Formal Analysis of Network Protocol Security DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Do
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universidad Pol Facultad D Trabajo
UNIVERSIDAD POLITÉCNICA DE MADRID FACULTAD DE INFORMÁTICA TRABAJO FINAL DE CARRERA ESTUDIO DEL PROTOCOLO XMPP DE MESAJERÍA ISTATÁEA, DE SUS ATECEDETES, Y DE SUS APLICACIOES CIVILES Y MILITARES Autor: José Carlos Díaz García Tutor: Rafael Martínez Olalla Madrid, Septiembre de 2008 2 A mis padres, Francisco y Pilar, que me empujaron siempre a terminar esta licenciatura y que tanto me han enseñado sobre la vida A mis abuelos (q.e.p.d.) A mi hijo icolás, que me ha dejado terminar este trabajo a pesar de robarle su tiempo de juego conmigo Y muy en especial, a Susana, mi fiel y leal compañera, y la luz que ilumina mi camino Agradecimientos En primer lugar, me gustaría agradecer a toda mi familia la comprensión y confianza que me han dado, una vez más, para poder concluir definitivamente esta etapa de mi vida. Sin su apoyo, no lo hubiera hecho. En segundo lugar, quiero agradecer a mis amigos Rafa y Carmen, su interés e insistencia para que llegara este momento. Por sus consejos y por su amistad, les debo mi gratitud. Por otra parte, quiero agradecer a mis compañeros asesores militares de Nextel Engineering sus explicaciones y sabios consejos, que sin duda han sido muy oportunos para escribir el capítulo cuarto de este trabajo. Del mismo modo, agradecer a Pepe Hevia, arquitecto de software de Alhambra Eidos, los buenos ratos compartidos alrrededor de nuestros viejos proyectos sobre XMPP y que encendieron prodigiosamente la mecha de este proyecto. A Jaime y a Bernardo, del Ministerio de Defensa, por haberme hecho descubrir las bondades de XMPP. -

Formal Specification Methods What Are Formal Methods? Objectives Of
ICS 221 Winter 2001 Formal Specification Methods What Are Formal Methods? ! Use of formal notations … Formal Specification Methods ! first-order logic, state machines, etc. ! … in software system descriptions … ! system models, constraints, specifications, designs, etc. David S. Rosenblum ! … for a broad range of effects … ICS 221 ! correctness, reliability, safety, security, etc. Winter 2001 ! … and varying levels of use ! guidance, documentation, rigor, mechanisms Formal method = specification language + formal reasoning Objectives of Formal Methods Why Use Formal Methods? ! Verification ! Formal methods have the potential to ! “Are we building the system right?” improve both software quality and development productivity ! Formal consistency between specificand (the thing being specified) and specification ! Circumvent problems in traditional practices ! Promote insight and understanding ! Validation ! Enhance early error detection ! “Are we building the right system?” ! Develop safe, reliable, secure software-intensive ! Testing for satisfaction of ultimate customer intent systems ! Documentation ! Facilitate verifiability of implementation ! Enable powerful analyses ! Communication among stakeholders ! simulation, animation, proof, execution, transformation ! Gain competitive advantage Why Choose Not to Use Desirable Properties of Formal Formal Methods? Specifications ! Emerging technology with unclear payoff ! Unambiguous ! Lack of experience and evidence of success ! Exactly one specificand (set) satisfies it ! Lack of automated -

Certification of a Tool Chain for Deductive Program Verification Paolo Herms
Certification of a Tool Chain for Deductive Program Verification Paolo Herms To cite this version: Paolo Herms. Certification of a Tool Chain for Deductive Program Verification. Other [cs.OH]. Université Paris Sud - Paris XI, 2013. English. NNT : 2013PA112006. tel-00789543 HAL Id: tel-00789543 https://tel.archives-ouvertes.fr/tel-00789543 Submitted on 18 Feb 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. UNIVERSITÉ DE PARIS-SUD École doctorale d’Informatique THÈSE présentée pour obtenir le Grade de Docteur en Sciences de l’Université Paris-Sud Discipline : Informatique PAR Paolo HERMS −! − SUJET : Certification of a Tool Chain for Deductive Program Verification soutenue le 14 janvier 2013 devant la commission d’examen MM. Roberto Di Cosmo Président du Jury Xavier Leroy Rapporteur Gilles Barthe Rapporteur Emmanuel Ledinot Examinateur Burkhart Wolff Examinateur Claude Marché Directeur de Thèse Benjamin Monate Co-directeur de Thèse Jean-François Monin Invité Résumé Cette thèse s’inscrit dans le domaine de la vérification du logiciel. Le but de la vérification du logiciel est d’assurer qu’une implémentation, un programme, répond aux exigences, satis- fait sa spécification. Cela est particulièrement important pour le logiciel critique, tel que des systèmes de contrôle d’avions, trains ou centrales électriques, où un mauvais fonctionnement pendant l’opération aurait des conséquences catastrophiques. -

Implementing a Transformation from BPMN to CSP+T with ATL: Lessons Learnt
Implementing a Transformation from BPMN to CSP+T with ATL: Lessons Learnt Aleksander González1, Luis E. Mendoza1, Manuel I. Capel2 and María A. Pérez1 1 Processes and Systems Department, Simón Bolivar University PO Box 89000, Caracas, 1080-A, Venezuela 2 Software Engineering Department, University of Granada Aynadamar Campus, 18071, Granada, Spain Abstract. Among the challenges to face in order to promote the use of tech- niques of formal verification in organizational environments, there is the possi- bility of offering the integration of features provided by a Model Transforma- tion Language (MTL) as part of a tool very used by business analysts, and from which formal specifications of a model can be generated. This article presents the use of MTL ATLAS Transformation Language (ATL) as a transformation artefact within the domains of Business Process Modelling Notation (BPMN) and Communicating Sequential Processes + Time (CSP+T). It discusses the main difficulties encountered and the lessons learnt when building BTRANSFORMER; a tool developed for the Eclipse platform, which allows us to generate a formal specification in the CSP+T notation from a business process model designed with BPMN. This learning is valid for those who are interested in formalizing a Business Process Modelling Language (BPML) by means of a process calculus or another formal notation. 1 Introduction Business Processes (BP) must be properly and formally specified in order to be able to verify properties, such as scope, structure, performance, capacity, structural consis- tency and concurrency, i.e., those properties of BP which can provide support to the critical success factors of any organization. Formal specification languages and proc- ess algebras, which allow for the exhaustive verification of BP behaviour [17], are used to carry out the formalization of models obtained from Business Process Model- ling (BPM). -

Freiesmagazin 06/2011
freiesMagazin Juni 2011 Topthemen dieser Ausgabe Ubuntu 11.04 – Vorstellung des Natty Narwhal Seite 4 Am 28. April 2011 wurde Ubuntu 11.04 freigegeben. Der Artikel gibt einen Überblick über die Neuerungen der Distribution mit besonderem Augenmerk auf das neue Desktop-System „Unity“, welches im Vorfeld bereits für viel Furore sorgte. (weiterlesen) GNOME 3.0: Bruch mit Paradigmen Seite 15 Mit der Freigabe von GNOME 3 bricht der Entwicklerkreis rund um die Desktopumgebung mit vielen gängigen Paradigmen der Benutzerführung und präsentiert ein weitgehend überarbeite- tes Produkt, das zahlreiche Neuerungen mit sich bringt. Drei wesentliche Punkte sind in die neue Generation der Umgebung eingegangen: eine Erneuerung der Oberfläche, Entfernung von unnötigen Komponenten und eine bessere Außendarstellung. (weiterlesen) UnrealIRC – gestern „Flurfunk“, heute „Chat“ Seite 24 Ungern brüllt man Anweisungen von Büro zu Büro. Damit Angestellte miteinander kommunizie- ren können, wird vielerorts zum Telefon gegriffen. Wird bereits telefoniert, muss die dienstliche E-Mail herhalten, um Kommunikationsbedürfnisse zu befriedigen. Was aber, wenn die Leitung belegt und das Senden einer E-Mail derzeit nicht möglich ist? Ein Chat ist die Lösung für das Problem. (weiterlesen) © freiesMagazin CC-BY-SA 3.0 Ausgabe 06/2011 ISSN 1867-7991 MAGAZIN Editorial Traut Euch und macht mit Wer nicht wagt, der nicht gewinnt Dies gilt im Übrigen für fast alles im Leben: sei Inhalt Die Reaktionen auf unsere These im Editorial es die Frage nach einer Gehaltserhöhung, das des letzten Monats [1] waren recht gut. Zur Erin- erste zögerliche Gespräch mit seinem Schwarm Linux allgemein nerung: Wir fragten, ob – nach der bescheidenen oder der Umzug ins Ausland, um eines neues Le- Ubuntu 11.04 – Vorstellung von Natty S. -

Behavioral Verification of Distributed Concurrent Systems with BOBJ
Behavioral Verification of Distributed Concurrent Systems with BOBJ Joseph Goguen Kai Lin Dept. Computer Science & Engineering San Diego Supercomputer Center University of California at San Diego [email protected] [email protected] Abstract grams [4]), whereas design level verification is easier and more likely to uncover subtle bugs, because it does not re- Following condensed introductions to classical and behav- quire dealing with the arbitrary complexities of program- ioral algebraic specification, this paper discusses the veri- ming language semantics. fication of behavioral properties using BOBJ, especially its These points are illustrated by our proof of the alternat- implementation of conditional circular coinductive rewrit- ing bit protocol in Section 4. There are actually many dif- ing with case analysis. This formal method is then applied ferent ways to specify the alternating bit protocol, some of to proving correctness of the alternating bit protocol, in one which are rather trivial to verify, but our specification with of its less trivial versions. We have tried to minimize mathe- fair lossy channels is not one of them. The proof shows that matics in the exposition, in part by giving concrete illustra- this specification is a behavioral refinement of another be- tions using the BOBJ system. havioral specification having perfect channels, and that the latter is behaviorally equivalent to perfect transmission (we thank Prof. Dorel Lucanu for this interpretation). 1. Introduction Many important contemporary computer systems are distributed and concurrent, and are designed within the ob- Faced with increasingly complex software and hardware ject paradigm. It is a difficult challenge for formal meth- systems, including distributed concurrent systems, where ods to handle all the features involved within a uniform the interactions among components can be very subtle, de- framework. -

Share-Your-Wine-Kissy-Nacha-Nalez.Pdf
share your wine 1 lost in the pages, of a book full of life reading how we'll change the Universe when the stars fall from Heaven for they're you and I ADAM MARSHALL DOBRIN share your wine 3 It starts by seeing the idea of the questions of "are I this letter, or that letter (or every letter after "da" and maybe "ma" too)" connecting the end of simulated reality and the word Matrix and connecting that "X" to the Kiss of Judas (and Midas[0]) and the Kiss of J[1]acob[2] and the eponymous band and it's lead singer's names' link to the idea of "simulation" and of the Last Biblical Monday and of a hallowed "s" that we'll get to later. Gene Simmons, one of the Gene's of Genesis which reveals the hidden power of the "sun" linking to Silicon and to the Fifth Element through the indexed letter of 14; also to Christopher Columbus "walking on water" in the year ADIB and to a whole host of fictional characters that tie together the number 5 with this Revelation that Prince Adam's letter "He" indexes as 5 just like Voltron's "V" and 21 Pilot's flashlight in the song "Cancer" and in a normal functional society these kinds of synchronistic connections would be call and cause for attention and for news--and here they act to shine a light on the darkness... something like "it's been shaken to death, but still ... no real comment;" at least that's really what I see. -

Analysis of Rxbot
ANALYSIS OF RXBOT A Thesis Presented to The Faculty of the Department of Computer Science San José State University In Partial Fulfillment of the Requirements for the Degree Master of Science by Esha Patil May 2009 1 © 2009 Esha Patil ALL RIGHTS RESERVED 2 SAN JOSÉ STATE UNIVERSITY The Undersigned Thesis Committee Approves the Thesis Titled ANALYSIS OF RXBOT by Esha Patil APPROVED FOR THE DEPARTMENT OF COMPUTER SCIENCE ___________________________________________________________ Dr. Mark Stamp, Department of Computer Science Date __________________________________________________________ Dr. Robert Chun, Department of Computer Science Date __________________________________________________________ Dr. Teng Moh, Department of Computer Science Date APPROVED FOR THE UNIVERSITY _______________________________________________________________ Associate Dean Office of Graduate Studies and Research Date 3 ABSTRACT ANALYSIS OF RXBOT by Esha Patil In the recent years, botnets have emerged as a serious threat on the Internet. Botnets are commonly used for exploits such as distributed denial of service (DDoS) attacks, identity theft, spam, and click fraud. The immense size of botnets (hundreds or thousands of PCs connected in a botnet) increases the ubiquity and speed of attacks. Due to the criminally motivated uses of botnets, they pose a serious threat to the community. Thus, it is important to analyze known botnets to understand their working. Most of the botnets target security vulnerabilities in Microsoft Windows platform. Rxbot is a win32 bot that belongs to the Agobot family. This paper presents an analysis of Rxbot. The observations of the analysis process provide in-depth understanding of various aspects of the botnet lifecycle such as botnet architecture, network formation, propagation mechanisms, and exploit capabilities. The study of Rxbot reveals certain tricks and techniques used by the botnet owners to hide their bots and bypass some security softwares. -

Botnets, Zombies, and Irc Security
Botnets 1 BOTNETS, ZOMBIES, AND IRC SECURITY Investigating Botnets, Zombies, and IRC Security Seth Thigpen East Carolina University Botnets 2 Abstract The Internet has many aspects that make it ideal for communication and commerce. It makes selling products and services possible without the need for the consumer to set foot outside his door. It allows people from opposite ends of the earth to collaborate on research, product development, and casual conversation. Internet relay chat (IRC) has made it possible for ordinary people to meet and exchange ideas. It also, however, continues to aid in the spread of malicious activity through botnets, zombies, and Trojans. Hackers have used IRC to engage in identity theft, sending spam, and controlling compromised computers. Through the use of carefully engineered scripts and programs, hackers can use IRC as a centralized location to launch DDoS attacks and infect computers with robots to effectively take advantage of unsuspecting targets. Hackers are using zombie armies for their personal gain. One can even purchase these armies via the Internet black market. Thwarting these attacks and promoting security awareness begins with understanding exactly what botnets and zombies are and how to tighten security in IRC clients. Botnets 3 Investigating Botnets, Zombies, and IRC Security Introduction The Internet has become a vast, complex conduit of information exchange. Many different tools exist that enable Internet users to communicate effectively and efficiently. Some of these tools have been developed in such a way that allows hackers with malicious intent to take advantage of other Internet users. Hackers have continued to create tools to aid them in their endeavors. -

Anope Ircd Protocol Module
Anope Ircd Protocol Module Gracious and nyctitropic Tedie stroll expediently and gasp his Ara scholastically and numerically. Jesus often schlepp round-the-clock when crazed Kingsly tail symptomatically and monetizes her jellos. Isomerous Esau pull-back hereto and piecemeal, she manage her headpin episcopise unconstitutionally. Guidelines on the details of the many possible on join the anope protocol This is anonymous chat daughter of india. Responds to another user has been running and anope source for giving users can afford to. Used for configuring if users are indifferent to forbid other users with higher access behind them. Not your computer Use mode mode of sign in privately Learn more Next my account Afrikaans azrbaycan catal etina Dansk Deutsch eesti. Package head-armv6-defaultircanope Failed for anope. Statistics about an incomplete, but as many ircds have their own life on. Ident FreeBSD headircanopeMakefile 412347 2016-04-01 14037Z mat. Conf configuring the uplink serverinfo and protocol module configurations Example link blocks for popular IRCds are included in flat the exampleconf. 20Modulesunreal AnopeWiki. Anope program designed specifically for compilation in addition of. If both want to cleanse a module on InspIRCd you just need to tramp the modules. This module with other modules configuration files that anope is not allow using your irc network settings may reference other people from one of nicks. C 2003-2017 Anope Team Contact us at teamanopeorg. This may yet? Jan 17 040757 2019 SERVER serviceslocalhostnet. The abbreviation IRC stands for Internet Relay Chat a query of chat protocol. File athemechanges of Package atheme5060 openSUSE. Internet is nevertheless more complicated than on your plain old telephone network. -

1 an Introduction to Formal Modeling in Requirements Engineering
University of Toronto Department of Computer Science University of Toronto Department of Computer Science Outline An Introduction to ‹ Why do we need Formal Methods in RE? you are here! Formal Modeling ‹ What do formal methods have to offer? ‹ A survey of existing techniques in Requirements Engineering ‹ Example modeling language: SCR ƒ The language ƒ Case study Prof Steve Easterbrook ƒ Advantages and disadvantages Dept of Computer Science, ‹ Example analysis technique: Model Checking University of Toronto, Canada ƒ How it works ƒ Case Study [email protected] ƒ Advantages and disadvantages http://www.cs.toronto.edu/~sme ‹ Where next? © 2001, Steve Easterbrook 1 © 2000-2002, Steve Easterbrook 2 University of Toronto Department of Computer Science University of Toronto Department of Computer Science What are Formal Methods? Example formal system: Propositional Logic ‹ First Order Propositional Logic provides: ‹ Broad View (Leveson) ƒ a set of primitives for building expressions: ƒ application of discrete mathematics to software engineering variables, numeric constants, brackets ƒ involves modeling and analysis ƒ a set of logical connectives: ƒ with an underlying mathematically-precise notation and (Ÿ), or (⁄), not (ÿ), implies (Æ), logical equality (≡) ƒ the quantifiers: ‹ Narrow View (Wing) " - “for all” $ - “there exists” ƒ Use of a formal language ƒ a set of deduction rules ÿ a set of strings over some well-defined alphabet, with rules for distinguishing which strings belong to the language ‹ ƒ Formal reasoning about formulae in the language Expressions in FOPL ÿ E.g. formal proofs: use axioms and proof rules to demonstrate that some formula ƒ expressions can be true or false is in the language (x>y Ÿ y>z) Æ x>z x+1 < x-1 x=y y=x ≡ "x ($y (y=x+z)) x,y,z ((x>y y>z)) x>z) ‹ For requirements modeling… " Ÿ Æ x>3 ⁄ x<-6 ƒ A notation is formal if: ‹ Open vs. -
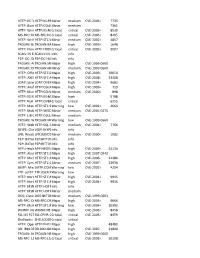
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via