An Active Learning Framework for Efficient Acquisition and Detection of Unknown Malware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

About the Contributors
336 About the Contributors Burcin Bozkaya is an Associate Professor of Operations Management and the Associate Dean at Sabanci School of Management. Burcin earned his B.S. and M.S. degrees in Industrial Engineering at Bilkent University and his Ph.D. in Manage- ment Science at the School of Business of the University of Alberta. Prior to join- ing Sabanci University in 2004, Burcin worked as a Senior Operations Research Analyst at Environmental Systems Research Institute (ESRI), Inc., in Redlands, California. During this industry work experience, Burcin participated in and led many software development projects specializing in the applications of GIS and Operations Research in transportation and logistics optimization. In one such proj- ect, he received INFORMS Franz Edelman Finalist Award, for a project completed for Schindler Elevator Corporation. Since 2004, Burcin teaches courses on Opera- tions Management, Geographic Information Systems, Customer Relationship Management with Location Intelligence, Quantitative Decision Making and Excel/ VBA Programming. He conducts research on Spatial Analytics, Location Analysis, Transportation Network Planning and Vehicle Routing Optimization, and Combi- national Optimization using Heuristic Algorithms, and has published in various international journals. He is a recipient of IEEE 2008 Best Paper Award, and the 2010 Canadian Operational Research Society’s Best Practice Prize. Burcin is a father of two and enjoys playing his guitar and flute, and traveling in his (not-so- easy-to-find) free time. Vivek Singh is an Assistant Professor at the School of Communication and Information, Rutgers University and a Visiting Assistant Professor at the MIT Media Lab. Vivek obtained his PhD in Information and Computer Science from the University of California, Irvine and spent two years conducting post-doctoral research at the Massachusetts Institute of Technology. -
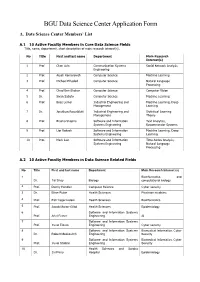
BGU Data Science Center Application Form
BGU Data Science Center Application Form A. Data Science Center Members’ List A.1 10 Active Faculty Members in Core Data Science Fields Title, name, department, short description of main research interest(s). No Title First and last name Department Main Research Interest(s) 1 Prof. Chen Avin Communication Systems Social Network Analysis Engineering 2 Prof. Aryeh Kontorovich Computer Science Machine Learning 3 Prof. Michael Elhadad Computer Science Natural Language Processing 4 Prof. Ohad Ben-Shahar Computer Science Computer Vision 5 Dr. Sivan Sabato Computer Science Machine Learning 6 Prof. Boaz Lerner Industrial Engineering and Machine Learning, Deep Management Learning 7 Dr. Jonathan Rosenblatt Industrial Engineering and Statistical Learning Management Theory 8 Prof. Bracha Shapira Software and Information Text Analytics, Systems Engineering Recommender Systems 9 Prof. Lior Rokach Software and Information Machine Learning, Deep Systems Engineering Learning 10 Prof. Mark Last Software and Information Time-Series Analysis, Systems Engineering Natural Language Processing A.2 10 Active Faculty Members in Data Science Related Fields No Title First and last name Department Main Research Interest (s) 1 Bioinformatics and Dr. Tal Shay Biology computational biology 2 Prof. Danny Hendler Computer Science Cyber security 3 Dr. Eitan Rubin Health Sciences Precision medicine 4 Prof. Esti Yeger-Lotem Health Sciences Bioinformatics 5 Prof. Jacob Moran-Gilad Health Sciences Epidemiology 6 Software and Information Systems Prof. Ariel Felner Engineering AI 7 Software and Information Systems Prof. Yuval Elovici Engineering Cyber security 8 Software and Information Systems Biomedical Informatics, Cyber Dr. Robert Moskovitch Engineering Security 9 Software and Information Systems Biomedical Informatics, Cyber Prof. Yuval Shahar Engineering Security 10 Health Sciences and Soroka Dr. -

CURRICULUM VITAE and LIST of PUBLICATIONS May 2019 Personal Details: Name: Shlomi (Shlomo) Dolev
CURRICULUM VITAE AND LIST OF PUBLICATIONS May 2019 Personal Details: Name: Shlomi (Shlomo) Dolev. Date and place of birth: 5/12/58, Israel. Regular military service: 13/2/77 to 12/8/80 (Cap- tain). Address and telephone number at work: Department of Computer Science, Ben-Gurion University of the Negev, Beer-Sheva 84105, Israel, Tel: 08-6472718, Fax: 08-6477650, Email: [email protected]. Parent of: Noa, Yorai, Hagar and Eden. Short Biography: Shlomi Dolev received his B.Sc. in Engineering and B.A. in Computer Science in 1984 and 1985, and his M.Sc. and D.Sc. in computer Science in 1990 and 1992 from the Technion Israel Institute of Technology. From 1992 to 1995 he was at Texas A&M University as a visiting research specialist. In 1995 he joined the Department of Mathematics and Computer Science at Ben-Gurion University. Shlomi is the founder and the first department head of the Computer Science Department at Ben-Gurion University, established in 2000. After just 15 years, the department has been ranked among the first 150 best departments in the world. He is the author of a book entitled Self-Stabilization published by MIT Press in 2000. His publications, more than three hundred conferences, journals and patents, include papers in JACM, SIAM journal on computing, Nature Photonics, Nature Communications, Physical Review, Journal of the Optical Society of America A, Distributed Computing, IEEE/ACM Trans. on Networking, ACM Trans. on Information and System Security, Journal of Cryptology, Journal of Computer and System Sciences, ACM Trans. on Knowledge Discovery from Data, ACM Trans. -

Sec-Lib: Protecting Scholarly Digital Libraries from Infected Papers Using Active Machine Learning Framework
Old Dominion University ODU Digital Commons Computer Science Faculty Publications Computer Science 2019 Sec-Lib: Protecting Scholarly Digital Libraries From Infected Papers Using Active Machine Learning Framework Nir Nissim Aviad Cohen Jian Wu Old Dominion University Andrea Lanzi Lior Rokach See next page for additional authors Follow this and additional works at: https://digitalcommons.odu.edu/computerscience_fac_pubs Part of the Computer Engineering Commons, and the Information Security Commons Original Publication Citation Nissim, N., Cohen, A., Wu, J., Lanzi, A., Rokach, L., Elovici, Y., & Giles, L. (2019). Sec-Lib: Protecting scholarly digital libraries from infected papers using active machine learning framework. IEEE Access, 7, 110050-110073. doi:10.1109/access.2019.2933197 This Article is brought to you for free and open access by the Computer Science at ODU Digital Commons. It has been accepted for inclusion in Computer Science Faculty Publications by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. Authors Nir Nissim, Aviad Cohen, Jian Wu, Andrea Lanzi, Lior Rokach, Yuval Elovici, and Lee Giles This article is available at ODU Digital Commons: https://digitalcommons.odu.edu/computerscience_fac_pubs/141 IEEE Access· Multidi5ciplinary l Rapid Review l OpenAcce5sJournal Received July 8, 2019, accepted July 24, 2019, date of publication August 6, 2019, date of current version August 21, 2019. Digital Object Identifier 10.1109/ACCESS.2019.2933197 Sec-Lib: Protecting Scholarly -

Academic Perspectives on Cyber Security Challenges
You are cordially invited to attend Yuval Ne'eman Workshop for Science, Technology and Security, the National Cyber Bureau and Blavatnik Interdisciplinary Cyber Research Center (ICRC), Tel Aviv University The 4th Annual International Cybersecurity Conference: Academic Perspectives on Cyber Security Challenges Monday, September 15th, 2014, 10:30 – 13:00, Kes Hamishpat Hall, Trubowicz Building, Tel Aviv University 10:00 - 10:30 Reception & Registration 10:30 - 11:40 Moderator: Dr. Yaniv Harel, Fellow, Blavatnik Interdisciplinary Cyber Research Center, TAU The Global Cyber-Vulnerability Report Prof. V.S Subrahmanian, Professor of Computer Science, University of Maryland and Head of the Center for Digital International Government Implementations of Machine Learning Tools for Detecting Cyber Anomalies Prof. Irad E. Ben-Gal, Head of the Department of Industrial Engineering & Management, TAU Rebuilding Trust in Computing Platforms Dr. Eran Tromer, Senior Lecturer , Blavatnik School of Computer Science, TAU Cyber Threat: Achilles Heel of Space Systems? Dr. Deganit Paikowsky, Senior Researcher, Yuval Ne'eman Workshop for Science, Technology and Security, TAU Ms. Gil Baram , Researcher, Yuval Ne'eman Workshop for Science, Technology and Security, TAU 11:40 - 12:00 Coffee Break 12:00 - 13:00 Air-Gap and Cyber Security Prof. Yuval Elovici, Director, Deutche Telekom Laboratories, Ben-Gurion University of the Negev, Israel Cyber Studies in International Relations: Future Directions and Priorities Dr. Lucas Kello, Research Fellow, Belfer Center for Science and International Affairs, Harvard University Discovering Weaknesses in Virtual Systems Prof. Assaf Schuster, Head of the Technion Center for Computer Engineering & a Professor in the Computer Science Department, Technion, Israel Institute of Technology Cybersecurity Through a Military Revolution Prism Lior Tabansky, Senior Researcher, Yuval Ne'eman Workshop for Science, Technology and Security, TAU Sponsored by: Steven E.