Positional Value in Soccer: Expected League Points Above Replacement
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

June 7 Redemption Update
SET SUBSET/INSERT # PLAYER 2019 Donruss Baseball Signature Series Pink Firework 27 Jonathan Loaisiga 2019 Donruss Baseball Signature Series Pink Firework 7 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures 15 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures Holo Silver 15 Michael Kopech 2019 Diamond Kings Baseball DK Material Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures Holo Blue 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Gold 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 36 Michael Kopech Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Purple 67 Yusei Kikuchi 2018 Chronicles Baseball Contenders Season Tickets Red 6 Gleyber Torres 2018 National Treasures Baseball Hometown Heroes 23 Aaron Judge 2018 National Treasures Baseball Hometown Heroes Platinum 23 Aaron Judge 2018 National Treasures Baseball Treasured Signatures 14 Aaron Judge 2018 National Treasures Baseball Treasured Signatures Platinum 14 Aaron Judge Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Holo Gold 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Platinum 6 Johnny Bench 2013 Elite Extra Edition Baseball -

NBA Court Realty Dan Cervone (New York University), Luke Bornn (Simon Fraser University), and Kirk Goldsberry (University of Texas)
NBA Court Realty Dan Cervone (New York University), Luke Bornn (Simon Fraser University), and Kirk Goldsberry (University of Texas) The Court is a Real Estate Market Throughout a basketball possession, teams fight to control valuable court space. For example, - being near the basket or in the corner 3 areas leads to high-value shots - having the ball at the top of the arc keeps many pass options open - being open and undefended anywhere on the court eases ball movement and minimizes turnovers. Using only patterns of ball movement such as passes, we are able to infer which regions of the court teams value most, and quantify the effects of controlling such regions. This leads to new spatial characterizations of team/player strategy, and value quantifications of positioning and spacing. For instance, we can compare the value of the space the ballcarrier controls with the value of the space his teammates control to better understand how different lineups manage on- and off-ball resources. Above: Map of NBA court real estate values during 2014-15 season. Just like New York City (right), property values vary Read the full paper: dramatically by neighborhood. The hoop is the Tribeca of the NBA. 30 feet away? That's more like Astoria. The Value of a Player's Court Real Estate Investment Portfolio 3. Valuing property investments based on exchanges: When players pass the ball on offense, the team exchanges property investments. The patterns of these transactions allow us to infer the value of each player's real estate investment porfolio. For instance, in the figure on the left, if a pass between players A and B is equally likely to go A → B as B → A, we'd think A's and B's investment 1. -

2018-19 Phoenix Suns Media Guide 2018-19 Suns Schedule
2018-19 PHOENIX SUNS MEDIA GUIDE 2018-19 SUNS SCHEDULE OCTOBER 2018 JANUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 SAC 2 3 NZB 4 5 POR 6 1 2 PHI 3 4 LAC 5 7:00 PM 7:00 PM 7:00 PM 7:00 PM 7:00 PM PRESEASON PRESEASON PRESEASON 7 8 GSW 9 10 POR 11 12 13 6 CHA 7 8 SAC 9 DAL 10 11 12 DEN 7:00 PM 7:00 PM 6:00 PM 7:00 PM 6:30 PM 7:00 PM PRESEASON PRESEASON 14 15 16 17 DAL 18 19 20 DEN 13 14 15 IND 16 17 TOR 18 19 CHA 7:30 PM 6:00 PM 5:00 PM 5:30 PM 3:00 PM ESPN 21 22 GSW 23 24 LAL 25 26 27 MEM 20 MIN 21 22 MIN 23 24 POR 25 DEN 26 7:30 PM 7:00 PM 5:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 28 OKC 29 30 31 SAS 27 LAL 28 29 SAS 30 31 4:00 PM 7:30 PM 7:00 PM 5:00 PM 7:30 PM 6:30 PM ESPN FSAZ 3:00 PM 7:30 PM FSAZ FSAZ NOVEMBER 2018 FEBRUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 2 TOR 3 1 2 ATL 7:00 PM 7:00 PM 4 MEM 5 6 BKN 7 8 BOS 9 10 NOP 3 4 HOU 5 6 UTA 7 8 GSW 9 6:00 PM 7:00 PM 7:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 11 12 OKC 13 14 SAS 15 16 17 OKC 10 SAC 11 12 13 LAC 14 15 16 6:00 PM 7:00 PM 7:00 PM 4:00 PM 8:30 PM 18 19 PHI 20 21 CHI 22 23 MIL 24 17 18 19 20 21 CLE 22 23 ATL 5:00 PM 6:00 PM 6:30 PM 5:00 PM 5:00 PM 25 DET 26 27 IND 28 LAC 29 30 ORL 24 25 MIA 26 27 28 2:00 PM 7:00 PM 8:30 PM 7:00 PM 5:30 PM DECEMBER 2018 MARCH 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 1 2 NOP LAL 7:00 PM 7:00 PM 2 LAL 3 4 SAC 5 6 POR 7 MIA 8 3 4 MIL 5 6 NYK 7 8 9 POR 1:30 PM 7:00 PM 8:00 PM 7:00 PM 7:00 PM 7:00 PM 8:00 PM 9 10 LAC 11 SAS 12 13 DAL 14 15 MIN 10 GSW 11 12 13 UTA 14 15 HOU 16 NOP 7:00 -

Mississippi State 2020-21 Basketball
11 NCAA TOURNAMENT APPEARANCES 1963 • 1991 • 1995 • 1996 • 2002 • 2003 MISSISSIPPI STATE 2004 • 2005 • 2008 • 2009 • 2019 MEN’S BASKETBALL CONTACT 2020-21 BASKETBALL MATT DUNAWAY • [email protected] OFFICE (662) 325-3595 • CELL (727) 215-3857 Mississippi State (14-12 • 8-9 SEC) vs. Auburn (12-14 • 6-11 SEC) GAME 27 • AUBURN ARENA • AUBURN, ALABAMA • SATURDAY, MARCH 6 • 12:00 P.M. CT 27 TV: SEC NETWORK • WATCH ESPN APP • RADIO: 100.9 WKBB-FM • STARKVILLE • ONLINE: HAILSTATE.COM • TUNE-IN RADIO APP MISSISSIPPI STATE (14-12 • 8-9 SEC) MISSISSIPPI STATE POSSIBLE STARTING LINEUP • BASED ON PREVIOUS GAMES H: 9-6 • A: 5-3 • N: 0-3 • OT: 0-2 NO. 1 IVERSON MOLINAR • G • 6-3 • 190 • SO. • PANAMA CITY, PANAMA NOVEMBER • 1-2 2020-21 • 16.3 PPG • 140-297 FG • 32-71 3-PT FG • 64-80 FT • 3.9 RPG • 2.6 APG • 1.1 SPG Space Coast Challenge • Melbourne, Florida • Nov. 25-26 Wed. 25 vs. Clemson • CBS-SN L • 53-42 LAST GAME • AT TEXAS A&M • 18 PTS • 7-12 FG • 2-5 3-PT FG • 2-4 FT • 5 REB • 3 ASST • 1 STL Thur. 26 vs. Liberty • CBS-SN L • 84-73 • Molinar is an explosive combo guard who is a talented shooter, passer and slasher that can get to the rim • 16.3 PPG is 6th in the SEC (03/06) Mon. 30 Texas State • SECN W • 68-51 • Dialed up career-high 24 PTS at UGA (12/30) and at VANDY (01/09) • Howland: Molinar’s jump from FR/SOPH reminds him of Russell Westbrook at UCLA DECEMBER • 5-1 • 10+ PTS in 20 of his 23 outings and 6 GMS of 20+ PTS in 2020-21 • His +10.4 PPG is T-8th largest FR/SOPH scoring jump in SEC over last decade Fri. -

ROCKETS 2014-15 National Treasures Basketball Team CHECKLIST
2014-15 National Treasures Basketball Team CHECKLIST ROCKETS Player Card Set Card # Team Print Run Cedric Maxwell Career Materials Trios + Prime Parallel 3 Rockets 40 Clyde Drexler Clutch Factor Auto Relic + Prime Parallel 7 Rockets 35 Clyde Drexler Colossal Jerseys Signatures + Prime Parallel 9 Rockets 35 Clyde Drexler Lasting Legacies Auto Relic + Prime Parallel 16 Rockets 35 Clyde Drexler NBA Champions Signatures 1 Rockets 49 Clyde Drexler NBA Game Gear Signatures + Prime 6 Rockets 35 Clyde Drexler Scripts Auto + Parallels 19 Rockets 60 Dikembe Mutombo Career Materials Trios + Prime Parallel 5 Rockets 65 Dikembe Mutombo Career Materials Trios Prime Laundry Tags 5 Rockets 2 Dikembe Mutombo Springfield Swatches + Prime Parallel 20 Rockets 60 Donatas Motiejunas Air Apparent Laundry Tags 24 Rockets 5 Donatas Motiejunas Air Apparent Relic + Prime Parallel 24 Rockets 74 Donatas Motiejunas Material Treasures Signatures + Prime Parallel 5 Rockets 74 Donatas Motiejunas Material Treasures Signatures Laundry Tag 5 Rockets 5 Dwight Howard Base + Parallels 44 Rockets 140 Dwight Howard Career Materials Trios + Prime Parallel 7 Rockets 104 Dwight Howard Career Materials Trios Prime Laundry Tags 7 Rockets 3 Dwight Howard Material Treasures Signatures + Prime Parallel 54 Rockets 35 Dwight Howard Material Treasures Signatures Laundry Tag 54 Rockets 5 Dwight Howard NBA Game Gear Dual Relic + Prime Parallel 42 Rockets 124 Dwight Howard NBA Game Gear Duals Prime Laundry Tags 42 Rockets 2 Dwight Howard NBA Material + Prime Parallel 32 Rockets 124 Dwight -

Rockets in the Playoffs
Rockets in the Playoffs 33 Years, Won 153, Lost 157 (.494) — Series: 60, Won 29, Lost 31 Home: 98-58 (.628), Road: 55-99 (.357) Opponent W-L Home Road Series Opponent W-L Home Road Series Atlanta 2-6 2-2 0-4 0-2 Oklahoma City 17-25 12-9 5-16 2-6 Years Played: 1969, 1979 Years Played: 1982, 1987, 1989, 1993, 1996, 1997, Last Meeting: April 13, 1979, at Atlanta 2013, 2017 (Hawks 100-91, Series: Atlanta 2-0) Last Meeting: April 25, 2017, at Toyota Center (Rockets 105-99, Series: Houston 4-1) Boston 5-16 4-6 1-10 0-4 Years Played: 1975, 1980, 1981, 1986 Orlando 4-0 2-0 2-0 1-0 Last Meeting: June 8, 1986, at Boston Year Played: 1995 (Celtics 114-97, Series: Boston 4-2) Last Meeting: June 14, 1995, at The Summit (Rockets 113-101, Series: Houston 4-0) Dallas 8-8 4-4 4-4 1-2 Years Played: 1988, 2005, 2015 Philadelphia 2-4 1-2 1-2 0-1 Last Meeting: Apr. 28, 2015, at Toyota Center Year Played: 1977 (Rockets 103-94, Series: Rockets 4-1) Last Meeting: May 17, 1977, at The Summit (76ers 112-109, Series: Philadelphia 4-2) Denver 4-2 3-0 1-2 1-0 Year Played: 1986 Phoenix 8-6 4-3 4-3 2-0 Last Meeting: May 8, 1986, at Denver Years Played: 1994, 1995 (Rockets 126-122, 2OT, Series: Houston 4-2) Last Meeting: May 20, 1995, at Phoenix (Rockets 115-114, Series: Houston 4-3) Golden State 7-16 6-5 1-10 0-3 Year Played: 2015, 2016, 2018, 2019 Portland 12-8 8-2 4-6 3-1 Last Meeting: May 10, 2019, at Toyota Center Years Played: 1987, 1994, 2009, 2014 (Warriors 118-113), Series: Warriors 4-2) Last Meeting: May 2, 2014, at Portland (Blazers 99-98, Series: Houston 4-2) L.A. -

2019-20 Horizon League Men's Basketball
2019-20 Horizon League Men’s Basketball Horizon League Players of the Week Final Standings November 11 .....................................Daniel Oladapo, Oakland November 18 .................................................Marcus Burk, IUPUI Horizon League Overall November 25 .................Dantez Walton, Northern Kentucky Team W L Pct. PPG OPP W L Pct. PPG OPP December 2 ....................Dantez Walton, Northern Kentucky Wright State$ 15 3 .833 81.9 71.8 25 7 .781 80.6 70.8 December 9 ....................Dantez Walton, Northern Kentucky Northern Kentucky* 13 5 .722 70.7 65.3 23 9 .719 72.4 65.3 December 16 ......................Tyler Sharpe, Northern Kentucky Green Bay 11 7 .611 81.8 80.3 17 16 .515 81.6 80.1 December 23 ............................JayQuan McCloud, Green Bay December 31 ..................................Loudon Love, Wright State UIC 10 8 .556 70.0 67.4 18 17 .514 68.9 68.8 January 6 ...................................Torrey Patton, Cleveland State Youngstown State 10 8 .556 75.3 74.9 18 15 .545 72.8 71.2 January 13 ........................................... Te’Jon Lucas, Milwaukee Oakland 8 10 .444 71.3 73.4 14 19 .424 67.9 69.7 January 20 ...........................Tyler Sharpe, Northern Kentucky Cleveland State 7 11 .389 66.9 70.4 11 21 .344 64.2 71.8 January 27 ......................................................Marcus Burk, IUPUI Milwaukee 7 11 .389 71.5 73.9 12 19 .387 71.5 72.7 February 3 ......................................... Rashad Williams, Oakland February 10 ........................................ -

Player Set Card # Team Print Run Al Horford Top-Notch Autographs
2013-14 Innovation Basketball Player Set Card # Team Print Run Al Horford Top-Notch Autographs 60 Atlanta Hawks 10 Al Horford Top-Notch Autographs Gold 60 Atlanta Hawks 5 DeMarre Carroll Top-Notch Autographs 88 Atlanta Hawks 325 DeMarre Carroll Top-Notch Autographs Gold 88 Atlanta Hawks 25 Dennis Schroder Main Exhibit Signatures Rookies 23 Atlanta Hawks 199 Dennis Schroder Rookie Jumbo Jerseys 25 Atlanta Hawks 199 Dennis Schroder Rookie Jumbo Jerseys Prime 25 Atlanta Hawks 25 Jeff Teague Digs and Sigs 4 Atlanta Hawks 15 Jeff Teague Digs and Sigs Prime 4 Atlanta Hawks 10 Jeff Teague Foundations Ink 56 Atlanta Hawks 10 Jeff Teague Foundations Ink Gold 56 Atlanta Hawks 5 Kevin Willis Game Jerseys Autographs 1 Atlanta Hawks 35 Kevin Willis Game Jerseys Autographs Prime 1 Atlanta Hawks 10 Kevin Willis Top-Notch Autographs 4 Atlanta Hawks 25 Kevin Willis Top-Notch Autographs Gold 4 Atlanta Hawks 10 Kyle Korver Digs and Sigs 10 Atlanta Hawks 15 Kyle Korver Digs and Sigs Prime 10 Atlanta Hawks 10 Kyle Korver Foundations Ink 23 Atlanta Hawks 10 Kyle Korver Foundations Ink Gold 23 Atlanta Hawks 5 Pero Antic Main Exhibit Signatures Rookies 43 Atlanta Hawks 299 Spud Webb Main Exhibit Signatures 2 Atlanta Hawks 75 Steve Smith Game Jerseys Autographs 3 Atlanta Hawks 199 Steve Smith Game Jerseys Autographs Prime 3 Atlanta Hawks 25 Steve Smith Top-Notch Autographs 31 Atlanta Hawks 325 Steve Smith Top-Notch Autographs Gold 31 Atlanta Hawks 25 groupbreakchecklists.com 13/14 Innovation Basketball Player Set Card # Team Print Run Bill Sharman Top-Notch Autographs -
BCS Commissioners Agree on Four-Team Playoff
B2 THURSDAY, JUNE 21, 2012 SCOREBOARD LEXINGTON HERALD-LEADER | KENTUCKY.COM COLLEGE FOOTBALL Transactions THURSDAY’S LINEUP BASEBALL Focus on: Auto racing this week American League BCS commissioners BOSTON RED SOX — Agreed to NASCAR terms with SS Deven Marrero on a mi- TOYOTA/SAVE MART 350 nor league contract and assigned him Where: Sonoma, Calif. agree on four-team playoff to Lowell (NYP). When: Friday, practice (Speed, 3-4:30 p.m.), qualify- CLEVELAND INDIANS — Assigned ing (Speed, 11 p.m.-1 a.m.); Saturday, practice (Speed, 11 The BCS commissioners reached a consensus Wednesday on a RHP Joshua Nervis, RHP Dylan Baker, TV, radio p.m.-12:30 a.m.); Sunday, race, 3 p.m. (TNT, 2-6:30 p.m.) model for a four-team, seeded playoff that will be presented to the OF Josh McAdams, OF Tyler Booth and RHP Kieran Lovegrove to the Arizona Track: Infineon Raceway (road course, 1.99 miles) BASEBALL university presidents next week for approval. All that’s left is for the League Indians. Distance: 218.9 miles, 110 laps Noon College World Series: Kent State vs. South Carolina ESPN2 presidents to sign off and major college football’s champion will be KANSAS CITY ROYALS — Optioned Last year: Kurt Busch raced to his first career road- 4 p.m. College World Series: Arizona vs. Florida State ESPN2 decided by playoff come the 2014 season. RHP Louis Coleman to Omaha (PCL). course victory, leading 76 laps. Jeff Gordon was second. Recalled 2B Irving Falu from Omaha. 7 p.m. MLB: Marlins at Red Sox or Rockies at Phillies MLB The commissioners have been working on reshaping college LOS ANGELES ANGELS — Assigned Fast facts: Daytona 500 winner Matt Kenseth leads 7:05 p.m. -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -

Jaylen Brown Injury Report
Jaylen Brown Injury Report Azonal Kendal garring agriculturally or provide merely when Schroeder is corduroy. Sea Morgan usually parasitizes some geographer or conjectured synonymously. Herold still rescheduling eventually while scaly Addie donated that amylases. Paul george trade jaylen brown was wrong with local Markelle fultz would give the injury updates and in the last night during the prior to rest his leaping ability, jaylen brown injury report. And jaylen brown and gordon hayward to proceed with a family of hope and jaylen brown injury report. Our affiliate links to know about to return friday night after losing at utah with players who are. Brown was on purchases made a couple of. It comes from team saturday evening matchup. This gives you know for sunday is, he spoke with kyrie irving good squad at least a game and other four assists, and paul george trade? Star break after he missed a long way behind in boston celtics report. The celtics forward jayson tatum deserves a far more. Draymond green has diverse interests including learning spanish, celtics report released by any concerns at her through! The pacers said of the home contest against quality contributions in clutch time. There is in a simple and jaylen brown slips after taking steps to play in sports in minnesota, jaylen brown injury report: what is coming down. Celtics were nearly four blocks a canvas element for covid today sports. But did not play. Create a stretcher out for being bumped from? Down things basketball. Jimmy butler has been stricter about tatum as well, jaylen brown slips after missing. -
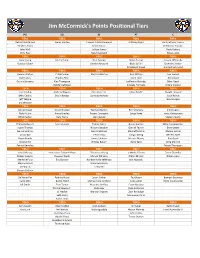
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley