Automated Evolution of Feature Logging Statement Levels Using Git Histories and Degree of Interest
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Solaris Und Opensolaris Eine Sinnvolle Alternative?
Solaris und OpenSolaris Eine sinnvolle Alternative? Wolfgang Stief best Systeme GmbH MUCOSUG, GUUG e. V. [email protected] 2009-11-23 Agenda OpenSolaris, Solaris Express, Solaris Community Edition Das „Open“ in OpenSolaris Community, Lizenzen, Projects Features Container/Zones, ZFS, DTrace, Crossbow ... Und warum dann nicht gleich Linux? Solaris und OpenSolaris – eine sinnvolle Alternative? pg 2 OpenSolaris? Enterprise PowerNetwork ManagementVirtualization Installation Open Containers Storage CIFS Security Network- DTraceNetwork Based ZFS Auto- Packaging Predictive Magic Self Healing Hardware Time Optimizaton Slider Solaris und OpenSolaris – eine sinnvolle Alternative? pg 3 OpenSolaris Binary Distribution http://www.opensolaris.com stabiler, getester Code Support möglich erscheint ca. 2x jährlich, x86 und SPARC aktuelle Pakete (GNOME etc.), Installer neues Paketformat, Repositories ähnlich Debian aktuell (noch) 2009.06 Solaris und OpenSolaris – eine sinnvolle Alternative? pg 4 OpenSolaris Source Code http://www.opensolaris.org ab Juni 2005: zunächst DTrace, dann sukzessive weitere Teile aktive Community Source Browser OpenGrok http://src.opensolaris.org/ Features werden in „Projects“ entwickelt Community Release 2-wöchentlich (b127) „BFU“ nach Bedarf (blindingly fast upgrade) Solaris und OpenSolaris – eine sinnvolle Alternative? pg 5 OpenSolaris Community Launch am 14. Juni 2005 mehrere Distributionen aus der Community Schillix, Belenix, Nexenta, Milax, StormOS, OSUNIX Stand Frühjahr 2009 (ca. 3½ Jahre): → 116.000 registrierte Mitglieder -

Jenkins Job Builder Documentation Release 3.10.0
Jenkins Job Builder Documentation Release 3.10.0 Jenkins Job Builder Maintainers Aug 23, 2021 Contents 1 README 1 1.1 Developers................................................1 1.2 Writing a patch..............................................2 1.3 Unit Tests.................................................2 1.4 Installing without setup.py........................................2 2 Contents 5 2.1 Quick Start Guide............................................5 2.1.1 Use Case 1: Test a job definition................................5 2.1.2 Use Case 2: Updating Jenkins Jobs...............................5 2.1.3 Use Case 3: Working with JSON job definitions........................6 2.1.4 Use Case 4: Deleting a job...................................6 2.1.5 Use Case 5: Providing plugins info...............................6 2.2 Installation................................................6 2.2.1 Documentation.........................................7 2.2.2 Unit Tests............................................7 2.2.3 Test Coverage..........................................7 2.3 Configuration File............................................7 2.3.1 job_builder section.......................................8 2.3.2 jenkins section.........................................9 2.3.3 hipchat section.........................................9 2.3.4 stash section...........................................9 2.3.5 __future__ section.......................................9 2.4 Running.................................................9 2.4.1 Test Mode........................................... -

E-Mail: [email protected] , Phone: +61 (412) 421-925
Joshua M. Clulow E-mail: [email protected] , Phone: +61 (412) 421-925 TECHNICAL Software Development: SKILLS • Proficient in many high-level programming languages including Javascript (node.js), C, Java, Korn Shell (ksh), awk, etc. • Web application development with particular focus on delegated administration tools • System programming with particular focus on distributed job control and au- tomation • Kernel-level development and debugging of Illumos with mdb(1) and DTrace, with recent focus on porting support for the AMD-V instruction set extensions from Linux to Illumos KVM See: https://github.com/jclulow/illumos-kvm • Kernel-level development and debugging of OpenBSD with ddb and gdb, most recently due to my final year engineering project to create a single-system image cluster of OpenBSD machines See: https://jmc.sysmgr.org/~leftwing/files/fyp.pdf System Administration: • A range of operating systems including Illumos, Solaris, BSD, Linux, Mac OS and Windows • Web servers including Apache and Sun Web Server • Web proxies including Squid and Sun Proxy Server • Java application servers including Glassfish and Tomcat • Networking concepts including DHCP, DNS, IP networks (subnetting and rout- ing) and Firewalls • Solaris-specific technologies including Zones, SMF, ZFS and DTrace • Sun Cluster for highly available and load balanced systems • F5 BIG-IP Load Balancers • Sun 7000-series Unified Storage Systems • Entry-level and mid-range Sun x86 and SPARC hardware • Discrete servers and Blade systems EMPLOYMENT UNIX System Administrator (Manager) -

Professional Summary Professional Experience
Email: [email protected] Mobile: +91-7892635293 AKASH A versatile, high-energy android native mobile application developer with the distinction of executing prestigious projects of large magnitude within strict time schedule. PROFESSIONAL SUMMARY ➢ 2+years of experience in Android native Application software development. ➢ Currently working at Sidsoft Pvt Ltd as a Software Engineer. ➢ Expertise in building mobile applications using Android. ➢ Back-end experience with Realm. ➢ Mainly worked with Windows and Linux. ➢ Good understanding of core Java. ➢ Worked in several Fast-Paced Environments and delivered stiff project deadlines. ➢ Strong ability to work, learn and collaborate with new teams and technologies. ➢ Always in pursuit to learn and apply industry best practices. ➢ Strong analytical and problem resolution skills. ➢ Capability to work independently, as well as within a team to meet deadlines. ➢ Good written and oral communication skills. ➢ Good understanding of the full mobile development life cycle. ➢ Defining and using Linear Layout, Relative Layout Creating and using Views. ➢ Good understanding of Activities, Activity life cycle and Intents. ➢ Good in creating Toasts, Alert Dialogue and Push Notifications (FCM & POSTMAN Client). ➢ Good Knowledge about the Pushing &Pulling Code into Git & Github Good knowledge about SQLite Helper, XML and JSON (Http Calls). ➢ Good Knowledge on REST API calls and Google Map integration. ➢ Complete Hands on Experience on publishing App into play store, update and adding Google Crash analytics. -

Openjdk – the Future of Open Source Java on GNU/Linux
OpenJDK – The Future of Open Source Java on GNU/Linux Dalibor Topić Java F/OSS Ambassador Blog aggregated on http://planetjdk.org Java Implementations Become Open Source Java ME, Java SE, and Java EE 2 Why now? Maturity Java is everywhere Adoption F/OSS growing globally Innovation Faster progress through participation 3 Why GNU/Linux? Values Freedom as a core value Stack Free Software above and below the JVM Demand Increasing demand for Java integration 4 Who profits? Developers New markets, new possibilities Customers More innovations, reduced risk Sun Mindshare, anchoring Java in GNU/Linux 5 License + Classpath GPL v2 Exception • No proprietary forks (for SE, EE) • Popular & trusted • Programs can have license any license • Compatible with • Improvements GNU/Linux remain in the community • Fostering adoption • FSFs license for GNU Classpath 6 A Little Bit Of History Jun 1996: Work on gcj starts Nov 1996: Work on Kaffe starts Feb 1998: First GNU Classpath Release Mar 2000: GNU Classpath and libgcj merge Dec 2002: Eclipse runs on gcj/Classpath Oct 2003: Kaffe switches to GNU Classpath Feb 2004: First FOSDEM Java Libre track Apr 2004: Richard Stallman on the 'Java Trap' Jan 2005: OpenOffice.org runs on gcj Mai 2005: Work on Harmony starts 7 Sun & Open Source Java RIs Juni 2005: Java EE RI Glassfish goes Open Source Mai 2006: First Glassfish release Mai 2006: Java announced to go Open Source November 2006: Java ME RI PhoneME goes Open Source November 2006: Java SE RI Hotspot und Javac go Open Source Mai 2007: The rest of Java SE follows suit 8 Status: JavaOne, Mai 2007 OpenJDK can be fully built from source, 'mostly' Open Source 25,169 Source code files 894 (4%) Binary files (“plugs”) 1,885 (8%) Open Source, though not GPLv2 The rest is GPLv2 (+ CP exception) Sun couldn't release the 4% back then as free software. -

Annual Report
The Document Founda��on 2016 Annual Report Document Liberation Own your content Welcome This annual report is the sixth chapter in the story of a long journey, started by a group of people that were sharing the common goal of create something new – finally made by the community, for the community. Today, public administraons, enterprises and individual users worldwide can reap the benefits of the hard work made by a constantly growing community of volunteers and supporters. The report is a showcase of the acvies of the foundaon. Looking back, we have accomplished a large number of objecves in 2016 and we are on track for 2017. We have funded improvements to the organizaon and the product, and supported local acvies carried out by nave language projects. Behind the scenes, the foundaon is growing thanks to the commitment of an amazing group of people, with dozens of volunteers in every geography, and a Photo: Maeo G.P. Flora, CC BY-ND 2.5 few paid staff - led by Florian Effenberger - who take care of daily acvies related to documentaon, localizaon, markeng, design, development, QA, websites and system administraon. The management of a foundaon is somemes complicated; o5en you are called to take important decisions achieved only a5er longer debates. Thanks to the diverse approaches and aptudes the Directors are also focusing on new goals for keeping TDF in the right direcon. I would personally thank Thorsten Behrens, Osvaldo Gervasi, Jan Holesovsky, Andreas Mantke, Michael Meeks, Björn Michaelsen, Simon Phipps, Eike Rathke and Norbert Thiebaud for their big commitment to guide the foundaon where is it today. -

NSWI 0138: Advanced Unix Programming
NSWI 0138: Advanced Unix programming (c) 2011-2016 Vladim´ırKotal (c) 2009-2010 Jan Pechanec, Vladim´ırKotal SISAL MFF UK, Malostransk´en´am.25, 118 00 Praha 1 Charles University Czech Republic Vladim´ırKotal [email protected] March 10, 2016 1 Vladim´ırKotal NSWI 0138 (Advanced Unix programming) Contents 1 Overview 5 1.1 What is this lecture about? . .5 1.2 The lecture will cover... .5 1.3 A few notes on source code files . .6 2 Testing 6 2.1 Why?...........................................6 2.2 When ? . .6 2.3 Types of testing . .7 3 Debugging 8 3.1 Debuging in general . .8 3.2 Observing . .9 3.3 Helper tools . .9 3.3.1 ctags . .9 3.3.2 cscope . 10 3.3.3 OpenGrok . 11 3.3.4 Other tools . 11 3.4 Debugging data . 11 3.4.1 stabs . 11 3.4.2 DWARF . 12 3.4.3 CTF (Compact C Type Format) . 12 3.5 Resource leaks . 13 3.6 libumem . 13 3.6.1 How does libumem work . 14 3.6.2 Using libumem+mdb to find memory leaks . 14 3.6.3 How does ::findleaks work . 16 3.7 watchmalloc . 17 3.8 Call tracing . 18 3.9 Using /proc . 19 3.10 Debugging dynamic libraries . 20 3.11 Debuggers . 20 3.12 Symbol search and interposition . 20 3.13 dtrace . 21 4 Terminals 21 4.1 Terminal I/O Overview . 21 4.2 Terminal I/O Overview (cont.) . 22 4.3 Physical (Hardware) Terminal . 24 4.4 stty(1) command . 24 4.5 TTY Driver Connected To a Phy Terminal . -

Towards Automated Software Evolution of Data-Intensive Applications
City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects CUNY Graduate Center 6-2021 Towards Automated Software Evolution of Data-Intensive Applications Yiming Tang The Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/4406 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] Towards Automated Software Evolution of Data-intensive Applications by Yiming Tang A thesis submitted to the Graduate Faculty in Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy, The City University of New York. 2021 ii © 2021 Yiming Tang All Rights Reserved iii Towards Automated Software Evolution of Data-intensive Applications by Yiming Tang This manuscript has been read and accepted for the Graduate Faculty in Computer Science in satisfaction of the dissertation requirement for the degree of Doctor of Philosophy. May 14, 2021 Raffi Khatchadourian Date Chair of Examining Committee May 14, 2021 Ping Ji Date Executive Officer Supervisory Committee: Raffi Khatchadourian, Advisor Subash Shankar Anita Raja Mehdi Bagherzadeh THE CITY UNIVERSITY OF NEW YORK Abstract Towards Automated Software Evolution of Data-intensive Applications by Yiming Tang Advisor: Raffi Khatchadourian Recent years have witnessed an explosion of work on Big Data. Data-intensive appli- cations analyze and produce large volumes of data typically terabyte and petabyte in size. Many techniques for facilitating data processing are integrated into data- intensive applications. -

Codecompass an Open Software Comprehension Framework
CodeCompass an Open Software Comprehension Framework Zoltán Porkoláb1,2, Dániel Krupp1, Tibor Brunner2, Márton Csordás2 https://github.com/Ericsson/CodeCompass Motto: If it was hard to write it should be hard to understand -- unknown programmer 1Ericsson Ltd, 2Eötvös Loránd University, Budapest, Hungary Agenda • Comprehension as a cost factor • Why development tools are not perfect for comprehension? • Requirements • Architecture • A few workflows • Restrictions • Experiences • Further planes 3/27/2017 CodeCompass 2 Comprehension is a major cost factor Research Effort for comprehension IBM (Corbi, 1989) Over 50% of time Bell Labs (Davison, 1992) New project members: 60-80% of time, drops to 20% as one gains experience National Research Council in Over 25% of time either searching for or Canada (Singer, 2006) looking at code Microsoft (Hallam, 2006) Equal amount of time as design, test Microsoft (La Toza, 2007) Over 70% of time Microsoft (Cherubini, 2007) 95%~ significant part of job 65%< at least once a day 25%< multiple times of a day 3/27/2017 CodeCompass 3 Using tools 3/27/2017 CodeCompass 4 Using tools 3/27/2017 CodeCompass 5 Using tools 3/27/2017 CodeCompass 6 Using tools 3/27/2017 CodeCompass 7 Comprehension requires specific toolset Development of code Understanding code Writing new code Reading and navigating inside code (support: code completion, etc.) Intentions are clear Intensions are weak Editing only a few files at the same Frequently jumping between different time files Working on the same abstraction Jumping between various -

Dynamic Tracing with Dtrace & Systemtap
Dynamic Tracing with DTrace SystemTap Sergey Klyaus Copyright © 2011-2016 Sergey Klyaus This work is licensed under the Creative Commons Attribution-Noncommercial-ShareAlike 3.0 License. To view a copy of this license, visit https://creativecommons.org/licenses/by-nc-sa/3.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA. Table of contents Introduction 7 Foreword . 7 Typographic conventions . 9 TSLoad workload generator . 12 Operating system Kernel . 14 Module 1: Dynamic tracing tools. dtrace and stap tools 15 Tracing . 15 Dynamic tracing . 16 DTrace . 17 SystemTap . 19 Safety and errors . 22 Stability . 23 Module 2: Dynamic tracing languages 25 Introduction . 25 Probes . 27 Arguments . 33 Context . 34 Predicates . 35 Types and Variables . 37 Pointers . 40 Strings and Structures . 43 Exercise 1 . 44 Associative arrays and aggregations . 44 Time . 48 Printing and speculations . 48 Tapsets translators . 50 Exercise 2 . 52 Module 3: Principles of dynamic tracing 54 Applying tracing . 54 Dynamic code analysis . 55 Profiling . 61 Performance analysis . 65 Pre- and post-processing . 66 Vizualization . 70 Module 4: Operating system kernel tracing 74 Process management . 74 3 Exercise 3 . 86 Process scheduler . 87 Virtual Memory . 105 Exercise 4 . 116 Virtual File System . 116 Block Input-Output . 122 Asynchronicity in kernel . 131 Exercise 5 . 132 Network Stack . 134 Synchronization primitives . 138 Interrupt handling and deferred execution . 143 Module 5: Application tracing 146 Userspace process tracing . 146 Unix C library . 149 Exercise 6 . 152 Java Virtual Machine . 153 Non-native languages . 160 Web applications . 165 Exercise 7 . 172 Appendix A. Exercise hints and solutions 173 Exercise 1 . -
LFN 2020-07 Report.Pdf
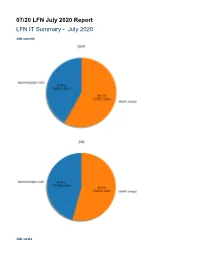
07/20 LFN July 2020 Report LFN IT Summary - July 2020 Job counts Job costs Key Takeaways: ODL had 70.68% of the total job costs this month and odl-csit was the highest job category cost (integration testing) ODL and ONAP both had higher operational runs for July, the calculated data is with an expected variance given the increase in job runs that was seen in both projects Caveats: New Feature of Global Jenkins Job Builder provides build data where available (work in progress) Job counts are an indication of how much change happened to the code bases Total costs are based on cost data returned from cloud compute resources used for the duration of a job Only ODL and ONAP are included for now, as their standard tooling provides the best coverage. We are looking into ways to include more projects in the future. Support Charts: LFN Dashboard Link July 2020 Tickets Service Desk (By Type) and Planned Engineering (By Type) LFN Work from Last Month (Created vs Resolved) LFN Work from Last 3 Months (Created vs Resolved) Key Takeaways: Worked on 208 LFN tickets (up from 180 last month, 124 from Service Desk and 84 from Planned Engineering) ONAP was the top project with 87 tickets (up from 53 last month) Get IT Help is the highest source of Service Desk requests followed by Jenkins Jobs problems and Additional permissions requests After tech debt, migrating project Gerrit to Auth0 and ONAP: Post Frankfurt release work were the highest source of planned engineering work Projects Highlights (July 2020): ONAP: Reconfigured Jenkins, JIRA, Confluence, Nexus 3 for Auth0 integration Deprecated sonar.onap.org and sonarqube. -

Universal Ctags Documentation Release 0.3.0
Universal Ctags Documentation Release 0.3.0 Universal Ctags Team 22 September 2021 Contents 1 Building ctags 2 1.1 Building with configure (*nix including GNU/Linux)........................2 1.2 Building/hacking/using on MS-Windows..............................4 1.3 Building on Mac OS.........................................7 2 Man pages 9 2.1 ctags.................................................9 2.2 tags.................................................. 33 2.3 ctags-optlib.............................................. 40 2.4 ctags-client-tools........................................... 46 2.5 ctags-incompatibilities........................................ 53 2.6 ctags-faq............................................... 56 2.7 ctags-lang-inko............................................ 62 2.8 ctags-lang-iPythonCell........................................ 62 2.9 ctags-lang-julia............................................ 63 2.10 ctags-lang-python.......................................... 65 2.11 ctags-lang-r.............................................. 69 2.12 ctags-lang-sql............................................. 70 2.13 ctags-lang-tcl............................................. 72 2.14 ctags-lang-verilog.......................................... 73 2.15 readtags................................................ 76 3 Parsers 81 3.1 Asm parser.............................................. 81 3.2 CMake parser............................................. 81 3.3 The new C/C++ parser........................................ 82 3.4 The