Using Natural Language to Predict Bias and Factuality in Media with a Study on Rationalization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Evocative and Persuasive Power of Loaded Words in the Political Discourse on Drug Reform
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OpenEdition Lexis Journal in English Lexicology 13 | 2019 Lexicon, Sensations, Perceptions and Emotions Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Electronic version URL: http://journals.openedition.org/lexis/3182 DOI: 10.4000/lexis.3182 ISSN: 1951-6215 Publisher Université Jean Moulin - Lyon 3 Electronic reference Sarah Bourse, « Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform », Lexis [Online], 13 | 2019, Online since 14 March 2019, connection on 20 April 2019. URL : http://journals.openedition.org/lexis/3182 ; DOI : 10.4000/ lexis.3182 This text was automatically generated on 20 April 2019. Lexis is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Conjuring up terror and tears: the evocative and persuasive power of loaded w... 1 Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Introduction 1 In the last few years, the use of the adjective “post-truth” has been emerging in the media to describe the political scene. This concept has gained momentum in the midst of fake allegations during the Brexit vote and the 2016 American presidential election, so much so that The Oxford Dictionary elected it word of the year in 2016. Formerly referring to the lies at the core of political scandals1, the term “post-truth” now describes a situation where the objective facts have far less importance and impact than appeals to emotion and personal belief in order to influence public opinion2. -

Reuters Institute Digital News Report 2020
Reuters Institute Digital News Report 2020 Reuters Institute Digital News Report 2020 Nic Newman with Richard Fletcher, Anne Schulz, Simge Andı, and Rasmus Kleis Nielsen Supported by Surveyed by © Reuters Institute for the Study of Journalism Reuters Institute for the Study of Journalism / Digital News Report 2020 4 Contents Foreword by Rasmus Kleis Nielsen 5 3.15 Netherlands 76 Methodology 6 3.16 Norway 77 Authorship and Research Acknowledgements 7 3.17 Poland 78 3.18 Portugal 79 SECTION 1 3.19 Romania 80 Executive Summary and Key Findings by Nic Newman 9 3.20 Slovakia 81 3.21 Spain 82 SECTION 2 3.22 Sweden 83 Further Analysis and International Comparison 33 3.23 Switzerland 84 2.1 How and Why People are Paying for Online News 34 3.24 Turkey 85 2.2 The Resurgence and Importance of Email Newsletters 38 AMERICAS 2.3 How Do People Want the Media to Cover Politics? 42 3.25 United States 88 2.4 Global Turmoil in the Neighbourhood: 3.26 Argentina 89 Problems Mount for Regional and Local News 47 3.27 Brazil 90 2.5 How People Access News about Climate Change 52 3.28 Canada 91 3.29 Chile 92 SECTION 3 3.30 Mexico 93 Country and Market Data 59 ASIA PACIFIC EUROPE 3.31 Australia 96 3.01 United Kingdom 62 3.32 Hong Kong 97 3.02 Austria 63 3.33 Japan 98 3.03 Belgium 64 3.34 Malaysia 99 3.04 Bulgaria 65 3.35 Philippines 100 3.05 Croatia 66 3.36 Singapore 101 3.06 Czech Republic 67 3.37 South Korea 102 3.07 Denmark 68 3.38 Taiwan 103 3.08 Finland 69 AFRICA 3.09 France 70 3.39 Kenya 106 3.10 Germany 71 3.40 South Africa 107 3.11 Greece 72 3.12 Hungary 73 SECTION 4 3.13 Ireland 74 References and Selected Publications 109 3.14 Italy 75 4 / 5 Foreword Professor Rasmus Kleis Nielsen Director, Reuters Institute for the Study of Journalism (RISJ) The coronavirus crisis is having a profound impact not just on Our main survey this year covered respondents in 40 markets, our health and our communities, but also on the news media. -

Moderation Guide
Moderation Guide Society of Editors www.societyofeditors.org 01 Moderation Guide Society of Editors www.societyofeditors.org Department for Communities and Local Government 01 Foreword Introduction Before the arrival of online news, the and threatening content is an issue of real C.P. Scott, Manchester Guardian editor from 1872 to 1929, writing for the 100th space available for content was limited and concern for many. That is why we funded anniversary of the paper and his 50th birthday in 1921, said a newspaper’s primary office newspaper editorials and comment pieces the Society of Editors with input and support was the gathering of news. were the preserve of the few. from the Press Complaints Commission to carry out research into current moderation “At the peril of its soul it must see that the supply is not tainted. Neither in what it gives, Today there really are no such physical of user-generated content and to produce nor in what it does not give, nor in the mode of presentation must the unclouded face restrictions and together with technological good practice guidance to help on-line of truth suffer wrong. Comment is free, but facts are sacred.” advances and social networking, a much moderators in the future. larger group of commentators now have This most famous quote of the longest serving editor of the newspaper we know today a voice on almost any topic. This opening The majority of online news outlets take as The Guardian, now provides the title of the comment section of the Guardian’s up of traditional media, with the advent of the issue of moderation seriously, not successful website. -
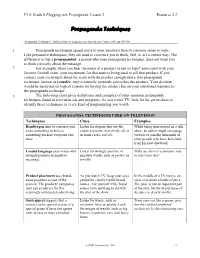
Lesson 2-Resource 2.2 Propaganda Techniques
ELA Grade 6 Plugging into Propaganda, Lesson 2 Resource 2.2 Propaganda Techniques “Propaganda Techniques,” Holt Literature & Language Arts, Introductory Course, 2003, pp. 643-645 1 Propaganda techniques appeal more to your emotions than to common sense or logic. Like persuasive techniques, they are used to convince you to think, feel, or act a certain way. The difference is that a propagandist, a person who uses propaganda techniques, does not want you to think critically about the message. 2 For example, when you hear the name of a product or see its logo* associated with your favorite football team, your excitement for that team is being used to sell that product. If you connect your excitement about the team with the product enough times, this propaganda technique, known as transfer, may eventually persuade you to buy the product. Your decision would be based not on logical reasons for buying the product but on your emotional response to the propaganda technique. 3 The following chart gives definitions and examples of other common propaganda techniques found in television ads and programs. As you watch TV, look for the given clues to identify these techniques in every kind of programming you watch. PROPAGANDA TECHNIQUES USED ON TELEVISION Techniques Clues Examples Bandwagon tries to convince you Listen for slogans that use the While being interviewed on a talk to do something or believe words everyone, everybody, all, or show, an author might encourage something because everyone else in some cases, nobody. viewers to join the thousands of does. other people who have benefited from his new diet book. -

The Future of Public Service Broadcasting DMG Media Response to the Digital, Culture, Media and Sport Select Committee's Call
Written evidence submitted by DMG Media The Future of Public Service Broadcasting DMG Media response to the Digital, Culture, Media and Sport Select Committee’s call for evidence 1. This response is made on behalf of DMG Media, the publishers of the Daily Mail, Mail on Sunday, MailOnline, Metro, Metro.co.uk, the ‘i’ and inews. It is being submitted because BBC online news competes for audience with our digital titles and we are concerned that funding changes could give the BBC an unfair advantage. 2. DMG Media is not a broadcaster, and public service broadcasters have by longstanding convention not published newspapers. Therefore, whilst over the decades our news titles and the BBC may have had political and cultural differences, they have not been commercial rivals. 3. However the coming of the digital age has changed that. The philosophical foundation of the BBC was that in return for public funding and access to scarce broadcast spectrum, it would develop then-new technology (radio and television) and use it to provide, in addition to education and entertainment, an impartial news service. The written word was not part of its remit. 4. The unlimited possibilities of the internet have destroyed the rationale of that arrangement. Satellite, cable, and now streaming have brought new competitors into the entertainment market, global players with vastly greater resources than the BBC. 5. The BBC is dependent for funding on the licence fee, over which successive governments have resolutely retained control, doubtless believing that a national broadcaster which has to regularly come to the government of the day with a begging bowl is more likely to be compliant. -

Downloads of Technical Information
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2018 Nuclear Spaces: Simulations of Nuclear Warfare in Film, by the Numbers, and on the Atomic Battlefield Donald J. Kinney Follow this and additional works at the DigiNole: FSU's Digital Repository. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES NUCLEAR SPACES: SIMULATIONS OF NUCLEAR WARFARE IN FILM, BY THE NUMBERS, AND ON THE ATOMIC BATTLEFIELD By DONALD J KINNEY A Dissertation submitted to the Department of History in partial fulfillment of the requirements for the degree of Doctor of Philosophy 2018 Donald J. Kinney defended this dissertation on October 15, 2018. The members of the supervisory committee were: Ronald E. Doel Professor Directing Dissertation Joseph R. Hellweg University Representative Jonathan A. Grant Committee Member Kristine C. Harper Committee Member Guenter Kurt Piehler Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii For Morgan, Nala, Sebastian, Eliza, John, James, and Annette, who all took their turns on watch as I worked. iii ACKNOWLEDGMENTS I would like to thank the members of my committee, Kris Harper, Jonathan Grant, Kurt Piehler, and Joseph Hellweg. I would especially like to thank Ron Doel, without whom none of this would have been possible. It has been a very long road since that afternoon in Powell's City of Books, but Ron made certain that I did not despair. Thank you. iv TABLE OF CONTENTS Abstract..............................................................................................................................................................vii 1. -

Fake News Detection for the Russian Language
Fake news detection for the Russian language Gleb Kuzmin∗ Daniil Larionov∗ Moscow Institute of Physics and Technology Federal Research Center / Dolgoprudny, Russia ”Computer Science and Control” [email protected] / Moscow, Russia [email protected] Dina Pisarevskaya∗ Ivan Smirnov Federal Research Center Federal Research Center ”Computer Science and Control” ”Computer Science and Control” / Moscow, Russia / Moscow, Russia [email protected] [email protected] Abstract In this paper, we trained and compared different models for fake news detection in Russian. For this task, we used such language features as bag-of-n-grams and bag of Rhetorical Structure Theory features, and BERT embeddings. We also compared the score of our models with the human score on this task and showed that our models deal with fake news detection better. We investigated the nature of fake news by dividing it into two non-overlapping classes: satire and fake news. As a result, we obtained the set of models for fake news detection; the best of these models achieved 0.889 F1-score on the test set for 2 classes and 0.9076 F1-score on 3 classes task. 1 Introduction Fake news detection becomes a more significant task. It is connected with an increasing number of news in media and social media. To prevent rumors and misinformation from spreading in this news, we need to have a system able to detect fake news. It also could be useful because it’s hard for people to recognize fake news. Approaches to this task are being developed for English. However, fake news texts can be written originally in different ’source’ languages, i.e. -

Neural Architectures for Fine-Grained Propaganda Detection in News
Neural Architectures for Fine-Grained Propaganda Detection in News Pankaj Gupta1,2, Khushbu Saxena1, Usama Yaseen1,2, Thomas Runkler1, Hinrich Schutze¨ 2 1Corporate Technology, Machine-Intelligence (MIC-DE), Siemens AG Munich, Germany 2CIS, University of Munich (LMU) Munich, Germany [email protected] | [email protected] Abstract techniques in news articles at sentence and frag- ment level, respectively and thus, promotes ex- This paper describes our system (MIC-CIS) plainable AI. For instance, the following text is a details and results of participation in the propaganda of type ‘slogan’. fine-grained propaganda detection shared task Trump tweeted: ‘`BUILD THE WALL!" 2019. To address the tasks of sentence (SLC) | {z } and fragment level (FLC) propaganda detec- slogan tion, we explore different neural architectures Shared Task: This work addresses the two (e.g., CNN, LSTM-CRF and BERT) and ex- tasks in propaganda detection (Da San Mar- tract linguistic (e.g., part-of-speech, named en- tino et al., 2019) of different granularities: (1) tity, readability, sentiment, emotion, etc.), lay- Sentence-level Classification (SLC), a binary clas- out and topical features. Specifically, we have sification that predicts whether a sentence con- designed multi-granularity and multi-tasking tains at least one propaganda technique, and (2) neural architectures to jointly perform both the Fragment-level Classification (FLC), a token-level sentence and fragment level propaganda de- (multi-label) classification that identifies both the tection. Additionally, we investigate different ensemble schemes such as majority-voting, spans and the type of propaganda technique(s). relax-voting, etc. to boost overall system per- Contributions: (1) To address SLC, we de- formance. -

Media Bias, the Social Sciences, and NLP: Automating Frame Analyses to Identify Bias by Word Choice and Labeling
Media Bias, the Social Sciences, and NLP: Automating Frame Analyses to Identify Bias by Word Choice and Labeling Felix Hamborg Dept. of Computer and Information Science University of Konstanz, Germany [email protected] Abstract Even subtle changes in the words used in a news text can strongly impact readers’ opinions (Pa- Media bias can strongly impact the public per- pacharissi and de Fatima Oliveira, 2008; Price et al., ception of topics reported in the news. A dif- 2005; Rugg, 1941; Schuldt et al., 2011). When re- ficult to detect, yet powerful form of slanted news coverage is called bias by word choice ferring to a semantic concept, such as a politician and labeling (WCL). WCL bias can occur, for or other named entities (NEs), authors can label example, when journalists refer to the same the concept, e.g., “illegal aliens,” and choose from semantic concept by using different terms various words to refer to it, e.g., “immigrants” or that frame the concept differently and conse- “aliens.” Instances of bias by word choice and label- quently may lead to different assessments by ing (WCL) frame the referred concept differently readers, such as the terms “freedom fighters” (Entman, 1993, 2007), whereby a broad spectrum and “terrorists,” or “gun rights” and “gun con- trol.” In this research project, I aim to devise of effects occurs. For example, the frame may methods that identify instances of WCL bias change the polarity of the concept, i.e., positively and estimate the frames they induce, e.g., not or negatively, or the frame may emphasize specific only is “terrorists” of negative polarity but also parts of an issue, such as the economic or cultural ascribes to aggression and fear. -

Classification of Propaganda on Fragment Level: Using Logistic Regression with Handcrafted Contextual Features
Classification of Propaganda on Fragment Level: Using Logistic Regression with Handcrafted Contextual Features Author Supervisor S. (Sylvain) Maissan Dong Nguyen Second Examiner Frans Adriaans June 26, 2020 1 Abstract Propaganda in the media has become a rising problem, especially after automation. The ease of which propaganda can be created and spread is astonishing. A way to combat this is an automated propaganda detection system. The goal of fine-grained propaganda detection is to determine whether a given sentence uses a propaganda technique, or to recognize which techniques are used on the fragment level. In this paper we try to analyze the effects of contextual features on the fragment level when training a propaganda classifier. Using a logistic regression model I created some handcrafted features that solely depend on contextual information. The results showed no significant impact on the performance. The features based on the propagandistic fragment itself prove to be the top features in this setting. In future research it is recommended to create either more complex contextual features or to create features that are able to discern whether the fragment is Loaded Language or Name Calling. Keywords: Propaganda Classification, Fragment Level, Contextual Features, 2 Contents 1. Introduction 4 2. Related Work 6 3. Datasets 8 4. Methods 11 4.1. Preprocessing 11 4.2. Features 12 4.3. Baseines 14 4.4. Evaluation 15 5. Results 16 6. Discussion 18 7. Conclusion 19 3 1 Introduction Propaganda aims at influencing people’s mindset with the purpose of advancing a specific agenda. It uses psychological and rhetorical techniques to persuade the public. -

Open PDF 409KB
DMG Media—written evidence (FOJ0033) Response the House of Lords Communications and Digital Committee call for evidence on the future of journalism Overview 1. DMG Media publishes the Daily Mail, Mail on Sunday, MailOnline, Metro and metro.co.uk. DMG Media is a subsidiary of DMGT, which has also recently purchased the i and inews. 2. We are always ready to assist the Communications and Digital Committee, and welcome any government initiatives which advance the cause of freedom of expression and contribute to a healthy media industry. We are very grateful for the support the Department for Digital, Culture Media and Sport has given to new publishers during the current Coronavirus crisis. This has brought into sharp focus the economic frailty of the news industry, and will inevitably both shorten the time the industry has to make a successful transition from print to digital, and strengthen yet further the market dominance of the online platforms, Google and Facebook. 3. It is fair to say that over the last couple of years news publishers have faced a unprecedented array of inquiries, codes of practice and legislation, some very helpful, others much less so. 4. The Cairncross and Furman Reviews, and the Competition and Markets Authority Online Advertising Market Study all address the fundamental issue, which is that reliable journalism will have no future in the UK unless ways can be found to deliver enough revenue to support a wide and varied range of digital publications - including global players like MailOnline, the online equivalents of traditional local news newspapers, and specialist titles. -

Register of Journalists' Interests
REGISTER OF JOURNALISTS’ INTERESTS (As at 14 June 2019) INTRODUCTION Purpose and Form of the Register Pursuant to a Resolution made by the House of Commons on 17 December 1985, holders of photo- identity passes as lobby journalists accredited to the Parliamentary Press Gallery or for parliamentary broadcasting are required to register: ‘Any occupation or employment for which you receive over £795 from the same source in the course of a calendar year, if that occupation or employment is in any way advantaged by the privileged access to Parliament afforded by your pass.’ Administration and Inspection of the Register The Register is compiled and maintained by the Office of the Parliamentary Commissioner for Standards. Anyone whose details are entered on the Register is required to notify that office of any change in their registrable interests within 28 days of such a change arising. An updated edition of the Register is published approximately every 6 weeks when the House is sitting. Changes to the rules governing the Register are determined by the Committee on Standards in the House of Commons, although where such changes are substantial they are put by the Committee to the House for approval before being implemented. Complaints Complaints, whether from Members, the public or anyone else alleging that a journalist is in breach of the rules governing the Register, should in the first instance be sent to the Registrar of Members’ Financial Interests in the Office of the Parliamentary Commissioner for Standards. Where possible the Registrar will seek to resolve the complaint informally. In more serious cases the Parliamentary Commissioner for Standards may undertake a formal investigation and either rectify the matter or refer it to the Committee on Standards.