Real-Time Expression Transfer for Facial Reenactment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Glitz and Glam
FINAL-1 Sat, Feb 24, 2018 5:31:17 PM Glitz and glam The biggest celebration in filmmaking tvspotlight returns with the 90th Annual Academy Your Weekly Guide to TV Entertainment Awards, airing Sunday, March 4, on ABC. Every year, the most glamorous people • For the week of March 3 - 9, 2018 • in Hollywood stroll down the red carpet, hoping to take home that shiny Oscar for best film, director, lead actor or ac- tress and supporting actor or actress. Jimmy Kimmel returns to host again this year, in spite of last year’s Best Picture snafu. OMNI Security Team Jimmy Kimmel hosts the 90th Annual Academy Awards Omni Security SERVING OUR COMMUNITY FOR OVER 30 YEARS Put Your Trust in Our2 Familyx 3.5” to Protect Your Family Big enough to Residential & serve you Fire & Access Commercial Small enough to Systems and Video Security know you Surveillance Remote access 24/7 Alarm & Security Monitoring puts you in control Remote Access & Wireless Technology Fire, Smoke & Carbon Detection of your security Personal Emergency Response Systems system at all times. Medical Alert Systems 978-465-5000 | 1-800-698-1800 | www.securityteam.com MA Lic. 444C Old traditional Italian recipes made with natural ingredients, since 1995. Giuseppe's 2 x 3” fresh pasta • fine food ♦ 257 Low Street | Newburyport, MA 01950 978-465-2225 Mon. - Thur. 10am - 8pm | Fri. - Sat. 10am - 9pm Full Bar Open for Lunch & Dinner FINAL-1 Sat, Feb 24, 2018 5:31:19 PM 2 • Newburyport Daily News • March 3 - 9, 2018 the strict teachers at her Cath- olic school, her relationship with her mother (Metcalf) is Videoreleases strained, and her relationship Cream of the crop with her boyfriend, whom she Thor: Ragnarok met in her school’s theater Oscars roll out the red carpet for star quality After his father, Odin (Hop- program, ends when she walks kins), dies, Thor’s (Hems- in on him kissing another guy. -

Clones Stick Together
TVhome The Daily Home April 12 - 18, 2015 Clones Stick Together Sarah (Tatiana Maslany) is on a mission to find the 000208858R1 truth about the clones on season three of “Orphan Black,” premiering Saturday at 8 p.m. on BBC America. The Future of Banking? We’ve Got A 167 Year Head Start. You can now deposit checks directly from your smartphone by using FNB’s Mobile App for iPhones and Android devices. No more hurrying to the bank; handle your deposits from virtually anywhere with the Mobile Remote Deposit option available in our Mobile App today. (256) 362-2334 | www.fnbtalladega.com Some products or services have a fee or require enrollment and approval. Some restrictions may apply. Please visit your nearest branch for details. 000209980r1 2 THE DAILY HOME / TV HOME Sun., April 12, 2015 — Sat., April 18, 2015 DISH AT&T DIRECTV CABLE CHARTER CHARTER PELL CITY PELL ANNISTON CABLE ONE CABLE TALLADEGA SYLACAUGA BIRMINGHAM BIRMINGHAM BIRMINGHAM CONVERSION CABLE COOSA SPORTS WBRC 6 6 7 7 6 6 6 6 AUTO RACING Friday WBIQ 10 4 10 10 10 10 6 p.m. FS1 St. John’s Red Storm at Drag Racing WCIQ 7 10 4 Creighton Blue Jays (Live) WVTM 13 13 5 5 13 13 13 13 Sunday Saturday WTTO 21 8 9 9 8 21 21 21 7 p.m. ESPN2 Summitracing.com 12 p.m. ESPN2 Vanderbilt Com- WUOA 23 14 6 6 23 23 23 NHRA Nationals from The Strip at modores at South Carolina WEAC 24 24 Las Vegas Motor Speedway in Las Gamecocks (Live) WJSU 40 4 4 40 Vegas (Taped) 2 p.m. -
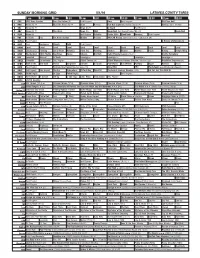
Sunday Morning Grid 5/1/16 Latimes.Com/Tv Times
SUNDAY MORNING GRID 5/1/16 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program Boss Paid Program PGA Tour Golf 4 NBC News (N) Å Meet the Press (N) Å News Rescue Red Bull Signature Series (Taped) Å Hockey: Blues at Stars 5 CW News (N) Å News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) NBA Basketball First Round: Teams TBA. (N) Basketball 9 KCAL News (N) Joel Osteen Schuller Pastor Mike Woodlands Amazing Paid Program 11 FOX In Touch Paid Fox News Sunday Midday Prerace NASCAR Racing Sprint Cup Series: GEICO 500. (N) 13 MyNet Paid Program A History of Violence (R) 18 KSCI Paid Hormones Church Faith Paid Program 22 KWHY Local Local Local Local Local Local Local Local Local Local Local Local 24 KVCR Landscapes Painting Joy of Paint Wyland’s Paint This Painting Kitchen Mexico Martha Pépin Baking Simply Ming 28 KCET Wunderkind 1001 Nights Bug Bites Space Edisons Biz Kid$ Celtic Thunder Legacy (TVG) Å Soulful Symphony 30 ION Jeremiah Youssef In Touch Leverage Å Leverage Å Leverage Å Leverage Å 34 KMEX Conexión En contacto Paid Program Fútbol Central (N) Fútbol Mexicano Primera División: Toluca vs Azul República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Schuller In Touch PowerPoint It Is Written Pathway Super Kelinda Jesse 46 KFTR Paid Program Formula One Racing Russian Grand Prix. -

+14 Days of Tv Listings Free
CINEMA VOD SPORTS TECH + 14 DAYS OF TV LISTINGS 1 JUNE 2015 ISSUE 2 TVGUIDE.CO.UK TVDAILY.COM Jurassic World Orange is the New Black Formula 1 Addictive Apps FREE 1 JUNE 2015 Issue 2 Contents TVGUIDE.CO.UK TVDAILY.COM EDITOR’S LETTER 4 Latest TV News 17 Food We are living in a The biggest news from the world of television. Your television dinners sorted with revolutionary age for inspiration from our favourite dramas. television. Not only is the way we watch television being challenged by the emergence of video on 18 Travel demand, but what we watch on television is Journey to the dizzying desert of Dorne or becoming increasingly take a trip to see the stunning setting of diverse and, thankfully, starting to catch up with Downton Abbey. real world demographics. With Orange Is The New Black back for another run on Netflix this month, we 19 Fashion decided to celebrate the 6 Top 100 WTF Steal some shadespiration from the arduous journey it’s taken to get to where we are in coolest sunglass-wearing dudes on TV. 2015 (p14). We still have a Moments (Part 2) long way to go, but we’re The final countdown of the most unbelievable getting there. Sports Susan Brett, Editor scenes ever to grace the small screen, 20 including the electrifying number one. All you need to know about the upcoming TVGuide.co.uk Formula 1 and MotoGP races. 104-08 Oxford Street, London, W1D 1LP [email protected] 8 Cinema CONTENT 22 Addictive Apps Editor: Susan Brett Everything you need to know about what’s Deputy Editor: Ally Russell A handy guide to all the best apps for Artistic Director: Francisco on at the Box Office right now. -

THE GETAWAY GIRL: a NOVEL and CRITICAL INTRODUCTION By
THE GETAWAY GIRL: A NOVEL AND CRITICAL INTRODUCTION By EMILY CHRISTINE HOFFMAN Bachelor of Arts in English University of Kansas Lawrence, Kansas 1999 Master of Arts in English University of Kansas Lawrence, Kansas 2002 Submitted to the Faculty of the Graduate College of the Oklahoma State University in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY December, 2009 THE GETAWAY GIRL: A NOVEL AND CRITICAL INTRODUCTION Dissertation Approved: Jon Billman Dissertation Adviser Elizabeth Grubgeld Merrall Price Lesley Rimmel Ed Walkiewicz A. Gordon Emslie Dean of the Graduate College ii ACKNOWLEDGMENTS I would like to express my appreciation to several people for their support, friendship, guidance, and instruction while I have been working toward my PhD. From the English department faculty, I would like to thank Dr. Robert Mayer, whose “Theories of the Novel” seminar has proven instrumental to both the development of The Getaway Girl and the accompanying critical introduction. Dr. Elizabeth Grubgeld wisely recommended I include Elizabeth Bowen’s The House in Paris as part of my modernism reading list. Without my knowledge of that novel, I am not sure how I would have approached The Getaway Girl’s major structural revisions. I have also appreciated the efforts of Dr. William Decker and Dr. Merrall Price, both of whom, in their role as Graduate Program Director, have generously acted as my advocate on multiple occasions. In addition, I appreciate Jon Billman’s willingness to take the daunting role of adviser for an out-of-state student he had never met. Thank you to all the members of my committee—Prof. -

Classifieds to Work for You! 1144 Hwy
PAID ECRWSS Eagle River PRSRT STD PRSRT U.S. Postage Permit No. 13 POSTAL PATRON POSTAL 5353 Hwy. 70 W 5353 Hwy. Eagle River, WI 54521 Eagle River, Page 1 Saturday, Dec. 24, 2011 24, Dec. (715) 479-4421 A SPECIAL SECTION OF THE SECTION OF SPECIAL A AND THE THREE LAKES NEWS VILAS COUNTY NEWS-REVIEW VILAS COUNTY SUPER SHOPPING GUIDE OF VILAS AND ONEIDA COUNTIES VILAS AND ONEIDA SUPER SHOPPING GUIDE OF NORTH WOODS NORTH More for: Look North in the Trader Woods • and Much • Real Estate • TV Listings these sale flyers: • Automotive See the Trader for See the Trader © Eagle River Publications, Inc. 1972 Inc. © Eagle River Publications, • PAMIDA • PICK ’N SAVE • TRIG’S • CAMP’S SUPERVALU •THREE LAKES FOODS BAKER’S • WALGREENS •SHOPKO • MENARDS •FRONTIER • P&G BRANDSAVER • MILLS FLEET FARM • KOHL’S • Entertainment • Classified Ads LIKELIKE THISTHIS PHOTO?PHOTO? NorthwoodsNorthwoods FurnitureFurniture OutletOutlet 1st1st TimeTime EverEver WAREHOUSEWAREHOUSE Up To SALE!SALE! 75% Off on: • Overstocks • Discontinued Items • Accessories • Scratch-and-Dent Items Our warehouse is overflowing with year-end closeouts from both locations! Check out hundreds more taken by News-Review photographers in our online Photo Gallery. Shop Now! www.vcnewsreview.com FOR VIEWING OR PURCHASE Open Save BIG! Special Sale ends Jan. 2 Holiday Hours! BRING YOUR TRUCK • TRAILER • VAN! LOCAL TELEPHONE PREFIXES Hours: Mon.-Sat. 9-5; Sun. 11-3 Arbor Vitae 356, 358 Minocqua 356, 358 (call ahead for details) Argonne 649 North Land O’ Lakes (906) 544 Boulder Junction 385 Phelps 545 HURRY IN FOR BEST SELECTION! Conover 477, 479 Presque Isle 686 Crandon 478 Rhinelander 362, 365, 369 Where Friends Meet Friends St. -

2017 NOVELLO ADJUDICATOR - Mr John Bradley First Press of the Olive Harvest
The only way to fi nd out what’s going on! Serving the Hunter for over 20 years with a readership of over 4,000 weekly! Thursday 18th May, 2017 Missed an issue? www.huntervalleyprinting.com.au/Pages/Entertainer.php See inside TV Guide Opening Night Friday 26 May @ 6.30pm RSL Hall, Murrurundi Entry: $10 (includes supper & drinks) 2017 NOVELLO ADJUDICATOR - Mr John Bradley First press of the olive harvest. Unfiltered, Extra Virgin Olive Oil. People's Choice 2016 Barry Bryan "Moving the Mob" - The exhibition will be open from 27 May - 12 June (Sat/Sun/Public Holiday) Entry by gold coin donation Enquiries: 0415 503 632 or 6546 6001 www.pukaraestate.com.au www.murrurundiartprize.com SESSION TIMES: THURSDAY 18 MAY - WEDNESDAY 24 MAY Cinema is CLOSED Mondays outside of school and public holidays JOHN WICK: CHAPTER 2 ALIEN: COVENANT SNATCHED (MA15+) 123mins (MA15+) 122mins (MA15+) 90mins Thu, Fri & Tue Thu, Fri & Tue Thu, Fri & Tue 9.00am, 1.30pm & 9.00pm 11.30am, 4.00pm & 6.10pm 11.30am, 4.20pm & 8.30pm Sat, Sun & Wed Sat, Sun & Wed Sat, Sun & Wed 10.45am, 4.10pm & 6.15pm 12.00pm, 3.45pm & 8.30pm 9.00am, 2.20pm & 6.40pm GUARDIANS OF BEAUTY AND COMING SOON THE GALAXY: VOL 2 Pirates of the Caribbean - Dead Men Tell No Tales (M) 136mins THE BEAST The Mummy (PG) 129mins Despicable Me 3 Thu, Fri & Tue Cars 3 Sat, Sun & Wed Transformers - Last Knight 9.00am, 1.50pm & 6.20pm Spiderman - Homecomming 12-15 Sydney Street Sat, Sun & Wed 9.00am Dunkirk Muswellbrook 1.10pm & 8.45pm All tickets $10 Phone: (02) 4044 0600 Live in Muswellbrook? Don’t forget the Courtesy Bus is available to get you to the cinema. -

Florida State University Libraries
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2017 The Laws of Fantasy Remix Matthew J. Dauphin Follow this and additional works at the DigiNole: FSU's Digital Repository. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES THE LAWS OF FANTASY REMIX By MATTHEW J. DAUPHIN A Dissertation submitted to the Department of English in partial fulfillment of the requirements for the degree of Doctor of Philosophy 2017 Matthew J. Dauphin defended this dissertation on March 29, 2017. The members of the supervisory committee were: Barry Faulk Professor Directing Dissertation Donna Marie Nudd University Representative Trinyan Mariano Committee Member Christina Parker-Flynn Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii To every teacher along my path who believed in me, encouraged me to reach for more, and withheld judgment when I failed, so I would not fear to try again. iii TABLE OF CONTENTS Abstract ............................................................................................................................................ v 1. AN INTRODUCTION TO FANTASY REMIX ...................................................................... 1 Fantasy Remix as a Technique of Resistance, Subversion, and Conformity ......................... 9 Morality, Justice, and the Symbols of Law: Abstract -

Sandman Company Overview
01 ABOUT SANDMAN STUDIOS SANDMAN STUDIOS ENT. Sandman Studios Entertainment is a full-service creative agency engaged in animation, visual effects production and interactive multimedia. With the ability to deliver everything from initial concept and design to development, integration and implementation, Sandman provides high quality solutions that meet your media needs, and that work within your budget. Sandman’s principals have worked extensively among a diverse and prominent portfolio of Entertainment, Media, Technology and Fortune 500 corporations, bringing industry-leading strategy and design together with advanced technology to create award-winning, innovative solutions across a broad range of media. The principals at Sandman have been key providers of leading technical and creative services to the market place. The Company’s ability to provide the highest quality services from beginning to end rivals larger competitors. However, Sandman has a much lower cost structure than these larger players, and therefore, is able to deliver a significantly higher return on investment to its clients. It is this value leadership that enables the Company to successfully win accounts with its high profile clientele. Equipped with the latest technologies and staffed with talented professionals and artists, Sandman is an attractive provider due to its ability to provide high quality solutions, while at the same time offering quick response times and reliability, at very competitive prices. SANDMAN STUDIOS ENT. 02 ANIMATION & VISUAL EFFECTS PRODUCTION Sandman Studios Entertainment principals have extensive experience and skill in animation, visual effects production for feature film, broadcast, and video. Collectively, our artists, production managers and VFX & animation supervisors have provided stunning animations & visual effects for over 200 feature films, hundreds of hours of television, hundreds of commercials, and countless video projects. -
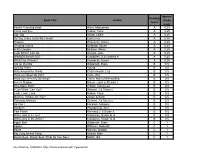
Book Title Author Reading Level Approx. Grade Level
Approx. Reading Book Title Author Grade Level Level Anno's Counting Book Anno, Mitsumasa A 0.25 Count and See Hoban, Tana A 0.25 Dig, Dig Wood, Leslie A 0.25 Do You Want To Be My Friend? Carle, Eric A 0.25 Flowers Hoenecke, Karen A 0.25 Growing Colors McMillan, Bruce A 0.25 In My Garden McLean, Moria A 0.25 Look What I Can Do Aruego, Jose A 0.25 What Do Insects Do? Canizares, S.& Chanko,P A 0.25 What Has Wheels? Hoenecke, Karen A 0.25 Cat on the Mat Wildsmith, Brain B 0.5 Getting There Young B 0.5 Hats Around the World Charlesworth, Liza B 0.5 Have you Seen My Cat? Carle, Eric B 0.5 Have you seen my Duckling? Tafuri, Nancy/Greenwillow B 0.5 Here's Skipper Salem, Llynn & Stewart,J B 0.5 How Many Fish? Cohen, Caron Lee B 0.5 I Can Write, Can You? Stewart, J & Salem,L B 0.5 Look, Look, Look Hoban, Tana B 0.5 Mommy, Where are You? Ziefert & Boon B 0.5 Runaway Monkey Stewart, J & Salem,L B 0.5 So Can I Facklam, Margery B 0.5 Sunburn Prokopchak, Ann B 0.5 Two Points Kennedy,J. & Eaton,A B 0.5 Who Lives in a Tree? Canizares, Susan et al B 0.5 Who Lives in the Arctic? Canizares, Susan et al B 0.5 Apple Bird Wildsmith, Brain C 1 Apples Williams, Deborah C 1 Bears Kalman, Bobbie C 1 Big Long Animal Song Artwell, Mike C 1 Brown Bear, Brown Bear What Do You See? Martin, Bill C 1 Found online, 7/20/2012, http://home.comcast.net/~ngiansante/ Approx. -

Midlife Demon Hunter
MIDLIFE DEMON HUNTER THE FORTY PROOF SERIES, BOOK 3 SHANNON MAYER CONTENTS Acknowledgments Chapter 1 Chapter 2 Chapter 3 Chapter 4 Chapter 5 Chapter 6 Chapter 7 Chapter 8 Chapter 9 Chapter 10 Chapter 11 Chapter 12 Chapter 13 Chapter 14 Chapter 15 Chapter 16 Chapter 17 Chapter 18 Chapter 19 Chapter 20 Chapter 21 Chapter 22 Chapter 23 Chapter 24 Chapter 25 Chapter 26 Chapter 27 Up Next! About the Author Copyright © Shannon Mayer 2020 All rights reserved HiJinks Ink Publishing www.shannonmayer.com All rights reserved. Without limiting the rights under copyright reserved above, no part of this publication may be reproduced, stored in or introduced into a database and retrieval system or transmitted in any form or any means (electronic, mechanical, photocopying or otherwise) without the prior written permission of both the owner of the copyright and the above publishers. Please do not participate in or encourage the piracy of copyrighted materials in violation of the author’s rights. Purchase only authorized editions. This is a work of fiction. Names, characters, places and incidents are either the product of the author’s imagination or are used fictitiously, and any resemblance to actual persons living or dead, business establishments, events or locales is entirely coincidental. Mayer, Shannon Created with Vellum ACKNOWLEDGMENTS Thank you to the ladies in the back row. You know, to the ones who cheer the loudest, who support their fellow women even as they themselves struggle. The ladies who stand up for what’s right and for taking on challenges that others shy away from. -

The Brothers Grimm Spectaculathon (Full-Length) (1St Ed
The Brothers Grimm Spectaculathon (full-length) (1st ed. - 08.02.07) - brothersgrimmspectaculathonAjr Copyright © 2007 Don Zolidis ALL RIGHTS RESERVED Copyright Protection. This play (the “Play”) is fully protected under the copyright laws of the United States of America and all countries with which the United States has reciprocal copyright relations, whether through bilateral or multilateral treaties or otherwise, and including, but not limited to, all countries covered by the Pan-American Copyright Convention, the Universal Copyright Convention, and the Berne Conven- tion. Reservation of Rights. All rights to this Play are strictly reserved, including, without limitation, professional and amateur stage performance rights; motion picture, recitation, lecturing, public reading, radio broadcast- ing, television, video, and sound recording rights; rights to all other forms of mechanical or electronic repro- duction now known or yet to be invented, such as CD-ROM, CD-I, DVD, photocopying, and information storage and retrieval systems; and the rights of translation into non-English languages. Performance Licensing and Royalty Payments. Amateur and stock performance rights to this Play are controlled exclusively by Playscripts, Inc. (“Playscripts”). No amateur or stock production groups or indi- viduals may perform this Play without obtaining advance written permission from Playscripts. Required roy- alty fees for performing this Play are specified online at the Playscripts website (www.playscripts.com). Such royalty fees may be subject to change without notice. Although this book may have been obtained for a particular licensed performance, such performance rights, if any, are not transferable. Required royalties must be paid every time the Play is performed before any audience, whether or not it is presented for profit and whether or not admission is charged.