How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PGA TOUR Player/Manager List
2016 PGA TOUR Player/Manager List Generated On: 2/17/2016 - A - ADAMS, Blake - 1 Degree Management, LLC AIKEN, Thomas - Wasserman Media Group - London ALLEM, Fulton - Players Group, Inc ALLENBY, Robert - MVP, Inc. ALLEN, Michael - Medalist Management, Inc. ALLRED, Jason - 4U Management, LLC AL, Geiberger, - Cross Consulting AMES, Stephen - Wasserman Media Group - Canada ANCER, Abraham - The Legacy Agency ANDERSON, Mark - Blue Giraffe Sports ANDRADE, Billy - 4Sports & Entertainment ANGUIANO, Mark - The Legacy Agency AOKI, Isao - High Max APPLEBY, Stuart - Blue Giraffe Sports ARAGON, Alex - Wasserman Media Group - VA ARMOUR III, Tommy - Tommy Armour, III, Inc. ARMOUR, Ryan - IMG ATKINS, Matt - a3 Athletics AUSTIN, Woody - The Legacy Agency AXLEY, Eric - a3 Athletics AZINGER, Paul - TCP Sports Management, LLC A., Jimenez, Miguel - Marketing and Management International - B - BADDELEY, Aaron - Pro-Sport Management BAEK, Todd - Hambric Sports Management BAIRD, Briny - Pinnacle Enterprises, Inc. BAKER-FINCH, Ian - IMG Media BAKER, Chris - 1 Degree Management, LLC BALLO, JR., Mike - Lagardere Sports BARBER, Blayne - IMG BARLOW, Craig - The Legacy Agency BARNES, Ricky - Lagardere Sports BATEMAN, Brian - Lagardere Sports - GA BEAUFILS, Ray - Wasserman Media Group - VA BECKMAN, Cameron - Wasserman Media Group - VA BECK, Chip - Tour Talent BEEM, Rich - Marketing and Management International BEGAY III, Notah - Freeland Sports, LLC BELJAN, Charlie - Meister Sports Management BENEDETTI, Camilo - The Legacy Agency BERGER, Daniel - Excel Sports Management BERTONI, Travis - Medalist Management, Inc. BILLY, Casper, - Pinnacle Enterprises, Inc. BLAUM, Ryan - 1 Degree Management, LLC BLIXT, Jonas - Lagardere Sports - FL BOHN, Jason - IMG BOLLI, Justin - Blue Giraffe Sports BOWDITCH, Steven - Players Group, Inc BOWDITCH, Steven - IMG BRADLEY, Keegan - Lagardere Sports - FL BRADLEY, Michael - Lagardere Sports BREHM, Ryan - Wasserman Media Group - Wisconsin BRIGMAN, D.J. -

2019 Boeing Classic the Club at Snoqualmie Ridge Second Round Groupings and Starting Times Saturday, August 24, 2019
2019 Boeing Classic The Club at Snoqualmie Ridge Second Round Groupings and Starting Times Saturday, August 24, 2019 TEE # 1 11:35 Olin Browne Tequesta, FL 70 70 Wes Short, Jr. Austin, TX 70 70 Tim Petrovic Austin, TX 70 70 11:46 Dave Cunningham Scottsdale, AZ 69 69 David McKenzie Melbourne, Australia 69 69 Larry Mize Columbus, GA 70 70 11:57 Marco Dawson Merritt Island, FL 69 69 Cliff Kresge Kingsport, TN 69 69 Tommy Tolles The Cliffs Communities, NC 69 69 12:08 Scott Parel Augusta, GA 69 69 Paul Goydos Long Beach, CA 69 69 Joe Durant Pensacola Beach, FL 69 69 12:19 Scott McCarron Mooresville, NC 69 69 Colin Montgomerie Royal Troon, Scotland 69 69 Steve Flesch Union, KY 69 69 12:30 Glen Day Alotion, AR 69 69 Brandt Jobe Oklahoma City, OK 69 69 Woody Austin Derby, KS 69 69 12:41 Tom Gillis Lake Orion, MI 69 69 John Huston Clearwater, FL 69 69 Russ Cochran Paducah, KY 69 69 12:52 Tom Pernice Jr. Murrieta, CA 68 68 Duffy Waldorf Las Vegas, NV 68 68 David Frost Delray Beach, FL 69 69 1:03 Ken Duke Stuart, FL 68 68 Greg Kraft Belleair, FL 68 68 Kirk Triplett Scottsdale, AZ 68 68 1:14 Retief Goosen Polokwane, South Africa 67 67 Mark O'Meara Houston, TX 67 67 Kent Jones Albuquerque, NM 68 68 1:25 Stephen Leaney Perth, Australia 66 66 Gene Sauers Savannah, GA 67 67 Jerry Kelly Madison, WI 67 67 1:36 Jeff Maggert Sea Pines, SC 66 66 Bernhard Langer Munich, Germany 66 66 Paul Broadhurst Nuneaton, England 66 66 1:47 Fred Funk Ponte Vedra Beach, FL 64 64 Fred Couples Seattle, WA 65 65 Doug Garwood Los Angeles, CA 66 66 Report Generated at 18:31:43 -

2004 Ford Senior Players Championship
Page 1 | Pre-Tournament Media Notes Bridgestone SENIOR PLAYERS Championship Firestone Country Club | Akron, Ohio | August 12-16, 2020 PGA TOUR Media Contacts • Laura Vescovi – [email protected], 904-465-5924 • Jackie Servais – [email protected], 303-249-6439 Quick Facts • Golf Course: Firestone Country Club (Par 70 / 7,400 yards) • Designed by: Bert Way and Robert Trent Jones (1929) • Purse: $3,000,000 (Winner: $450,000) • Golf Channel (local times): Thurs-Fri, 11:00 a.m. – 2:00 p.m.; Sat, 3:00 – 5:00 p.m.; Sun, 2:30 – 5:00 p.m. • Social Media: @seniorplayers (Instagram, Facebook and Twitter) Field Overview (as of 8/11/20) The 38th annual Bridgestone SENIOR PLAYERS Championship comes to Akron, Ohio and will be contested at Firestone Country Club for the second straight year. The event is the fourth-oldest on PGA TOUR Champions and formerly one that rotated venues but will now be contested at Firestone through 2022. Retief Goosen will return to defend his title, and will be joined by eight other past champions of the event: Vijay Singh (2018), Scott McCarron (2017), Bernhard Langer (2014, 2015, 2016), Kenny Perry (2013), Fred Couples (2011), Mark O’Meara (2010), Jay Haas (2009), and Loren Roberts (2007). The field features 14 players making their tournament debuts, including Ernie Els, Mike Weir and Charles Schwab Cup leader Brett Quigley. Additional field highlights: • Seven members of the World Golf Hall of Fame • Three players who have won a professional event at Firestone (Singh, World Golf Championships 2008; Clarke, -

Official Media Guide
OFFICIAL MEDIA GUIDE OCTOBER 6-11, 2015 &$ " & "#"!" !"! %'"# Table of Contents The Presidents Cup Summary ................................................................. 2 Chris Kirk ...............................................................................52 Media Facts ..........................................................................................3-8 Matt Kuchar ..........................................................................53 Schedule of Events .............................................................................9-10 Phil Mickelson .......................................................................54 Acknowledgements ...............................................................................11 Patrick Reed ..........................................................................55 Glossary of Match-Play Terminology ..............................................12-13 Jordan Spieth ........................................................................56 1994 Teams and Results/Player Records........................................14-15 Jimmy Walker .......................................................................57 1996 Teams and Results/Player Records........................................16-17 Bubba Watson.......................................................................58 1998 Teams and Results/Player Records ......................................18-19 International Team Members ..................................................59-74 2000 Teams and Results/Player Records -

2020 Media Guide
2020 Media Guide Schedule of Events October 5 – 11, 2020 TPC Summerlin 1700 Village Center Circle Las Vegas, NV 89134 www.shrinershospitalsopen.com Monday, October 5, 2020 (Course closed to the public) Tuesday, October 6, 2029 (Course closed to the public) Wednesday, October 7, 2020 (Course closed to the public) Championship Pro-Am Presented by Red Rock Casino Resort & Spa 6:00 a.m. Gates Open 7:00 a.m. Championship Pro-Am (Tee Times: 7:00 - 8:30 a.m. and 11:30 a.m. - 12:20 p.m.) Thursday, October 8, 2020 - Sunday, October 11, 2020 (Course closed to the public) PGA TOUR Professional Competition Thursday, October 8: First round of professional competition 6:00 a.m. Gates Open 6:45 a.m. – 8:35 a.m. and 11:30 a.m. – 12:20 p.m. Approximate Tee Times Friday, October 9: Second round of professional competition 6:00 a.m. Gates Open 6:45 a.m. – 8:35 a.m. and 11:30 a.m. – 12:20 p.m. Approximate Tee Times Saturday, October 10: Third round of professional competition 6:00 a.m. Gates Open 6:45 a.m. – 12:55 p.m. Approximate Tee Times Sunday, October 11: Final round of professional competition Championship Sunday 6:00 a.m. Gates Open 6:45 a.m. – 12:55 p.m. Approximate Tee Times TOURNAMENT MEDIA RELATIONS Contact Information Terri Maruca Kirvin Doak Communications M: 702-371-6962 E: [email protected] T: @ntylion92 Emily Clayton Kirvin Doak Communications M: 702-349-7758 E: [email protected] T: @emilybclayton Helpful Information Parking Information: All media tournament parking is located at Suncoast Hotel on the corner of Rampart Boulevard and Alta Drive. -

No Agent ALLEM, Fulton - Players Group Management - VA ALLENBY, Robert - MVP, Inc
2020 PGA TOUR Player/Manager List Generated On: 8/10/2020 - A - ADAMS, Blake - MGC Sports ALBERTSON, Anders - No Agent ALDRIDGE, Tyler - No Agent ALLEM, Fulton - Players Group Management - VA ALLENBY, Robert - MVP, Inc. ALLEN, Michael - Medalist Management, Inc. AL, Geiberger, - Cross Consulting AMES, Stephen - No Agent ANCER, Abraham - GSE Worldwide ANDERSON, Mark - No Agent ANDRADE, Billy - 4Sports & Entertainment AN, Byeong Hun - Wasserman Media Group - London APPLEBY, Stuart - Resolute Sports Advisors ARAGON, Alex - No Agent ARMOUR III, Tommy - Tommy Armour, III, Inc. ARMOUR, Ryan - No Agent ARNAUD, Michael - Empire Sports Management ATKINS, Matt - No Agent AUSTIN, Woody - GSE Worldwide AXLEY, Eric - a3 Athletics AZINGER, Paul - TCP Sports Management, LLC A., Jimenez, Miguel - Marketing and Management International - B - BADDELEY, Aaron - Pro-Sport Management BAIRD, Briny - Pinnacle Enterprises, Inc. BAKER-FINCH, Ian - Excel Sports Management BAKER, Chris - MGC Sports BARBER, Blayne - No Agent BARJON, Paul - Players Group Management - VA BARNES, Erik - TCP Sports Management, LLC BARNES, Ricky - Sportfive BECKMAN, Cameron - Wasserman Media Group - VA BECK, Chip - Tour Talent BEEM, Rich - Marketing and Management International BELJAN, Charlie - Meister Sports Management BERGER, Daniel - Excel Sports Management BLAIR, Zac - Mullhaupt Management, LLC BLAKEFIELD, Mark - Fidelity Sports Group, LLC BLANKS, Kris - No Agent BLAUM, Ryan - MGC Sports BLIXT, Jonas - Sportfive BOHN, Jason - No Agent BOWDITCH, Steven - No Agent BOZZELLI, Dominic -

How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR
How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Fearing, Douglas, Jason Acimovic, and Stephen C Graves. “How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR.” Journal of Quantitative Analysis in Sports 7.1 (2011): n. pag. © 2011 American Statistical Association As Published http://dx.doi.org/10.2202/1559-0410.1268 Publisher Walter de Gruyter Version Final published version Citable link http://hdl.handle.net/1721.1/107940 Terms of Use Article is made available in accordance with the publisher's policy and may be subject to US copyright law. Please refer to the publisher's site for terms of use. Journal of Quantitative Analysis in Sports Volume 7, Issue 1 2011 Article 5 How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR Douglas Fearing, Harvard Business School Jason Acimovic, MIT Operations Research Center Stephen C. Graves, MIT Sloan School of Management Recommended Citation: Fearing, Douglas; Acimovic, Jason; and Graves, Stephen C. (2011) "How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR," Journal of Quantitative Analysis in Sports: Vol. 7: Iss. 1, Article 5. DOI: 10.2202/1559-0410.1268 ©2011 American Statistical Association. All rights reserved. Brought to you by | Massachusetts Institute of Technology - MIT Libraries Authenticated | 18.101.8.220 Download Date | 3/9/14 5:50 AM How to Catch a Tiger: Understanding Putting Performance on the PGA TOUR Douglas Fearing, Jason Acimovic, and Stephen C. -

THE PLAYERS Championship Tournament Records
Table of Contents Schedule of Events................................................................. 2-3 THE PLAYERS 1993 .............................................................. 168 Player Eligibility ......................................................................... 4 Hole-by-Hole Summary and Scoring Recap .................... 169 Broadcast Schedule .................................................................. 5 THE PLAYERS 1994 .............................................................. 170 Tournament Officials ................................................................ 6 Hole-by-Hole Summary and Scoring Recap .................... 171 Style Reminder .......................................................................... 6 THE PLAYERS 1995 .............................................................. 172 Tournament Fact Sheet.......................................................... 7-9 Hole-by-Hole Summary and Scoring Recap .................... 173 History at a Glance.................................................................. 10 THE PLAYERS 1996 .............................................................. 174 Timeline History of THE PLAYERS .....................................11-12 Hole-by-Hole Summary and Scoring Recap .................... 175 Official Scorecard for 2020 ..................................................... 12 THE PLAYERS 1997 .............................................................. 176 Hole-by-Hole Summary and Scoring Recap .................... 177 COMPETITORS’ CAPSULES -

Regions Tradition Greystone G&CC Second Round Groupings And
Regions Tradition Greystone G&CC Second Round Groupings and Starting Times Friday, May 7, 2021 TEE # 10 9:30 Corey Pavin Dallas, TX Billy Mayfair Scottsdale, AZ Gary Hallberg Denver, CO 9:40 Kenny Perry Franklin, KY Jeff Maggert Sea Pines, SC David Frost Delray Beach, FL 9:51 Colin Montgomerie Royal Troon, Scotland José María Olazábal San Sebastian, Spain Ian Woosnam Oswestry, Wales 10:01 Robert Karlsson Katrineholm, Sweden Bernhard Langer Munich, Germany David Toms Shreveport, LA 10:12 Miguel Angel Jiménez Malaga, Spain Vijay Singh Fiji Islands Tim Petrovic Austin, TX 10:22 Larry Mize Columbus, GA Mark O'Meara Las Vegas, NV Sandy Lyle Perthshire, Scotland 10:33 Loren Roberts Memphis, TN Steve Jones Tempe, AZ Mark Brooks Fort Worth, TX 10:43 Dicky Pride Tuscaloosa, AL Tom Byrum San Antonio, TX Gene Sauers Savannah, GA 10:54 Alex Cejka Munich, Germany Paul Broadhurst Nuneaton, England Joe Durant Pensacola Beach, FL 11:04 Steve Pate Delray Beach, FL Doug Barron Memphis, TN Mike Goodes Reidsville, NC 11:15 Olin Browne Tequesta, FL Tommy Tolles The Cliffs Communities, NC Stephen Ames Canada 11:25 Paul Goydos Long Beach, CA Scott Hoch Orlando, FL Joey Sindelar Horseheads, NY 11:36 Steve Flesch Union, KY Marco Dawson Merritt Island, FL Kent Jones Albuquerque, NM 11:46 Tom Gillis Lake Orion, MI Matt Gogel Mission Hills, KS Tim Herron Minneapolis, MN Report Generated at 16:53:02 on 05/04/21 Page 1 of 2 Regions Tradition Greystone G&CC Second Round Groupings and Starting Times Friday, May 7, 2021 TEE # 1 9:35 Michael Allen Paradise Valley, AZ Billy Andrade Bristol, RI Glen Day Alotion, AR 9:45 Frank Lickliter II Ponte Vedra Bch, FL Scott Dunlap Sarasota, FL Russ Cochran Paducah, KY 9:56 John Huston Clearwater, FL Wes Short, Jr. -

A Field Full of Tour Winners and Hot Young Players Expected at the 2006 Reno-Tahoe Open
FOR IMMEDIATE RELEASE CONTACT: Jim Kline, Reno-Tahoe Open 775-322-3900 / [email protected] Ronele Klingensmith, RKPR Inc. 775-378-0031 cell / [email protected] A FIELD FULL OF TOUR WINNERS AND HOT YOUNG PLAYERS EXPECTED AT THE 2006 RENO-TAHOE OPEN RENO, Nev. (August 10, 2006)—From David Duval to Jason Day, the list of impressive players that are expected to play at the 2006 Reno-Tahoe Open continues to grow. Now its eighth year on the PGA TOUR, the 2006 Reno-Tahoe Open is scheduled for Aug. 21-27, 2006 at Montrêux Golf & Country Club in Reno, Nev. Forget the question “Who will I see if I come out to the Reno-Tahoe Open?” Tiger Woods and Phil Mickelson may be playing at the invitation only World Golf Championships, but more than 40 top players that have won PGA TOUR events including the British Open, PGA Championship, Buick Open, FBR Phoenix Open and Honda Classic will be at the Reno-Tahoe Open. “The players on the PGA TOUR love playing at the Reno-Tahoe Open and it shows with the strong field of players that have committed so far,” said Jim Kline, Reno-Tahoe Open tournament director. “The field is full of the brightest up and coming stars on TOUR like Jason Day and seasoned pros like Nick Price. It will be a great tournament that everyone should come out to watch.” Past PGA TOUR tournament winners scheduled to play at the 2006 Reno-Tahoe Open include: • Woody Austin • Dan Forsman • Neal Lancaster • John Senden • Cameron Beckman • Carlos Franco • Ian Leggatt • Heath Slocum • Notah Begay III • Brent Geiberger • Andrew Magee • Chris Smith • Mark Brooks • Bill Glasson • Len Mattiace • Paul Stankowski • Bob Burns • Matt Gogel • Blaine McCallister • Steve Stricker • Tom Byrum • Paul Goydos • Jim McGovern • Kevin Sutherland • Jose Coceres • Donnie Hammond • Larry Mize • Kirk Triplett • John Cook • J.P. -
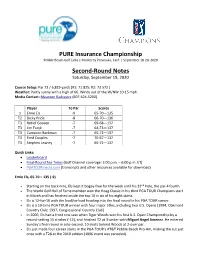
RD2 PURE Champ Notes
PURE Insurance Championship Pebble Beach Golf Links | Monterey Peninsula, Calif. | September 18-20, 2020 Second-Round Notes Saturday, September 19, 2020 Course Setup: Par 72 / 6,829 yards (R1: 71.825; R2: 72.572 ) Weather: Partly sunny with a high of 66. Winds out of the W/NW 10-15 mph. Media Contact: Maureen Radzavicz (607-624-5200) Player To Par Scores 1 Ernie Els -9 65-70—135 T2 Dicky Pride -8 66-70—136 T3 Retief Goosen -7 69-68—137 T3 Jim Furyk -7 64-73—137 T3 Cameron Beckman -7 65-72—137 T3 Fred Couples -7 70-67—137 T3 Stephen Leaney -7 65-72—137 Quick Links: • Leaderboard • Final-Round Tee Times (Golf Channel coverage: 3:00 p.m. – 6:00 p.m. ET) • PGATOURmedia.com (transcripts and other resources available for download) Ernie Els, 65-70 – 135 (-9) • Starting on the back nine, Els kept it bogey-free for the week until his 22nd hole, the par-4 fourth. • The World Golf Hall of Fame member won the Hoag Classic in his third PGA TOUR Champions start in March and has finished inside the top 10 in six of his eight starts. • Els is 12-for-16 with the lead/co-lead heading into the final round in his PGA TOUR career. • Els is a 19-time PGA TOUR winner with four major titles, including two U.S. Opens (1994, Oakmont Country Club; 1997, Congressional Country Club). • In 2000, Els had a front row seat when Tiger Woods won his first U.S. -

American Family Insurance University Ridge GC Second Round Groupings and Starting Times Saturday, June 12, 2021
American Family Insurance University Ridge GC Second Round Groupings and Starting Times Saturday, June 12, 2021 TEE # 1 8:55 Woody Austin Derby, KS 72 72 Rocco Mediate Greensburg, PA 72 72 Fred Funk Austin, TX 72 72 9:05 Paul Goydos Long Beach, CA 72 72 Vijay Singh Fiji Islands 72 72 Tom Byrum San Antonio, TX 72 72 9:15 Kirk Triplett Scottsdale, AZ 72 72 Ernie Els South Africa 72 72 Mike Weir Brights Grv, ON, Canada 72 72 9:25 John Senden Brisbane, Australia 71 71 Paul Broadhurst Nuneaton, England 71 71 Tom Gillis Lake Orion, MI 71 71 9:35 Willie Wood Edmond, OK 71 71 Scott Parel Augusta, GA 71 71 Marco Dawson Merritt Island, FL 71 71 9:45 Larry Mize Columbus, GA 70 70 Jay Haas Greenville, SC 70 70 Mark Brooks Fort Worth, TX 71 71 9:55 Dicky Pride Tuscaloosa, AL 70 70 Shane Bertsch Denver, CO 70 70 Stephen Leaney Perth, Australia 70 70 10:05 Kenny Perry Franklin, KY 70 70 Joe Durant Pensacola Beach, FL 70 70 Steve Flesch Union, KY 70 70 10:15 Bernhard Langer Munich, Germany 70 70 David Toms Shreveport, LA 70 70 Glen Day Alotian, AR 70 70 10:25 Scott Dunlap Sarasota, FL 69 69 Esteban Toledo Mexicali, Mexico 69 69 Steve Stricker Madison, WI 70 70 10:35 Rod Pampling Brisbane, Australia 69 69 Robert Karlsson Katrineholm, Sweden 69 69 Brandt Jobe Oklahoma City, OK 69 69 10:45 Colin Montgomerie Royal Troon, Scotland 68 68 Wes Short, Jr. Austin, TX 68 68 Ken Duke Stuart, FL 69 69 10:55 Fred Couples Newport Beach, CA 68 68 Retief Goosen Polokwane, South Africa 68 68 Ken Tanigawa Scottsdale, AZ 68 68 11:05 Miguel Angel Jiménez Malaga, Spain 65