ICL Technical Journal Volume 9 Issue 2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Considerations for Use of Microcomputers in Developing Countrystatistical Offices
Considerations for Use of Microcomputers in Developing CountryStatistical Offices Final Report Prepared by International Statistical Programs Center Bureau of the Census U.S. Department of Commerce Funded by Office of the Science Advisor (c Agency for International Development issued October 1983 IV U.S. Department of Commerce Malcolm Baldrige, Secretary Clarence J. Brown, Deputy Secretary BUREAU OF THE CENSUS C.L. Kincannon, Deputy Director ACKNOWLEDGE ME NT S This study was conducted by the International Statistical Programs Center (ISPC) of the U.S. Bureau of the Census under Participating Agency Services Agreement (PASA) #STB 5543-P-CA-1100-O0, "Strengthening Scientific and Technological Capacity: Low Cost Microcomputer Technology," with the U.S. Agency for International Development (AID). Funding fcr this project was provided as a research grant from the Office of the Science Advisor of AID. The views and opinions expressed in this report, however, are those of the authors, and do not necessarily reflect those of the sponsor. Project implementation was performed under general management of Robert 0. Bartram, Assistant Director for International Programs, and Karl K. Kindel, Chief ISPC. Winston Toby Riley III provided input as an independent consultant. Study activities and report preparation were accomplished by: Robert R. Bair -- Principal Investigator Barbara N. Diskin -- Project Leader/Principal Author Lawrence I. Iskow -- Author William K. Stuart -- Author Rodney E. Butler -- Clerical Assistant Jerry W. Richards -- Clerical Assistant ISPC would like to acknowledge the many microcomputer vendors, software developers, users, the United Nations Statistical Office, and AID staff and contractors that contributed to the knowledge and experiences of the study team. -

Programming Languages, Database Language SQL, Graphics, GOSIP
b fl ^ b 2 5 I AH1Q3 NISTIR 4951 (Supersedes NISTIR 4871) VALIDATED PRODUCTS LIST 1992 No. 4 PROGRAMMING LANGUAGES DATABASE LANGUAGE SQL GRAPHICS Judy B. Kailey GOSIP Editor POSIX COMPUTER SECURITY U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 100 . U56 4951 1992 NIST (Supersedes NISTIR 4871) VALIDATED PRODUCTS LIST 1992 No. 4 PROGRAMMING LANGUAGES DATABASE LANGUAGE SQL GRAPHICS Judy B. Kailey GOSIP Editor POSIX COMPUTER SECURITY U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1992 (Supersedes July 1992 issue) U.S. DEPARTMENT OF COMMERCE Barbara Hackman Franklin, Secretary TECHNOLOGY ADMINISTRATION Robert M. White, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director - ;,’; '^'i -; _ ^ '’>.£. ; '':k ' ' • ; <tr-f'' "i>: •v'k' I m''M - i*i^ a,)»# ' :,• 4 ie®®;'’’,' ;SJ' v: . I 'i^’i i 'OS -.! FOREWORD The Validated Products List is a collection of registers describing implementations of Federal Information Processing Standards (FTPS) that have been validated for conformance to FTPS. The Validated Products List also contains information about the organizations, test methods and procedures that support the validation programs for the FTPS identified in this document. The Validated Products List is updated quarterly. iii ' ;r,<R^v a;-' i-'r^ . /' ^'^uffoo'*^ ''vCJIt<*bjteV sdT : Jr /' i^iL'.JO 'j,-/5l ':. ;urj ->i: • ' *?> ^r:nT^^'Ad JlSid Uawfoof^ fa«Di)itbiI»V ,, ‘ isbt^u ri il .r^^iytsrH n 'V TABLE OF CONTENTS 1. -

Hacker's Handbook Ok Just a Quick Note, This Is a Very Early Version of the Book and Was Later Banned
Hacker's Handbook Ok just a quick note, this is a very early version of the book and was later banned. We've done our best in converting it to ASCII. It's taken us some time to put it together because of the reformatting, so I hope it's appreciated. We have kept to the original page numbering for so that the index will be correct. Compliments Electronic Images - Gizmo Century Communications - T H E - - H A C K E R ' S - - H A N D B O O K - Copyright (c) Hugo Cornwall All rights reserved First published in Great Britain in 1985 by Century Communications Ltd Portland House, 12-13 Greek Street, London W1V 5LE. Reprinted 1985 (four times) ISBN 0 7126 0650 5 Printed and bound in Great Britain by Billing & Sons Limited, Worcester. CONTENTS Introduction vii First Principles 2 Computer-to-computer communications 7 3 Hackers' Equipment 15 4 Targets: What you can find on mainframes 30 5 Hackers' Intelligence 42 6 Hackers' Techniques 57 7 Networks 69 8 Viewdata systems 86 9 Radio computer data 99 10 Hacking: the future 108 file:///E|/Books/Hackers Handbook.htm (1 of 133) [11/28/2000 5:58:48 AM] Hacker's Handbook Appendices I troubleshooting 112 II Glossary 117 III CCITT and related standards 130 IV Standard computer alphabets 132 V Modems 141 VI Radio Spectrum 144 VII Port-finder flow chart 148 INTRODUCTION The word 'hacker' is used in two different but associated ways: for some, a hacker is merely a computer enthusiast of any kind, who loves working with the beasties for their own sake, as opposed to operating them in order to enrich a company or research project --or to play games. -
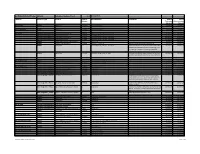
ACTIAN PRODUCTS by Platform Extended Support List
ACTIAN PRODUCTS by Platform Extended Support List As of 30 Jun 2015 \ Platform Product Type Product Product OS Release(s) Comments End of End of Release Extended Obsolescence Support Support DG/UX Intel RDBMS Ingres II EE 2.0/0001 4.20 MU04, MU05 31-Dec-08 31-Dec-13 DG/UX Motorola RDBMS Ingres II EE 2.0/0001 4.1 MU04 to MU06 31-Dec-08 31-Dec-13 HP TRU 64 Application Development OpenROAD Development 5.0/0506 Tru64 4.0f, 4.0g, 5.0a, 5.1, 5.1a, 5.1b 31-Dec-18 31-Dec-23 Application Development OpenROAD Runtime 5.0/0506 Tru64 4.0f, 4.0g, 5.0a, 5.1, 5.1a, 5.1b 31-Dec-18 31-Dec-23 Application Development OpenROAD Development 4.1/0403 Tru64 4.0f, 4.0g, 5.0a, 5.1, 5.1a, 5.1b 31-Mar-14 31-Mar-19 Application Development OpenROAD Runtime 4.1/0403 Tru64 4.0f, 4.0g, 5.0a, 5.1, 5.1a, 5.1b 31-Mar-14 31-Mar-19 RDBMS Ingres 2006 Release 2 Service Pack 2 9.1.2 Tru64 5.1b 31-Dec-16 31-Dec-21 RDBMS Ingres 2.6 Service Pack 6 2.6/0803 Tru64 5.1, 5.1a, 5.1b Marvel is supported running Tru64 5.1b. 31-Dec-14 31-Dec-19 RDBMS Ingres II EE 2.5 Tru64 4.0f, 4.0g, 5.0a, 5.1, 5.1a, 5.1b Customers should use Ingres threads on GS series 31-Dec-12 31-Dec-17 machines with NUMA architecture running Tru64 5.x. -

User Guide Disclaimer
HostAccess User Guide Disclaimer Every effort has been made to ensure that the information contained within this publication is accurate and up-to-date. However, Rogue Wave Software, Inc. does not accept liability for any errors or omissions. Rogue Wave Software, Inc. continuously develops its products and services, and therefore reserves the right to alter the information within this publication without notice. Any changes will be included in subsequent editions of this publication. As the computing industry lacks consistent standards, Rogue Wave Software, Inc. cannot guarantee that its products will be compatible with any combination of systems you choose to use them with. While we may be able to help, you must determine for yourself the compatibility in any particular instance of Rogue Wave Software, Inc. products and your hardware/software environment. Rogue Wave Software, Inc. acknowledges that certain proprietary programs, products or services may be mentioned within this publication. These programs, products or services are distributed under Trademarks or Registered Trademarks of their vendors and/or distributors in the relevant country. Your right to copy this publication, in either hard-copy (paper) or soft-copy (electronic) format, is limited by copyright law. You must obtain prior authorisation from Rogue Wave Software, Inc. before copying, adapting or making compilations of this publication. HostAccess is a trademark of Quovadx Ltd in the United Kingdom and is a registered trademark in the USA. Microsoft is a registered trademark and Windows is a trademark of the Microsoft Corporation. Other brands and their products are trademarks or registered trademarks of their respected holders and should be noted as such. -

Miscellaneous Repairs Chesapeake City Bridge Construction Solicitation
IFB W912BU21B0004 US Army Corps of Engineers Philadelphia District Miscellaneous Repairs Chesapeake City Bridge Chesapeake City, Maryland Construction Solicitation and Specifications 15 June 2021 This page was intentionally left blank for duplex printing. INVITATION NO. W912BU21B0004 PHILADELPHIA DISTRICT CORPS OF ENGINEERS INVITATION FOR BIDS FOR MISCELLANEOUS REPAIRS CHESAPEAKE CITY BRIDGE CHESAPEAKE CITY, MARYLAND I. NOTE THE AFFIRMATIVE ACTION REQUIREMENT OF THE EQUAL OPPORTUNITY CLAUSE WHICH MAY APPLY TO THE CONTRACT RESULTING FROM THIS SOLICITATION. II. BIDDERS ARE REQUIRED TO COMPLETE THE REPRESENTATION AND CERTIFICATIONS PORTION OF SECTION 00 45 00 OF THIS SOLICITATION AND SUBMIT THIS WITH THEIR OFFER. III. PROSPECTIVE BIDDERS ARE INVITED TO VISIT THE SITE TO ACQUAINT THEMSELVES WITH THE SITE CONDITIONS AND ANY PROBLEMS INCIDENT TO THE PROSECUTION OF THE WORK. THE SITE VISIT WILL BE HELD ON 22 JUNE 2021. THE SITE VISIT WILL BEGIN AT 10:00 AM AT THE CHESAPEAKE CITY PROJECT Office - C&D CANAL 815 BETHEL ROAD, CHESAPEAKE CITY, MARYLAND 21915. ALL THOSE PLANNING TO ATTEND MUST CONTACT MR. MIKE HART VIA EMAIL AT [email protected], PRIOR TO THE SITE VISIT. 15 JUNE 2021 This page was intentionally left blank for duplex printing. SOLICITATION, OFFER, 1. SOLICITATION NO. 2. TYPE OF SOLICITATION 3. DATE ISSUED PAGE OF PAGES AND AWARD X SEALED BID (IFB) 15-Jun-2021 W912BU21B0004 1 OF 41 (Construction, Alteration, or Repair) NEGOTIATED(RFP) IMPORTANT - The "offer" section on the reverse must be fully completed by offeror. 4. CONTRACT NO. 5. REQUISITION/PURCHASE REQUEST NO. 6. PROJECT NO. 7. ISSUED BY CODE W912BU 8. -

THIS MONTH Sony WA -8800 Ten -Band Cassette Recorder
REVIEWED THIS MONTH Sony WA -8800 ten -band cassette recorder YESTERDAY'S SPY SET The 128 Set Revisited BUILD THE LONGWAVER LOOP ANTENNA INDEX TO VOLUME 49 Regular Features for Airband, Scanning, Junior Listeners, SSB Utility Listening, Propagation and Broadcast Enthusiasts Extra Wideband Scanning Power New Models With Even More Facilities! JUST RELEASED. NEW HP2000 Now with continuous coverage featuring a completere -design and new p.c.b. layout Frequency coverage:- 500KHz- 1300MHz with no gaps * 1,000 channel memory * Receives AM -FM- Wideband FM * Search steps selectable from 5KHz to 995KHz * Keypad or rotary tune controls * Switcheable 10dB attenuator Each set is supplied with:- * Full set of high power NiCad rechargeable batteries * UK spec. charger * Three antennas- VHF, UHF, short wave telescopic * Carrying case, belt clip, shoulder strap * Dc cable for car cigar adaptor supply * Earpiece for private listening £269 NEW Nevada MS1000 Mobile/Base Scanner An exciting new scanner with all the specifications of the HP200 aboveplus:- * Switcheable audio squelch * Tape recorder output socket * Automatic tape recorder switching circuit switchestape recorder on when a signal is present * All metal case for improved EMC compatibility £279 Awilable From Authorised Dealers Throughout The UK- t Nevada Communications, 189 London Road, North End, Portsmouth. P02 9AE Send in £2 now *r our LATEST CATALOGUE with full details ofour complete product range (includes a £2 voucher). CA=e5)zr_727x arro VOL. 49 ISSUE 12 DECEMBER 1991 ON SALE NOVEMBER 28 10 Speedbird Concorde Zero One Peter Rouse GU1DKD (Next Issue on sale DECEMBER 20) 12 A Basic RTTY Receive -only Terminal unit - EDITOR: Dick Ganderton, C. -

Another ICL Anthology
Foreword On June 21st 1948 Tom Kilburn ran a program on the first electronically stored program computer in the world. Freddy Williams and Tom had been struggling for some time to make their cathode ray tube store work. Demonstrating the store was the key thing, for without a store the computer as we know it today could never be. This simple machine, always known as the 'BABY', was developed into the Ferranti Mark 1, the first computer to go on commercial sale anywhere in the world. Tom's program was the first program to be written and run. Some of us here in Manchester felt that the fiftieth anniversary of such stupendous achievements should not go unnoticed. So at 11 a.m. on June 21st 1998, fifty years to the dot later, Tom ran that same program again on a reconstructed BABY that had earlier been ceremonially switched on by the widow of Freddy Williams. A team of enthusiasts, almost all members or retired members of ICL, researched the design and built the machine from genuine 1940s components. This would not have been possible without the usual ICL drive and enthusiasm, typified at the personal level by Chris Burton (ex- ICL West Gorton) who led the team, and marked at the corporate level by sponsorship of the project. Anyone interested can now see BABY at the Museum of Science and Industry in Manchester. Tom Kilburn says that it looks exactly like the original - except that it's cleaner. I mention this story because it illustrates vividly what has happened to our industry over fifty years. -

ICL Technical Journal Volume 5 Issue 3
TECHniCAl j o u m n i Volume 5 Issue 3 May 1987 Published by INTERNATIONAL COMPUTERS LIMITED at OXFORD UNIVERSITY PRESS iCL The ICL Technical Journal is published twice a year by TECHniCRl International Computers Limited at Oxford University jouRnfli Press. Editor J. Howlett ICL House, Putney, London SW15 ISW, UK Editorial Board J. Howlett (Editor) F.F. Land H.M. Cropper (F International) (London School of Economics & D.W. Davies, FRS Political Science) G.E. Felton K.H. Macdonald M.D. Godfrey M R. Miller C.H.L. Goodman (British Telecom Research (Standard Telephone Laboratories) Laboratories and Warwick J.M. Pinkerton University) E.C.P. Portman All correspondence and papers to be considered for publication should be addressed to the Editor. The views expressed in the papers are those of the authors and do not necessarily represent ICL policy. 1987 subscription rates: annual subscription £32 UK, £40 rest of world, US $72 N. America; single issues £17 UK, £22 rest of world, US $38 N. America. Orders with remittances should be sent to the Journals Subscriptions Department, Oxford University Press, Walton Street, Oxford 0X2 6DP, UK. This publication is copyright under the Berne Convention and the Interna tional Copyright Convention. All rights reserved. Apart from any copying under the UK Copyright Act 1956, part 1, section 7, whereby a single copy of an article may be supplied, under certain conditions, for the purposes of research or private study, by a library of a class prescribed by the UK Board of Trade Regulations (Statutory Instruments 1957, No. 868), no part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means without the prior permission of the copyright owners. -

Validated Products List, 1993 No. 4
VALIDATED PRODUCTS LIST 1993 No. 4 Programming Languages Database Language SQL Graphics GOSIP POSIX Judy B. Kailey Computer Security Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1993 {Supersedes July 1993 issue) -i)C 100 .U56 NIST //5274 1993 DATE DUE QrUhi j Demco, Inc. 38-293 NISTIR 5274 (Supersedes NISTIR 5220) VALIDATED PRODUCTS LIST 1993 No. 4 Programming Languages Database Language SQL Graphics GOSIP POSiX Judy B. Kailey Computer Security Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1993 (Supersedes July 1993 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director / FOREWORD The Validated Products List is a collection of registers describing implementations of Federal Information Processing Standards (FIPS) that have been validated for conformance to FIPS. The Validated Products List also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The Validated Products List is updated quarterly. IV TABLE OF CONTENTS 1. INTRODUCTION 1-1 1.1 Purpose 1-1 1.2 Document Organization 1-2 1.2.1 Programming Languages 1-2 1.2.2 Database Language SQL 1-2 1.2.3 Graphics 1-2 1.2.4 GOSIP 1-2 1.2.5 POSIX 1-2 1.2.6 Computer Security 1-2 1.2.7 FIPS Conformance Testing Products 1-2 2. -

Validated Products List: Programming Languages, Database Language
NISTIR 469 (Supersedes NISTIR 4623) VALIDATED PRODUCTS LIST 1991 No. 4 Programming Languages Database Language SQL Graphics ®OSIP Judy B. Kailey POSIX Editor U.S. DEPARTMENT OF COMMERCE National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1991 (Supersedes July 1991 issue) U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director — QC 100 .U56 NIST //4690 1991 V C.2 NISTIR 4690 (Supersedes NISTIR 4623) - ' J JF VALIDATED PRODUCTS LIST 1991 No. 4 Programming Languages Database Langucige SQL Graphics GOSIP Judy B. Kailey POSIX Editor U.S. DEPARTMENT OF COMMERCE National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1991 (Supersedes July 1991 issue) U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director FOREWORD The Validated Products List (formerly called the Validated Processor List) is a collection of registers describing implementations of Federal Information Processing Standards (FIPS) that have been tested for conformance to FIPS. The Validated Products List also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The Validated Products List is updated quarterly. TABLE OF CONTENTS 1. INTRODUCTION 1-1 1.1 Purpose 1-1 1.2 Document Organization 1-1 1.2.1 Programming Languages 1-1 1.2.2 Database Language SQL 1-2 1.2.3 Graphics 1-2 1.2.4 GOSIP 1-2 1.2.5 POSIX 1-2 1.2.6 FIPS Conformance Testing Products 1-2 2. -

1 Je{A1f-Ht-4Ttfitte
r ButtetlJe '1 Je{a1f-Ht-4ttfitte European Commission Delegation Library 2300 M Street, NW ·f OCTOBRE 1997 Washington, DO 20037 EDITORIAL .............................................. 3 COMMUNICATIONS ........................................ 5 STB INFO ................................................ 6 INFORMATIONS DU CENTRE DE CALCUL . 12 ARTICLES . Information technology in the European Parliament . 14 . Comité des utilisateurs Adonis du 19 juin 1997 . 22 . "Bien choisir le contenu de 1' information": Internet et informations statistiques 23 . Deployment of 32-bit Client-Server Applications . 27 . Euro changeover of information systems . 39 . Migrating to Windows NT 4.0- Security issues and solutions . 44 . Future E-Mail of the Commission . 50 . API's for E-Mail applications . 52 ORGANISATION . 55 TABLEAUX DE BORD . Budget informatique . 58 . Ressources humaines . 59 . Projets d'infrastructure . 61 . Formation . 62 LISTE DES PRODUITS . 66 COMITES 1 GROUPES DE TRAVAIL . 87 CALENDRIER . 88 C.E. 1 Direction Informatique 1 Unité Relations Utilisateurs et Cohérence Informatique J ) Editeur: F. ROSSA JMO C2 1 82 tél: 32394 fax: 33869 DOCUMENT INTERNE Editorial Dans notre Bulletin informatique de janvier 1995, je faisais allusion au triple élargissement de la famille EUROPE et au fait que nous aurions l'opportunité de travailler avec des informaticiens Finlandais, Suédois ou Autrichiens. Cela se vérifie encore aujourd'hui avec la nomination de Monsieur W. BAROSCH, de nationnalité autrichienne, comme chef de l'unité "Support logistique et formation". Sont également à noter les récentes nominations de: M. Jean-Luc SION comme assistant du directeur ainsi que de M. Philippe BERTRAND comme chef de l'unité "Coordination des ressources humaines et budgétaires". Félicitations aux différents récipiendaires Notre Bulletin est un des moyens utilisé pour la diffusion de l'information.