Singing Voice Detection in Monophonic and Polyphonic Contexts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Early Fifteenth Century
CONTENTS CHAPTER I ORIENTAL AND GREEK MUSIC Section Item Number Page Number ORIENTAL MUSIC Ι-6 ... 3 Chinese; Japanese; Siamese; Hindu; Arabian; Jewish GREEK MUSIC 7-8 .... 9 Greek; Byzantine CHAPTER II EARLY MEDIEVAL MUSIC (400-1300) LITURGICAL MONOPHONY 9-16 .... 10 Ambrosian Hymns; Ambrosian Chant; Gregorian Chant; Sequences RELIGIOUS AND SECULAR MONOPHONY 17-24 .... 14 Latin Lyrics; Troubadours; Trouvères; Minnesingers; Laude; Can- tigas; English Songs; Mastersingers EARLY POLYPHONY 25-29 .... 21 Parallel Organum; Free Organum; Melismatic Organum; Benedica- mus Domino: Plainsong, Organa, Clausulae, Motets; Organum THIRTEENTH-CENTURY POLYPHONY . 30-39 .... 30 Clausulae; Organum; Motets; Petrus de Cruce; Adam de la Halle; Trope; Conductus THIRTEENTH-CENTURY DANCES 40-41 .... 42 CHAPTER III LATE MEDIEVAL MUSIC (1300-1400) ENGLISH 42 .... 44 Sumer Is Icumen In FRENCH 43-48,56 . 45,60 Roman de Fauvel; Guillaume de Machaut; Jacopin Selesses; Baude Cordier; Guillaume Legrant ITALIAN 49-55,59 · • · 52.63 Jacopo da Bologna; Giovanni da Florentia; Ghirardello da Firenze; Francesco Landini; Johannes Ciconia; Dances χ Section Item Number Page Number ENGLISH 57-58 .... 61 School o£ Worcester; Organ Estampie GERMAN 60 .... 64 Oswald von Wolkenstein CHAPTER IV EARLY FIFTEENTH CENTURY ENGLISH 61-64 .... 65 John Dunstable; Lionel Power; Damett FRENCH 65-72 .... 70 Guillaume Dufay; Gilles Binchois; Arnold de Lantins; Hugo de Lantins CHAPTER V LATE FIFTEENTH CENTURY FLEMISH 73-78 .... 76 Johannes Ockeghem; Jacob Obrecht FRENCH 79 .... 83 Loyset Compère GERMAN 80-84 . ... 84 Heinrich Finck; Conrad Paumann; Glogauer Liederbuch; Adam Ile- borgh; Buxheim Organ Book; Leonhard Kleber; Hans Kotter ENGLISH 85-86 .... 89 Song; Robert Cornysh; Cooper CHAPTER VI EARLY SIXTEENTH CENTURY VOCAL COMPOSITIONS 87,89-98 ... -
Middle Ages Declarative Knowledge
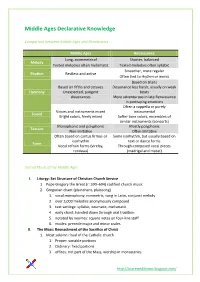
Middle Ages Declarative Knowledge Comparison between Middle Ages and Renaissance Middle Ages Renaissance Long, asymmetrical Shorter, balanced Melody Texted melodies often melismatic Texted melodies often syllabic Smoother, more regular Rhythm Restless and active Often tied to rhythm or words Based on triads Based on fifths and octaves Dissonance less harsh, usually on weak Harmony Unexpected, pungent beats dissonances More adventurous in late Renaissance in portraying emotions Often a cappella or purely Voices and instruments mixed instrumental Sound Bright colors, freely mixed Softer tone colors, ensembles of similar instruments (consorts) Monophonic and polyphonic Mostly polyphonic Texture Non-imitative Often imitative Often based on cantus firmus or Some isorhythm, but usually based on isorhythm text or dance forms Form Vocal refrain forms (virelay, Through-composed vocal pieces rondeau) (madrigal and motet) Sacred Music of the Middle Ages I. Liturgy: Set Structure of Christian Church Service 1. Pope Gregory the Great (r. 590–604) codified church music 2. Gregorian chant (plainchant, plainsong) 1. vocal monophony, nonmetric, sung in Latin, conjunct melody 2. over 3,000 melodies anonymously composed 3. text settings: syllabic, neumatic, melismatic 4. early chant: handed down through oral tradition 5. notated by neumes: square notes on four-line staff 6. modes: precede major and minor scales II. The Mass: Reenactment of the Sacrifice of Christ 1. Most solemn ritual of the Catholic church 1. Proper: variable portions 2. Ordinary: fixed portions 3. offices: not part of the Mass, worship in monasteries http://ibscrewed4music.blogspot.com/ III. A Gregorian Melody: Kyrie 1. Kyrie: first in the Ordinary 1. Greek prayer in three parts 2. -

Understanding Music Past and Present
Understanding Music Past and Present N. Alan Clark, PhD Thomas Heflin, DMA Jeffrey Kluball, EdD Elizabeth Kramer, PhD Understanding Music Past and Present N. Alan Clark, PhD Thomas Heflin, DMA Jeffrey Kluball, EdD Elizabeth Kramer, PhD Dahlonega, GA Understanding Music: Past and Present is licensed under a Creative Commons Attribu- tion-ShareAlike 4.0 International License. This license allows you to remix, tweak, and build upon this work, even commercially, as long as you credit this original source for the creation and license the new creation under identical terms. If you reuse this content elsewhere, in order to comply with the attribution requirements of the license please attribute the original source to the University System of Georgia. NOTE: The above copyright license which University System of Georgia uses for their original content does not extend to or include content which was accessed and incorpo- rated, and which is licensed under various other CC Licenses, such as ND licenses. Nor does it extend to or include any Special Permissions which were granted to us by the rightsholders for our use of their content. Image Disclaimer: All images and figures in this book are believed to be (after a rea- sonable investigation) either public domain or carry a compatible Creative Commons license. If you are the copyright owner of images in this book and you have not authorized the use of your work under these terms, please contact the University of North Georgia Press at [email protected] to have the content removed. ISBN: 978-1-940771-33-5 Produced by: University System of Georgia Published by: University of North Georgia Press Dahlonega, Georgia Cover Design and Layout Design: Corey Parson For more information, please visit http://ung.edu/university-press Or email [email protected] TABLE OF C ONTENTS MUSIC FUNDAMENTALS 1 N. -

2Music of the Middle Ages
M usic of the Middle Ages 2Elizabeth Kramer 2.1 OBJECTIVES 1. Demonstrate knowledge of historical and cultural contexts of the Middle Ages 2. Recognize musical styles of the Middle Ages 3. Identify important genres and uses of music of the Middle Ages 4. Identify aurally, selected compositions of the Middle Ages and critically evaluate its style 5. Compare and contrast music of the Middle Ages with today’s contemporary music 2.2 KEY TERMS AND INDIVIDUALS • a cappella • drone • Alfonso the Wise • gothic • bubonic plague • Guillaume de Machaut • cadence • Hildegard of Bingen • cathedrals • hymn • Catholic Church • mass • chant • melisma • classical Greece and Rome • Middle Ages (450-1400 CE) • clergy • nobility • commoners • Perotin • courtly love • polyphony • courts • Pope • Crusades • Pythagoras Page | 34 UNDERSTANDING MUSIC MUSIC OF THE MIDDLE AGES • refrain • syllabic • rhythm according to the text • university • Roman Empire (27 BCE – 476 CE) • vernacular literatures • song • verse • strophes • Virgin Mary 2.3 INTRODUCTION AND HISTORICAL CONTEXT 2.3.1 Musical Timeline Events in History Events in Music 2nd millennia BCE: First Hebrew Psalms are written 7th Century BCE: Ancient Greeks and Romans use music for entertainment and religious rites 6th Century BCE: Pythagoras and his experi- ments with acoustics From the 1st Century CE: Spread of Christianity through the Roman Empire 4th Century BCE: Plato and Aristotle write 4th Century CE: Founding of the monastic about music movement in Christianity c. 400 CE: St Augustine writes about church c. 450 CE: Fall of Rome music 4th – 9th Century CE: Development/Codification of Christian Chant c. 800 CE: First experiments in Western Music 11th Century CE: Rise of Feudalism & the Three Estates 11th Century CE: Guido of Arezzo refines of mu- 11th Century: Growth of Marian Culture sic notation and development of solfège 1088 CE: Founding of the University of Bolo- gna 12th Century CE: Hildegard of Bingen writes c. -

An Analysis of Guillaume De Machaut's "Le Lay De La Fonteinne" in Cultural Context Patricia A
The University of Maine DigitalCommons@UMaine Electronic Theses and Dissertations Fogler Library 12-2001 Words and music in communion: an analysis of Guillaume de Machaut's "Le Lay de la Fonteinne" in cultural context Patricia A. Turcic Follow this and additional works at: http://digitalcommons.library.umaine.edu/etd Part of the French and Francophone Language and Literature Commons Recommended Citation Turcic, Patricia A., "Words and music in communion: an analysis of Guillaume de Machaut's "Le Lay de la Fonteinne" in cultural context" (2001). Electronic Theses and Dissertations. 486. http://digitalcommons.library.umaine.edu/etd/486 This Open-Access Thesis is brought to you for free and open access by DigitalCommons@UMaine. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of DigitalCommons@UMaine. WORDS AND MUSIC IN COMMUNION: AN ANALYSIS OF GUILLAUME DE MACHAUT’S “LE LAY DE LA FONTEINNE” IN CULTURAL CONTEXT By Patricia A. Turcic B.A. Colby College, 1977 M.A. Bowling Green State University, 1988 B.M. University of Maine, 1996 A THESIS Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts (in Liberal Studies) The Graduate School The University of Maine December, 200 1 Advisory Committee: Cathleen Bauschatz, Professor of French, Advisor Kristina Passman, Associate Professor of Classical Language and Literature Beth Wiemann, Assistant Professor of Music Copyright 200 1 Patricia A. Turcic All Rights Reserved .. 11 WORDS AND MUSIC IN COMMUNION: AN ANALYSIS OF GUILLAUME DE MACHAUT’S “LE LAY DE LA FONTEINNE” IN CULTURAL CONTEXT By Patricia Turcic Thesis Advisor: Dr. -

Music Syllabus
1 Core Knowledge Music Syllabus Course Length: 13 weeks, 2 sessions per week Objectives: By the end of this term the student will: • know and accurately use specific terminology in describing musical parameters such as melody, rhythm, harmony and form • know and articulate musical characteristics of each historical style period in Western classical music as well as several popular and world music styles • correctly identify excerpts from these historical periods, popular and world music styles • understand the connections between musical styles and cultural contexts Requirements: Midterm: 25% Final Exam: 25% Five Assignments: 50% (5X10% each) Text: This syllabus is based on Joseph Kerman’s Listen, 4th Brief Edition text and accompanying 6-CD set (Bedford/St. Martin’s Press, 2000). There are many excellent reasons to use Kerman’s material, in part due to the close correlation to the Core Knowledge music sequence, but also because of the merit and quality of the text itself. It comes with an instructor’s manual that includes more exam questions and teaching Syllabus developed by the Core Knowledge Foundation https://www.coreknowledge.org/ 2 material. There is also an excellent website available through the publisher’s homepage, http://www.bedfordstmartins.com/music/. However, this course could be easily adapted to suit other standard music appreciation texts, including the following (all have accompanying CDs): Craig Wright, Listening to Music, 3rd edition. Westport, CT: Wadsworth, 1999. Joseph Machlis, The Enjoyment of Music, 7th edition. New York: Norton, 1995. Jeremy Yudkin, Understanding Music, 2nd edition. Upper Saddle River, NJ: Prentice Hall, 1999. Other material is drawn from the following sources that are widely available and currently under copyright. -

THE ACCOMPANIMENT of GREGORIAN CHANT by Patricia Burgstahler A.B., Nazareth College, 1956
THE ACCOMPANIMENT OF GREGORIAN CHANT by Patricia Burgstahler A.B., Nazareth College, 1956 Submitted to the Department of Music and the Faculty of the Graduate School of the University of Kansas in partial fulfill- ment of the requirements for the degree of Master of Arts. April, 1959 ACKNOWLEDGEMENTS I wish first of all to thank my husband, whose constant interest and encouragement made it possible for me to write this thesis, and then Dr. Joseph Yasser, to whom I am deeply indebted for his generous reading of this entire manuscript, his many constructive comments and bibliographical sugges- tions, and his enthusiastic approval of this application of his quartal harmonic system. To Dr. Milton Steinhardt and to Mr. George Michael I express my gratitude for their help- ful direction and valuable advice. 11 CONTENTS Page ACKNOWLEDGEMENTS· . 11 INTRODUCTION .... iv CHAPTER I HISTORICAL SURVEY OF GREGORIAN CHANT .... l Origins . ... 2 Early Forms ...... 3 Medieval Period .... 5 Modern Period ............. 9 ChronoloF," of the Chants. 11 CHAPTER II HISTORICAL SURVEY OF GREGORIAN CHANT ACCOMPANIMENT . 14 Early Polyphonic Settings and Later Art Forms . 16 Early Tertian Harmonizations ....•.• 18 Modern Tertian Harmonizations . .. 19 The Theory of Quartal Harmony ..... 26 CHAPTER III CURRENT RHYTHMIC THEORIES 35 The Mensuralist School. 36 The Accentualist School . 39 The Solesmes School 44 CHAPTER IV METHOD OF THE PRESENT ACCOMPANIMENT . 51 Harmony ....... 52 Rhythm. 57 Selection of Chants .. 60 CHAPTER V QUARTAL ACCOMPANIMENTS .. 63 Mass I. 64 Mass IV . 68 Mass XV • • • • • • • • • • • 73 Mass XVI with Ambrosian Gloria .. 77 Credo I . 81 Tones of the Gloria Patri . ... 85 Psalm Tones . • 87 Nativity Proper: Midnight Mass .•. -

University of Southampton Research Repository
University of Southampton Research Repository Copyright © and Moral Rights for this thesis and, where applicable, any accompanying data are retained by the author and/or other copyright owners. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis and the accompanying data cannot be reproduced or quoted extensively from without first obtaining permission in writing from the copyright holder/s. The content of the thesis and accompanying research data (where applicable) must not be changed in any way or sold commercially in any format or medium without the formal permission of the copyright holder/s. When referring to this thesis and any accompanying data, full bibliographic details must be given, e.g. Thesis: Author (Year of Submission) "Full thesis title", University of Southampton, name of the University Faculty or School or Department, PhD Thesis, pagination. UNIVERSITY OF SOUTHAMPTON FACULTY OF HUMANITIES Music Volume 1 of 1 Genre, Taxonomy and Repertory in Insular Polyphony of the “Long Thirteenth Century” (c. 1150-c.1350) by Amy Williamson Thesis for the degree of Doctor of Philosophy March 2016 UNIVERSITY OF SOUTHAMPTON ABSTRACT FACULTY OF HUMANITIES Music Thesis for the degree of Doctor of Philosophy GENRE, TAXONOMY AND REPERTORY IN INSULAR POLYPHONY OF THE “LONG THIRTEENTH CENTURY” (c. 1150-c.1350) Amy Williamson Modern scholarship has often viewed insular medieval music unfavourably in comparison to continental and, specifically, Notre Dame composition. This is, in part, due to the fragmentary remains of the insular repertory and the lack of theoretical literature relevant to insular composition, which clearly contrasted with French practices, at times. -

323 a Profession of Poetry' Or Song-Writing Per Se. Rather Their
323 a profession of poetry' or song-writing per se. Rather their few surviving S011.gs appear to have formed an adjunct to their p:rimary careers in publishing, music, o:r preaching. Apa:rt from the exceptioY1al case ("11 tout jamais" by Jean Marot), their identified productions in the field of mono phonic song are quite typical of the repertoire as a whole. The one work by a professional poet, on the other hand, is sty'listically similar to courtly poems a~!,d atypical of the monophonic repertoire. One can draw two conclusions from this. First, there is some overlap between the monopho',ic repertoire av-d that of courtly poetry', but it is slight and involves only songs which are stylistically marginal to monopho""y'. Secondly, gi ven the backgrou"Y'ds of known authors, one can expect simila rities between the mO'1.ophonic sOYJ.gs and learned poetI'y of the period. With regard to pe:rformers, there is direct evidence that nuns a:J.d preachers sang some of the religious sO:J.gs, and that law clerks sang excerpts from the secular repertoire. Furthermore, there is indirect evidence that street-singers in the tradition of the medieval jongleurs and later chanteurs publics sang monophonic songs. Indirect evidence also indicates that sacred and secular songs were available to literate -- i. but not necessarily' wealthy' -- members of the general pUblic I j as well as courtiers (and possibly professional musicians) \ who could read music. \ I The aUdience for the songs cOY1sisted of co~gregatiohs, probably' largely female, at public sermons, and those who J, '" 324 attended the public theater. -

Medieval Music
CONSEJERÍA DE EDUCACIÓN Dirección General de Participación e Innovación Educativa Identificación del material AICLE TÍTULO Medieval Music NIVEL LINGÜÍSTICO A2.1 SEGÚN MCER IDIOMA Inglés ÁREA / MATERIA Música NÚCLEO TEMÁTICO Historia de la Música La unidad pretende introducir al alumnado en el conocimiento de la música GUIÓN TEMÁTICO medieval, tanto religiosa como profana, trabajando sus características principales y compositores destacados. FORMATO Material didáctico en formato PDF CORRESPONDENCIA 2º de Educación Secundaria CURRICULAR AUTORÍA Almudena Viéitez Roldán TEMPORALIZACIÓN 6 sesiones. APROXIMADA Competencia lingüística: - Adquisición de vocabulario - Elaborar y formular preguntas al compañero - Discusión y puesta en común en voz alta de aspectos concretos del tema - Elaboración de textos - Lectura comprensiva COMPETENCIAS BÁSI- - Fomento de las destrezas orales CAS Competencia cultural y artística: - Conocimiento de música de otras épocas, inculcando una actitud de respeto hacia la misma Competencia para aprender a aprender: - Extraer características a partir de audiciones sin la presentación previa de la teoría - Establecer similitudes y diferencias entre el pasado y el presente Se recomienda completar la unidad con la interpretación vocal o instrumental OBSERVACIONES de alguna pieza de música medieval, por ejemplo la Cantiga nº 100 a la Virgen María de Alfonso X el Sabio, con flauta dulce o canto. Material AICLE. 2º de ESO: Medieval Music 3 Tabla de programación AICLE - Comprender y expresarse en una o más lenguas extranjeras de manera apropiada - Conocer, valorar y respetar los aspectos básicos de la cultura y la historia propias y OBJETIVOS de los demás, así como el patrimonio artístico y cultural - Apreciar la creación artística y comprender el lenguaje de las distintas manifesta- ciones artísticas, utilizando diversos medios de expresión y representación CONTENIDOS Bloque 4: La música en la cultura y en la sociedad. -

5 the Fourteenth Century Elizabeth Eva Leach
5 The fourteenth century elizabeth eva leach Although a famous popular history book’s subtitle glossed the fourteenth century as ‘calamitous’,a consideration of its music would probably see the period as a triumph.1 In part this is because the chief technology that gives us access to the past – writing – became more widely used for record keeping by this time. In particular, the special kind of writing used to record musical sounds – musical notation – reached a new level of prescription, describing relative pitches and rhythms more fully than before. As the fourteenth century paid more cultural attention to writing things down in the first place, more music books survive from this period than from any earlier centuries, and their contents seem tantalizingly decipherable. The detailed social and political history of the fourteenth century is complex and beyond the scope of this chapter. However, some of its aspects will be mentioned here, not in order to give a comprehensive history, but in order to suggest ways in which larger historical changes affected musical culture. The later fourteenth century saw a deep division of the Western Christian church, a problem partly caused by the refusal of successive popes to reside in Rome after the French pope Clement V moved the papal court to Avignon (France) in 1309. The often lavish papal court was responsible for employing a large number of expert singers, many of whom we know to have also been composers because pieces by them survive.2 Avignon was especially important as a centre for musical -

Music: Its Language, History, and Culture
City University of New York (CUNY) CUNY Academic Works Open Educational Resources Brooklyn College 2015 Music: Its Language, History, and Culture Douglas Cohen CUNY Brooklyn College Brooklyn College Library and Academic IT How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/bc_oers/4 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] MUSIC: ITS LANGUAGE, HISTORY, AND CULTURE A Reader for Music 1300 RAY ALLEN DOUGLAS COHEN NANCY HAGER JEFFREY TAYLOR Copyright © 2006, 2007, 2008, 2014 by the Conservatory of Music at Brooklyn College of the City University of New York. Original text by Ray Allen, Douglas Cohen, Nancy Hager, and Jeffrey Taylor with contributions by Marc Thorman. ISBN: 978-0-9913887-0-7 Music: Its Language, History and Culture by the Conservatory of Music at Brooklyn College of the City University of New York is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/4.0/deed.en_US. Based on a work at http://www.music1300.info/reader. Permissions beyond the scope of this license may be available at http://www.music1300.info/reader. Cover art and design by Lisa Panazzolo Photos by John Ricasoli CONTENTS Introduction 1 Chapter 1: Elements of Sound and Music 3 Elements of Sound: Frequency, Amplitude, Wave Form, Duration 3 Elements