Quantiles and Quantile Based Plots Percentiles and Quantiles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Statistical Analysis of Distributions, Percentile Rank Classes and Top-Cited
How to analyse percentile impact data meaningfully in bibliometrics: The statistical analysis of distributions, percentile rank classes and top-cited papers Lutz Bornmann Division for Science and Innovation Studies, Administrative Headquarters of the Max Planck Society, Hofgartenstraße 8, 80539 Munich, Germany; [email protected]. 1 Abstract According to current research in bibliometrics, percentiles (or percentile rank classes) are the most suitable method for normalising the citation counts of individual publications in terms of the subject area, the document type and the publication year. Up to now, bibliometric research has concerned itself primarily with the calculation of percentiles. This study suggests how percentiles can be analysed meaningfully for an evaluation study. Publication sets from four universities are compared with each other to provide sample data. These suggestions take into account on the one hand the distribution of percentiles over the publications in the sets (here: universities) and on the other hand concentrate on the range of publications with the highest citation impact – that is, the range which is usually of most interest in the evaluation of scientific performance. Key words percentiles; research evaluation; institutional comparisons; percentile rank classes; top-cited papers 2 1 Introduction According to current research in bibliometrics, percentiles (or percentile rank classes) are the most suitable method for normalising the citation counts of individual publications in terms of the subject area, the document type and the publication year (Bornmann, de Moya Anegón, & Leydesdorff, 2012; Bornmann, Mutz, Marx, Schier, & Daniel, 2011; Leydesdorff, Bornmann, Mutz, & Opthof, 2011). Until today, it has been customary in evaluative bibliometrics to use the arithmetic mean value to normalize citation data (Waltman, van Eck, van Leeuwen, Visser, & van Raan, 2011). -

5. the Student T Distribution
Virtual Laboratories > 4. Special Distributions > 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 5. The Student t Distribution In this section we will study a distribution that has special importance in statistics. In particular, this distribution will arise in the study of a standardized version of the sample mean when the underlying distribution is normal. The Probability Density Function Suppose that Z has the standard normal distribution, V has the chi-squared distribution with n degrees of freedom, and that Z and V are independent. Let Z T= √V/n In the following exercise, you will show that T has probability density function given by −(n +1) /2 Γ((n + 1) / 2) t2 f(t)= 1 + , t∈ℝ ( n ) √n π Γ(n / 2) 1. Show that T has the given probability density function by using the following steps. n a. Show first that the conditional distribution of T given V=v is normal with mean 0 a nd variance v . b. Use (a) to find the joint probability density function of (T,V). c. Integrate the joint probability density function in (b) with respect to v to find the probability density function of T. The distribution of T is known as the Student t distribution with n degree of freedom. The distribution is well defined for any n > 0, but in practice, only positive integer values of n are of interest. This distribution was first studied by William Gosset, who published under the pseudonym Student. In addition to supplying the proof, Exercise 1 provides a good way of thinking of the t distribution: the t distribution arises when the variance of a mean 0 normal distribution is randomized in a certain way. -

Theoretical Statistics. Lecture 20
Theoretical Statistics. Lecture 20. Peter Bartlett 1. Recall: Functional delta method, differentiability in normed spaces, Hadamard derivatives. [vdV20] 2. Quantile estimates. [vdV21] 3. Contiguity. [vdV6] 1 Recall: Differentiability of functions in normed spaces Definition: φ : D E is Hadamard differentiable at θ D tangentially → ∈ to D D if 0 ⊆ φ′ : D E (linear, continuous), h D , ∃ θ 0 → ∀ ∈ 0 if t 0, ht h 0, then → k − k → φ(θ + tht) φ(θ) − φ′ (h) 0. t − θ → 2 Recall: Functional delta method Theorem: Suppose φ : D E, where D and E are normed linear spaces. → Suppose the statistic Tn : Ωn D satisfies √n(Tn θ) T for a random → − element T in D D. 0 ⊂ If φ is Hadamard differentiable at θ tangentially to D0 then ′ √n(φ(Tn) φ(θ)) φ (T ). − θ If we can extend φ′ : D E to a continuous map φ′ : D E, then 0 → → ′ √n(φ(Tn) φ(θ)) = φ (√n(Tn θ)) + oP (1). − θ − 3 Recall: Quantiles Definition: The quantile function of F is F −1 : (0, 1) R, → F −1(p) = inf x : F (x) p . { ≥ } Quantile transformation: for U uniform on (0, 1), • F −1(U) F. ∼ Probability integral transformation: for X F , F (X) is uniform on • ∼ [0,1] iff F is continuous on R. F −1 is an inverse (i.e., F −1(F (x)) = x and F (F −1(p)) = p for all x • and p) iff F is continuous and strictly increasing. 4 Empirical quantile function For a sample with distribution function F , define the empirical quantile −1 function as the quantile function Fn of the empirical distribution function Fn. -

A Logistic Regression Equation for Estimating the Probability of a Stream in Vermont Having Intermittent Flow
Prepared in cooperation with the Vermont Center for Geographic Information A Logistic Regression Equation for Estimating the Probability of a Stream in Vermont Having Intermittent Flow Scientific Investigations Report 2006–5217 U.S. Department of the Interior U.S. Geological Survey A Logistic Regression Equation for Estimating the Probability of a Stream in Vermont Having Intermittent Flow By Scott A. Olson and Michael C. Brouillette Prepared in cooperation with the Vermont Center for Geographic Information Scientific Investigations Report 2006–5217 U.S. Department of the Interior U.S. Geological Survey U.S. Department of the Interior DIRK KEMPTHORNE, Secretary U.S. Geological Survey P. Patrick Leahy, Acting Director U.S. Geological Survey, Reston, Virginia: 2006 For product and ordering information: World Wide Web: http://www.usgs.gov/pubprod Telephone: 1-888-ASK-USGS For more information on the USGS--the Federal source for science about the Earth, its natural and living resources, natural hazards, and the environment: World Wide Web: http://www.usgs.gov Telephone: 1-888-ASK-USGS Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. Government. Although this report is in the public domain, permission must be secured from the individual copyright owners to reproduce any copyrighted materials contained within this report. Suggested citation: Olson, S.A., and Brouillette, M.C., 2006, A logistic regression equation for estimating the probability of a stream in Vermont having intermittent -

A Tail Quantile Approximation Formula for the Student T and the Symmetric Generalized Hyperbolic Distribution
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Schlüter, Stephan; Fischer, Matthias J. Working Paper A tail quantile approximation formula for the student t and the symmetric generalized hyperbolic distribution IWQW Discussion Papers, No. 05/2009 Provided in Cooperation with: Friedrich-Alexander University Erlangen-Nuremberg, Institute for Economics Suggested Citation: Schlüter, Stephan; Fischer, Matthias J. (2009) : A tail quantile approximation formula for the student t and the symmetric generalized hyperbolic distribution, IWQW Discussion Papers, No. 05/2009, Friedrich-Alexander-Universität Erlangen-Nürnberg, Institut für Wirtschaftspolitik und Quantitative Wirtschaftsforschung (IWQW), Nürnberg This Version is available at: http://hdl.handle.net/10419/29554 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu IWQW Institut für Wirtschaftspolitik und Quantitative Wirtschaftsforschung Diskussionspapier Discussion Papers No. -

Stat 5102 Lecture Slides: Deck 1 Empirical Distributions, Exact Sampling Distributions, Asymptotic Sampling Distributions
Stat 5102 Lecture Slides: Deck 1 Empirical Distributions, Exact Sampling Distributions, Asymptotic Sampling Distributions Charles J. Geyer School of Statistics University of Minnesota 1 Empirical Distributions The empirical distribution associated with a vector of numbers x = (x1; : : : ; xn) is the probability distribution with expectation operator n 1 X Enfg(X)g = g(xi) n i=1 This is the same distribution that arises in finite population sam- pling. Suppose we have a population of size n whose members have values x1, :::, xn of a particular measurement. The value of that measurement for a randomly drawn individual from this population has a probability distribution that is this empirical distribution. 2 The Mean of the Empirical Distribution In the special case where g(x) = x, we get the mean of the empirical distribution n 1 X En(X) = xi n i=1 which is more commonly denotedx ¯n. Those with previous exposure to statistics will recognize this as the formula of the population mean, if x1, :::, xn is considered a finite population from which we sample, or as the formula of the sample mean, if x1, :::, xn is considered a sample from a specified population. 3 The Variance of the Empirical Distribution The variance of any distribution is the expected squared deviation from the mean of that same distribution. The variance of the empirical distribution is n 2o varn(X) = En [X − En(X)] n 2o = En [X − x¯n] n 1 X 2 = (xi − x¯n) n i=1 The only oddity is the use of the notationx ¯n rather than µ for the mean. -

Integration of Grid Maps in Merged Environments
Integration of grid maps in merged environments Tanja Wernle1, Torgeir Waaga*1, Maria Mørreaunet*1, Alessandro Treves1,2, May‐Britt Moser1 and Edvard I. Moser1 1Kavli Institute for Systems Neuroscience and Centre for Neural Computation, Norwegian University of Science and Technology, Trondheim, Norway; 2SISSA – Cognitive Neuroscience, via Bonomea 265, 34136 Trieste, Italy * Equal contribution Corresponding author: Tanja Wernle [email protected]; Edvard I. Moser, [email protected] Manuscript length: 5719 words, 6 figures,9 supplemental figures. 1 Abstract (150 words) Natural environments are represented by local maps of grid cells and place cells that are stitched together. How transitions between map fragments are generated is unknown. Here we recorded grid cells while rats were trained in two rectangular compartments A and B (each 1 m x 2 m) separated by a wall. Once distinct grid maps were established in each environment, we removed the partition and allowed the rat to explore the merged environment (2 m x 2 m). The grid patterns were largely retained along the distal walls of the box. Nearer the former partition line, individual grid fields changed location, resulting almost immediately in local spatial periodicity and continuity between the two original maps. Grid cells belonging to the same grid module retained phase relationships during the transformation. Thus, when environments are merged, grid fields reorganize rapidly to establish spatial periodicity in the area where the environments meet. Introduction Self‐location is dynamically represented in multiple functionally dedicated cell types1,2 . One of these is the grid cells of the medial entorhinal cortex (MEC)3. The multiple spatial firing fields of a grid cell tile the environment in a periodic hexagonal pattern, independently of the speed and direction of a moving animal. -

Depth, Outlyingness, Quantile, and Rank Functions in Multivariate & Other Data Settings Eserved@D = *@Let@Token
DEPTH, OUTLYINGNESS, QUANTILE, AND RANK FUNCTIONS – CONCEPTS, PERSPECTIVES, CHALLENGES Depth, Outlyingness, Quantile, and Rank Functions in Multivariate & Other Data Settings Robert Serfling1 Serfling & Thompson Statistical Consulting and Tutoring ASA Alabama-Mississippi Chapter Mini-Conference University of Mississippi, Oxford April 5, 2019 1 www.utdallas.edu/∼serfling DEPTH, OUTLYINGNESS, QUANTILE, AND RANK FUNCTIONS – CONCEPTS, PERSPECTIVES, CHALLENGES “Don’t walk in front of me, I may not follow. Don’t walk behind me, I may not lead. Just walk beside me and be my friend.” – Albert Camus DEPTH, OUTLYINGNESS, QUANTILE, AND RANK FUNCTIONS – CONCEPTS, PERSPECTIVES, CHALLENGES OUTLINE Depth, Outlyingness, Quantile, and Rank Functions on Rd Depth Functions on Arbitrary Data Space X Depth Functions on Arbitrary Parameter Space Θ Concluding Remarks DEPTH, OUTLYINGNESS, QUANTILE, AND RANK FUNCTIONS – CONCEPTS, PERSPECTIVES, CHALLENGES d DEPTH, OUTLYINGNESS, QUANTILE, AND RANK FUNCTIONS ON R PRELIMINARY PERSPECTIVES Depth functions are a nonparametric approach I The setting is nonparametric data analysis. No parametric or semiparametric model is assumed or invoked. I We exhibit the geometric structure of a data set in terms of a center, quantile levels, measures of outlyingness for each point, and identification of outliers or outlier regions. I Such data description is developed in terms of a depth function that measures centrality from a global viewpoint and yields center-outward ordering of data points. I This differs from the density function, -

Sampling Student's T Distribution – Use of the Inverse Cumulative
Sampling Student’s T distribution – use of the inverse cumulative distribution function William T. Shaw Department of Mathematics, King’s College, The Strand, London WC2R 2LS, UK With the current interest in copula methods, and fat-tailed or other non-normal distributions, it is appropriate to investigate technologies for managing marginal distributions of interest. We explore “Student’s” T distribution, survey its simulation, and present some new techniques for simulation. In particular, for a given real (not necessarily integer) value n of the number of degrees of freedom, −1 we give a pair of power series approximations for the inverse, Fn ,ofthe cumulative distribution function (CDF), Fn.Wealsogivesomesimpleandvery fast exact and iterative techniques for defining this function when n is an even −1 integer, based on the observation that for such cases the calculation of Fn amounts to the solution of a reduced-form polynomial equation of degree n − 1. We also explain the use of Cornish–Fisher expansions to define the inverse CDF as the composition of the inverse CDF for the normal case with a simple polynomial map. The methods presented are well adapted for use with copula and quasi-Monte-Carlo techniques. 1 Introduction There is much interest in many areas of financial modeling on the use of copulas to glue together marginal univariate distributions where there is no easy canonical multivariate distribution, or one wishes to have flexibility in the mechanism for combination. One of the more interesting marginal distributions is the “Student’s” T distribution. This statistical distribution was published by W. Gosset in 1908. -

How to Use MGMA Compensation Data: an MGMA Research & Analysis Report | JUNE 2016
How to Use MGMA Compensation Data: An MGMA Research & Analysis Report | JUNE 2016 1 ©MGMA. All rights reserved. Compensation is about alignment with our philosophy and strategy. When someone complains that they aren’t earning enough, we use the surveys to highlight factors that influence compensation. Greg Pawson, CPA, CMA, CMPE, chief financial officer, Women’s Healthcare Associates, LLC, Portland, Ore. 2 ©MGMA. All rights reserved. Understanding how to utilize benchmarking data can help improve operational efficiency and profits for medical practices. As we approach our 90th anniversary, it only seems fitting to celebrate MGMA survey data, the gold standard of the industry. For decades, MGMA has produced robust reports using the largest data sets in the industry to help practice leaders make informed business decisions. The MGMA DataDive® Provider Compensation 2016 remains the gold standard for compensation data. The purpose of this research and analysis report is to educate the reader on how to best use MGMA compensation data and includes: • Basic statistical terms and definitions • Best practices • A practical guide to MGMA DataDive® • Other factors to consider • Compensation trends • Real-life examples When you know how to use MGMA’s provider compensation and production data, you will be able to: • Evaluate factors that affect compensation andset realistic goals • Determine alignment between medical provider performance and compensation • Determine the right mix of compensation, benefits, incentives and opportunities to offer new physicians and nonphysician providers • Ensure that your recruitment packages keep pace with the market • Understand the effects thatteaching and research have on academic faculty compensation and productivity • Estimate the potential effects of adding physicians and nonphysician providers • Support the determination of fair market value for professional services and assess compensation methods for compliance and regulatory purposes 3 ©MGMA. -
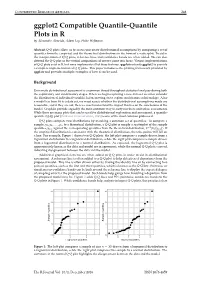
Ggplot2 Compatible Quantile-Quantile Plots in R by Alexandre Almeida, Adam Loy, Heike Hofmann
CONTRIBUTED RESEARCH ARTICLES 248 ggplot2 Compatible Quantile-Quantile Plots in R by Alexandre Almeida, Adam Loy, Heike Hofmann Abstract Q-Q plots allow us to assess univariate distributional assumptions by comparing a set of quantiles from the empirical and the theoretical distributions in the form of a scatterplot. To aid in the interpretation of Q-Q plots, reference lines and confidence bands are often added. We can also detrend the Q-Q plot so the vertical comparisons of interest come into focus. Various implementations of Q-Q plots exist in R, but none implements all of these features. qqplotr extends ggplot2 to provide a complete implementation of Q-Q plots. This paper introduces the plotting framework provided by qqplotr and provides multiple examples of how it can be used. Background Univariate distributional assessment is a common thread throughout statistical analyses during both the exploratory and confirmatory stages. When we begin exploring a new data set we often consider the distribution of individual variables before moving on to explore multivariate relationships. After a model has been fit to a data set, we must assess whether the distributional assumptions made are reasonable, and if they are not, then we must understand the impact this has on the conclusions of the model. Graphics provide arguably the most common way to carry out these univariate assessments. While there are many plots that can be used for distributional exploration and assessment, a quantile- quantile (Q-Q) plot (Wilk and Gnanadesikan, 1968) is one of the most common plots used. Q-Q plots compare two distributions by matching a common set of quantiles. -
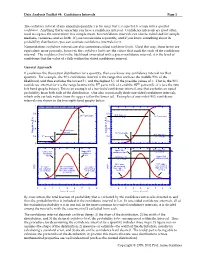
Data Analysis Toolkit #4: Confidence Intervals Page 1 Copyright © 1995
Data Analysis Toolkit #4: Confidence Intervals Page 1 The confidence interval of any uncertain quantity x is the range that x is expected to occupy with a specified confidence. Anything that is uncertain can have a confidence interval. Confidence intervals are most often used to express the uncertainty in a sample mean, but confidence intervals can also be calculated for sample medians, variances, and so forth. If you can calculate a quantity, and if you know something about its probability distribution, you can estimate confidence intervals for it. Nomenclature: confidence intervals are also sometimes called confidence limits. Used this way, these terms are equivalent; more precisely, however, the confidence limits are the values that mark the ends of the confidence interval. The confidence level is the likelihood associated with a given confidence interval; it is the level of confidence that the value of x falls within the stated confidence interval. General Approach If you know the theoretical distribution for a quantity, then you know any confidence interval for that quantity. For example, the 90% confidence interval is the range that encloses the middle 90% of the likelihood, and thus excludes the lowest 5% and the highest 5% of the possible values of x. That is, the 90% confidence interval for x is the range between the 5th percentile of x and the 95th percentile of x (see the two left-hand graphs below). This is an example of a two-tailed confidence interval, one that excludes an equal probability from both tails of the distribution. One also occasionally finds one-sided confidence intervals, which only exclude values from the upper tail or the lower tail.