CSI 5335 Project
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
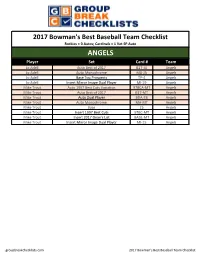
2017 Bowmans Best Baseball Group Break Checklist
2017 Bowman's Best Baseball Team Checklist Rockies = 0 Autos; Cardinals = 1 Vet SP Auto ANGELS Player Set Card # Team Jo Adell Auto Best of 2017 B17-JA Angels Jo Adell Auto Monochrome MA-JA Angels Jo Adell Base Top Prospects TP-4 Angels Jo Adell Insert Mirror Image Dual Player MI-19 Angels Mike Trout Auto 1997 Best Cuts Variation 97BCA-MT Angels Mike Trout Auto Best of 2017 B17-MT Angels Mike Trout Auto Dual Player BDA-TB Angels Mike Trout Auto Monochrome MA-MT Angels Mike Trout Base 25 Angels Mike Trout Insert 1997 Best Cuts 97BC-MT Angels Mike Trout Insert 2017 Dean's List BADL-MT Angels Mike Trout Insert Mirror Image Dual Player MI-15 Angels groupbreakchecklists.com 2017 Bowman's Best Baseball Team Checklist ASTROS Player Set Card # Team Alex Bregman Auto Best of 2017 B17-AB Astros Alex Bregman Auto Dual Player BDA-CB Astros Alex Bregman Auto Monochrome MA-ABR Astros Alex Bregman Base Rookie 54 Astros Alex Bregman Insert 1997 Best Cuts 97BC-AB Astros Alex Bregman Insert Raking Rookies RR-AB Astros Carlos Correa Auto 1997 Best Cuts Variation 97BCA-CC Astros Carlos Correa Auto Best of 2017 B17-CC Astros Carlos Correa Auto Dual Player BDA-CB Astros Carlos Correa Base 48 Astros Carlos Correa Insert 1997 Best Cuts 97BC-CC Astros Carlos Correa Insert Mirror Image Dual Player MI-20 Astros Derek Fisher Auto Best of 2017 B17-DF Astros George Springer Base 56 Astros Jeff Bagwell Auto 1997 Best Cuts Variation 97BCA-JB Astros Jeff Bagwell Insert 1997 Best Cuts 97BC-JB Astros Jose Altuve Base 9 Astros Kyle Tucker Base Top Prospects TP-23 Astros -

To View the 2021 Front Row Auction Catalog
LIVE AUCTION 1. Custom Made TLU Cornhole Boards— Get ready for tailgate season with these custom made TLU Cornhole Boards. It’s the perfect addition to your party or backyard celebration! Donated by Ronnie ’81 and Julia Glenewinkel 2. Altuve, Correa, Bregman, Springer Autographed Astros Piece —Another Priceless Piece for any Houstonian, Baseball Fan, or Collector is this custom framed Piece signed by the “Core Four”. All four players hold special places in fan’s hearts. This photo is signed in an orange paint pen and authenticated by Beckett. 3. Patrick Mahomes Autographed Kansas City Chiefs Helmet—This helmet is signed by the 2018 NFL MVP and Super Bowl LIV MVP, Patrick Mahomes. It is a must have for any Texas Tech Alumni or NFL fan! It is authenticated by JSA. 4. Texas Longhorns 2005 National Championship Team Signed and Framed Jersey— Very rarely do you see a piece like this! This jersey is signed by numerous members of the infamous 2005 Texas Longhorns National Championship Rose Bowl Team. 5. 2022 NCAA Men’s Final Four Experience—The Big Easy will host the Final Four — and this year, you’ll be included! Enjoy two (2) Upper Sideline Seat Tickets to the 2022 Semi-Final Game #1, Semi-Final Game #2, and the Championship Game (Dates TBD) at the Mercedes-Benz Superdome. Included is a three (3) night stay in a Hotel in New Orleans. Airfare is not included. 6. Deep in the Heart of Texas—Excellent hunting opportunity and weekend retreat in the beautiful Texas Hill Country NE of Brady, TX. -

* Text Features
The Boston Red Sox Thursday, November 1, 2018 * The Boston Globe Why the Red Sox feel good about David Price going forward Alex Speier David Price came to Fenway Park ready to celebrate the Red Sox’ 2018 championship season, and hoping to do it again sometime in the next four years. Price had the right to opt out of the final four years and $127 million of the record-setting seven-year, $217 million deal he signed with the Red Sox after the 2015 season by midnight on Wednesday. However, as he basked in the afterglow of his first World Series title, the lefthander said that he would not leave the Red Sox. “I’m opting in. I’m not going anywhere. I want to win here. We did that this year and I want to do it again,” Price said minutes before boarding a duck boat. “There wasn’t any reconsideration on my part ever. I came here to win. We did that this year and that was very special, and now I want to do it again.” Red Sox principal owner (and Globe owner) John Henry was pleased with the decision. While industry opinion was nearly unanimous that Price wouldn’t have been able to make as much money on the open market as he will over the duration of his Red Sox deal, Henry said that the team wasn’t certain of the pitcher’s decision until he informed the club. “[Boston is] a tough town in many ways. I think [the opt-out] was there because it gave him an opportunity to see if he wanted to spend [all seven years here],” said Henry. -

"What Raw Statistics Have the Greatest Effect on Wrc+ in Major League Baseball in 2017?" Gavin D
1 "What raw statistics have the greatest effect on wRC+ in Major League Baseball in 2017?" Gavin D. Sanford University of Minnesota Duluth Honors Capstone Project 2 Abstract Major League Baseball has different statistics for hitters, fielders, and pitchers. The game has followed the same rules for over a century and this has allowed for statistical comparison. As technology grows, so does the game of baseball as there is more areas of the game that people can monitor and track including pitch speed, spin rates, launch angle, exit velocity and directional break. The website QOPBaseball.com is a newer website that attempts to correctly track every pitches horizontal and vertical break and grade it based on these factors (Wilson, 2016). Fangraphs has statistics on the direction players hit the ball and what percentage of the time. The game of baseball is all about quantifying players and being able give a value to their contributions. Sabermetrics have given us the ability to do this in far more depth. Weighted Runs Created Plus (wRC+) is an offensive stat which is attempted to quantify a player’s total offensive value (wRC and wRC+, Fangraphs). It is Era and park adjusted, meaning that the park and year can be compared without altering the statistic further. In this paper, we look at what 2018 statistics have the greatest effect on an individual player’s wRC+. Keywords: Sabermetrics, Econometrics, Spin Rates, Baseball, Introduction Major League Baseball has been around for over a century has given awards out for almost 100 years. The way that these awards are given out is based on statistics accumulated over the season. -

October, 1998
By the Numbers Volume 8, Number 1 The Newsletter of the SABR Statistical Analysis Committee October, 1998 RSVP Phil Birnbaum, Editor Well, here we go again: if you want to continue to receive By the If you already replied to my September e-mail, you don’t need to Numbers, you’ll have to drop me a line to let me know. We’ve reply again. If you didn’t receive my September e-mail, it means asked this before, and I apologize if you’re getting tired of it, but that the committee has no e-mail address for you. If you do have there’s a good reason for it: our committee budget. an e-mail address but we don’t know about it, please let Neal Traven (our committee chair – see his remarks later this issue) Our budget is $500 per year. know, so that we can communicate with you more easily. Giving us your e-mail address does not register you to receive BTN by e- Our current committee member list numbers about 200. Of the mail. Unless you explicitly request that, I’ll continue to send 200 of us, 50 have agreed to accept delivery of this newsletter by BTN by regular mail. e-mail. That leaves 150 readers who need physical copies of BTN. At four issues a year, that’s 600 mailings, and there’s no As our 1998 budget has not been touched until now, we have way to do 600 photocopyings and mailings for $500. sufficient funds left over for one more full issue this year. -

Salary Correlations with Batting Performance
Salary correlations with batting performance By: Jaime Craig, Avery Heilbron, Kasey Kirschner, Luke Rector, Will Kunin Introduction Many teams pay very high prices to acquire the players needed to make that team the best it can be. While it often seems that high budget teams like the New York Yankees are often very successful, is the high price tag worth the improvement in performance? We compared many statistics including batting average, on base percentage, slugging, on base plus slugging, home runs, strike outs, stolen bases, runs created, and BABIP (batting average for balls in play) to salaries. We predicted that higher salaries will correlate to better batting performances. We also divided players into three groups by salary range, with the low salary range going up to $1 million per year, the mid-range salaries from $1 million to $10 million per year, and the high salaries greater than $10 million per year. We expected a stronger correlation between batting performance and salaries for players in the higher salary range than the correlation in the lower salary ranges. Low Salary Below $1 million In figure 1 is a correlation plot between salary and batting statistics. This correlation plot is for players that are making below $1 million. We see in all of the plots that there is not a significant correlation between salary and batting statistics. It is , however, evident that players earning the lowest salaries show the lowest correlations. The overall trend for low salary players--which would be expected--is a negative correlation between salary and batting performance. This negative correlation is likely a result of players getting paid according to their specific performance, or the data are reflecting underpaid rookies who have not bloomed in the major leagues yet. -

SF Giants Press Clips Tuesday, August 7, 2018
SF Giants Press Clips Tuesday, August 7, 2018 San Francisco Chronicle Giants blow 9th-inning lead, fall 3-1 to Astros John Shea The world champs came to town, though they weren’t quite as recognizable as they were in October because of injuries to several front-line players. In the end, it didn’t matter. The Astros were still the Astros. The Giants were one out from beating shorthanded Houston 1-0 in Monday night’s opener of a quick two-game series, but closer Will Smith yielded a three-run homer to Marwin Gonzalez, permitting the Astros to celebrate a 3-1 victory. For much of the evening, the story line for the Giants was Brandon Crawford’s sixth-inning home run and seven spectacular innings by Rookie of the Year candidate Dereck Rodriguez, who has been a savior in a year the rotation has been undermined by injuries. Smith walked Alex Bregman with one out and Yuli Gurriel with two away. Gonzalez crushed a 1- 0, down-the-middle fastball, and the Giants were denied their sixth win in eight games. “That’s baseball,” Rodriguez said. “Sometimes you’re dominant, and sometimes it’s just one bad pitch. Everybody’s trying. The great thing about this sport is, tomorrow (Smith) is going to get the ball again when we have the lead in the ninth inning. That’s part of the game, and that’s why we play.” Afterward, in the quiet of the clubhouse, Smith and Rodriguez crossed paths. Smith told the rookie he pitched beautifully, and the rookie wanted it known he had Smith’s back. -

Medieval Facial Hair in Major League Baseball - Not Even Past
Medieval Facial Hair in Major League Baseball - Not Even Past BOOKS FILMS & MEDIA THE PUBLIC HISTORIAN BLOG TEXAS OUR/STORIES STUDENTS ABOUT 15 MINUTE HISTORY "The past is never dead. It's not even past." William Faulkner NOT EVEN PAST Tweet 14 Like THE PUBLIC HISTORIAN Medieval Facial Hair in Major League Baseball Making History: Houston’s “Spirit of the Confederacy” May 06, 2020 More from The Public Historian BOOKS America for Americans: A History of Xenophobia in the United States by Erika Lee (2019) (via flickr) April 20, 2020 by Guy Raffa More Books What is it with baseball players and whiskers? The 2013 Red Sox perfected the art of beard-bonding on the way to their third World Series championship DIGITAL HISTORY in ten years. Boston players and their fans rallied around what Christopher Oldstone-Moore calls the “quest beard” in his history of facial hair, Of Beards and Men. Two years later the Yankees began winning Más de 72: Digital Archive Review only after Brett Gardner stopped shaving his upper lip and, seeking to propitiate the baseball gods, his https://notevenpast.org/medieval-facial-hair-in-major-league-baseball/[6/22/2020 12:26:57 PM] Medieval Facial Hair in Major League Baseball - Not Even Past teammates followed suit. Lip caterpillars soon dwindled along with victories that first year without naked- faced Derek Jeter, but there were still more staches and wins than pundits predicted before the season began. The 2017 Fall Classic featured two rosters—the Houston Astros and Los Angeles Dodgers— modeling a wide assortment of trendy beards, with Dallas Keuchel’s voluminous but well-tended shrubbery taking first-place honors. -

Determining the Value of a Baseball Player
the Valu a Samuel Kaufman and Matthew Tennenhouse Samuel Kaufman Matthew Tennenhouse lllinois Mathematics and Science Academy: lllinois Mathematics and Science Academy: Junior (11) Junior (11) 61112012 Samuel Kaufman and Matthew Tennenhouse June 1,2012 Baseball is a game of numbers, and there are many factors that impact how much an individual player contributes to his team's success. Using various statistical databases such as Lahman's Baseball Database (Lahman, 2011) and FanGraphs' publicly available resources, we compiled data and manipulated it to form an overall formula to determine the value of a player for his individual team. To analyze the data, we researched formulas to determine an individual player's hitting, fielding, and pitching production during games. We examined statistics such as hits, walks, and innings played to establish how many runs each player added to their teams' total runs scored, and then used that value to figure how they performed relative to other players. Using these values, we utilized the Pythagorean Expected Wins formula to calculate a coefficient reflecting the number of runs each team in the Major Leagues scored per win. Using our statistic, baseball teams would be able to compare the impact of their players on the team when evaluating talent and determining salary. Our investigation's original focusing question was "How much is an individual player worth to his team?" Over the course of the year, we modified our focusing question to: "What impact does each individual player have on his team's performance over the course of a season?" Though both ask very similar questions, there are significant differences between them. -
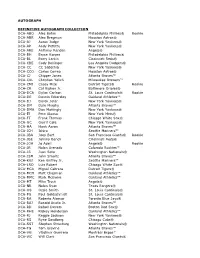
2021 Topps Definitive Collection BB Checklist.Xls
AUTOGRAPH DEFINITIVE AUTOGRAPH COLLECTION DCA-ABO Alec Bohm Philadelphia Phillies® Rookie DCA-ABR Alex Bregman Houston Astros® DCA-AJ Aaron Judge New York Yankees® DCA-AP Andy Pettitte New York Yankees® DCA-ARE Anthony Rendon Angels® DCA-BH Bryce Harper Philadelphia Phillies® DCA-BL Barry Larkin Cincinnati Reds® DCA-CBE Cody Bellinger Los Angeles Dodgers® DCA-CC CC Sabathia New York Yankees® DCA-CCO Carlos Correa Houston Astros® DCA-CJ Chipper Jones Atlanta Braves™ DCA-CKL Christian Yelich Milwaukee Brewers™ DCA-CMI Casey Mize Detroit Tigers® Rookie DCA-CR Cal Ripken Jr. Baltimore Orioles® DCA-DCA Dylan Carlson St. Louis Cardinals® Rookie DCA-DE Dennis Eckersley Oakland Athletics™ DCA-DJ Derek Jeter New York Yankees® DCA-DM Dale Murphy Atlanta Braves™ DCA-DMA Don Mattingly New York Yankees® DCA-EJ Pete Alonso New York Mets® DCA-FT Frank Thomas Chicago White Sox® DCA-GC Gerrit Cole New York Yankees® DCA-HA Hank Aaron Atlanta Braves™ DCA-ICH Ichiro Seattle Mariners™ DCA-JBA Joey Bart San Francisco Giants® Rookie DCA-JBE Johnny Bench Cincinnati Reds® DCA-JOA Jo Adell Angels® Rookie DCA-JR Nolan Arenado Colorado Rockies™ DCA-JS Juan Soto Washington Nationals® DCA-JSM John Smoltz Atlanta Braves™ DCA-KGJ Ken Griffey Jr. Seattle Mariners™ DCA-LRO Luis Robert Chicago White Sox® DCA-MCA Miguel Cabrera Detroit Tigers® DCA-MCH Matt Chapman Oakland Athletics™ DCA-MMC Mark McGwire Oakland Athletics™ DCA-MT Mike Trout Angels® DCA-NR Nolan Ryan Texas Rangers® DCA-OS Ozzie Smith St. Louis Cardinals® DCA-PG Paul Goldschmidt St. Louis Cardinals® DCA-RA Roberto Alomar Toronto Blue Jays® DCA-RAJ Ronald Acuña Jr. -

2017 Bowman Baseball Checklist
BASE VETERANS AND ROOKIES 1 Kris Bryant Chicago Cubs® 2 Kenta Maeda Los Angeles Dodgers® 3 Bryce Harper Washington Nationals® 4 Jeff Hoffman Colorado Rockies™ Rookie 5 Trevor Story Colorado Rockies™ 6 Mookie Betts Boston Red Sox® 7 Cole Hamels Texas Rangers® 8 Matt Carpenter St. Louis Cardinals® 9 Carlos Correa Houston Astros® 10 Jose Bautista Toronto Blue Jays® 11 Ryan Braun Milwaukee Brewers™ 12 Trea Turner Washington Nationals® 13 Stephen Piscotty St. Louis Cardinals® 14 Stephen Strasburg Washington Nationals® 15 Buster Posey San Francisco Giants® 16 Joey Votto Cincinnati Reds® 17 Yoenis Cespedes New York Mets® 18 Andrew McCutchen Pittsburgh Pirates® 19 Jose Altuve Houston Astros® 20 Manny Margot San Diego Padres™ Rookie 21 Giancarlo Stanton Miami Marlins® 22 Carson Fulmer Chicago White Sox® Rookie 23 Andrew Benintendi Boston Red Sox® Rookie 24 Craig Kimbrel Boston Red Sox® 25 Yoan Moncada Chicago White Sox® Rookie 26 Teoscar Hernandez Houston Astros® Rookie 27 Reynaldo Lopez Chicago White Sox® Rookie 28 Miguel Cabrera Detroit Tigers® 29 Yulieski Gurriel Houston Astros® Rookie 30 Nomar Mazara Texas Rangers® 31 Josh Donaldson Toronto Blue Jays® 32 Aaron Judge New York Yankees® Rookie 33 Ichiro Miami Marlins® 34 Robert Gsellman New York Mets® Rookie 35 Ryon Healy Oakland Athletics™ Rookie 36 Anthony Rizzo Chicago Cubs® 37 Evan Longoria Tampa Bay Rays™ 38 Andrew Miller Cleveland Indians® 39 Noah Syndergaard New York Mets® 40 Manny Machado Baltimore Orioles® 41 Orlando Arcia Milwaukee Brewers™ Rookie 42 Jose De Leon Tampa Bay Rays™ Rookie -

Stattrak for Baseball/Softball Statistics Quick Reference
StatTrak for Baseball/Softball Statistics Quick Reference Batting PA Plate Appearances HP Hit by Pitch R Runs CO Catcher's Obstruction H Hits SO Strike Outs 2B Doubles SH Sacrifice Hit (sacrifice bunt) 3B Triples SF Sacrifice Fly HR Home Runs DP Double Plays Hit Into OE Reaching On-Error SB Stolen Bases FC Fielder’s Choice CS Caught Stealing BB Walks RBI Runs Batted In B1, B2, B3, B4, B5 Name Your Own Categories (renamable) BS1, BS2, BS3, BS4, BS5 Create Your Own Statistics (renamable) G Games = Number of Batting records in database AB At Bats = PA - BB - HP - SH - SF - CO 1B Singles = H - 2B - 3B - HR TB Total Bases = H + 2B + (2 x 3B) + (3 x HR) SLG Slugging Percentage = TB / AB OBP On-Base Percentage = (H + BB + HP) / (AB + BB + HP + SF) <=== Major League Method or (H + BB + HP + OE) / (AB + BB + HP + SF) <=== Include OE or (H + BB + HP + FC) / (AB + BB + HP + SF) <=== Include FC or (H + BB + HP + OE + FC) / (AB + BB + HP + SF) <=== Include OE and FC BA Batting Average = H / AB RC Runs Created = ((H + BB) x TB) / (AB + BB) TA Total Average = (TB + SB + BB + HP) / (AB - H + CS + DP) PP Pure Power = SLG - BA SBA Stolen Base Average = SB / (SB + CS) CHS Current Hitting Streak LHS Longest Hitting Streak Pitching IP Innings Pitched SF Sacrifice Fly R Runs WP Wild Pitch ER Earned-Runs Bk Balks BF Batters Faced PO Pick Offs H Hits B Balls 2B Doubles S Strikes 3B Triples GS Games Started HR Home Runs GF Games Finished BB Walks CG Complete Games HB Hit Batter W Wins CO Catcher's Obstruction L Losses SO Strike Outs Sv Saves SH Sacrifice Hit