What Is Vectorization?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Operating Guide
Operating Guide EPIA EN-Series Mini-ITX Mainboard January 18, 2012 Version 1.21 EPIA EN-Series Operating Guide Table of Contents Table of Contents ...................................................................................................................................................................................... i VIA EPIA EN-Series Overview.............................................................................................................................................................. 1 VIA EPIA EN-Series Layout .................................................................................................................................................................. 2 VIA EPIA EN-Series Specifications ...................................................................................................................................................... 3 VIA EPIA EN Processor SKUs .............................................................................................................................................................. 4 VIA CN700 Chipset Overview ............................................................................................................................................................... 5 VIA EPIA EN-Series I/O Back Panel Layout ...................................................................................................................................... 6 VIA EPIA EN-Series Layout Diagram & Mounting Holes .............................................................................................................. -

Vxworks Architecture Supplement, 6.2
VxWorks Architecture Supplement VxWorks® ARCHITECTURE SUPPLEMENT 6.2 Copyright © 2005 Wind River Systems, Inc. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means without the prior written permission of Wind River Systems, Inc. Wind River, the Wind River logo, Tornado, and VxWorks are registered trademarks of Wind River Systems, Inc. Any third-party trademarks referenced are the property of their respective owners. For further information regarding Wind River trademarks, please see: http://www.windriver.com/company/terms/trademark.html This product may include software licensed to Wind River by third parties. Relevant notices (if any) are provided in your product installation at the following location: installDir/product_name/3rd_party_licensor_notice.pdf. Wind River may refer to third-party documentation by listing publications or providing links to third-party Web sites for informational purposes. Wind River accepts no responsibility for the information provided in such third-party documentation. Corporate Headquarters Wind River Systems, Inc. 500 Wind River Way Alameda, CA 94501-1153 U.S.A. toll free (U.S.): (800) 545-WIND telephone: (510) 748-4100 facsimile: (510) 749-2010 For additional contact information, please visit the Wind River URL: http://www.windriver.com For information on how to contact Customer Support, please visit the following URL: http://www.windriver.com/support VxWorks Architecture Supplement, 6.2 11 Oct 05 Part #: DOC-15660-ND-00 Contents 1 Introduction -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Intel® Architecture and Tools
Klaus-Dieter Oertel Intel-SSG-Developer Products Division FZ Jülich, 22-05-2017 The “Free Lunch” is over, really Processor clock rate growth halted around 2005 Source: © 2014, James Reinders, Intel, used with permission Software must be parallelized to realize all the potential performance 4 Optimization Notice Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Changing Hardware Impacts Software More cores More Threads Wider vectors Intel® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Future Intel® Xeon Intel® Xeon Phi™ Future Intel® Xeon® Processor Processor Processor Processor Xeon® Intel® Xeon® Phi™ x100 x200 Processor Xeon Phi™ Processor 5100 series 5500 series 5600 series E5-2600 v2 Processor Processor1 Coprocessor & Coprocessor (KNH) 64-bit series E5-2600 (KNC) (KNL) v3 series v4 series Up to Core(s) 1 2 4 6 12 18-22 TBD 61 72 TBD Up to Threads 2 2 8 12 24 36-44 TBD 244 288 TBD SIMD Width 128 128 128 128 256 256 512 512 512 TBD Intel® Intel® Intel® Intel® Intel® Intel® Intel® Intel® Vector ISA IMCI 512 TBD SSE3 SSE3 SSE4- 4.1 SSE 4.2 AVX AVX2 AVX-512 AVX-512 Optimization Notice Product specification for launched and shipped products available on ark.intel.com. 1. Not launched or in planning. Copyright © 2016, Intel Corporation. All rights reserved. 9 *Other names and brands may be claimed as the property of others. Changing Hardware Impacts Software More cores More Threads Wider vectors Intel® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Future Intel® Xeon Intel® Xeon Phi™ Future Intel® Xeon® Processor Processor Processor Processor Xeon® Intel® Xeon® Phi™ x100 x200 Processor Xeon Phi™ Processor 5100 series 5500 series 5600 series E5-2600 v2 Processor Processor1 Coprocessor & Coprocessor (KNH) 64-bit series E5-2600 (KNC) (KNL) v3 series v4 series Up to Core(s) 1 2 4 6 12 18-22 TBD 61 72 TBD Up to Threads 2 High2 performance8 12 24software36-44 mustTBD be 244both: 288 TBD SIMD Width 128 . -

Intel® Software Guard Extensions (Intel® SGX)
Intel® Software Guard Extensions (Intel® SGX) Developer Guide Intel(R) Software Guard Extensions Developer Guide Legal Information No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied war- ranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel rep- resentative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Intel technologies features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at Intel.com, or from the OEM or retailer. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm. Intel, the Intel logo, Xeon, and Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. Optimization Notice Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. -

AMD Ryzen 5 1600 Specifications
AMD Ryzen 5 1600 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD Ryzen 5 Model number 1600 CPU part numbers YD1600BBM6IAE is an OEM/tray microprocessor YD1600BBAEBOX is a boxed microprocessor with fan and heatsink Frequency 3200 MHz Turbo frequency 3600 MHz Package 1331-pin lidded micro-PGA package Socket Socket AM4 Introduction date March 15, 2017 (announcement) April 11, 2017 (launch) Price at introduction $219 Architecture / Microarchitecture Microarchitecture Zen Processor core Summit Ridge Core stepping B1 Manufacturing process 0.014 micron FinFET process 4.8 billion transistors Data width 64 bit The number of CPU cores 6 The number of threads 12 Floating Point Unit Integrated Level 1 cache size 6 x 64 KB 4-way set associative instruction caches 6 x 32 KB 8-way set associative data caches Level 2 cache size 6 x 512 KB inclusive 8-way set associative unified caches Level 3 cache size 2 x 8 MB exclusive 16-way set associative shared caches Multiprocessing Uniprocessor Features MMX instructions Extensions to MMX SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions AVX / Advanced Vector Extensions AVX2 / Advanced Vector Extensions 2.0 BMI / BMI1 + BMI2 / Bit Manipulation instructions SHA / Secure Hash Algorithm extensions F16C / 16-bit Floating-Point conversion instructions -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -

Multi-Platform Auto-Vectorization
H-0236 (H0512-002) November 30, 2005 Computer Science IBM Research Report Multi-Platform Auto-Vectorization Dorit Naishlos, Richard Henderson* IBM Research Division Haifa Research Laboratory Mt. Carmel 31905 Haifa, Israel *Red Hat Research Division Almaden - Austin - Beijing - Haifa - India - T. J. Watson - Tokyo - Zurich LIMITED DISTRIBUTION NOTICE: This report has been submitted for publication outside of IBM and will probably be copyrighted if accepted for publication. I thas been issued as a Research Report for early dissemination of its contents. In view of the transfer of copyright to the outside publisher, its distribution outside of IBM prior to publication should be limited to peer communications and specific requests. After outside publication, requests should be filled only by reprints or legally obtained copies of the article (e.g ,. payment of royalties). Copies may be requested from IBM T. J. Watson Research Center , P. O. Box 218, Yorktown Heights, NY 10598 USA (email: [email protected]). Some reports are available on the internet at http://domino.watson.ibm.com/library/CyberDig.nsf/home . Multi-Platform Auto-Vectorization Dorit Naishlos Richard Henderson IBM Haifa Labs Red Hat [email protected] [email protected] Abstract. The recent proliferation of the Single Instruction Multiple Data (SIMD) model has lead to a wide variety of implementations. These have been incorporated into many platforms, from gaming machines and em- bedded DSPs to general purpose architectures. In this paper we present an automatic vectorizer as implemented in GCC - the most multi-targetable compiler available today. We discuss the considerations that are involved in developing a multi-platform vectorization technology, and demonstrate how our vectorization scheme is suited to a variety of SIMD architectures. -
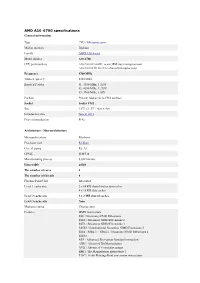
AMD A10-6700 Specifications General Information
AMD A10-6700 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD A10-Series Model number A10-6700 CPU part numbers AD6700OKA44HL is an OEM/tray microprocessor AD6700OKHLBOX is a boxed microprocessor Frequency 3700 MHz Turbo frequency 4300 MHz Boosted P states #1: 4300 MHz, 1.325V #2: 4200 MHz, 1.275V #3: 3900 MHz, 1.05V Package 904-pin lidded micro-PGA package Socket Socket FM2 Size 1.57" x 1.57" / 4cm x 4cm Introduction date June 4, 2013 Price at introduction $142 Architecture / Microarchitecture Microarchitecture Piledriver Processor core Richland Core stepping RL-A1 CPUID 610F31h Manufacturing process 0.032 micron Data width 64 bit The number of cores 4 The number of threads 4 Floating Point Unit Integrated Level 1 cache size 2 x 64 KB shared instruction caches 4 x 16 KB data caches Level 2 cache size 2 x 2 MB shared caches Level 3 cache size None Multiprocessing Uniprocessor Features MMX instructions SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions ABM / Advanced Bit Manipulation AVX / Advanced Vector Extensions BMI1 / Bit Manipulation instructions 1 F16C / 16-bit Floating-Point conversion instructions FMA3 / 3-operand Fused Multiply-Add instructions FMA4 / 4-operand Fused Multiply-Add instructions TBM / Trailing Bit Manipulation instructions XOP / eXtended Operations instructions AMD64 -

A Bibliography of Publications in IEEE Micro
A Bibliography of Publications in IEEE Micro Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 16 September 2021 Version 2.108 Title word cross-reference -Core [MAT+18]. -Cubes [YW94]. -D [ASX19, BWMS19, DDG+19, Joh19c, PZB+19, ZSS+19]. -nm [ABG+16, KBN16, TKI+14]. #1 [Kah93i]. 0.18-Micron [HBd+99]. 0.9-micron + [Ano02d]. 000-fps [KII09]. 000-Processor $1 [Ano17-58, Ano17-59]. 12 [MAT 18]. 16 + + [ABG+16]. 2 [DTH+95]. 21=2 [Ste00a]. 28 [BSP 17]. 024-Core [JJK 11]. [KBN16]. 3 [ASX19, Alt14e, Ano96o, + AOYS95, BWMS19, CMAS11, DDG+19, 1 [Ano98s, BH15, Bre10, PFC 02a, Ste02a, + + Ste14a]. 1-GHz [Ano98s]. 1-terabits DFG 13, Joh19c, LXB07, LX10, MKT 13, + MAS+07, PMM15, PZB+19, SYW+14, [MIM 97]. 10 [Loc03]. 10-Gigabit SCSR93, VPV12, WLF+08, ZSS+19]. 60 [Gad07, HcF04]. 100 [TKI+14]. < [BMM15]. > [BMM15]. 2 [Kir84a, Pat84, PSW91, YSMH91, ZACM14]. [WHCK18]. 3 [KBW95]. II [BAH+05]. ∆ 100-Mops [PSW91]. 1000 [ES84]. 11- + [Lyl04]. 11/780 [Abr83]. 115 [JBF94]. [MKG 20]. k [Eng00j]. µ + [AT93, Dia95c, TS95]. N [YW94]. x 11FO4 [ASD 05]. 12 [And82a]. [DTB01, Dur96, SS05]. 12-DSP [Dur96]. 1284 [Dia94b]. 1284-1994 [Dia94b]. 13 * [CCD+82]. [KW02]. 1394 [SB00]. 1394-1955 [Dia96d]. 1 2 14 [WD03]. 15 [FD04]. 15-Billion-Dollar [KR19a]. -

Compiler-Based Data Prefetching and Streaming Non-Temporal Store Generation for the Intel R Xeon Phitm Coprocessor
Compiler-based Data Prefetching and Streaming Non-temporal Store Generation for the Intel R Xeon PhiTM Coprocessor Rakesh Krishnaiyer†, Emre K¨ult¨ursay†‡, Pankaj Chawla†, Serguei Preis†, Anatoly Zvezdin†, and Hideki Saito† † Intel Corporation ‡ The Pennsylvania State University TM Abstract—The Intel R Xeon Phi coprocessor has software used, and generating them. In this paper, we: TM prefetching instructions to hide memory latencies and spe- • Present how the Intel R Xeon Phi coprocessor soft- cial store instructions to save bandwidth on streaming non- ware prefetch and non-temporal streaming store instructions temporal store operations. In this work, we provide details on R compiler-based generation of these instructions and evaluate are generated by the Intel Composer XE 2013, TM their impact on the performance of the Intel R Xeon Phi • Evaluate the impact of these mechanisms on the overall coprocessor using a wide range of parallel applications with performance of the coprocessor using a variety of parallel different characteristics. Our results show that the Intel R applications with different characteristics. Composer XE 2013 compiler can make effective use of these Our experimental results demonstrate that (i) a large mechanisms to achieve significant performance improvements. number of applications benefit significantly from software prefetching instructions (on top of hardware prefetching) that I. INTRODUCTION are generated automatically by the compiler for the Intel R TM TM The Intel R Xeon Phi coprocessor based on Intel R Xeon Phi coprocessor, (ii) some benchmarks can further Many Integrated Core Architecture (Intel R MIC Architec- improve when compiler options that control prefetching ture) is a many-core processor with long vector (SIMD) units behavior are used (e.g., to enable indirect prefetching), targeted for highly parallel workloads in the High Perfor- and (iii) many applications benefit from compiler generated mance Computing (HPC) segment. -

PC-Doctor Service Center 12 Data Sheet
PC-Doctor Service Center TM Data Sheet PC-Doctor Service Center is the diagnostic toolkit used by repair organizations, IT professionals, system builders and others to troubleshoot and isolate hardware issues, and to verify system integrity on servers, desktops, notebooks and mobile devices. The Service Center Kit includes diagnostics for Windows, DOS, Android, and Bootable Diagnostics that includes support for PCs and Intel-based Macs. Each kit contains a bootable USB key, CD and DVD test media, loopback adapters for serial, parallel, audio, and RJ45 ports, and a professional carrying case. In addition, the Service Center Premier Kit includes a power supply tester and PCI and miniPCI POST cards with remote display. What’s New? • Drive Erase – Certified NIST compliant! • Organize by customer, system or other desired parameters o Sanitization improvements for NVMe and ATA drives • Store test results from multiple test environments in one place as organized by your choice of sessions o Cloud storage for reports • Android version 8.x Oreo and 9.x Pie support My Links • Support for NVDIMM testing Create shortcuts to the most used utilities, test scripts, • DirectX 12 testing or websites: The first five links are added to the main • Storage testing improvements application screen for easy access. o Improved SAS drive coverage o Improved Intel Optane support System Snapshots o Expanded NVMe testing Snapshots provide a one-click solution to save a • Improved processor support detailed system inventory on PCs and Macs: o AMD Ryzen Mobile CPUs • All hardware devices o Skylake-W Xeon processors • (Windows) OS, virus protection, web browser, o AVX2 for AMD CPUs Windows startup programs and device drivers • Windows Server 2016 support Compare two system snapshots to visually display all • Updated Video Interactive testing hardware and driver changes—great for auditing and building customer confidence.