Copy and Paste Redeemed
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
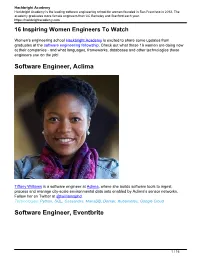
16 Inspiring Women Engineers to Watch
Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com 16 Inspiring Women Engineers To Watch Women's engineering school Hackbright Academy is excited to share some updates from graduates of the software engineering fellowship. Check out what these 16 women are doing now at their companies - and what languages, frameworks, databases and other technologies these engineers use on the job! Software Engineer, Aclima Tiffany Williams is a software engineer at Aclima, where she builds software tools to ingest, process and manage city-scale environmental data sets enabled by Aclima’s sensor networks. Follow her on Twitter at @twilliamsphd. Technologies: Python, SQL, Cassandra, MariaDB, Docker, Kubernetes, Google Cloud Software Engineer, Eventbrite 1 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com Maggie Shine works on backend and frontend application development to make buying a ticket on Eventbrite a great experience. In 2014, she helped build a WiFi-enabled basal body temperature fertility tracking device at a hardware hackathon. Follow her on Twitter at @magksh. Technologies: Python, Django, Celery, MySQL, Redis, Backbone, Marionette, React, Sass User Experience Engineer, GoDaddy 2 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. -

NUMA-Aware Thread Migration for High Performance NVMM File Systems
NUMA-Aware Thread Migration for High Performance NVMM File Systems Ying Wang, Dejun Jiang and Jin Xiong SKL Computer Architecture, ICT, CAS; University of Chinese Academy of Sciences fwangying01, jiangdejun, [email protected] Abstract—Emerging Non-Volatile Main Memories (NVMMs) out considering the NVMM usage on NUMA nodes. Besides, provide persistent storage and can be directly attached to the application threads accessing file system rely on the default memory bus, which allows building file systems on non-volatile operating system thread scheduler, which migrates thread only main memory (NVMM file systems). Since file systems are built on memory, NUMA architecture has a large impact on their considering CPU utilization. These bring remote memory performance due to the presence of remote memory access and access and resource contentions to application threads when imbalanced resource usage. Existing works migrate thread and reading and writing files, and thus reduce the performance thread data on DRAM to solve these problems. Unlike DRAM, of NVMM file systems. We observe that when performing NVMM introduces extra latency and lifetime limitations. This file reads/writes from 4 KB to 256 KB on a NVMM file results in expensive data migration for NVMM file systems on NUMA architecture. In this paper, we argue that NUMA- system (NOVA [47] on NVMM), the average latency of aware thread migration without migrating data is desirable accessing remote node increases by 65.5 % compared to for NVMM file systems. We propose NThread, a NUMA-aware accessing local node. The average bandwidth is reduced by thread migration module for NVMM file system. -

Magento on HHVM Speeding up Your Webshop with a Drop-In PHP Replacement
Magento on HHVM Speeding up your webshop with a drop-in PHP replacement. Daniel Sloof [email protected] What is HHVM? ● HipHop Virtual Machine ● Created by engineers at Facebook ● Essentially a reimplementation of PHP ● Originally translated PHP to C++, now translates PHP to bytecode ● Just-in-time compiler, turning generated bytecode into machine code ● In some cases 5 to 10 times faster than regular PHP So what’s the problem? ● HHVM not entirely compatible with PHP ● Magento’s PHP triggering many of these incompatibilities ● Choosing between ○ Forking Magento to work around HHVM ○ Fixing issues within the extensive HHVM C++ codebase Resulted in... fixing HHVM ● Already over 100 commits fixing Magento related HHVM bugs; ○ SimpleXML (majority of bugfixes) ○ sessions ○ number_format ○ __get and __set ○ many more... ● Most of these fixes already merged back into the official (github) repository ● Community Edition running (relatively) stable! Benchmarks Before we go to the results... ● Magento 1.8 with sample data ● Standard Apache2 / php-fpm / MySQL stack (with APC opcode cache). ● Standard HHVM configuration (repo-authoritative mode disabled, JIT enabled) ● Repo-authoritative mode has potential to increase performance by a large margin ● Tool of choice: siege Benchmarks: Response time Average across 50 requests Benchmarks: Transaction rate While increasing siege concurrency until avg. response time ~2 seconds What about <insert caching mechanism here>? ● HHVM does not get in the way ● Dynamic content still needs to be generated ● Replaces PHP - not Varnish, Redis, FPC, Block Cache, etc. ● As long as you are burning CPU cycles (always), you will benefit from HHVM ● Think about speeding up indexing, order placement, routing, etc. -

Automated Program Transformation for Improving Software Quality
Automated Program Transformation for Improving Software Quality Rijnard van Tonder CMU-ISR-19-101 October 2019 Institute for Software Research School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 Thesis Committee: Claire Le Goues, Chair Christian Kästner Jan Hoffmann Manuel Fähndrich, Facebook, Inc. Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Software Engineering. Copyright 2019 Rijnard van Tonder This work is partially supported under National Science Foundation grant numbers CCF-1750116 and CCF-1563797, and a Facebook Testing and Verification research award. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied, of any sponsoring corporation, institution, the U.S. government, or any other entity. Keywords: syntax, transformation, parsers, rewriting, crash bucketing, fuzzing, bug triage, program transformation, automated bug fixing, automated program repair, separation logic, static analysis, program analysis Abstract Software bugs are not going away. Millions of dollars and thousands of developer-hours are spent finding bugs, debugging the root cause, writing a patch, and reviewing fixes. Automated techniques like static analysis and dynamic fuzz testing have a proven track record for cutting costs and improving software quality. More recently, advances in automated program repair have matured and see nascent adoption in industry. Despite the value of these approaches, automated techniques do not come for free: they must approximate, both theoretically and in the interest of practicality. For example, static analyzers suffer false positives, and automatically produced patches may be insufficiently precise to fix a bug. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Nástroje Pro Sjednocení Datových Zdrojů Projektu Gloffer Tools for Unification of Data Sources Project Gloffer
VŠB – Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Nástroje pro sjednocení datových zdrojů projektu Gloffer Tools for unification of data sources project Gloffer 2018 Bc. Jakub Malchárek Rád bych poděkoval panu Ing. Radoslavu Fasugovi, Ph.D. za odbornou pomoc a konzultaci při zpracování této diplomové práce a cenné rady v průběhu implementace. Abstrakt V této diplomové práci se zabývám analýzou dostupných technologií pro implementaci webo- vého portálu Gloffer. Jsou zde popsány databáze (MySQL, Redis, MongoDB, Aerospike, Apache HBase, Apache Cassandra, Google Bigtable, Memcached), vyhledávače (Solr, Lucene, Elastic Search), webové servery (Apache HTTP server, Apache Tomcat), zprostředkovatelé zpráv (Rab- bit MQ), distribuované výpočetní technologie (Apache Hadoop) a vývojové technologie (PHP 7, Nette Framework, Java, Spring Framework). Cílem je nejen popis těchto technologií, ale také ná- vrh a implementace rozhraní pro sjednocení datových zdrojů projektu Gloffer v programovacím jazyce Java s využitím Spring Frameworku. Výstupem práce je inteligentní nástroj zpřístupňující data z více datových zdrojů. Závěr práce obsahuje výkonové testování vyvinutého nástroje. Klíčová slova: Aerospike, Apache Cassandra, Apache Hadoop, Apache HBase, Apache HTTP server, Apache Tomcat, aplikační rozhraní, datové zdroje, Elastic Search, fulltext, Google Bi- gtable, index, Java, Lucene, Memcached, MongoDB, MySQL, Nette Framework, PHP, Rabbit MQ, Redis, REST, Solr, Spring Framework Abstract In this diploma thesis I deal with analysis of the available technologies for implementation of the Gloffer web portal. There are described databases (MySQL, Redis, MongoDB, Aerospike, Apache HBase, Apache Cassandra, Google Bigtable, Memcached), search engines (Solr, Lucene, Elastic Search), web servers (Apache HTTP server, Apache Tomcat), message brokers (Rabbit MQ), distributed computing technologies (Apache Hadoop) and develop technologies (PHP 7, Nette Framework, Java, Spring Framework). -

Artificial Intelligence for Understanding Large and Complex
Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Abstract Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Copyright © 2020 by Pengfei Zheng All rights reserved except the rights granted by the Creative Commons Attribution-Noncommercial Licence Abstract As the democratization of global-scale web applications and cloud computing, under- standing the performance of a live production datacenter becomes a prerequisite for making strategic decisions related to datacenter design and optimization. Advances in monitoring, tracing, and profiling large, complex systems provide rich datasets and establish a rigorous foundation for performance understanding and reasoning. But the sheer volume and complexity of collected data challenges existing techniques, which rely heavily on human intervention, expert knowledge, and simple statistics. In this dissertation, we address this challenge using artificial intelligence and make the case for two important problems, datacenter performance diagnosis and datacenter workload characterization. The first thrust of this dissertation is the use of statistical causal inference and Bayesian probabilistic model for datacenter straggler diagnosis. -

Facebook Messenger Engineering
SED 1037 Transcript EPISODE 1037 [INTRODUCTION] [00:00:00] JM: Facebook Messenger is a chat application that millions of people use every day to talk to each other. Over time, Messenger has grown to include group chats, video chats, animations, facial filters, stories and many more features. Messenger is a tool for utility as well as for entertainment. Messengers used on both mobile and desktop, but the size of the mobile application is particularly important. There are many users who are on devices that do not have much storage space. As Messenger has accumulated features, the iOS codebase has grown larger and larger. Several generations of Facebook engineers have rotated through the company with responsibility of working on Facebook Messenger, and that has led to different ways of managing information within the same codebase. The iOS codebase had room for improvement and Project LightSpeed was a project within Facebook that had the goal of making Messenger on iOS much smaller. Mohsen Agsen and is an engineer with Facebook and he joins the show to talk about the process of rewriting the Messenger app. This is a great deep dive into how to rewrite a mission- critical iOS application, and this team became very large at a certain point within Facebook. It's a great story and I hope you enjoy it as well. [SPONSOR MESSAGE] [00:01:27] JM: When I’m building a new product, G2i is the company that I call on to help me find a developer who can build the first version of my product. G2i is a hiring platform run by engineers that matches you with React, React Native, GraphQL and mobile engineers who you can trust. -

Characterizing, Modeling, and Benchmarking Rocksdb Key-Value
Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook Zhichao Cao, University of Minnesota, Twin Cities, and Facebook; Siying Dong and Sagar Vemuri, Facebook; David H.C. Du, University of Minnesota, Twin Cities https://www.usenix.org/conference/fast20/presentation/cao-zhichao This paper is included in the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-12-0 Open access to the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) is sponsored by Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook Zhichao Cao†‡ Siying Dong‡ Sagar Vemuri‡ David H.C. Du† †University of Minnesota, Twin Cities ‡Facebook Abstract stores is still challenging. First, there are very limited studies of real-world workload characterization and analysis for KV- Persistent key-value stores are widely used as building stores, and the performance of KV-stores is highly related blocks in today’s IT infrastructure for managing and storing to the workloads generated by applications. Second, the an- large amounts of data. However, studies of characterizing alytic methods for characterizing KV-store workloads are real-world workloads for key-value stores are limited due to different from the existing workload characterization stud- the lack of tracing/analyzing tools and the difficulty of collect- ies for block storage or file systems. KV-stores have simple ing traces in operational environments. In this paper, we first but very different interfaces and behaviors. A set of good present a detailed characterization of workloads from three workload collection, analysis, and characterization tools can typical RocksDB production use cases at Facebook: UDB (a benefit both developers and users of KV-stores by optimizing MySQL storage layer for social graph data), ZippyDB (a dis- performance and developing new functions. -

Myrocks in Mariadb
MyRocks in MariaDB Sergei Petrunia <[email protected]> MariaDB Shenzhen Meetup November 2017 2 What is MyRocks ● #include <Yoshinori’s talk> ● This talk is about MyRocks in MariaDB 3 MyRocks lives in Facebook’s MySQL branch ● github.com/facebook/mysql-5.6 – Will call this “FB/MySQL” ● MyRocks lives there in storage/rocksdb ● FB/MySQL is easy to use if you are Facebook ● Not so easy if you are not :-) 4 FB/mysql-5.6 – user perspective ● No binaries, no packages – Compile yourself from source ● Dependencies, etc. ● No releases – (Is the latest git revision ok?) ● Has extra features – e.g. extra counters “confuse” monitoring tools. 5 FB/mysql-5.6 – dev perspective ● Targets a CentOS-type OS – Compiler, cmake version, etc. – Others may or may not [periodically] work ● MariaDB/Percona file pull requests to fix ● Special command to compile – https://github.com/facebook/mysql-5.6/wiki/Build-Steps ● Special command to run tests – Test suite assumes a big machine ● Some tests even a release build 6 Putting MyRocks in MariaDB ● Goals – Wider adoption – Ease of use – Ease of development – Have MyRocks in MariaDB ● Use it with MariaDB features ● Means – Port MyRocks into MariaDB – Provide binaries and packages 7 Status of MyRocks in MariaDB 8 Status of MyRocks in MariaDB ● MariaDB 10.2 is GA (as of May, 2017) ● It includes an ALPHA version of MyRocks plugin – Working to improve maturity ● It’s a loadable plugin (ha_rocksdb.so) ● Packages – Bintar, deb, rpm, win64 zip + MSI – deb/rpm have MyRocks .so and tools in a separate package. 9 Packaging for MyRocks in MariaDB 10 MyRocks and RocksDB library ● MyRocks is tied RocksDB@revno MariaDB – RocksDB is a github submodule – No compatibility with other versions MyRocks ● RocksDB is always compiled with RocksDB MyRocks S Z n ● l i And linked-in statically a b p ● p Distros have a RocksDB package y – Not using it. -

Unicorn: a System for Searching the Social Graph
Unicorn: A System for Searching the Social Graph Michael Curtiss, Iain Becker, Tudor Bosman, Sergey Doroshenko, Lucian Grijincu, Tom Jackson, Sandhya Kunnatur, Soren Lassen, Philip Pronin, Sriram Sankar, Guanghao Shen, Gintaras Woss, Chao Yang, Ning Zhang Facebook, Inc. ABSTRACT rative of the evolution of Unicorn's architecture, as well as Unicorn is an online, in-memory social graph-aware index- documentation for the major features and components of ing system designed to search trillions of edges between tens the system. of billions of users and entities on thousands of commodity To the best of our knowledge, no other online graph re- servers. Unicorn is based on standard concepts in informa- trieval system has ever been built with the scale of Unicorn tion retrieval, but it includes features to promote results in terms of both data volume and query volume. The sys- with good social proximity. It also supports queries that re- tem serves tens of billions of nodes and trillions of edges quire multiple round-trips to leaves in order to retrieve ob- at scale while accounting for per-edge privacy, and it must jects that are more than one edge away from source nodes. also support realtime updates for all edges and nodes while Unicorn is designed to answer billions of queries per day at serving billions of daily queries at low latencies. latencies in the hundreds of milliseconds, and it serves as an This paper includes three main contributions: infrastructural building block for Facebook's Graph Search • We describe how we applied common information re- product. In this paper, we describe the data model and trieval architectural concepts to the domain of the so- query language supported by Unicorn. -

Ting-Yuan Hsia (408) 707-2897 | [email protected]| H Ps:// H Ps:// Education Santa Clara Univeristy, Santa Clara, CA, USA Sep
Ting-Yuan Hsia (408) 707-2897 | [email protected]| hps://www.linkedin.com/in/ly2314| hps://www.ly2314.cc Education Santa Clara Univeristy, Santa Clara, CA, USA Sep. 2017 - Jun. 2019 Master of Science in Computer Science and Engineering GPA: 3.63 / 4 • Related Courses: Algorithm, Operating Systems, Data Mining, Cryptology, Computer Networks, Distributed Systems National Taiwan University, Taipei, Taiwan Sep. 2014 - Jun. 2016 Master of Science, Department of Electrical Engineering • Master thesis: “Scheduling-Aware Data Prefetching Based on Spark Framework”. • Related Courses: Machine Learning, Artificial Intelligence, Fault Tolerant Computing, Network and Computer Security National Taiwan University, Taipei, Taiwan Sep. 2010 - Jun. 2014 Bachelor of Science in Engineering, Department of Electrical Engineering • Related Courses: Data Structure and Programming Experience Software Development Engineer Jul. 2019 - Present NetApp, Inc. Sunnyvale, CA, USA • Develop and maintain ONTAP data protection technology including SnapMirror, SnapDiff, Volume Move. Software Engineer Intern Jun. 2018 - Sep. 2018 Facebook, Inc. Menlo Park, CA, USA • Developed a cache service from scratch for an internal system and it reduced page loading time by 60%. • The cache service was implemented in C++ and contains a Thrift interface which can be queried from PHP, C++ and Python clients. • Modified both back-end service and frontend user interface for pagination capability. Software Engineer Jan. 2013 - Jul. 2016 Zuvio Inc. Taipei, Taiwan • Developed and maintained client-side products including PowerPoint Add-ins and desktop applications from scratch using C#, XAML, WPF and VSTO. Teaching Assistant Feb. 2016 - Jul. 2016 National Taiwan University, Department of Electrical Engineering Taipei, Taiwan • Graded and assisted students in EE 4052, Computer Programming.