Deep Learning for Classifying Battlefield 4 Players
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Battlefield Browser Plugin Battlefield 4 Plugin Download Battlefield 4 Crashes, Tweaks, Errors, FPS, Graphics, Lag and Fixes
battlefield browser plugin battlefield 4 plugin download Battlefield 4 Crashes, Tweaks, Errors, FPS, Graphics, Lag and Fixes. It’s time to experience the latest iteration in one of the biggest first-person shooter franchises. Battlefield 4 is here, and I am sure that PC gamers must be itching to test their machines with its jaw-dropping visuals. The game did well in the beta, and the full game is also looking good overall. However, there are small issues that can spoil the fun for you. DICE would be fixing things along, but if you are looking for workarounds, you can browse through the following listing. #1 Battlefield 4 – An Error Was Reported From EA Online Fix The developer is aware of the problem and they are working on a permanent fix. In the meanwhile, you can try out the following workaround: First, head to your Battlelog and click the Profile in the top-right corner. Select “Change Soldier,” and you should see a list of soldiers associated with your account, one of which will be Active and highlighted in green. Click the Active button next to one of your non-Active soldiers to set it as your primary, and then try to play Battlefield 4. If you still receive the above error, try setting different soldiers to active and attempting to play again. #2 Battlefield 4 – Origin Showing Overcharged Amount It was a bug in the client and EA is aware of it. The problem however, has been fixed now and you will be able to see the right amount on your bill. -

ELECTRONIC ARTS Q2 FY16 PREPARED COMMENTS October 29, 2015 CHRIS: Thank You. Welcome to EA's Fiscal 2016 Second Quarter Earni
ELECTRONIC ARTS Q2 FY16 PREPARED COMMENTS October 29, 2015 CHRIS: Thank you. Welcome to EA’s fiscal 2016 second quarter earnings call. With me on the call today are Andrew Wilson, our CEO, and Blake Jorgensen, our CFO . Peter Moore, our COO, will be joining us for the Q&A portion of the call. Please note that our SEC filings and our earnings release are available at ir.ea.com. In addition, we have posted earnings slides to accompany our prepared remarks. Lastly, after the call, we will post our prepared remarks, an audio replay of this call, and a transcript. A quick calendar note: our Q3 earnings call is scheduled for Thursday, January 28, 2016. This presentation and our comments include forward-looking statements regarding future events and the future financial performance of the Company. Actual events and results may differ materially from our expectations. We refer you to our most recent Form 10-Q for a discussion of risks that could cause actual results to differ materially from those discussed today. Electronic Arts makes these statements as of today, October 29, 2015 and disclaims any duty to update them. During this call unless otherwise stated, the financial metrics will be presented on a non-GAAP basis. Our earnings release and the earnings slides provide a reconciliation of our GAAP to non-GAAP measures. These non-GAAP measures are not intended to be considered in isolation from, as a substitute for, or superior to our GAAP results. We encourage investors to consider all measures before making an investment decision. -

Asus Rog Cg8890
#48 (655) 2013 Еженедельный компьютерный журнал Конкурсы от компаний Western Digital, IIyama и A4Tech Монитор Iiyama ProLite X2783HSU-1 Системный блок ASUS ROG CG8890 1 UPGRADE / содержание № 48 (655) 2013 http://upweek.ru CREATIVE AIRWAVE HD Портативная беспроводная колонка ...........................3 Новости ........................................................................................4 Конкурс от компании A4Tech ...........................................10 Конкурс от компании Western Digital ..........................16 Системный блок ASUS ROG CG8890 .............................18 Конкурс от компании IIYAMA ...........................................24 Фонарик HuntKey WX01-220-02 ......................................25 Опрос от журнала UPGRADE ............................................27 Мышь ZALMAN ZM-GM1 ....................................................37 Монитор Iiyama ProLite X2783HSU-1 ............................41 Гарнитура Creative Aurvana Live!2 ..................................45 Техподдержка №655 .............................................................48 «Сибирь» и «Острова» в домашнем хозяйстве .....54 Художники для каталогов Windows .............................60 КОНКУРСЫ От КОмпаНий 2 3 UPGRADE / новости / содержание № 48 (655) 2013 UPGRADE / новости / содержание № 48 (655) 2013 http://upweek.ru http://upweek.ru Портативный ния. Данная модель также отличается внешнего USB-накопителя. В техни- FTP-сервер для обмена файлами. Кли- светодиодный проектор P2B эргономичным дизайном с возможно- ческое -

Battlefield 4 Manual
TABLE OF CONTENT GAME OVERVIEW 3 BASIC INFANTRY CONTROLS 4 CAMPAIGN 7 MULTIPLAYER 14 TEST RANGE 47 BATTLEFIELD 4 STORE 48 BATTLELOG 49 ORIGIN ACCOUNT 52 SUPPORT 53 GAME OVERVIEW 3 BATTLEFIELD 4 Battlefield 4™ is the genre-defining action blockbuster made from moments that blur the line between game and glory. Fueled by the next-generation power and fidelity of DICE’s Frostbite™ 3 engine, Battlefield 4 provides a visceral, dramatic experience unlike any other shooter. BASIC INFANTRY CONTROLS 4 PC Move W/A/S/D Camera control Mouse Crouch C Toggle crouch X Prone Z Jump/vault Spacebar Battlelog Backspace Fire weapon Left click Aim Right click BASIC INFANTRY CONTROLS 5 PC Reload R Pick up item R (hold) Engage (Campaign), Spotting (Multiplayer) Q Tactical visor (Campaign), CommoRose (Multiplayer) Q (hold) Weapon slots 1/2/3/4/5 Throw grenade G Use knife F Interact E Fire mode V BASIC INFANTRY CONTROLS 6 PC Flashlight (when available) T All chat J Team chat K Squad chat L Scoreboard Tab Game menu Esc Vehicle slots F1-F6 NOTE: For a full overview of controls, or to choose your preferred controls configuration, please select OPTIONS in the game menu. CAMPAIGN 7 Battlelog widget GAME SCREEN Engage target Detection Indicator Objective text Engage status Objective direction Ammo (magazine/total) Fire mode Map Health Inventory access buttons Grenades CAMPAIGN 8 STORY China is in turmoil. There are riots in the streets of Shanghai. People are enraged because of the assassination of Jin Jié. He was on deck for the presidency — a progressive man of the people who pushed the government for transparency, fairness, and freedom of speech. -

China's Digital Game Sector
May 17, 2018 China’s Digital Game Sector Matt Snyder, Analyst, Economics and Trade Acknowledgments: The author thanks Lisa Hanson, Dean Takahashi, and Greg Pilarowski for their helpful insights. Their assistance does not imply any endorsement of this report’s contents, and any errors should be attributed solely to the author. Disclaimer: This paper is the product of professional research performed by staff of the U.S.-China Economic and Security Review Commission, and was prepared at the request of the Commission to support its deliberations. Posting of the report to the Commission’s website is intended to promote greater public understanding of the issues addressed by the Commission in its ongoing assessment of U.S.- China economic relations and their implications for U.S. security, as mandated by Public Law 106-398 and Public Law 113-291. However, the public release of this document does not necessarily imply an endorsement by the Commission, any individual Commissioner, or the Commission’s other professional staff, of the views or conclusions expressed in this staff research report. Table of Contents Executive Summary....................................................................................................................................................3 China’s Digital Game Market ....................................................................................................................................3 Importance of the Digital Game Sector to the U.S. Economy ....................................................................................8 -

Stevens, RC and Raybould, D (2015) the Reality Paradox: Authenticity, fidelity, and the Real in Battle- field 4
Citation: Stevens, RC and Raybould, D (2015) The reality paradox: Authenticity, fidelity, and the real in Battle- field 4. The Soundtrack, 8 (1-2). 57 - 75. ISSN 1751-4207 DOI: https://doi.org/10.1386/st.8.1-2.57_1 Link to Leeds Beckett Repository record: https://eprints.leedsbeckett.ac.uk/id/eprint/2216/ Document Version: Article (Accepted Version) The aim of the Leeds Beckett Repository is to provide open access to our research, as required by funder policies and permitted by publishers and copyright law. The Leeds Beckett repository holds a wide range of publications, each of which has been checked for copyright and the relevant embargo period has been applied by the Research Services team. We operate on a standard take-down policy. If you are the author or publisher of an output and you would like it removed from the repository, please contact us and we will investigate on a case-by-case basis. Each thesis in the repository has been cleared where necessary by the author for third party copyright. If you would like a thesis to be removed from the repository or believe there is an issue with copyright, please contact us on [email protected] and we will investigate on a case-by-case basis. The Reality Paradox: Authenticity, fidelity and the real in Battlefield 4 Richard Stevens and Dave Raybould, with additional contributions from Ben Minto, Audio Director Battlefield 4.1 Although the interactive medium of video games is often referred to as non-linear, since progression through the game may follow different paths on repeated playthroughs, it is typically much more linear than the medium of film with respect to its treatment of time and space. -

Battlefield 5 Ps4 Download Time Battlefield V Among Playstation Plus’ Free Games for May
battlefield 5 ps4 download time Battlefield V among PlayStation Plus’ free games for May. Battlefield V is one of the three free games coming for PlayStation Plus subscribers next month, Sony announced today. The most recent title in EA’s long-running shooter series, BFV was first released in 2018. With rumors of a new Battlefield circulating recently, adding it to PS Plus’ collection of free games could be a boon to its player base. It will be playable on both PS4 and PS5, although it’s native to PS4. Image via PlayStation. After the hugely popular Battlefield 4 in 2013, EA and Dice came out with the police-centric Battlefield Hardline in 2015, World War I-era Battlefield 1 in 2016, and a return to World War II with Battlefield V. The month’s other free games are the PS5 version of destruction derby racer Wreckfest and open water survival PS4 game Stranded Deep . April’s free games, Oddworld: Soulstorm, Days Gone, and Zombie Army 4: Dead War , will be available until May 3. Three free games are included as a part of Sony’s $60 a year subscription service, which allows players to play online. It also includes the PlayStation Plus Collection, a group of PS4 games free to download at any time. All three May games will be available for active PS Plus subscribers from May 4 to 31, so make sure to grab them before they’re gone. PS Plus May 2021 countdown: PS4, PS5 free games release time - Battlefield 5, Wreckfest. We use your sign-up to provide content in ways you've consented to and to improve our understanding of you. -

Battlefield 4-Eu Eula Applicable to You
IMPORTANT NOTICE TO RESIDENTS OF THE EUROPEAN UNION: PLEASE SCROLL DOWN TO REVIEW THE BATTLEFIELD 4-EU EULA APPLICABLE TO YOU. ELECTRONIC ARTS SOFTWARE END USER LICENSE AGREEMENT BATTLEFIELD 4 This End User License Agreement (“License”) is an agreement between you and Electronic Arts Inc., its subsidiaries and affiliates (“EA”). This License governs your use of this software product and all related documentation, and updates and upgrades that replace or supplement the software in any respect and which are not distributed with a separate license (collectively, the "Software"). This Software is licensed to you, not sold. By installing or using the Software, you agree to the terms of this License and agree to be bound by it. Section 2 below describes the data EA may use to provide services and support to you in connection with the Software. If you do not agree to this use of data, do not install or use the Software. Section 16, below, provides that any disputes must be resolved by binding arbitration on an individual basis. IF YOU INSTALL the Software, the terms and conditions of this License are fully accepted by you. If you do not agree to the terms of this License, then do not install or use the Software. Right to Return (Applicable To Those Who Purchased Packaged Software From Physical Retail Stores In the United States). If you do not agree to the terms of this License or the Origin Software Application License and you have not fully installed or used the Software, you may return the Software for a refund or exchange within thirty (30) days from the date of purchase to the original place of purchase by following the instructions for return available at http://warrantyinfo.ea.com. -

The Developing World's Depiction in the Battlefield and Call of Duty
BAROMETR REGIONALNY TOM 13 NR 1 The Developing World’s Depiction in the Battlefield and Call of Duty Video Game Series. Does It Replicate the Stereotypical Image? Krzysztof Ząbecki University of Warsaw, Poland Abstract The purpose of this paper is to analyze how the Third World is presented in the highly popular Battle- field and Call of Duty video game series and whether the games replicate the Global South’s stereotypi- cal image. In the introduction, the term “stereotype” is defined, countries or regions to be considered “developing” are distiguished, and the choice of video games to be examined in the study is made. Then, the content of the chosen games is analyzed in order to find elements of the environment that are rep- resented, the sides of the depicted conflicts, their place and background, as well as playable characters and enemies. In the conclusion, the developing world’s depiction is compared to the already existing sterotypes in order to decide to what extent and in what aspects video games repeat them. Keywords: developing world, stereotype, video game, call of duty, battlefield Introduction In recent years, video games have become one of the most important and fastest developing media in the world, even though the video game market is difficult to estimate due to its decentralised character . Nonetheless, the wide and still growing popularity of video games is an undeniable fact, and the Battlefield and Call of Duty series are among the best known of them . The rising im- portance of virtual entertainment raises interest of scientists within different disciplines, although game studies are the discipline that focuses primarily on games . -
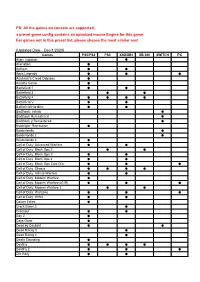
The Games on Console Are Supported, a Preset Game Config Contains an Optmized Mouse Engine for This Game
PS: All the games on console are supported, a preset game config contains an optmized mouse Engine for this game. For games not in this preset list, please choose the most similar one! (Updated Date:Dec/1/2020) Games PS5/PS4 PS3 XSX/XB1 XB 360 SWITCH PC Alien: Isolation ● Alienation ● Anthem ● ● Apex Legends ● ● ● Assassin's Creed Odyssey ● Assetto Corsa ● Battlefield 1 ● ● Battlefield 3 ● ● Battlefield 4 ● ● ● ● Battlefield V ● ● Battlefield Hardline ● ● BioShock: Infinite ● BioShock Remastered ● BioShock 2 Remastered ● Blacklight: Retribution ● Borderlands ● Borderlands 2 ● Borderlands 3 ● Call of Duty: Advanced Warfare ● ● Call of Duty: Black Ops 2 ● ● Call of Duty: Black Ops 3 ● ● Call of Duty: Black Ops 4 ● ● Call of Duty: Black Ops Cold War ● ● ● Call of Duty: Ghosts ● ● ● ● Call of Duty: Infinite Warfare ● ● Call of Duty: Modern Warfare ● Call of Duty: Modern Warfare(2019) ● ● ● Call of Duty: Modern Warfare 3 ● ● Call of Duty: Warzone ● ● ● Call of Duty: WWII ● ● Conan Exiles ● Crack Down 3 ● Crossout ● ● Day Z ● Days Gone ● Dead by Daylight ● ● Dead Rising 3 ● Dead Rising 4 ● Death Stranding ● Destiny ● ● ● ● Destiny 2 ● ● ● Dirt Rally ● ● DIRT 4 ● DJMax Respect ● Doom ● ● ● Doom: Eternal ● DriveClub ● Dying Light ● ● Evolve ● ● F1 2015~2020 ● Fallout 4 ● ● Far Cry 3 ● Far Cry 4 ● Far Cry 5 ● ● Far Cry Primal ● ● For Honor ● Fortnite: Battle Royale ● ● ● Forza 5~7 ● Forza Horizon 2~4 ● Gears of War 3 ● Gears of War 4 ● Gears of War 5 ● Gears of War: Ultimate Edition ● Ghost Recon: Rreakpoint ● Ghost Recon: Wildlands ● ● Grand Theft -

Asus Rog Cg8890 Мышь Zalman Zm-Gm1 Upgrade / Содержание № 48 (655) 2013
№№48 39 (655)(646) 20132013 Еженедельный Еженедельный компьютерный компьютерный журнал журнал Конкурсы от компаний Western Digital, IIyama и A4Tech Монитор Iiyama ProLite X2783HSU-1 Системный блок ASUS ROG CG8890 Мышь ZALMAN ZM-GM1 UPGRADE / содержание № 48 (655) 2013 CREATIVE AIRWAVE HD Портативная беспроводная колонка .........................3 Новости .....................................................................................4 Конкурс от компании Western Digital.........................6 Конкурс от компании A4Tech .........................................21 Конкурс от компании IIYAMA .........................................32 Системный блок ASUS ROG CG8890 ...........................34 Опрос от журнала UPGRADE ..........................................47 Мышь ZALMAN ZM-GM1 ..................................................62 Фонарик HuntKey WX01-220-02 ....................................69 Монитор Iiyama ProLite X2783HSU-1 ..........................73 Гарнитура Creative Aurvana Live!2.................................81 Техподдержка №655 ...........................................................88 «Сибирь» и «Острова» в домашнем хозяйстве ......................................................101 Художники для каталогов Windows ............................113 КОНКУРСЫ От КОмпаНий 2 3 UPGRADE / содержание № 48 (655) 2013 Портативный светодиодный проектор P2B Модель ASUS P2B способна проецировать изображение с разрешением 1280x800 пиксе- лей, полностью воспроизводя все оттенки из цветового пространства NTSC. Срок службы ее -
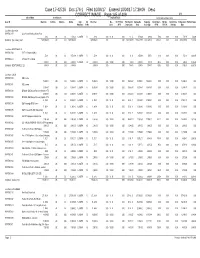
Case 17-42726 Doc 174-1 Filed 10/04/17 Entered 10
Case 17-42726 Doc 174-1 Filed 10/04/17 Entered 10/04/17 17:39:09 Desc CORRECT IMAGE Page 145 of 409 218 Selected Dates Asset Balances Depreciable Basis Current & Accum Depreciation Asset ID Beginning Additions Deletions Ending Depr Life Book Cost Bus. Net S179/A & Prior Reported Depreciable Beginning Current Depr & Net Sec Net Additions Ending Accum Net Book Value Meth/Conv Yr Mo Use % AFYD Depreciation Basis Accum Depr AFYD 179/179A Deletions Depr Location: {no value} WYNIT002117 Cisco Aironet Wireless Access Point 1,058.46 0.00 0.00 1,058.46 SL100FM 5 0 1,058.46 0.00 100.00 0.00 317.54 1,058.46 493.94 17.64 0.00 0.00 511.58 546.88 Subtotal: {no value} (122) 2,678,564.00 0.00 0.00 2,678,564.00 2,678,564.00 0.00 0.00 2,632,349.99 2,574,427.95 2,672,448.20 3,932.30 0.00 0.00 2,676,380.50 2,183.50 Location: BENTONVILLE WYNIT002564 70" TV - Bentonville Office 3,553.99 0.00 0.00 3,553.99 SL100FM 7 0 3,553.99 0.00 100.00 0.00 84.62 3,553.99 507.72 42.30 0.00 0.00 550.02 3,003.97 WYNIT002570 80" Sharp TV - w Stand 4,180.35 0.00 0.00 4,180.35 SL100FM 7 0 4,180.35 0.00 100.00 0.00 99.53 4,180.35 597.19 49.76 0.00 0.00 646.95 3,533.40 Subtotal: BENTONVILLE (2) 7,734.34 0.00 0.00 7,734.34 7,734.34 0.00 0.00 184.15 7,734.34 1,104.91 92.06 0.00 0.00 1,196.97 6,537.37 Location: COLO WYNIT001590 SQL License 10,494.87 0.00 0.00 10,494.87 SL100FM 3 0 10,494.87 0.00 100.00 0.00 10,494.87 10,494.87 10,494.87 0.00 0.00 0.00 10,494.87 0.00 WYNIT001591 SQL License 10,494.87 0.00 0.00 10,494.87 SL100FM 3 0 10,494.87 0.00 100.00 0.00 10,494.87 10,494.87 10,494.87