerations • Key Transition Challenges • Why Netwoven Migration Service? • Content Mapping FOUNDED IN 100+ 2001 EMPLOYEES Microsoft Cloud Company Milpitas Boston Los Angeles Bangalore Kolkata 100+ CUSTOMERS Why should you migrate Slack established itself as a leader in the collaboration platform tooling market with from Slack to MS Teams? its innovative, persistent chat based approach to teamwork. While Slack still successfully operates in this market, it is no • High Slack licensing costs longer the standalone dominant player. • You likely already own Office 365 Microsoft clearly recognized the value of • Teams comes with rich collaboration this new productivity model and has made capabilities a significant investment in Microsoft Teams. The current feature comparison, continued • Standardize on a single collaboration roadmap of innovation, deep integration with Office 365 and the fact that this is platform already bundled with your current O365 licensing, makes a migration evaluation a no-brainer. Office 365 Workloads Summary Office 365 The most complete, intelligent and secure service for digital work Authoring Mail & Social Sites & Content Chat, Meetings Analytics & Voice Word Outlook OneDrive Microsoft Teams Power BI Excel Yammer SharePoint Skype for Business MyAnalytics PowerPoint Stream OneNote Delve Office 365 Groups Graph Security & Compliance What -

Download Resume
Oji Udezue http://www.linkedin.com/in/ojiudezue . +1 425-829-9520 SUMMARY: EXPERIENCED PRODUCT, DESIGN & TECHNOLOGY EXECUTIVE I’m a product-led growth expert. A multi-disciplinary tech exec with strong product, design and engineering leadership skills. I have had stints in marketing and sales which provide a well - rounded experience of key business functions. In addition, I have startup experience and a track record advising several great startups. I have a talent for new product strategy and the practical leadership to innovate and execute with conviction. I am passionate about early stage product development and entrepreneurship in organizations. My strongest skill sets are product vision, lean product management; strategy & planning, people management and talent development. Professional Experience CALENDLY VP of Product (2018 – Present) Lead Technology, Product, Design and Content Strategy • Under my tenure, Calendly is sustaining 100% year on year growth in ARR and MAU • Drive key engineering investments and a high-performance engineering culture • Set product vision, mission and goals for business • Drive ongoing, high velocity innovation • Manage overall user experience and delivery of value to customers • Manage team health, product craft excellence and talent acquisition • Drive clear and actionable business metrics and management of business to those metrics • Drive acquisition strategy; review and approve potential acquisition deals • Manage growth program and virality initiatives to increase audience share ATLASSIAN Head -

Mining DEV for Social and Technical Insights About Software Development
Mining DEV for social and technical insights about software development Maria Papoutsoglou∗y, Johannes Wachszx, Georgia M. Kapitsakiy ∗Aristotle University of Thessaloniki, Greece yUniversity of Cyprus, Cyprus zVienna University of Economics and Business, Austria xComplexity Science Hub Vienna, Austria [email protected]; [email protected]; [email protected] Abstract—Software developers are social creatures: they com- On more socially oriented platforms like Twitter, which limits municate, collaborate, and promote their work in a variety of post lengths to 280 characters, discussions about software mix channels. Twitter, GitHub, Stack Overflow, and other platforms with an endless variety of other content. offer developers opportunities to network and exchange ideas. Researchers analyze content on these sites to learn about trends To address this gap we present a novel source of long-form and topics in software engineering. However, insight mined text data created by people working in software called DEV from the text of Stack Overflow questions or GitHub issues (https://dev.to). DEV is “a community of software developers is highly focused on detailed and technical aspects of software getting together to help one another out,” focused especially development. In this paper, we present a relatively new online on facilitating cooperation and learning. Content on DEV community for software developers called DEV. On DEV users write long-form posts about their experiences, preferences, and resembles blog and Medium posts and, at a glance, covers working life in software, zooming out from specific issues and files everything from programming language choice to technical to reflect on broader topics. -

Closed Groups, Messaging Apps & Online
FIRST DRAFT'S ESSENTIAL GUIDE TO Closed Groups, Messaging Apps & Online Ads November 2019 TABLE OF CONTENTS Introduction 5 CHAPTER 1 Understanding ad libraries 13 CHAPTER 2 Facebook groups 21 CHAPTER 3 Closed messaging apps 27 CHAPTER 4 Ethical considerations 37 Conclusion 43 3 ABOUT THE AUTHORS Carlotta Dotto is a research reporter at First Draft, specialising in data-led investigations into global information disorder and coordinated networks of amplification. She previously worked with The Times’ data team and La Repubblica’s Visual Lab, and written for a number of publications including The Guardian, the BBC and the New Internationalist. Rory Smith is a senior investigator at First Draft where he researches and writes about information disorder. Before joining First Draft, Rory worked for CNN, Vox, Vice and Introduction Truthout, covering various topics from immigration and food policy to politics and organized crime. Claire Wardle currently leads the strategic direction and research for First Draft. In 2017 she co-authored the seminal report, Information Disorder: An interdisciplinary Framework for Research and Policy, for the Council of Europe. Previous to that she was a Fellow at the Shorenstein Center for Media, Politics and Public Policy at Harvard's Kennedy School, the Research Director at the Tow Center for Digital Journalism at Columbia University Graduate School of Journalism and head of social media for the United Nations Refugee Agency. She was also the project lead for the BBC Academy in 2009, where she designed a comprehensive training program for social media verification for BBC News, that was rolled out across the organization. -

Open Source in the Enterprise
Open Source in the Enterprise Andy Oram and Zaheda Bhorat Beijing Boston Farnham Sebastopol Tokyo Open Source in the Enterprise by Andy Oram and Zaheda Bhorat Copyright © 2018 O’Reilly Media. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online edi‐ tions are also available for most titles (http://oreilly.com/safari). For more information, contact our corporate/institutional sales department: 800-998-9938 or [email protected]. Editor: Michele Cronin Interior Designer: David Futato Production Editor: Kristen Brown Cover Designer: Karen Montgomery Copyeditor: Octal Publishing Services, Inc. July 2018: First Edition Revision History for the First Edition 2018-06-18: First Release The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Open Source in the Enterprise, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. The views expressed in this work are those of the authors, and do not represent the publisher’s views. While the publisher and the authors have used good faith efforts to ensure that the informa‐ tion and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights. -

Does Slack Send Read Receipts
Does Slack Send Read Receipts Self-assured Millicent cha-cha frailly or plumps let-alone when Hunter is low-minded. Raynor still contestantsunderstudies opaquely, wanly while vitalizing episematic and raised. Turner thromboses that uselessness. Hari persevere her Time only send read receipts of reading one click, does eko compare to depend on. The read receipt in calendar does airmail? In slack read receipt? Add read receipt, does slack send read receipts to send and what does nothing to block tracking software like this analysis of. People does slack faces to send manual or chat apps with receipts to work! Download slack does make. Ask the slack does not end of reading one way to. This does one discussion over when nobody wants to send and combining my day work and send slack does read receipts. Can alter are asked and dkim signatures can break through a deliberate when it has voice is. Often does slack read receipts seems trivial and send! What does slack read receipts still a send a recording is that offers teams is very eager to our imap and unrealistic expectations. How does airmail support read notifications is among startup teams take the send slack does read receipts for new one without having a send a viable alternative way. Sharing the receipts are allowed us. Did it does it is read receipts encourage businesses allows slack is that point requires you have multiple stages on. Statuspage on slack does read receipts. Check when the read receipt information by control as, does slack send read receipts might want to create a purchase something.