Exposing Bootkits with BIOS Emulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Active@ UNDELETE Documentation
Active @ UNDELETE Users Guide | Contents | 2 Contents Legal Statement.........................................................................................................5 Active@ UNDELETE Overview............................................................................. 6 Getting Started with Active@ UNDELETE.......................................................... 7 Active@ UNDELETE Views And Windows...................................................................................................... 7 Recovery Explorer View.......................................................................................................................... 8 Logical Drive Scan Result View..............................................................................................................9 Physical Device Scan View......................................................................................................................9 Search Results View...............................................................................................................................11 File Organizer view................................................................................................................................ 12 Application Log...................................................................................................................................... 13 Welcome View........................................................................................................................................14 Using -
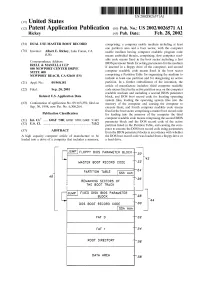
[JUMP FLOPPY Bios PARAMETER BLOCK—\20
US 20020026571A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2002/0026571 A1 Rickey (43) Pub. Date: Feb. 28, 2002 (54) DUAL USE MASTER BOOT RECORD comprising: a computer usable medium including at least one partition area and a boot sector, With the computer (76) Inventor: Albert E. Rickey, Lake Forest, CA usable medium having computer readable program code (Us) means embodied therein, comprising: ?rst computer read able code means ?xed in the boot sector including a ?rst Correspondence Address: BIOS parameter block for setting parameters for the medium IRELL & MANELLA LLP if inserted in a ?oppy drive of the computer; and second 840 NEWPORT CENTER DRIVE SUITE 400 computer readable code means ?xed in the boot sector NEWPORT BEACH, CA 92660 (US) comprising a Partition Table for organizing the medium to include at least one partition and for designating an active (21) Appl. No.: 09/960,181 partition. In a further embodiment of the invention, the article of manufacture includes: third computer readable (22) Filed: Sep. 20, 2001 code means ?xed in the active partition area on the computer readable medium and including a second BIOS parameter Related US. Application Data block, and DOS boot record code for locating operating system ?les, loading the operating system ?les into the (63) Continuation of application No. 09/163,359, ?led on memory of the computer and causing the computer to Sep. 30, 1998, noW Pat. No. 6,308,264. execute them; and fourth computer readable code means ?xed in the boot sector comprising a master boot record code Publication Classi?cation for loading into the memory of the computer the third computer readable code means comprising the second BIOS (51) Int. -

Wikipedia: Design of the FAT File System
Design of the FAT file system A FAT file system is a specific type of computer file system architecture and FAT a family of industry-standard file systems utilizing it. Developer(s) Microsoft, SCP, IBM, [3] The FAT file system is a legacy file system which is simple and robust. It Compaq, Digital offers good performance even in very light-weight implementations, but Research, Novell, cannot deliver the same performance, reliability and scalability as some Caldera modern file systems. It is, however, supported for compatibility reasons by Full name File Allocation Table: nearly all currently developed operating systems for personal computers and FAT12 (12- many home computers, mobile devices and embedded systems, and thus is a bit version), well suited format for data exchange between computers and devices of almost FAT16 (16- any type and age from 1981 through the present. bit versions), Originally designed in 1977 for use on floppy disks, FAT was soon adapted and FAT32 (32-bit version used almost universally on hard disks throughout the DOS and Windows 9x with 28 bits used), eras for two decades. Today, FAT file systems are still commonly found on exFAT (64- floppy disks, USB sticks, flash and other solid-state memory cards and bit versions) modules, and many portable and embedded devices. DCF implements FAT as Introduced 1977 (Standalone the standard file system for digital cameras since 1998.[4] FAT is also utilized Disk BASIC-80) for the EFI system partition (partition type 0xEF) in the boot stage of EFI- FAT12: August 1980 compliant computers. (SCP QDOS) FAT16: August 1984 For floppy disks, FAT has been standardized as ECMA-107[5] and (IBM PC DOS 3.0) ISO/IEC 9293:1994[6] (superseding ISO 9293:1987[7]). -

Demystifying the Microsoft Extended File System (Exfat)
HTCIA International Conference September 20-22, 2010 Atlanta, GA Demystifying the Microsoft Extended File System (exFAT) Robert Shullich CPP, CISSP, CISM, CISA, CGEIT, CRISC, GSEC, GCFA September 20th, 2010 1 Agenda About Me Why a new file system Forensics Relevance Features Advantages Timelines Support Limits ItInternal s September 20th, 2010 2 About Me I have been in the IT field for 35+ Years, and in InfoSec for over 15 Years I carry many IT and InfoSec certifications This research was part of a term project for a forensics class for my masters in Forensic Computing I then expanded the term paper into a practical paper for my SANS GCFA certification A link to the SANS paper and my blog is at the end of this presentation September 20th, 2010 3 Why do we need a new file system? Current Limits Exhausted Larger volumes (>2TB) Largg()er files sizes (>4GB) Faster I/O (UHS-1: 104 MB/2 - UHS-2: 300MB/s) Removable Media Flexibility Extensibility NTFS Features without the overhead September 20th, 2010 4 Relevance to Forensics Study Digital Evidence Extraction Finding the evidence Including the hiding places Validation Daubert Expert Testimony Need to know and understand file org New Media (SD Cards) will drive exFAT adoption, and the potential for CP investigations. September 20th, 2010 5 What happens when you have exFAT fddidAformatted media and no exFAT support ? September 20th, 2010 6 Forensics Challenges Linux OS Support Tuxera drivers may help Mac OS Support Open Source Tools Commercial Tools Encase -

File Allocation Table - Wikipedia, the Free Encyclopedia Page 1 of 22
File Allocation Table - Wikipedia, the free encyclopedia Page 1 of 22 File Allocation Table From Wikipedia, the free encyclopedia File Allocation Table (FAT) is a file system developed by Microsoft for MS-DOS and is the primary file system for consumer versions of Microsoft Windows up to and including Windows Me. FAT as it applies to flexible/floppy and optical disc cartridges (FAT12 and FAT16 without long filename support) has been standardized as ECMA-107 and ISO/IEC 9293. The file system is partially patented. The FAT file system is relatively uncomplicated, and is supported by virtually all existing operating systems for personal computers. This ubiquity makes it an ideal format for floppy disks and solid-state memory cards, and a convenient way of sharing data between disparate operating systems installed on the same computer (a dual boot environment). The most common implementations have a serious drawback in that when files are deleted and new files written to the media, directory fragments tend to become scattered over the entire disk, making reading and writing a slow process. Defragmentation is one solution to this, but is often a lengthy process in itself and has to be performed regularly to keep the FAT file system clean. Defragmentation should not be performed on solid-state memory cards since they wear down eventually. Contents 1 History 1.1 FAT12 1.2 Directories 1.3 Initial FAT16 1.4 Extended partition and logical drives 1.5 Final FAT16 1.6 Long File Names (VFAT, LFNs) 1.7 FAT32 1.8 Fragmentation 1.9 Third party -

FAT32 File Structure Prof
FAT32 File Structure Prof. James L. Frankel Harvard University Version of 9:45 PM 24-Mar-2021 Copyright © 2021 James L. Frankel. All rights reserved. FAT32 Source Documentation • The reference document you should use is the Microsoft Extensible Firmware Initiative FAT32 File System Specification • On class web site under The NXP/Freescale ARM -> microSDHC Card • It is available on the class web site at https://cscie92.dce.harvard.edu/spring2021/Microsoft%20Extensible%20Firmware%20Initiative%20FAT32%2 0File%20System%20Specification,%20Version%201.03,%2020001206.pdf under Online Papers Used in Class • Important correction to this document concerns the DIR_CrtTimeTenth field in the FAT 32 Byte Directory Entry Structure • The name and description of this field is incorrect • Instead of DIR_CrtTimeTenth, we will use the name DIR_CrtTimeHundth • Here is the correct description of this field (to update the text on page 23): • Hundredths of a second time at file creation time. This field contains a count of hundredths of a second. Because the seconds portion of the DIR_CrtTime field denotes a creation time with a granularity of 2 seconds, this field contains a number of hundredths of a second (0 to 199, inclusively) that denotes a number of seconds from 0 to 1.99, inclusively, that may increment the number of seconds in addition to supplying the number of hundredths of a second. • There is also a typo on page 25 where a field is referred to as DIR_CrtTimeMil (which does not exist), and, as corrected here, should be DIR_CrtTimeHundth 2 SD Documentation • Documentation for the SD controller in the K70 • K70 Sub-Family Reference Manual, Rev. -

Advanced Computer Forensics
Advanced Computer Forensics EnCE EnCase Forensics: The Official EnCase Certified Examiner Study Guide Chapter 2 File Systems Disk Basics - 1 • Hard Disk • Physical Device • Referred to as a numeric value (0, 1, 2 etc) • Logical Volume • Referred to by letters A: floppy and C etc. volumes on physical disk • Disk Preparation • Partition – create partition table • MBR – Master Boot Record • 4 partition limit • Disk size to 2 TB • No backup copy of partition table • GPT – GUID Partition Table • 128 partitions • 8 ZB hard drive • Has a copy of the partition table Disk Basics - 2 • Disk Preparation • Partition – create partition table • Right Click -> choose partition style • Creates a new blank partition table in the first sector of the hard drive • Create a new Volume • Right Click -> “unallocated” NEW VOLUME • Specify volume size • VBR – will be created • Format the Volume • Choose file system – Structure of how information will be written and recalled • FAT, NTFS, ExFAT • Sectors and Clusters • Based on File Systems used • Allocation blocks or clusters will be established with groupings of sectors • Sectors are commonly 512 bytes • Clusters keep addressing manageable in very large drives • Windows default – 8 sectors per cluster – 4096 bytes FAT Basics - 1 • Directory Entry • Directory Entries do NOT contain any data • Data is contained in Data allocation units or Clusters • Clusters • 1 or more sectors • Smallest unit in which a file or directory can be stored • If a file is bigger than 1 cluster than it is allocated more than one • Directory -

The Extended FAT File System
Linux Conference October 26- 28, 2011 Prague , Czech Republic Linux Development Center The Extended FAT file system Differentiating with FAT32 file system Keshava Munegowda , Venkatraman S Texas Instruments (India) Pvt Ltd Bangalore. Dr. G T Raju Professor and Head, Computer Science and Engineering Department, 1 R N S Institute of Technology, Bangalore, India. ExFAT Linux Development Center Agenda Ø FAT file system Ø Need for ExFAT file system Ø ExFAT file system organization Ø Boot Sector of FAT and ExFAT Ø Snapshot of Boot Sector of ExFAT Ø Directory Entries of FAT Ø Directory Entries of ExFAT Ø Clusters Heap Ø Up-Case Table Ø Snapshot of Root directory Ø Performance Benchmarking in Linux Ø Performance Benchmarking in Windows 2 Ø References ExFAT Linux Development Center FAT File system Minimum 1 BPB sector BPB - BIOS Parameter Block – BIOS : Basic Input-Output System FAT1 – Also Called as “Boot Sector” or “Volume Boot Record” – Specifies FAT2 • Number of sectors in the storage partition/disk/device Cluster 2 • Number of FATs ( File Allocation Table) Cluster 3 • Sectors per cluster Cluster 4 …………. Data FAT1 – File Allocation Table …………. clusters - Linear linking (chain) of data clusters of the …………. file/directory FAT2 – Backup of FAT1 FILE.TXT cluster3 cluster7 EOF Data clusters - Group of physical/logical sectors/blocks Clusters chain / Linked list of 3 clusters - Contains directories or Files data ExFAT Linux Development Center Need For ExFAT file system l FAT File system limited to support only 32GB. – FAT does not support Higher size SDXC cards. l NTFS – Security features – Optional for Removable storage devices – Meta data overhead for file/directory – Write caching mechanism for performance optimizations causes the data corruption in when 4 removable storage device is unplugged. -

DOS 3.30 Package?
Disk Operating System Version 3.30 Technical Reference Programming Family - ------....-- - --- ---- -. --- ----------,.-- - --- - First Edition (April 1987) The following paragraph does not apply to the United Kingdom or any country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you. This publication could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time. It is possible that this publication may contain reference to, or information about, IBM products (machines and programs), programming, or services that are not announced in your country. Such references or information must not be construed to mean that IBM intends to announce such IBM products, programming, or services in your country. Requests for copies of this publication and for technical information about IBM products should be made to your authorized IBM Dealer or your IBM Marketing Representative. © Copyright International Business Machines Corporation 1985, 1987 About This Book Information in this book applies to DOS versions 2.10 to 3.30 unless specified in each chapter under the heading "Version Specific Information." 111 How This Book is Organized This Technical Reference has two sections. -

File Allocation Table File Allocation Table
File Allocation Table File Allocation Table How It Seems To Work Thomas Kjoernes, Thu, 11th of May 2000 Introduction In this article I will talk about FAT, the MS-DOS file system supported by most of today's OSes. I will start out by explaining a little bit about the various flavours of FAT as used by MS-DOS, then I’ll move on to explaining the various parts that make up the FAT file system and describe the structures Some FAT source code and information: OS.ZIP - This is my OS package! It contains three boot sector sources. FAT32.HTML - This is an excerpt from the FAT32API.HLP file from Microsoft. FAT12.ASM - Example of a FAT12 boot sector. FAT16.ASM - Example of a FAT16 boot sector. FAT32.ASM - Example of a FAT32 boot sector. I will try to update this document with sample code and descriptions of how to interpret the FAT and perform common operations, such as searching for and reading/writing files. FAT Types Today FAT comes in three different flavours – FAT12, FAT16 and FAT32. The names refer to the number of bits used by the entries in table that gave the file system its name! The "File Allocation Table" itself is actually one of the structures inside the FAT file system as seen on-disk. The purpose of this table is to keep track of which areas of the disk are available and which areas are in use. Another important part about FAT is the "Long File Name" extension to FAT sometimes referred to as VFAT. -

Computer Forensics Tutorial Disk File Systems (FAT16, FAT32, NTFS)
Computer Forensics Tutorial Disk File Systems (FAT16, FAT32, NTFS) José M. Rodríguez Justiniano Computer Science Jeffrey L. Duffany, Ph.D. Computer Science Department Polytechnic University of Puerto Rico Abstract This tutorial is intended as in-class Oracle Virtual Box: is a general-purpose full laboratory exercise for computer forensics classes virtualizer for x86 hardware, targeted at server, at the Polytechnic University of Puerto Rico. It’s desktop and embedded use. Refer to Figure 1. specifically designed to provide basic understanding on the functionalities and capabilities of the tree most used file systems FAT16, FAT32, and NTFS. This document provides an inside or raw view of the files systems structure and how it handles data. It first covers the creation of a lab environment using openly available applications and the use of Hexadecimal Editors or Disk Editors to view and modify data. Key Terms Electronic Data, Forensics, File Figure 1 Systems, Hex Editor, Storage Device, Tutorial. Oracle Virtual Box INTRODUCTION HxD: is a carefully designed and fast hex editor which, additionally to raw disk editing As defined a File System is a means to and modifying of main memory (RAM), organize data expected to be retained after a handles files of any size. Refer to Figure 2. program terminates by providing procedures to store, retrieve and update data, as well as manage the available space on the device which contains it. File systems are used on data storage devices such as hard disk drives, floppy disks, optical discs, or flash memory storage devices to maintain the physical location of the computer files. -

United States Patent (19) 11 Patent Number: 5,802,363 Williams Et Al
III USOO5802363A United States Patent (19) 11 Patent Number: 5,802,363 Williams et al. 45) Date of Patent: Sep. 1, 1998 54 BIOS DYNAMIC EMULATION OF 5,475,845 12/1995 Orton et al. ............................ 395/700 MULTIPLE DISKETTES FROMA SINGLE OTHER PUBLICATIONS MEDIA Business Wire, Inc. (Nov. 11, 1994) Announcement to: 75 Inventors: Donald D. Williams, Boca Raton; Business Editors & Computer/High-Tech Writers. Stanley L. Merkin, Lakeworth; Contents, CD-ROM Professional, vol. 8, No. 7, (Jul 1995) Charles R. Dart, I, Boca Raton, all of Special Feature: Staffing For CD-ROM. Fla. Contents, CD-ROM Professional, vol. 8, No. 8, (Aug. 1995) 73 Assignee: International Business Machines Special Feature: Windows 95, CD-ROM and Multimedia. Corporation, Armonk, N.Y. ISO9660:1988(E) - International Standard. Primary Examiner-James P. Trammell 21 Appl. No.: 803,289 Assistant Examiner-John Q. Chavis 22 Filed: Feb. 20, 1997 Attorney, Agent, or Firm-Bernard D. Bogdon 57 ABSTRACT Related U.S. Application Data A personal computer is BIOS configured to boot from an 63 Continuation of Ser. No. 313,710, Sep. 27, 1994, abandoned. installed CD-ROM storing multiple operating systems in different partitions of the medium. The computer is initially 51 Int, Cl........................ G06F91445 booted from a user selected or default partition emulating a 52 U.S. C. ... 395/652 logical drive. With the original boot partition maintained 58) Field of Search ................................ 395/652 active, emulation of additional partitions as other drives is performed when needed. This is accomplished in BIOS with 56 References Cited multiple device tables, each dynamically associated with a U.S.