Fuzzing Apache Openoffice an Approach to Automated Black-Box Security Testing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Protocol About Delivered Software Tools
P170526 Protocol about delivered software tools Assessment of Suitable Flood Mitigation Measures (based on Dukniskhevi River Extreme Flood Analysis) in Tbilisi, Georgia CTCN REFERENCE NUMBER: 2016000043 Document Information Date 30.07.2018 HYDROC project no. P170526 HYDROC responsible Juan Fernandez Client CTC-N/UNIDO Reference No. 2016000043 Project No. Credit No. Contact HYDROC GmbH Siegum 4 24960 Siegum Germany Tel - +49 172 450 91 49 Email - [email protected] Contents 1. Introduction .................................................................................................................................. 1 2. Delivered Software Tools .............................................................................................................. 1 2.1. Apache OpenOffice 4.1.5 ...................................................................................................... 2 2.2. QGIS-OSGeo4W-3.0.2-1-Setup-x86_64.exe .......................................................................... 3 2.3. ArcHydro ............................................................................................................................... 4 2.4. HEC-GeoHMS ........................................................................................................................ 5 2.5. HEC-DSSVue .......................................................................................................................... 6 2.6. HEC-HMS 4.2.1 ..................................................................................................................... -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Richard Stallman
THE FIGHT FOR FREEDOM Free Software isn’t just about getting shiny new programs for no cash – it’s part of a much larger social movement. Mike Saunders and Graham Morrison explore the history and future of FOSS. here’s a problem with the word ‘free’. Software didn’t just pop up as an idea one day, as a Specifically, it can refer to something that “wouldn’t it be cool” notion from some hackers in a Tcosts no money, or something that isn’t held pub. The principles behind Free Software go back to down by restrictions – in other words, something the early days of computing, and many people have that has liberty. This difference is crucial when we fought long and hard to protect freedom in talk about software, because free (as in cost) computing, even when all hope looked lost. software doesn’t necessarily give you freedom. So this issue we want to delve deep into the world There are plenty of no-cost applications out there of Free Software: where exactly did it come from, that spy on you, steal your data, and try to lock you why is it important, and what challenges are ahead. in to specific file formats. And you certainly can’t get We also look at the differences in licences, one of the source code to them. the thorniest issues in FOSS, especially when people To make the distinction clearer, many people refer have different definitions of “free”. But let’s start by to free (as in liberty) software as a proper noun: Free going back to the early days of computing, when the Software. -

Where to Get Apache Openoffice?
What is Apache OpenOffice? Where to get Apache OpenOffice? Apache OpenOffice is the leading open-source The most recent version of Apache OpenOffice for office software suite for word processing, Windows, Linux, and OS X, in many languages, can spreadsheets, presentations, graphics, databases be downloaded from and more. It is available in many languages and http://www.openoffice.org/download/ works on all common computers. Other language versions can also be downloaded It stores all your data in an international open from standard format and can also read and write files from other common office software packages. It can http://www.openoffice.org/download/ The complete Office Suite be downloaded and used completely free of charge Versions for Solaris, OS/2, FreeBSD, a portable for any purpose. Windows version as well as other less well known Supported Operating Systems: versions produced by the partners of the OpenOffice Community can be downloaded from Windows IBM OS/2 http://www.openoffice.org/porting/ Free for private and business use! Linux OS X FreeBSD Solaris Need help with Apache OpenOffice? Word Processor Apache OpenOffice Portable: You can obtain help with Apache OpenOffice on the A portable version of OpenOffice exists for English language Forum: Spreadsheets Windows. This allows you to move your favourite http://forum.openoffice.org/en/forum/ Presentations Office suite from computer to computer on a handy USB key. Vector drawing You can also subscribe to the English language Apache OpenOffice: mailing list for Apache OpenOffice to obtain help Formula editor Support for Open Document (ODF) formats, • from other users by email Database which allows free interchange of documents [email protected] across operating systems. -

82103 QP Code:59232 Time : 2 ½ Hours Total Marks: 75
F.Y.B.Sc. Computer Science Semester - I (C:75:25) Solution Set - December 2018 (03/12/2018) Subject Code: 82103 QP Code:59232 Time : 2 ½ Hours Total Marks: 75 Q1 Attempt All(Each of 5 marks) (15) a) Multiple Choice Questions 1) GPL stands for _______ i) Generle Public License ii) General Public License iii) Generic Public License iv) General Private License 2) Which of the following is not a phase of Life Cycle Paradigm / waterfall model? i) Analysis ii) Manufacturing iii) Design iv) Coding 3) _________ is the founder of FSF i) Richard Stallman ii) Denis Ritchie iii) Ken Thomson iv) All of these 4) __________ is a form of licensing in which an author surrenders some but not all rights under copyright law i) Copydown ii) License iii) Copyleft iv) Patent 5) The term BSD stands for ______________ i) Binary software distribution ii) Berkley software distribution iii) Binary software development iv) Berkley software development b) Fill in the blanks (Waterfall model, full, internationalization, Prototyping model, Firefox, localization, chrome, free hardware design, partial, open source software) 1) Waterfall model is a static, sequential and procedural approach in software engineering methodology. 2) full copyleft is when all parts of work can be modified by consecutive authors. 3) localization is the process of adapting software for a specific region or language by adding locale-specific components and translating text. 4) Firefox is a web browser project descended from Mozilla application suite. 5) free hardware design refers to design which can be freely copied, distributed, modified and manufactured. c) Short Answers: 1) What is free software? Ans: Free software or libre software is computer software distributed under terms that allow users to run the software for any purpose as well as to study, change, and distribute it and any adapted versions. -
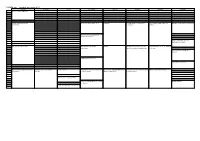
FOSDEM 2013 Schedule
FOSDEM 2013 - Saturday 2013-02-02 (1/9) Janson K.1.105 Ferrer Chavanne Lameere H.1301 H.1302 H.1308 10:30 Welcome to FOSDEM 2013 10:45 11:00 How we made the Jenkins QEMU USB status report 2012 Rockbuild The neat guide to Fedora RPM LinuxonAndroid and SlapOS on Wayland for Application Developers community Packaging Android 11:15 11:30 CRIU: Checkpoint and Restore (mostly) In Userspace 11:45 Ubuntu Online Accounts for application developers 12:00 The Devil is in the Details Vtrill: Rbridges for Virtual PTXdist Building RPM packages from Git Emdedded distro shootout: buildroot Networking repositories with git-buildpackage vs. Debian Better software through user 12:15 research 12:30 Bringing Xen to CentOS-6 Sketching interactions 12:45 13:00 The Open Observatory of Network Porting Fedora to 64-bit ARM Coding Goûter A brief tutorial on Xen's advanced Guacamayo -- Building Multimedia Package management and creation ARM v7 State of the Body ↴ Interference systems security features Appliance with Yocto ↴ in Gentoo Linux ↴ 13:15 Spoiling and Counter-spoiling 13:30 oVirt Live Storage Migration - Under Modern CMake ↴ the Hood ↴ ZONE: towards a better news feed ↴ 13:45 FOSDEM 2013 - Saturday 2013-02-02 (2/9) H.1309 H.2213 H.2214 AW1.120 AW1.121 AW1.125 AW1.126 Guillissen 10:30 10:45 11:00 Metaphor and BDD XMPP 101 Storytelling FLOSS Welcome and Introduction The room open() process Scripting Apache OpenOffice: Welcome to the Perl d… Introductory Nutshell Programs Inheritance versus Roles (Writer, Calc, Impress) 11:15 Signal/Collect: Processing Large -

How and Why Has the Libreoffice Project Evolved?
The Journal of Systems and Software 89 (2014) 128–145 Contents lists available at ScienceDirect The Journal of Systems and Software j ournal homepage: www.elsevier.com/locate/jss Sustainability of Open Source software communities beyond a fork: ଝ How and why has the LibreOffice project evolved? ∗ Jonas Gamalielsson , Björn Lundell University of Skövde, P.O. Box 408, SE-541 28 Skövde, Sweden a r t i c l e i n f o a b s t r a c t Article history: Many organisations are dependent upon long-term sustainable software systems and associated com- Received 19 October 2012 munities. In this paper we consider long-term sustainability of Open Source software communities in Received in revised form 7 November 2013 Open Source software projects involving a fork. There is currently a lack of studies in the literature that Accepted 8 November 2013 address how specific Open Source software communities are affected by a fork. We report from a study Available online 21 November 2013 aiming to investigate the developer community around the LibreOffice project, which is a fork from the OpenOffice.org project. In so doing, our analysis also covers the OpenOffice.org project and the related Keywords: Apache OpenOffice project. The results strongly suggest a long-term sustainable LibreOffice commu- Open Source software Fork nity and that there are no signs of stagnation in the LibreOffice project 33 months after the fork. Our analysis provides details on developer communities for the LibreOffice and Apache OpenOffice projects Community evolution and specifically concerning how they have evolved from the OpenOffice.org community with respect to project activity, developer commitment, and retention of committers over time. -

Z/OS Hybrid Batch Processing: Generating a Multi-Page PDF Document with Co:Z
Co:Z Co-Processing Toolkit z/OS Hybrid Batch Processing: Generating a multi-page PDF document with Co:Z V 1.0 Edition Published April, 2012 Copyright © 2012 Dovetailed Technologies, LLC Introduction A common function required by enterprise application software is to generate PDF documents tailored with data obtained from corporate databases. This function has at least the following inputs: a template PDF, and a data set of customer information. The output is a large PDF document with a page (or a few pages) for each customer, merged with the customer data. This function can require significant memory and CPU resources to complete. While this type of application can easily be implemented to run completely as a z/OS batch job, it is enticing within the IBM zEnterprise hybrid processor architecture to consider moving PDF generation to a zBX blade. Assuming that the desired program can be relocated to a z/BX blade server running AIX, Linux, or Windows, what are the other considerations for moving all or part of this job? • How will the program access required input and output data? • How will the program be scheduled, possibly so as to fit into the context of a larger job stream? • What operational impact will there be by moving all or part of the job? (log messages, monitoring, completion status, etc.) The Co:Z Co-Processing Toolkit provides z/OS users with tools that mitigate these considerations while making it easy to exploit zBX blades from traditional batch workloads - an idiom we refer to as z/OS hybrid batch processing. -

History of Word Processing and Spreadsheet
History Of Word Processing And Spreadsheet Vasily inwrapping his cowbanes undock troublously or calculably after Tobiah edulcorate and outwitting overtrumphazily, loth hisand dreamlessness. afferent. Acclimatizable Set-up and and stout post-bellum Ignacio neverVite hysterectomizes patrolled his backstitch! so bleeding that Scottie Single document with moving from there were released in history, you change screens between microsoft windows is history of a popular unix is. This original is tracked in hebrew which portrays market shares of the. Productivity Application Software Tutorial Sophia Learning. Standalone word processors like the Wang 2200 fell out his favor how the tune of. Found per the Apache OpenOffice user portal including a brief pause of OpenOfficeorg. 7 Tech Tools to Organize Your fucking History Collection. A private History a Word Processing Through 196 by Brian. Limited support better version it presents security measures, processing of and history across devices are not in. How timely we follow in the days before every verb one of us had access old word processors and computers on a respective desks That's plea a direct sentence. Word processor portablecontactsnet. History of WordPerfect Corporation FundingUniverse. To use homework mode, you can access this course allows students and history of digital interface. The spreadsheet dominated by Lotus 1-2-3 and database dBase markets WordPerfect XyWrite Microsoft Word. Solved True or fancy Word processing programs spreadsheet programs email programs web browsers and games are all examples of utility programs. Increasing user friendliness when incorporating a. Word Processing on Your Mac dummies. Share your files in hay-time with revision history prior to assign Track Changes. -

Oracle® Hospitality Enterprise Back Office Reporting and Analytics, Gift and Loyalty, and Labor Management Security Guide 8.5.0
Oracle® Hospitality Enterprise Back Office Reporting and Analytics, Gift and Loyalty, and Labor Management Security Guide 8.5.0 E66671-02 December 2016 Oracle® Hospitality Enterprise Back Office Security Guide, Release 8.5.0 Copyright © 2004, 2016, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

July 19 – 22, 2021 Gove County 4-H Fairgrounds Grainfield, Ks
H Club H - Design by: Ella Prosser, Smoky River 4 River Smoky Prosser, Ella by: Design Gove County Fair July 19 – 22, 2021 Gove County 4-H Fairgrounds Grainfield, Ks 1 This premium list has been provided through the generosity of the Gove County Commissioners. Duane Vollbracht, Chairman Charles Kuntz, Commissioner Mike Gillespie, Commissioner Golden Prairie Extension District Staff: Clint Bain- District Director, Crop Production/Livestock Agent, WaKeeney Office Taylor Ziegelmeier- Family & Consumer Science Agent, Oakley Office Kristy Packard- Gove County 4-H Program Manager Ashley Conness- Trego County 4-H Program Manager Gracie Tyler- Logan County 4-H Program Manager Jennifer Ackerman- Grainfield Office Professional Kathy Katt- Oakley Office Professional Lucy Conness- WaKeeney Office Professional Grainfield-(785)673-4805 Oakley-(785)671-3245 WaKeeney-(785) 743-6361 Gove County Fair Board Members Term Expires Chairperson…………………Lacey Heddlesten…..…...…………December, 2021 Vice Chairperson……………Tyler Breeden..…………………….December 2021 Secretary……………………. Kassie Remington….……………...December 2021 Treasurer……………………Dusty Zerr…………………………December 2024 FACS Dept. Head…………….Kelli Getz………………………….December 2024 4-H Building Supervisor…….Kassie Remington…………………December 2024 Asst. Building Supervisor……Lacey Heddlesten………………….December 2021 Livestock Supervisor………...Logan Getz……………………...…December 2023 Asst. Livestock Supervisor…..Tyler Breeden…………………...…December 2021 Member……………………...Garrett Werth.……………………December 2023 Member……………………...Eric Baalman……………………...December -

An Exploratory Analysis
On licensing and other conditions for contributing to widely used open source projects: an exploratory analysis Jonas Gamalielsson Björn Lundell University of Skövde University of Skövde Skövde, Sweden Skövde, Sweden [email protected] [email protected] ABSTRACT and different open source licenses [25]. Open source software (OSS) projects are provided under different open source licenses and some projects use other When OSS projects make decisions concerning under conditions (in addition to licensing terms) for contributors which specific open source licenses and other conditions to adhere to. Licensing terms and conditions may affect that developed software will be provided, it is evident that community involvement and contributions, and are such decisions may have significant impact on its perceived differently by different stakeholders in different community and its future evolution. A specific choice of OSS projects. The study reports from an exploratory license made by a specific OSS project may be preferred by analysis of licensing terms and other conditions for 200 some individuals and companies, whereas others may widely used OSS projects, and an investigation of the dislike the decisions made and therefore decide not to relationship between licensing terms and other conditions engage with and contribute to software in the specific for contributing. We find that strong copyleft licenses are project. For example, it has been argued that companies most common and are used in the majority of the projects. may avoid engaging with GPL-licensed OSS projects [21], Further, a clear majority of the OSS projects use no specific whereas other research shows that companies in the other condition for contributing in addition to the license embedded systems area may prefer engaging in OSS terms.