Modelling of Personalised Landmarks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
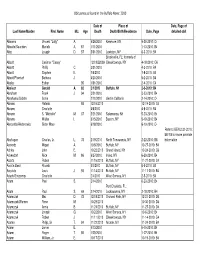
Obituaries Buffalo News 2010 by Name
Obituaries as found in the Buffalo News: 2010 Date of Place of Date, Page of Last Name/Maiden First Name M.I. Age Death Death/Birth/Residence Date, Page detailed obit Abbarno Vincent "Lolly" A. 9/26/2010 Kenmore, NY 9-30-2010: C4 Abbatte/Saunders Murielle A. 87 1/11/2010 1-13-2010: B4 Abbo Joseph D. 57 5/31/2010 Lewiston, NY 6-3-2010: B4 Brooksville, FL; formerly of Abbott Casimer "Casey" 12/19/22009 Cheektowaga, NY 4-18-2010: C6 Abbott Phillip C. 3/31/2010 4-3-2010: B4 Abbott Stephen E. 7/6/2010 7-8-2010: B4 Abbott/Pfoetsch Barbara J. 4/20/2010 5-2-2010: B4 Abeles Esther 95 1/31/2010 2-4-2010: C4 Abelson Gerald A. 82 2/1/2010 Buffalo, NY 2-3-2010: B4 Abraham Frank J. 94 3/21/2010 3-23-2010: B4 Abrahams/Gichtin Sonia 2/10/2010 died in California 2-14-2010: C4 Abramo Rafeala 93 12/16/2010 12-19-2010: C4 Abrams Charlotte 4/6/2010 4-8-2010: B4 Abrams S. "Michelle" M. 37 5/21/2010 Salamanca, NY 5-23-2010: B4 Abrams Walter I. 5/15/2010 Basom, NY 5-19-2010: B4 Abrosette/Aksterowicz Sister Mary 6/18/2010 6-19-2010: C4 Refer to BEN 2-21-2010: B6/7/8 for more possible Abshagen Charles, Jr. L. 73 2/19/2010 North Tonawanda, NY 2-22-2010: B8 information Acevedo Miguel A. 10/6/2010 Buffalo, NY 10-27-2010: B4 Achkar John E. -

Physician Directory NCB Health Professional by License And
NYC Health + Hospitals Physician Directory Corporate Finance NCB Updated as of March 25, 2016 Health Professional By License and NPI FACILITY NAME DOCTOR LAST NAME DOCTOR FIRST NAME NCB AAGAARD PHILIP NCB AARON ANDREA NCB ABADI JACOBO NCB ABADI MARIA NCB ABADIR DALE NCB ABADIRHALLOCK MICHELLE NCB ABAPO BLANCA NCB ABARCA FRANCISCO NCB ABARE MARCE NCB ABAYEVA IRINA NCB ABBADESSA BENJAMIN NCB ABBALEMATTEO DAVID NCB ABBAS NAEEM NCB ABBASOVA SABINA NCB ABBATEMATTEO DAVID NCB ABBIATI ROBERT NCB ABDELDAYEM HANEEN NCB ABDOU EMAD NCB ABDULAH DORINA NCB ABDULQUADER MOHAMMED NCB ABDURRAHEIM NURI NCB ABELARDO DEANDA NCB ABELL REBECCA Page 1 of 341 NYC Health + Hospitals Physician Directory Corporate Finance NCB Updated as of March 25, 2016 Health Professional By License and NPI FACILITY NAME DOCTOR LAST NAME DOCTOR FIRST NAME NCB ABESKHERON JOLLY NCB ABIAAD SIMON NCB ABISUGA OLAKUNLE NCB ABITBOL AGNES NCB ABITBOL AGNES NCB ABOAGYE ALEX NCB ABOGUNRIN GRACE NCB ABORDO ERIKA NCB ABRAHAM SAFER NCB ABRAHAM BINU NCB ABRAHAM AMI NCB ABRAMS KIM NCB ABRUZZOFOGARASSY MARY NCB ABUMEHLHA ADBULAZIZ NCB ACEVEDO DORA NCB ACEVEDO NATTASHA NCB ACEVEDO GLADYS NCB ACHARYA LOPAMUDRA NCB ACHARYA ANJALI NCB ACKER JESSICA NCB ACKERMAN NINA NCB ACOSTA NIVIA NCB ACOSTA ROBERT Page 2 of 341 NYC Health + Hospitals Physician Directory Corporate Finance NCB Updated as of March 25, 2016 Health Professional By License and NPI FACILITY NAME DOCTOR LAST NAME DOCTOR FIRST NAME NCB ACUNAVILLAORDUNA ANA NCB ADAMO ARTHUR NCB ADAMS HENRY NCB ADAMS MARIE NCB ADEBANJO OLUGBENGA NCB ADEOYE -

The Task Worth While; Or, the Divine Philosophy
JAN 27 1911 Mabie, Henry Clay, 1847- 1918. The t.^sT^ v7orth while; or The Task Worth While OR THE DIVINE PHILOSOPHY OF MISSIONS Xectuces Seminars /^^^^^ !.^'^'^^f, (1909-I9IOJ > JAN 27 1911 By Henry Clay Mabie, D. D. Formerly Corresponding Secretary of the American Baptist Foreign Mission Society Author of "In Brightest Asia," "Method in Soul-Winning," "The Meaning and Message of the Cross," " How Does thb Death of Christ Save Us?" "The Divine Right of Missions," etc. The Griffith & Rowland Press Philadelphia Boston Chicago St. Louis Copyright 1910 by A. J. ROWLAND, Secretary Published November, 1910 PREFACE The lectures which follow, except the last one, were given in full or in part by special invitation of the Theological Faculty's Union, in 1909-1910, before the following named institutions: Roch- ester Theological Seminary; University of Chi- cago Divinity School; Colgate Seminary, Hamil- ton, N. Y. ; MacMaster Seminary, Toronto, Cana- da ; Kansas City Seminary, Kan. ; Southwestern Seminary, Waco, Tex. ; Southern Baptist Theo- logical Seminary, Louisville, Ky. ; Crozer Theo- logical Seminary, Upland, Pa. ; and New^ton Theological Institution, Newton, Mass. Lectures III and VII were repeated before the Reformed Church Seminary, New Brunswick, N. J. The title and topics as named at the several institutions varied somewhat in form, although substantially the same material was used. For purposes of publication, however, it is thought the general title chosen is on the whole the fittest. The origin of the lectures themselves is com- VI PREFACE posite. They are based on long and careful first- hand study of the Holy Scriptures—the Divine Oracles themselves—rather than the thoughts of others about them. -

Original Research Research Letters
Journal of Hospital Medicine NO. MARCH 2018 3 VOL. 13 www.journalofhospitalmedicine.com An Official Publication of the Society of Hospital Medicine Original Research Review Numeracy, Health Literacy, Cognition, and 30-Day Proposed In-Training Electrocardiogram Readmissions among Patients with Heart Failure Interpretation Competencies for Undergraduate Madeline R. Sterling, et al. and Postgraduate Trainees Pavel Antiperovitch, et al. Do Combined Pharmacist and Prescriber Efforts on Medication Reconciliation Reduce ® Postdischarge Patient Emergency Department Choosing Wisely : Next Steps in Improving Healthcare Value Volume 13, Number 3, March 2018 13, Number 3, March Volume Visits and Hospital Readmissions? Michelle Baker, et al. Improving Quality of Care for Seriously Ill Patients: Opportunities for Hospitalists The TEND (Tomorrow’s Expected Number of Robin E. Fail and Diane E. Meier Discharges) Model Accurately Predicted the Number of Patients Who Were Discharged from ® the Hospital the Next Day Choosing Wisely : Things We Do Carl van Walraven and Alan J. Forster For No Reason Periprocedural Bridging Anticoagulation Derivation of a Clinical Model to Predict Unchanged Inpatient Echocardiograms Stacy A. Johnson and Joshua LaBrin Craig G. Gunderson, et al. In the Hospital Relationship between Hospital 30-Day Mortality In the Hospital: Series Introduction Rates for Heart Failure and Patterns of Early Inpatient Comfort Care Steven M. Ludwin and Sirisha Narayana Lena M. Chen, et al. Denah Joseph: “In the Hospital” Steven M. Ludwin and Sirisha Narayana Research Letters Primary Care Provider Preferences for Clinical Care Conundrum Communication with Inpatient Teams: One Size A Howling Cause of Pancytopenia Does Not Fit All Allison Casciato, et al. David Lawrence, et al Hospital Administrators’ Perspectives on Physician Perspectives in Hospital Medicine Engagement: A Qualitative Study Disruptive Physician Behavior: The Importance of Seppo T. -

Vol. 15, No. 3 November 2007
Cockaigne (In London Town) • Concert Allegro • Grania and Diarmid • May Song • Dream Children • Coronation Ode • Weary Wind of the West • Skizze • Offertoire • The Apostles • In The South (Alassio) • Introduction and Allegro • Evening Scene • In Smyrna • The Kingdom • Wand of Youth • HowElgar Calmly Society the Evening • Pleading • Go, Song of Mine • Elegy • Violin Concerto in B minor • Romance • Symphony No.2 •ournal O Hearken Thou • Coronation March • Crown of India • Great is the Lord • Cantique • The Music Makers • Falstaff • Carissima • Sospiri • The Birthright • The Windlass • Death on the Hills • Give Unto the Lord • Carillon • Polonia • Une Voix dans le Desert • The Starlight Express • Le Drapeau Belge • The Spirit of England • The Fringes of the Fleet • The Sanguine Fan • Violin Sonata in E minor • String Quartet in E minor • Piano Quintet in A minor • Cello Concerto in E minor • King Arthur • The Wanderer • Empire March • The Herald • Beau Brummel • Severn Suite • Soliloquy • Nursery Suite • Adieu • Organ Sonata • Mina • The Spanish Lady • Chantant • Reminiscences • Harmony Music • Promenades • Evesham Andante • Rosemary (That's for Remembrance) • Pastourelle • Virelai • Sevillana • Une Idylle • Griffinesque • Gavotte • Salut d'Amour • Mot d'Amour • Bizarrerie • O Happy Eyes • My Love Dwelt in a Northern Land • Froissart • Spanish Serenade • La Capricieuse • Serenade • The Black Knight • Sursum Corda • The Snow • Fly, Singing Bird • From the Bavarian Highlands • The Light of LifeNOVEMBER • King Olaf2007 Vol.• Imperial 15, No. -

"G" S Circle 243 Elrod Dr Goose Creek Sc 29445 $5.34
Unclaimed/Abandoned Property FullName Address City State Zip Amount "G" S CIRCLE 243 ELROD DR GOOSE CREEK SC 29445 $5.34 & D BC C/O MICHAEL A DEHLENDORF 2300 COMMONWEALTH PARK N COLUMBUS OH 43209 $94.95 & D CUMMINGS 4245 MW 1020 FOXCROFT RD GRAND ISLAND NY 14072 $19.54 & F BARNETT PO BOX 838 ANDERSON SC 29622 $44.16 & H COLEMAN PO BOX 185 PAMPLICO SC 29583 $1.77 & H FARM 827 SAVANNAH HWY CHARLESTON SC 29407 $158.85 & H HATCHER PO BOX 35 JOHNS ISLAND SC 29457 $5.25 & MCMILLAN MIDDLETON C/O MIDDLETON/MCMILLAN 227 W TRADE ST STE 2250 CHARLOTTE NC 28202 $123.69 & S COLLINS RT 8 BOX 178 SUMMERVILLE SC 29483 $59.17 & S RAST RT 1 BOX 441 99999 $9.07 127 BLUE HERON POND LP 28 ANACAPA ST STE B SANTA BARBARA CA 93101 $3.08 176 JUNKYARD 1514 STATE RD SUMMERVILLE SC 29483 $8.21 263 RECORDS INC 2680 TILLMAN ST N CHARLESTON SC 29405 $1.75 3 E COMPANY INC PO BOX 1148 GOOSE CREEK SC 29445 $91.73 A & M BROKERAGE 214 CAMPBELL RD RIDGEVILLE SC 29472 $6.59 A B ALEXANDER JR 46 LAKE FOREST DR SPARTANBURG SC 29302 $36.46 A B SOLOMON 1 POSTON RD CHARLESTON SC 29407 $43.38 A C CARSON 55 SURFSONG RD JOHNS ISLAND SC 29455 $96.12 A C CHANDLER 256 CANNON TRAIL RD LEXINGTON SC 29073 $76.19 A C DEHAY RT 1 BOX 13 99999 $0.02 A C FLOOD C/O NORMA F HANCOCK 1604 BOONE HALL DR CHARLESTON SC 29407 $85.63 A C THOMPSON PO BOX 47 NEW YORK NY 10047 $47.55 A D WARNER ACCOUNT FOR 437 GOLFSHORE 26 E RIDGEWAY DR CENTERVILLE OH 45459 $43.35 A E JOHNSON PO BOX 1234 % BECI MONCKS CORNER SC 29461 $0.43 A E KNIGHT RT 1 BOX 661 99999 $18.00 A E MARTIN 24 PHANTOM DR DAYTON OH 45431 $50.95 -

Cinematic Taganrog
Alexander Fedorov Cinematic Taganrog Moscow, 2021 Fedorov A.V. Cinematic Taganrog. Moscow: "Information for all", 2021. 100 p. The book provides a brief overview of full–length feature films and TV series filmed in Taganrog (taking into account the opinions of film critics and viewers), provides a list of actors, directors, cameramen, screenwriters, composers and film experts who were born, studied and / or worked in Taganrog. Reviewer: Professor M.P. Tselysh. © Alexander Fedorov, 2021. 2 Table of contents Introduction ……………………………………………………………………………………… 4 Movies filmed in Taganrog and its environs ………………………………………….. 5 Cinematic Taganrog: Who is Who…………………………….…………………………. 69 Anton Barsukov: “How I was filming with Nikita Mikhalkov, Victor Merezhko and Andrey Proshkin.………………………………………………… 77 Filmography (movies, which filmed in Taganrog and its surroundings)…… 86 About the Author……………………………………………………………………………….. 92 References ………………………………………………………………………………………… 97 3 Introduction What movies were filmed in Taganrog? How did the press and viewers evaluate and rate these films? What actors, directors, cameramen, screenwriters, film composers, film critics were born and / or studied in this city? In this book, for the first time, an attempt is made to give a wide panorama of nearly forty Soviet and Russian movies and TV series filmed in Taganrog and its environs, in the mirror of the opinions of film critics and viewers. Unfortunately, data are not available for all such films (therefore, the book, for example, does not include many documentaries). The book cites articles and reviews of Soviet and Russian film critics, audience reviews on the Internet portals "Kino –teater.ru" and "Kinopoisk". I also managed to collect data on over fifty actors, directors, screenwriters, cameramen, film composers, film critics, whose life was associated with Taganrog. -

Episode Guide
Last episode aired Monday May 21, 2012 Episodes 001–175 Episode Guide c www.fox.com c www.fox.com c 2012 www.tv.com c 2012 www.fox.com The summaries and recaps of all the House, MD episodes were downloaded from http://www.tv.com and processed through a perl program to transform them in a LATEX file, for pretty printing. So, do not blame me for errors in the text ^¨ This booklet was LATEXed on May 25, 2012 by footstep11 with create_eps_guide v0.36 Contents Season 1 1 1 Pilot ...............................................3 2 Paternity . .5 3 Occam’s Razor . .7 4 Maternity . .9 5 Damned If You Do . 11 6 The Socratic Method . 13 7 Fidelity . 15 8 Poison . 17 9 DNR ............................................... 19 10 Histories . 21 11 Detox . 23 12 Sports Medicine . 25 13 Cursed . 27 14 Control . 29 15 Mob Rules . 31 16 Heavy . 33 17 Role Model . 35 18 Babies & Bathwater . 37 19 Kids ............................................... 39 20 Love Hurts . 41 21 Three Stories . 43 22 Honeymoon . 47 Season 2 49 1 Acceptance . 51 2 Autopsy . 53 3 Humpty Dumpty . 55 4 TB or Not TB . 57 5 Daddy’s Boy . 59 6 Spin ............................................... 61 7 Hunting . 63 8 The Mistake . 65 9 Deception . 67 10 Failure to Communicate . 69 11 Need to Know . 71 12 Distractions . 73 13 Skin Deep . 75 14 Sex Kills . 77 15 Clueless . 79 16 Safe ............................................... 81 17 AllIn............................................... 83 18 Sleeping Dogs Lie . 85 19 House vs. God . 87 20 Euphoria (1) . 89 House, MD Episode Guide 21 Euphoria (2) . 91 22 Forever . -

Jigsaw Interim
JIGSAW INTERIM DAVID ALYN GORDON Copyright © 2021 by David Alyn Gordon All rights reserved. No part of this book may be reproduced in any form or by any electronic or mechanical means, including information storage and retrieval systems, without written permission from the author, except for the use of brief quotations in a book review. Created with Vellum JIGSAW INTERIM February 1, 1944 International Evangelical Hospital Voltri, Italy Noah’s condition was unchanged. His face remained fully covered in bandages from the surgery following what happened at the Operation Corvo lab. Lavonia had brought him to the abandoned hospital nearly three weeks before—following events at the Villa Delle Brignole—and he had yet to regain consciousness. The hospital itself had been bombed in 1942, and then deserted. But the bombs hadn’t destroyed everything, and what remained provided an ideal environment for Dr. Vincente D’Ambrosio to care for Noah. D’Ambrosio and Lavonia took turns watching over Noah. Elisabetta had become increasingly annoyed with the whole situation. “He’ll get us all killed,” she said on more than one occasion. Each time, Lavonia reviewed the letters from her future self, and then reassured Elisabetta that Noah would come around soon. On February 1, 1944, at 3:20 p.m., Lavonia made a point of being in Noah’s room when Dr. D’Ambrosio came to check on him. For the first time, Noah rolled over in bed. He woke a moment later, and screamed. An instant after that, he was full of questions. “Where am I? Why is it so dark? Why can’t I see?” “I’m here, my love,” Lavonia replied. -
Cass C Ity Chronicle
# CASS C ITY CHRONICLE VOLUME 28, NUMBER 42. CASS CITY, MICHIGAN, FRIDAY, JANUARY 26, 1934. EIGHT PAGES. NA HOi!RSARE ed upon by the president and Sales CHURCHES CHOOSE and Schmuk did likewise for the LENTEN THEMES NARRATIONSOF Elkton five. RgJRGNN!ON Hunt each sanl~ three sho,ts Irom MXCfMenKay~g%kt aItrrip%°~d~gre~nd- A straw vote is being taken this TUN LA week in the Presbyterian and Meth- the side court, while Kelley added cry foi~ a fu~her week's schooling i VOLLEYBALL RANKIN6 odist constituencies to determine 30GTOGENARIANI;two from mid-floor. MahaJ~g, Kil- FLAN APPFEOVED which will consist of a trip into the themes which will be studied bourn, Wallace and Tyo also scored the oil fields, discussions on oil in the vesper fellowship which for the locals, while Elkton's scor- Survey of Business Places in field operations, and a trip through Diaz Holds Top Position as meets each Sunday at five o'clock. In which Are Told Early Ex- ing was limited to three baskets by Cass City State Bank to the Lincoln up-to-date refinery at A check-list of twenty-five sub- Carr and six charity tosses by Five Villages Will I Robinson, II1., and three or four Other Teams Fall periences of Cass City Resume Regular Business jects has been prepared and circu- Hutchinson. days' schooling on salesmanship Back. Citizens. Cass City showed a strong de- Start Soon. land petroleum products, finishing lated among the adults of each March 12. church to guide the steering-com- fense, as they limited .the visiting team to five field goals. -
2019 Gratitude Report Craig A
Reverence • Innovation • Compassion • Community • Integrity • Excellence • Reverence Innovation • Compassion • Community • Integrity • Excellence • Reverence • Innovation Compassion • Community2019 • Integrity Gratitude • Excellence • Reverence Report • Innovation • Compassion Community • Integrity • ExcellenceLiving • Reverence Our Values• Innovation • Compassion • Community Integrity • Excellence • Reverence • Innovation • Compassion • Community • Integrity Continuing & Home Care Foundation • Kenmore Mercy Foundation • Mercy Hospital Foundation • Mount St. Mary’s Hospital Foundation • Sisters Hospital Foundation The Foundations of Catholic Health On behalf of the of Catholic Health, you are sharing in our Foundations of Catholic core values. Of course, your support helps fund important medical advances and Health, it is my honor to new technologies, which are so critical in present this 2019 Gratitude healthcare today. But you also give the Report highlighting our five gifts of empathy and kindness, of caring Foundations – Continuing and hope. & Home Care Foundation, Kenmore Mercy Foundation, We would like to express our heartfelt Mercy Hospital Foundation, thanks to our board members, physicians, Mount St. Mary’s Hospital associates, benefactors, and other Foundation and Sisters supporters who continually work together Hospital Foundation. to find creative solutions and strive for excellence in care. Your generous support of the Foundations enables our hospitals and care facilities to keep pace—and lead—in The Christian spirit of caring for one an ever-changing healthcare environment. Although this another has guided Catholic Health’s report celebrates the excellent work from 2019, I would healing ministry for more than 165 years. be remiss not to mention the tremendous outpouring Now, more than ever, our core values lead of support as Catholic Health has combated COVID-19 us forward. -

Faculty News
Volume 20 Article 16 Issue 2 ISC Centennial 1958 Faculty News Follow this and additional works at: https://lib.dr.iastate.edu/iowastate_veterinarian Part of the Veterinary Medicine Commons Recommended Citation (1958) "Faculty News," Iowa State University Veterinarian: Vol. 20 : Iss. 2 , Article 16. Available at: https://lib.dr.iastate.edu/iowastate_veterinarian/vol20/iss2/16 This Article is brought to you for free and open access by the Journals at Iowa State University Digital Repository. It has been accepted for inclusion in Iowa State University Veterinarian by an authorized editor of Iowa State University Digital Repository. For more information, please contact [email protected]. FACULT-Y NEWS ... Only One Dr. Chivers the student that proper restraint and con trol of livestock is necessary at all times for their safety as practitioners of veteri nary medicine. Dr. Chivers returned to Iowa State College in 1939. For 9 years he served as the ambulatory clinician for the veteri nary clinic. During this time he worked at various problems confronting the vet erinary profession and for which very little was known or they did not have a good treatment for. One of these was calf enteritis. This was before antibiotics were available and many of the infected calves would die within a short time after birth. Dr. Chivers found that whole blood transfusions from the dam soon after parturition greatly decreased the mor tality rate. In 1948 Dr. Chivers transferred to the Department of Surgery. After clinics each day, he continued to work on disease Doctor Chivers, large animal clinician, conditions which he was confronted with, relaxing at home_ trying to find a better surgical procedure or treatment.