Analysis of NBA Team Strength Using Players' Race Data Based on Clustering Method
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2011-12 Pac-12 Men's Basketball Standings
For Immediate Release: February 6, 2012 Contacts: Dave Hirsch ([email protected]), Sarah Kezele ([email protected]) 2011-12 PAC-12 MEN’S BASKETBALL STANDINGS PAC-12 OVERALL W-L Pct. Home Away W-L Pct. Home Away Neut. AP Coach vs. T25 Streak Washington 9-2 .818 6-1 3-1 16-7 .696 13-2 3-3 0-2 - - 0-2 Won 5 California 8-3 .727 6-1 2-2 18-6 .750 15-1 2-4 1-1 - t36 0-2 Won 1 Colorado 8-3 .727 7-0 1-3 16-7 .696 13-1 2-4 1-2 - - 0-0 Won 2 Oregon 7-4 .636 3-2 4-2 16-7 .696 11-3 5-3 0-1 - - 0-1 Lost 1 Arizona 7-4 .636 3-2 4-2 16-8 .667 10-3 5-3 1-2 - - 0-1 Won 2 Stanford 6-5 .545 5-1 1-4 16-7 .696 12-2 3-4 1-1 - - 0-1 Lost 1 UCLA 6-5 .545 4-0 2-5 13-10 .565 10-3 2-5 1-2 - - 0-2 Won 1 Oregon State 5-6 .455 3-1 2-5 15-8 .652 10-2 4-5 1-1 - - 0-1 Won 1 Washington State 4-7 .364 4-2 0-5 12-11 .522 10-2 1-6 1-3 - - 0-1 Lost 1 Arizona State 3-8 .273 2-2 1-6 7-16 .304 4-8 2-6 1-2 - - 0-0 Lost 2 Utah 2-9 .182 2-4 0-5 5-18 .217 5-7 0-8 0-3 - - 0-0 Lost 4 USC 1-10 .091 1-4 0-6 6-18 .250 4-8 1-9 1-1 - - 0-0 Lost 2 THIS WEEK’S SCHEDULE AROUND THE PAC-12 Thurs., Feb. -

Game 10 2009-10 Georgetown Basketball Harvard (7-2) at No. 14
2009-10 GEORGETOWN BASKETBALL Harvard (7-2) at No. 14/13 Georgetown (8-1) Wednesday, Dec. 22, 2009 • noon (ET) McDonough Arena • Washington, D.C. Georgetown Sports Information | www.guhoyas.com Senior Communications Director | Bill Shapland | 202-687-2492 | [email protected] Sports Information Director | Mike “Mex” Carey | 202-687-2475 | [email protected] Game 10 Today’s Top 10 from the Hilltop TODAy’s GAME 10 Years as a head coach for Georgeotwn’s John Thompson III, Tipoff – none who has a 192-94 all-time record, including a 124-52 record on the TV – none Internet – Live video of the game will be available on the Georgetown Athlet- Hilltop. ics website – www.guhoyas.com 9 Games against teams ranked in the top-20 in the RPI Ratings Radio – ESPN980 AM; Rich Chvotkin handles the call the Hoyas will play this year – Temple (2), St. John’s (13), UConn (5), Coach – John Thompson III is in his sixth season at the helm of the Hoyas Villanova (11), Syracuse (8), Duke (1) and West Virginia (6). The ... In five years at Georgetown, Thompson has led the Hoyas to the 2007 NCAA Hoyas play Villanova and Syracuse twice. Final Four, the 2007 BIG EAST Tournament Championship and two-straight BIG EAST Regular crowns (2006-07, 2007-08) ... He has a record of 124-52 8 Times that John Thompson III-coached teams have beaten at Georgetown and a nine-year record of 192-94, including a 68-42 record at Harvard (Princeton was 8-0 against the Crimson). Princeton ... The Hoyas have made the postseason every year since JTIII took 7 Underclassmen on the Georgetown roster this season – the over the program in 2004-05. -

Seniors Consider Military Test Important New Schedule Requires
THEOur Vision: “Successful-LAKER Now and Beyond” REVIEWOur Mission: “Learners for Life” Volume 40 Calloway County High School Issue 1 2108 College Farm Road, Murray, Ky. 42071 September 20, 2019 2019 Homecoming Queen Seniors consider military test important Rainey Gaddie military.” required like it was in the past.” Staff Writer Crouse added that 12 students Some people think it’s pointless signed up to take the test. to take the test if they aren’t going For the first time in many years, Seniors who took the test last into the military, but it’s also about juniors were not required to take year caution against not taking it. what skills they have and what the Armed Services Vocational Senior Jessica Wicker said, “I they excel in. Aptitude Battery (ASVAB), a test thought taking the ASVAB was Senior Jack Daughaday had used to determine qualification for really helpful to a lot of students, some input on the topic. enlistment in the United States myself included. I think it should “I think that the ASVAB is an- Armed Forces. be a requirement because there other standardized test that could Principal Chris King said, “It are a lot of kids it would benefit. help students prepare for the ACT used to be that it had to be one of Also, if someone decides he wants or SAT. Personally, after taking the things that the state used to to pursue a career in the military the ASVAB, my ACT score went determine if you were transition and he hasn’t taken the ASVAB at up by two points, which can mean ready or not; that’s no longer the school, he only has one opportuni- everything to some students. -
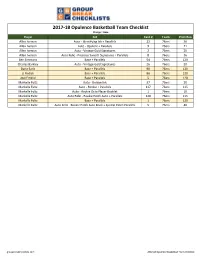
2017-18 Opulence Basketball Team Checklist
2017-18 Opulence Basketball Team Checklist Orange = Base Player Set Card # Team Print Run Allen Iverson Auto - Identifying Ink + Parallels 22 76ers 36 Allen Iverson Auto - Opulent + Parallels 9 76ers 71 Allen Iverson Auto - Vintage Gold Signatures 2 76ers 20 Allen Iverson Auto Relic - Precious Swatch Signatures + Parallels 8 76ers 36 Ben Simmons Base + Parallels 54 76ers 120 Charles Barkley Auto - Vintage Gold Signatures 26 76ers 20 Dario Saric Base + Parallels 90 76ers 120 JJ Redick Base + Parallels 86 76ers 120 Joel Embiid Base + Parallels 5 76ers 120 Markelle Fultz Auto - Golden Ink 37 76ers 20 Markelle Fultz Auto - Rookie + Parallels 117 76ers 115 Markelle Fultz Auto - Rookie Octo Player Booklet 1 76ers 10 Markelle Fultz Auto Relic - Rookie Patch Auto + Parallels 140 76ers 115 Markelle Fultz Base + Parallels 1 76ers 120 Markelle Fultz Auto Relic - Rookie Patch Auto Book + Special Patch Parallels 5 76ers 40 groupbreakchecklists.com 2017-18 Opulence Basketball Team Checklist Player Set Card # Team Print Run Bill Walton Auto - Vintage Gold Signatures 27 Blazers 20 Caleb Swanigan Auto Relic - Rookie Patch Auto + Parallels 147 Blazers 115 Caleb Swanigan Auto Relic - Rookie Patch Auto Book + Special Patch Parallels 18 Blazers 38 CJ McCollum Auto Relic - Golden Auto Memorabilia + Parallels 40 Blazers 51 CJ McCollum Auto Relic - Precious Swatch Signatures + Parallels 35 Blazers 51 CJ McCollum Base + Parallels 24 Blazers 120 Clyde Drexler Auto - Gold Metal (USA) 13 Blazers 20 Clyde Drexler Auto - Gold Records Signatures + Parallels 28 Blazers -

Set Subset/Insert # Player
SET SUBSET/INSERT # PLAYER 2014 Panini Golden Age Baseball Historic Signatures 12 Bo Derek 2014 Panini National Treasures Baseball Rookie Material Signatures Gold 197 Gregory Polanco 2015 Panini Black Gold (15-16) Basketball Black Gold Signatures 17 Wesley Matthews 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs 213 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs 230 R.J. Hunter 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Double 251 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Double Prime 251 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Double Prime 267 R.J. Hunter 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Jumbo 313 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Jumbo Prime 313 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Prime 213 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Triple 282 Stanley Johnson 2015 Panini Gold Standard (15-16) Basketball Rookie Jersey Autographs Triple Prime 282 Stanley Johnson 2015 Panini Luxe (15-16) Basketball DeLuxe 21 Terry Rozier 2015 Panini Luxe (15-16) Basketball DeLuxe 79 Wesley Matthews 2015 Panini Luxe (15-16) Basketball Luxe Autographs 21 Terry Rozier 2015 Panini Luxe (15-16) Basketball Luxe Autographs 79 Wesley Matthews 2015 Panini Luxe (15-16) Basketball Luxe Autographs Emerald 79 Wesley -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -

P20 Layout 1
American yachts Duke beat Indiana lead Sydney-Hobart in Pinstripe Bowl 16 44-4118 MONDAY, DECEMBER 28, 2015 Man Utd and Van Gaal in suspense as Chelsea loom Page 19 PHOENIX: Phoenix Suns center Alex Len (21) attempts to shoot as Philadelphia 76ers guard Hollis Thompson, left, and Nerlens Noel defend in the third quarter during an NBA basketball game, Saturday, in Phoenix. — AP 76ers beat Suns 111-104 for second win PHOENIX: Isaiah Canaan scored 22 points, reserve Nik after losing three in a row. Gordon Hayward scored 28 HAWKS 117, KNICKS 98 points and 12 rebounds. Charlotte fought back to take Stauskas had 17 and the lowly Philadelphia 76ers beat points for Utah. Paul Millsap scored 22 points, Al Horford added 19 the lead for good at 89-88 on a layup by Walker with the Phoenix Suns 111-104 on Saturday night for their points and Atlanta won its sixth straight game. Carmelo 1:55 left. second victory of the season. Carl Landry added 16 PELICANS 110, ROCKETS 108 Anthony, returning after missing one game with a points as Philadelphia (2-30) snapped a 12-game losing Anthony Davis had 24 points, 13 rebounds and sprained right ankle, finished with 18 points and 12 HEAT 108, MAGIC 101 streak with its first win since Dec. 1. The 76ers also three blocked shots for New Orleans, and Tyreke Evans rebounds for the Knicks. New York has dropped three Dwyane Wade and Chris Bosh each scored 24 points, stopped a 23-game road slide dating to last season. stole Trevor Ariza’s inbounds pass in the final seconds. -

2012-13 Tulsa 66Ers Media Guide Was Designed, Written and Tony Taylor
2012 • 2013 SCHEDULE NOVEMBER DECEMBER SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 18 19 20 21 22 23 24 1 TEX 7 PM 25 26 27 28 29 30 2 3 4 5 6 7 8 TEX RGV SXF RGV RGV 4 PM 7 PM 11 AM 7 PM 7 PM 9 10 11 12 13 14 15 RGV BAK BAK 4 PM 9 PM 9 PM JANUARY 16 17 18 19 20 21 22 SUN MON TUE WED THU FRI SAT IWA CTN 1 2 3 4 5 7 PM 7 PM 23 24 25 26 27 28 29 IDA TEX 7 PM 7 PM CTN CTN 6 7 8 9 10 11 12 30 31 6:30 PM 6:30 PM SCW 9 PM 13 14 15 16 17 18 19 FEBRUARY SCW AUS AUS 7 PM 7 PM 7 PM SUN MON TUE WED THU FRI SAT 20 21 22 23 24 25 26 1 2 IWA LAD LAD ERI SCW 7 PM 7 PM 7 PM 7 PM 7 PM 27 28 29 30 31 3 4 5 6 7 8 9 ERI SPG AUS 6 PM 6 PM 7:30 PM 10 11 12 13 14 15 16 TEX TEX 3 PM 7 PM MARCH 17 18 19 20 21 22 23 SXF SXF SUN MON TUE WED THU FRI SAT 7 PM 1 2 7 PM 24 25 26 27 28 RNO SXF IWA 7 PM 7 PM 7 PM 3 4 5 6 7 8 9 IWA 11 AM 10 11 12 13 14 15 16 IWA LAD IDA IDA APRIL 4 PM 9 PM 8 PM 8 PM SUN MON TUE WED THU FRI SAT 17 18 19 20 21 22 23 1 2 3 4 5 6 BAK IWA SXF IWA FWN 7 PM 7 PM 7 PM 7 PM 7 PM 24 25 26 27 28 29 30 RGV RGV AUS AUS 31 7 PM 7 PM 7:30 PM 7 PM *ALL TIMES ARE CENTRAL AWAY HOME FOR LIVE GAME COVERAGE OF EVERY HOME AND AWAY GAME TUNE IN TO: GET YOUR TICKETS TODAY! 918.585.8444 [email protected] RADIO 1300 AM OR WATCH THE FUTURECAST LIVE STREAM AT TULSA66ERS.COM B I X B Y , O K L AHO M A PROUD AFFILIATE OF THE OKL AHOMA CIT Y THUNDER TGeneralUL InformationSA6 6StaffER SThe. -

Team Training Program
TEAM TRAINING Impact Basketball is very proud of our extensive productive tradition of training teams from around the world as they prepare for upcoming events, seasons, or tournament competition. It is with great honor that we help your team to be at its very best through our comprehensive training and team-building program. The Impact Basketball Team Training Program will give your players a chance to train together in a focused environment with demanding on-court offensive and defensive skill training along with intense off-court strength and conditioning training. The experienced Impact Basketball staff will provide the team with a truly unique bonding experience through training and competition, as well as off-court team building activities. Designated team practice times and live games against high-level American players, including NBA players, provide teams with an opportunity to prepare for their upcoming competition while also developing individually. Each team’s program will be completely customized to fit their schedule, with direct consultation from the team’s coaching staff and management. We will integrate any and all concepts that the coaching staff would like to implement and focus the training on areas that the team’s coaches have deemed deficient. Our incorporation of off-site training and team-building exercises make this a one-of-a-kind opportunity for team and individual development. We have the ability to provide training options for the entire team or for a smaller group of the team’s players. The Impact staff can help set up all the housing, food, and transportation needs for the team. -

2014-15 Panini Select Basketball Set Checklist
2014-15 Panini Select Basketball Set Checklist Base Set Checklist 100 cards Concourse PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Blue Prizms #/249, Red Prizms #/149, Orange Prizms #/60, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Premier PARALLEL CARDS: Purple/White Prizms, Silver Prizms, Light Blue Prizms Die-Cut #/199, Purple Prizms Die-Cut #/99, Tie-Dye Prizms Die-Cut #/25, Gold Prizms Die-Cut #/10, Green Prizms Die-Cut #/5, Black Prizms Die-Cut 1/1 Courtside PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Copper #/49, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Concourse 1 Stephen Curry - Golden State Warriors 2 Dwyane Wade - Miami Heat 3 Victor Oladipo - Orlando Magic 4 Larry Sanders - Milwaukee Bucks 5 Marcin Gortat - Washington Wizards 6 LaMarcus Aldridge - Portland Trail Blazers 7 Serge Ibaka - Oklahoma City Thunder 8 Roy Hibbert - Indiana Pacers 9 Klay Thompson - Golden State Warriors 10 Chris Bosh - Miami Heat 11 Nikola Vucevic - Orlando Magic 12 Ersan Ilyasova - Milwaukee Bucks 13 Tim Duncan - San Antonio Spurs 14 Damian Lillard - Portland Trail Blazers 15 Anthony Davis - New Orleans Pelicans 16 Deron Williams - Brooklyn Nets 17 Andre Iguodala - Golden State Warriors 18 Luol Deng - Miami Heat 19 Goran Dragic - Phoenix Suns 20 Kobe Bryant - Los Angeles Lakers 21 Tony Parker - San Antonio Spurs 22 Al Jefferson - Charlotte Hornets 23 Jrue Holiday - New Orleans Pelicans 24 Kevin Garnett - Brooklyn Nets 25 Derrick Rose -

Opponents Opponents
opponents opponents OPPONENTS opponents opponents Directory Ownership ................................................................Bruce Levenson, Michael Gearon, Steven Belkin, Ed Peskowitz, ..............................................................................Rutherford Seydel, Todd Foreman, Michael Gearon Sr., Beau Turner President, Basketball Operations/General Manager .....................................................................................Danny Ferry Assistant General Manager.........................................................................................................................................Wes Wilcox Senior Advisor, Basketball Operations .....................................................................................................................Rick Sund Head Coach .......................................................... Larry Drew (All-Time: 84-64, .568; All-Time vs Hornets: 1-2, .333) Assistant Coaches ............................................................. Lester Conner, Bob Bender, Kenny Atkinson, Bob Weiss Player Development Instructor ............................................................................................................................Nick Van Exel Strength & Conditioning Coach ........................................................................................................................ Jeff Watkinson Vice President of Public Relations .........................................................................................................................................TBD -

FORBES 30 Under
The rugged and revolutionary Olympus OM-D E-M1. No matter where life’s INTRODUCING A CAMERA adventures take you, the Olympus OM-D E-M1 can always be by your side. Its AS RUGGED magnesium alloy body is dustproof, splashproof, and freezeproof, so it’ll survive the harshest of conditions. And the super-fast and durable 1/8000s mechanical AS YOU ARE. shutter and 10 fps sequential shooting will capture your entire journey exactly the way you experienced it. www.getolympus.com/em1 Move into a New World ÒThe OM-D lets me get great shots because itÕs rugged and durable. In this shot, I was shooting when the dust was the thickest because it enhanced the light. I even changed lenses and IÕve yet to have a dust problem with my OM-D system.Ó -Jay Dickman, Olympus Visionary Shot with an OM-D, M.ZUIKO ED 75-300mm f4.8-6.7 II • One of the smallest and lightest bodies in its class at 17.5 ounces* • Built-in Wi-Fi • Full system of premium, interchangeable lenses *E-M1 body only contents — JAnUARY 20, 2014 VOLUME 193 NUMBER 1 30 FORBES 30 UNDER 88 | NEXT-GENERATION ENTREPRENEURS Four hundred and f fty faces of the future. 11 | FACT & COMMENT BY STEVE FORBES The lies continue. LEADERBOARD 14 | SCORECARD 2013: a very good year. 16 | BEING REED HASTINGS The man running the show at Netfl ix has a story that any screenwriter would be proud of. 18 | THE YEAR’S HOTTEST STARTUPS A panel of VCs and entrepreneurs selected these businesses from more than 300 contenders.