Lecture @DHBW: Data Warehouse 04 Modeling Andreas Buckenhofer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Top 40 Singles Top 40 Albums
16 December 2001 CHART #1290 Top 40 Singles Top 40 Albums FALLIN' GET THE PARTY STARTED THE RECORD INTERNATIONAL SUPER HITS 1 Alicia Keys 21 Pink 1 Bee Gees 21 Green Day Last week 1 / 15 weeks Gold / BMG Last week 22 / 5 weeks BMG Last week 3 / 3 weeks Platinum / UNIVERSAL Last week 30 / 6 weeks Gold / WARNER EVERYWHERE QUEEN OF MY HEART SWING WHEN YOU'RE WINNING WHOA NELLY 2 Michelle Branch 22 Westlife 2 Robbie Williams 22 Nelly Furtado Last week 11 / 7 weeks WARNER Last week 23 / 4 weeks BMG Last week 1 / 4 weeks Platinum x3 / CAPITOL/EMI Last week 20 / 35 weeks Platinum x2 / UNIVERSAL CAN'T GET YOU OUT OF MY HEAD 1+1+1 (IT AIN'T TWO) ECHOES - THE BEST OF COLLECTION 3 Kylie Minogue 23 K'Lee 3 Pink Floyd 23 Tracy Chapman Last week 3 / 11 weeks Gold / FMR Last week 17 / 9 weeks UNIVERSAL Last week 2 / 5 weeks Platinum x2 / CAPITOL/EMI Last week 21 / 7 weeks Platinum / WARNER EMOTION FAMILY AFFAIR MY GIFT TO YOU ULTIMATE CAT STEVENS 4 Destiny's Child 24 Mary J Blige 4 Hayley Westenra 24 Cat Stevens Last week 2 / 10 weeks COL/SONY Last week 33 / 4 weeks UNIVERSAL Last week 9 / 3 weeks Platinum / UNIVERSAL Last week 15 / 2 weeks Platinum x3 / UNIVERSAL STARLIGHT ALL IT TAKES TUSCAN SKIES DREAMING 5 The Superman Lovers 25 Stellar 5 Andrea Bocelli 25 Andre Rieu Last week 4 / 15 weeks BMG Last week 26 / 17 weeks EPIC/SONY Last week 10 / 7 weeks Platinum / UNIVERSAL Last week 36 / 2 weeks UNIVERSAL TOO CLOSE YOUTHFUL ROTTEN APPLES - GREATEST HIT.. -

Sexion Q 3-14
www.ExpressGayNews.com • June 17, 2002 Q1 CYMK CoverCover StoryStory Even though her astonishing voice makes it seem predestined, stardom has been a long time coming for Anastacia. The Chicago-born diva went through many start-and-stop career moments before her chops were recognized. She traipsed along the edge of the music world as a backup dancer and upscale hair salon receptionist for years with her biggest talent going unrecognized, mostly because nobody could quite figure out what to do with her. She was ready to give up until an appearance on the now-defunct MTV talent show The Cut gave her the chance to shine. Although she didn’t win top prize on the show, the budding vocalist did scoop up a record deal and recognition from the likes of pop superstar Michael Jackson and megaproducer David Foster. Now, she has finally earned her stripes after years of honing her sound and gaining a massive European follow- ing. Her debut album, Not That Kind, (See ANASTACIA on page Q9) Q2 www.ExpressGayNews.com • June 17, 2002 CYMK InIn ReviewReview The first clue that Nixon’s Nixon is not fact that the Kennedys were assassinated or The funniest scenes are when Nixon that they are watching the real thing. His supposed to be historically accurate is that else they would be stuck with the whole goads Kissinger into playacting conversations performance is so dead on that it makes you there are 68 stars on the American flag that Vietnam mess and toy with the idea of starting with Brezhnev and Mao Tse Tung. -

Anastacia Not That Kind Mp3, Flac, Wma
Anastacia Not That Kind mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Electronic / Funk / Soul / Pop Album: Not That Kind Country: Asia Released: 2000 Style: Rhythm & Blues, Downtempo MP3 version RAR size: 1246 mb FLAC version RAR size: 1454 mb WMA version RAR size: 1884 mb Rating: 4.6 Votes: 518 Other Formats: AAC DTS XM RA MP1 VQF ASF Tracklist Hide Credits Not That Kind Arranged By – Ric Wake, Richie JonesArranged By [Backing Vocals] – Anastacia, BeBe 1 WinansBacking Vocals – BeBe WinansDrums – Richie JonesEngineer [Mix Assistant 3:20 Engineer] – Joe ErnstGuitar – Eric KupperGuitar [Guitar Solo] – Chris GoerckeRecorded By [Vocals] – Thomas R. YezziWritten-By – Marvin Young, Will Wheaton I'm Outta Love 2 4:03 Drums – Louis Biancaniello, Sam WattersGuitar – Vernon Black 3 Cowboys & Kisses 4:41 4 Who's Gonna Stop The Rain 5:00 Love Is Alive Backing Vocals – Audrey L. Wheeler*, Keith Fluitt, Nicky Richards*, Rob MathesEngineer [Assistant] – Chris Brooke, Jim Annunziatto*, Ron Last, Ryan HewittEngineer [Pro-tools] – Jim Annunziatto*Guitar, Keyboards – Russ DeSalvoOrgan [Hammond B-3] – Loris 5 HollandPiano – Leon PendarvisProducer [Additional Production] – Richie JonesProducer 4:06 [Production Coordinator] – David Barratt Programmed By [Additional Programming] – Pat Carroll*, Russ DeSalvoProgrammed By [Percussion], Drum Programming – Richie JonesRecorded By [Lead Vocals Assistant Recorder] – Dave PolerRecorded By [Track] – Bob Cadway, Dan HetzelWritten-By – Gary Wright I Ask Of You 6 4:27 Guitar – Chris Camozzi Wishing Well Arranged By -

SOUL ASYLUM Biography by Arthur Levy
SOUL ASYLUM biography by Arthur Levy “It’s a crazy mixed up world out there, Someone’s always got a gun and it’s all about money You live with loneliness, or you live with somebody who’s crazy It’s just a crazy mixed up world …” (“Crazy Mixed Up World”) Chapter 1. Every Cloud Has One Renewed and revitalized, Soul Asylum founders Dave Pirner and Dan Murphy return to rock’s front line with THE SILVER LINING, their first new studio release since 1998’s Candy From a Stranger. That album inadvertently kicked off a seven-year sabbatical for the group, which telescoped into the death of bassist Karl Mueller in June 2005, the other founding member of the triumvirate that has steered Soul Asylum through rock’s white water for the past two decades plus. The re-emergence of the group on THE SILVER LINING is as much a reaffirmation of Soul Asylum’s commitment to the music as it is a dedication to Karl, who worked and played on the album right up until the end. They were joined in the studio by not-so-new heavyweight Minneapolis drummer Michael Bland (who has played with everyone from Paul Westerberg to Prince). The band is now complemented by Tommy Stinson on bass, a member of fellow Twin Cities band the Replacements since age 13, and a pal of Dan’s since he was in high school and Tommy in junior high. Tommy was the only friend that Karl could endorse to replace himself in the band. This hard-driving lineup was introduced for the first time in October 2005, when they played sold-out showcase dates at First Avenue in Minneapolis and the Bowery Ballroom in New York – within three days. -

2021-04-03 Press Release Margie Evans
April 3, 2021 OFFICIAL PRESS RELEASE MARGIE EVANS, ICONIC AND SOPHISTICATED QUEEN OF THE BLUES, DIES AT 81 Dateline: Shreveport, Louisiana, April 3, 2021 Margie Evans, a legendary, international Blues and Gospel entertainer, songwriter, music producer, actress, music historian, community activist and motivational spokeswoman, who broke barriers for African American female Blues performers with poise, dignity and sophistication, died on March 19, 2021. In addition to her musicianship, Evans is noted as an activist for parity in music education as well as a promoter of the legacy of Blues music. As she often said, “I’ve been around a long time and I’ve really paid my dues.” She was age of eighty-one. A family statement did not reveal the cause of death. The lengthy career of the unsung, effervescent entertainer is chronicled in her first biographical memoir, “Margie Evans: The Classy, Sophisticated Queen of the Blues, due for release on Amazon in two weeks. In all of her endeavors, Evans embodied African American women of courage, faith and wisdom who demanded respect. In each of her acting roles, radio commercials, iconic albums and international tours, she represented complex, decisive women, articulating a profound grace, depth, perseverance and dignity in each of her performances. Marjorie Ann Johnson was born in 1939 in Shreveport, Louisiana, in the United States. She chose to be known as Margie. Raised as a devout Christian, Margie Evans’ early exposure to music was through gospel, inspired by her mother, Mrs. Veva Williams, who taught Latin and piano. After graduating from Grambling College, majoring in elementary education, in 1958, Margie moved to Los Angeles, where she later married her longtime friend and neighbor, Rev. -
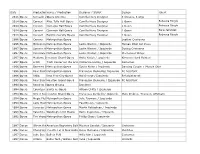
Date Production Name Venue / Production Designer / Stylist Design
Date ProductionVenue Name / Production Designer / Stylist Design Talent 2015 Opera Komachi atOpera Sekidrera America Camilla Huey Designer 3 dresses, 3 wigs 2014 Opera Concert Alice Tully Hall Opera Camilla Huey Designer 1 Gown Rebecca Ringle 2014 Opera Concert Carnegie Hall Opera Camilla Huey Designer 1 Gown Rebecca Ringle 2014 Opera Concert Carnegie Hall Opera Camilla Huey Designer 1 Gown Sara Jakubiak 2013 Opera Concert Bard University Opera Camilla Huey Designer 1 Gown Rebecca Ringle 1996 Opera Carmen Metropolitan Opera Leather Costumes 1996 Opera Midsummer'sMetropolitan Night's Dream Opera Leslie Weston / Izquierdo Human Pillar Set Piece 1997 Opera Samson & MetropolitanDelilah Opera Leslie Weston / Izquierdo Dyeing Costumes 1997 Opera Cerentola Metropolitan Opera Leslie Weston / Izquierdo Mechanical Wings 1997 Opera Madame ButterflyHouston Grand Opera Anita Yavich / Izquierdo Kimonos Hand Painted 1997 Opera Lillith Tisch Center for the Arts OperaCatherine Heraty / Izquierdo Costumes 1996 Opera Bartered BrideMetropolitan Opera Sylvia Nolan / Izquierdo Dancing Couple + Muscle Shirt 1996 Opera Four SaintsMetropolitan In Three Acts Opera Francesco Clemente/ Izquierdo FC Asssitant 1996 Opera Atilla New York City Opera Hal George / Izquierdo Refurbishment 1995 Opera Four SaintsHouston In Three Grand Acts Opera Francesco Clemente / Izquierdo FC Assistant 1994 Opera Requiem VariationsOpera Omaha Izquierdo 1994 Opera Countess MaritzaSanta Fe Opera Allison Chitty / Izquierdo 1994 Opera Street SceneHouston Grand Opera Francesca Zambello/ Izquierdo -

High Society 2
HIGH SOCIETY Written by Noga Pnueli October 2019 INT. ESTEE’S HOUSE - KITCHEN - NIGHT Jacksboro, Texas. Population 1,311. A neglected old family home. Looks like a family lived here twenty years ago, but no longer does. ESTEE, 30’s, is what is locally referred to as a LIFER, aka a woman who never left her pathetic hometown and whose wasted potential has made a home atop her shoulders like a ton of bricks. She is currently avoiding her existential woes by baking complicated SOURDOUGH RYE BREAD in her kitchen. She looks small in the big empty house, like a child whose parents never came back home. She wears an old pajama dress full of holes from years of use. She places all the baking ingredients on the table, and starts bringing them to life like a mad conductor. Flour, yeast, sugar, eggs -- a congregation of disparate materials, manipulated into one cohesive, smooth, harmonious ball of dough in her skilled hands. (AND YES THIS IS A METAPHOR FOR LATER, THANKS FOR ASKING.) She puts her full arm strength into it, exorcising her demons into the dough. (They say the demons make it rise faster.) She dumps the dough into a bowl, puts a wet towel over it to let it rise. Finished, she slumps into a chair and chugs from a bottle of bourbon. Just a casual low-key small sip. Then another. Then another. Then another. INT. ESTEE’S HOUSE - BEDROOM - LATER Estee lies spread out in bed, drunk. Her sheets look childish, like she’s been using them since she was a teen. -

DJ – Titres Incontournables
DJ – Titres incontournables Ce listing de titres constamment réactualisé , il vous ait destiné afin de surligner avec un code couleur ce que vous préférez afin de vous garantir une personnalisation totale de votre soirée . Si vous le souhaitez , il vaut mieux nous appeler pour vous envoyer sur votre mail la version la plus récente . Vous pouvez aussi rajouter des choses qui n’apparaissent pas et nous nous chargeons de trouver cela pour vous . Des que cette inventaire est achevé par vos soins , nous renvoyer par mail ce fichier adapté à vos souhaits 2018 bruno mars – finesse dj-snake-magenta-riddim-audio ed-sheeran-perfect-official-music-video liam-payne-rita-ora-for-you-fifty-shades-freed luis-fonsi-demi-lovato-echame-la-culpa ofenbach-vs-nick-waterhouse-katchi-official-video vitaa-un-peu-de-reve-en-duo-avec-claudio-capeo-clip-officiel 2017 amir-on-dirait april-ivy-be-ok arigato-massai-dont-let-go-feat-tessa-b- basic-tape-so-good-feat-danny-shah bastille-good-grief bastille-things-we-lost-in-the-fire bigflo-oli-demain-nouveau-son-alors-alors bormin-feat-chelsea-perkins-night-and-day burak-yeter-tuesday-ft-danelle-sandoval calum-scott-dancing-on-my-own-1-mic-1-take celine-dion-encore-un-soir charlie-puth-attention charlie-puth-we-dont-talk-anymore-feat-selena-gomez clean-bandit-rockabye-ft-sean-paul-anne-marie dj-khaled-im-the-one-ft-justin-bieber-quavo-chance-the-rapper-lil-wayne dj-snake-let-me-love-you-ft-justin-bieber enrique-iglesias-subeme-la-radio-remix-remixlyric-video-ft-cnco feder-feat-alex-aiono-lordly give-you-up-feat-klp-crayon -

Ringo Starr & Anastacia
KultourZeit Das Eventmagazin für Zwickau Nr. 01/2018 S. 03 Pyromasters: beliebte Open-Air Show ist zurück S. 06 Festwoche zum 900-jährigen Stadtjubiläum Festival of Lights S. 07 Ostertanz im Big Band Im Festjahr Weltstars in der Stadthalle: Sound für Tanzbegeisterte Ringo Starr & Anastacia m 17.06.2018 werden „Ringo Mit über 30 Millionen verkauften Tonträ- Starr And His All Starr Band“ gern zählt Anastacia längst als Weltstar. Lokal werben A die Stadthalle zum Beben Doch sie hatte es nicht immer leicht. Zwei- bringen. Die Sitzplätze waren mal bekam sie die Diagnose Krebs gestellt, Kundenansprachen und Informationen der innerhalb weniger Tage ausverkauft. ließ sich davon jedoch nicht unterkriegen Region über moderne Medien im öffentli- Verständlich, denn immerhin handelt und bewies, dass ihr Wille stärker ist als chen Raum zielgerichtet und aktuell zu ver- es sich um den ehemaligen Schlag- die Krankheit. Ihre 2003 ins Leben gerufe- breiten, dafür steht die Zwickauer Agentur zeuger der ersten Boyband der Welt – ne Stiftung „Anastacia Fund“ unterstützt Comedia Concept. Neben klassischen „Out of der Beatles. Frauen im Kampf gegen Krebs, macht Home“-Medien bietet sie ihren Kunden mitt- ihnen Mut und ruft zu Vorsorgeuntersu- lerweile an hochfrequentierten Standorten Ringo Starr kommt nicht allein, sondern chungen auf. Der Popstar sammelt regel- moderne LED-Großbildschirme als Branchen- mit seiner All Starr Band, welche bereits mäßig Spenden, welche in die Stiftung fenster der Region an, wo neben Stadtnews, für andere internationale Künstler wie und zum Teil in die Krebsforschung fließen. Wetter, Kultur- und Freizeittipps ebenso Clips Santana, Toto und Jorney spielte. Erleben Anastacia ist zurück mit ihrem siebten regionaler Unternehmen werbewirksam Sie eine einzigartige Mischung aus den Studioalbum „Evolution“ und feiert dies auf aufgeschaltet werden. -

African Tongues in Our Mouths: Their Role in African-Centred Psychology
African Tongues in Our Mouths: Their Role in African-Centred Psychology Vera L. Nobles ORCID iD: https://orcid.org/0000-0002-5174-3328 Roberta M. Federico ORCID iD: https://orcid.org/0000-0003-1328-2580 Abstract This paper discusses the importance of language in the development of a Pan African Black Psychology. The article demonstrates how recognizing and honouring the ‘African Tongues in our Mouths’ (Ebonics and BaNtu Portuguese) are both acts of retention and resistance to dehumanization and are essential and valuable to the restoration of healing and wellness for African (continental and diaspora) people and practitioners. Keywords: Linguistic, African Psychology, African Diaspora, Pan African Psychology Alternation 27,1 (2020) 50 – 66 50 Print ISSN 1023-1757; Electronic ISSN: 2519-5476; DOI https://doi.org/10.29086/2519-5476/2020/v27n1a4 The Role of African Tongues in African-Centered Psychology Izilimi zase-Afrika Emilonyeni Yethu: Iqhaza Lazo Kusifundongqondo Ngengxilabu-Afrika Vera L. Nobles ORCID iD: https://orcid.org/0000-0002-5174-3328 Roberta M. Federico ORCID iD: https://orcid.org/0000-0003-1328-2580 Iqoqa Leli phepha lixoxa ngokubaluleka kwezilimi ekwakhiweni kobumbano lwama-Afrika ansundu esifundongqondo. Iphepha likhombisa ukuthi ukubhekelela kanye nokuhlonipha izilimi zase-Afrika emilonyeni yethu (ama- Ebonics kanye nabantu abangamaPutukezi) kokubili kuba kanjani yizindlela zokugcina kanye nokulwa nokwehliswa isithunzi; kanti kubalulekile futhi kunosizo ekubuyiseni ukwelapha kanye nempilo yabantu base-Afrika (abazinze e-Afrika nabahlala phesheya kwezilwandle) kanye nabasebenzi bolimi. Amagama asemqoka: ucwaningozilimi, isifundongqondo ngobu-Afrika, abantu base-Afrika abahlala phesheya kwezilwandle, ubumbano lwesifundongqondo nge-Afrika 51 Vera L. Nobles & Roberta M. Federico Figure 1: Escrava Anastacia, circa the 1740s. -

Dan Blaze's Karaoke Song List
Dan Blaze's Karaoke Song List - By Artist 112 Peaches And Cream 411 Dumb 411 On My Knees 411 Teardrops 911 A Little Bit More 911 All I Want Is You 911 How Do You Want Me To Love You 911 More Than A Woman 911 Party People (Friday Night) 911 Private Number 911 The Journey 10 cc Donna 10 cc I'm Mandy 10 cc I'm Not In Love 10 cc The Things We Do For Love 10 cc Wall St Shuffle 10 cc Dreadlock Holiday 10000 Maniacs These Are The Days 1910 Fruitgum Co Simon Says 1999 Man United Squad Lift It High 2 Evisa Oh La La La 2 Pac California Love 2 Pac & Elton John Ghetto Gospel 2 Unlimited No Limits 2 Unlimited No Limits 20 Fingers Short Dick Man 21st Century Girls 21st Century Girls 3 Doors Down Kryptonite 3 Oh 3 feat Katy Perry Starstrukk 3 Oh 3 Feat Kesha My First Kiss 3 S L Take It Easy 30 Seconds To Mars The Kill 38 Special Hold On Loosely 3t Anything 3t With Michael Jackson Why 4 Non Blondes What's Up 4 Non Blondes What's Up 5 Seconds Of Summer Don't Stop 5 Seconds Of Summer Good Girls 5 Seconds Of Summer She Looks So Perfect 5 Star Rain Or Shine Updated 08.04.2015 www.blazediscos.com - www.facebook.com/djdanblaze Dan Blaze's Karaoke Song List - By Artist 50 Cent 21 Questions 50 Cent Candy Shop 50 Cent In Da Club 50 Cent Just A Lil Bit 50 Cent Feat Neyo Baby By Me 50 Cent Featt Justin Timberlake & Timbaland Ayo Technology 5ive & Queen We Will Rock You 5th Dimension Aquarius Let The Sunshine 5th Dimension Stoned Soul Picnic 5th Dimension Up Up and Away 5th Dimension Wedding Bell Blues 98 Degrees Because Of You 98 Degrees I Do 98 Degrees The Hardest -

T.G.I.F.|Tgif
2014/10/3 Kickit Step Sheet - T.G.I.F.|TGIF T.G.I.F. (a.k.a. TGIF) Choreographed by Jo Thompson & Michele Perron Description: 32 count, 4 wall, high intermediate hustle line dance Music: Just Got Paid by NSync [114 bpm / No Strings Attached] Working Day And Night by Michael Jackson [138 bpm / Off The Wall] She's A Bad Mama Jama by Carl Carlton [Carl Carlton] Never Make Your Move Too Soon by Tom Principato [116 bpm / CD: I Know What You're Thinkin'...] Finally by Ce Ce Peniston [CD: 20th Century Masters - The Millennium Collection: The Best of CeCe Peniston / Finally / Available on iTunes] I'm Outta Love by Anastacia [119 bpm / CD Single / Not That Kind / Now 47 / Available on iTunes] Fever by Jeff Moore [120 bpm / Line Dance Fever] The Hustle by Scooter Lee [112 bpm / CD: By Request / Available on iTunes] Pop That Koochie by Eddie Holloway [CD: Soul N' the Blues: The Greatest Hits / Hollerin' & Poppin' / Available on iTunes] Choreographed at Cowichan Goes Country, Vancouver Island, BC (May 2000). Special Thanks to Rhonda and Randy Shotts for their input SIDE, BEHIND AND ACROSS: REPEAT (HUSTLE VINE); SIDE-TOGETHER-ACROSS 1-2 Step right side, cross left behind &3 Step right side, cross left over 4-5 Step right side, cross left behind &6 Step right side, cross left over 7&8 Step right side, step left together, cross right over TURN, TURN, CROSSING TRIPLE, SIDE-TOGETHER-ACROSS, STEP AND 'POSE' 1-2 Turn ¼ right and step left back, turn ¼ right and step right side (6:00) 3&4 Crossing chassé left-right-left 5&6 Step right side, step left together, cross right over 7&8 Turn ¼ right and step left back, step right back, touch left forward (9:00) Left heel lifted, both knees bent, as if in a sit position.