SKI: Exposing Kernel Concurrency Bugs Through Systematic Schedule
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Trusted Docker Containers and Trusted Vms in Openstack
Trusted Docker Containers and Trusted VMs in OpenStack Raghu Yeluri Abhishek Gupta Outline o Context: Docker Security – Top Customer Asks o Intel’s Focus: Trusted Docker Containers o Who Verifies Trust ? o Reference Architecture with OpenStack o Demo o Availability o Call to Action Docker Overview in a Slide.. Docker Hub Lightweight, open source engine for creating, deploying containers Provides work flow for running, building and containerizing apps. Separates apps from where they run.; Enables Micro-services; scale by composition. Underlying building blocks: Linux kernel's namespaces (isolation) + cgroups (resource control) + .. Components of Docker Docker Engine – Runtime for running, building Docker containers. Docker Repositories(Hub) - SaaS service for sharing/managing images Docker Images (layers) Images hold Apps. Shareable snapshot of software. Container is a running instance of image. Orchestration: OpenStack, Docker Swarm, Kubernetes, Mesos, Fleet, Project Docker Layers Atomic, Lattice… Docker Security – 5 key Customer Asks 1. How do you know that the Docker Host Integrity is there? o Do you trust the Docker daemon? o Do you trust the Docker host has booted with Integrity? 2. How do you verify Docker Container Integrity o Who wrote the Docker image? Do you trust the image? Did the right Image get launched? 3. Runtime Protection of Docker Engine & Enhanced Isolation o How can Intel help with runtime Integrity? 4. Enterprise Security Features – Compliance, Manageability, Identity authentication.. Etc. 5. OpenStack as a single Control Plane for Trusted VMs and Trusted Docker Containers.. Intel’s Focus: Enable Hardware-based Integrity Assurance for Docker Containers – Trusted Docker Containers Trusted Docker Containers – 3 focus areas o Launch Integrity of Docker Host o Runtime Integrity of Docker Host o Integrity of Docker Images Today’s Focus: Integrity of Docker Host, and how to use it in OpenStack. -

Providing User Security Guarantees in Public Infrastructure Clouds
1 Providing User Security Guarantees in Public Infrastructure Clouds Nicolae Paladi, Christian Gehrmann, and Antonis Michalas Abstract—The infrastructure cloud (IaaS) service model offers improved resource flexibility and availability, where tenants – insulated from the minutiae of hardware maintenance – rent computing resources to deploy and operate complex systems. Large-scale services running on IaaS platforms demonstrate the viability of this model; nevertheless, many organizations operating on sensitive data avoid migrating operations to IaaS platforms due to security concerns. In this paper, we describe a framework for data and operation security in IaaS, consisting of protocols for a trusted launch of virtual machines and domain-based storage protection. We continue with an extensive theoretical analysis with proofs about protocol resistance against attacks in the defined threat model. The protocols allow trust to be established by remotely attesting host platform configuration prior to launching guest virtual machines and ensure confidentiality of data in remote storage, with encryption keys maintained outside of the IaaS domain. Presented experimental results demonstrate the validity and efficiency of the proposed protocols. The framework prototype was implemented on a test bed operating a public electronic health record system, showing that the proposed protocols can be integrated into existing cloud environments. Index Terms—Security; Cloud Computing; Storage Protection; Trusted Computing F 1 INTRODUCTION host level. While support data encryption at rest is offered by several cloud providers and can be configured by tenants Cloud computing has progressed from a bold vision to mas- in their VM instances, functionality and migration capabil- sive deployments in various application domains. However, ities of such solutions are severely restricted. -

Ivoyeur: Inotify
COLUMNS iVoyeur inotify DAVE JOSEPHSEN Dave Josephsen is the he last time I changed jobs, the magnitude of the change didn’t really author of Building a sink in until the morning of my first day, when I took a different com- Monitoring Infrastructure bination of freeways to work. The difference was accentuated by the with Nagios (Prentice Hall T PTR, 2007) and is Senior fact that the new commute began the same as the old one, but on this morn- Systems Engineer at DBG, Inc., where he ing, at a particular interchange, I would zig where before I zagged. maintains a gaggle of geographically dispersed It was an unexpectedly emotional and profound metaphor for the change. My old place was server farms. He won LISA ‘04’s Best Paper off to the side, and down below, while my future was straight ahead, and literally under award for his co-authored work on spam construction. mitigation, and he donates his spare time to the SourceMage GNU Linux Project. The fact that it was under construction was poetic but not surprising. Most of the roads I [email protected] travel in the Dallas/Fort Worth area are under construction and have been for as long as anyone can remember. And I don’t mean a lane closed here or there. Our roads drift and wan- der like leaves in the water—here today and tomorrow over there. The exits and entrances, neither a part of this road or that, seem unable to anticipate the movements of their brethren, and are constantly forced to react. -

NOVA: a Log-Structured File System for Hybrid Volatile/Non
NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu and Steven Swanson, University of California, San Diego https://www.usenix.org/conference/fast16/technical-sessions/presentation/xu This paper is included in the Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST ’16). February 22–25, 2016 • Santa Clara, CA, USA ISBN 978-1-931971-28-7 Open access to the Proceedings of the 14th USENIX Conference on File and Storage Technologies is sponsored by USENIX NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu Steven Swanson University of California, San Diego Abstract Hybrid DRAM/NVMM storage systems present a host of opportunities and challenges for system designers. These sys- Fast non-volatile memories (NVMs) will soon appear on tems need to minimize software overhead if they are to fully the processor memory bus alongside DRAM. The result- exploit NVMM’s high performance and efficiently support ing hybrid memory systems will provide software with sub- more flexible access patterns, and at the same time they must microsecond, high-bandwidth access to persistent data, but provide the strong consistency guarantees that applications managing, accessing, and maintaining consistency for data require and respect the limitations of emerging memories stored in NVM raises a host of challenges. Existing file sys- (e.g., limited program cycles). tems built for spinning or solid-state disks introduce software Conventional file systems are not suitable for hybrid mem- overheads that would obscure the performance that NVMs ory systems because they are built for the performance char- should provide, but proposed file systems for NVMs either in- acteristics of disks (spinning or solid state) and rely on disks’ cur similar overheads or fail to provide the strong consistency consistency guarantees (e.g., that sector updates are atomic) guarantees that applications require. -

Firecracker: Lightweight Virtualization for Serverless Applications
Firecracker: Lightweight Virtualization for Serverless Applications Alexandru Agache, Marc Brooker, Andreea Florescu, Alexandra Iordache, Anthony Liguori, Rolf Neugebauer, Phil Piwonka, and Diana-Maria Popa, Amazon Web Services https://www.usenix.org/conference/nsdi20/presentation/agache This paper is included in the Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-13-7 Open access to the Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) is sponsored by Firecracker: Lightweight Virtualization for Serverless Applications Alexandru Agache Marc Brooker Andreea Florescu Amazon Web Services Amazon Web Services Amazon Web Services Alexandra Iordache Anthony Liguori Rolf Neugebauer Amazon Web Services Amazon Web Services Amazon Web Services Phil Piwonka Diana-Maria Popa Amazon Web Services Amazon Web Services Abstract vantage over traditional server provisioning processes: mul- titenancy allows servers to be shared across a large num- Serverless containers and functions are widely used for de- ber of workloads, and the ability to provision new func- ploying and managing software in the cloud. Their popularity tions and containers in milliseconds allows capacity to be is due to reduced cost of operations, improved utilization of switched between workloads quickly as demand changes. hardware, and faster scaling than traditional deployment meth- Serverless is also attracting the attention of the research com- ods. The economics and scale of serverless applications de- munity [21,26,27,44,47], including work on scaling out video mand that workloads from multiple customers run on the same encoding [13], linear algebra [20, 53] and parallel compila- hardware with minimal overhead, while preserving strong se- tion [12]. -

KVM/ARM: Experiences Building the Linux ARM Hypervisor
KVM/ARM: Experiences Building the Linux ARM Hypervisor Christoffer Dall and Jason Nieh fcdall, [email protected] Department of Computer Science, Columbia University Technical Report CUCS-010-13 April 2013 Abstract ization. To address this problem, ARM has introduced hardware virtualization extensions in the newest ARM As ARM CPUs become increasingly common in mo- CPU architectures. ARM has benefited from the hind- bile devices and servers, there is a growing demand sight of x86 in its design. For example, nested page for providing the benefits of virtualization for ARM- tables, not part of the original x86 virtualization hard- based devices. We present our experiences building the ware, are standard in ARM. However, there are impor- Linux ARM hypervisor, KVM/ARM, the first full sys- tant differences between ARM and x86 virtualization ex- tem ARM virtualization solution that can run unmodified tensions such that x86 hypervisor designs may not be guest operating systems on ARM multicore hardware. directly amenable to ARM. These differences may also KVM/ARM introduces split-mode virtualization, allow- impact hypervisor performance, especially for multicore ing a hypervisor to split its execution across CPU modes systems, but have not been evaluated with real hardware. to take advantage of CPU mode-specific features. This allows KVM/ARM to leverage Linux kernel services and We describe our experiences building KVM/ARM, functionality to simplify hypervisor development and the ARM hypervisor in the mainline Linux kernel. maintainability while utilizing recent ARM hardware KVM/ARM is the first hypervisor to leverage ARM virtualization extensions to run application workloads in hardware virtualization support to run unmodified guest guest operating systems with comparable performance operating systems (OSes) on ARM multicore hardware. -

Koller Dan Williams IBM T
An Ounce of Prevention is Worth a Pound of Cure: Ahead-of-time Preparation for Safe High-level Container Interfaces Ricardo Koller Dan Williams IBM T. J. Watson Research Center Abstract as the container filesystem is already layered at the same file- based granularity as images. Containers continue to gain traction in the cloud as However, relying on the host to implement the filesystem lightweight alternatives to virtual machines (VMs). This abstraction is not without cost: the filesystem abstraction is is partially due to their use of host filesystem abstractions, high-level, wide, and complex, providing an ample attack which play a role in startup times, memory utilization, crash surface to the host. Bugs in the filesystem implementation consistency, file sharing, host introspection, and image man- can be exploitedby a user to crash or otherwise get controlof agement. However, the filesystem interface is high-level and the host, resulting in (at least) a complete isolation failure in wide, presenting a large attack surface to the host. Emerg- a multi-tenant environment such as a container-based cloud. ing secure container efforts focus on lowering the level A search on the CVE database [13] for kernel filesystem vul- of abstraction of the interface to the host through deprivi- nerabilities provides a sobering reminder of the width, com- leged functionality recreation (e.g., VMs, userspace kernels). plexity, and ultimately danger of filesystem interfaces. However, the filesystem abstraction is so important that some have resorted to directly exposing it from the host instead of Efforts to improve the security of containers use low-level suffering the resulting semantic gap. -

Monitoring File Events
MONITORING FILE EVENTS Some applications need to be able to monitor files or directories in order to deter- mine whether events have occurred for the monitored objects. For example, a graphical file manager needs to be able to determine when files are added or removed from the directory that is currently being displayed, or a daemon may want to monitor its configuration file in order to know if the file has been changed. Starting with kernel 2.6.13, Linux provides the inotify mechanism, which allows an application to monitor file events. This chapter describes the use of inotify. The inotify mechanism replaces an older mechanism, dnotify, which provided a subset of the functionality of inotify. We describe dnotify briefly at the end of this chapter, focusing on why inotify is better. The inotify and dnotify mechanisms are Linux-specific. (A few other systems provide similar mechanisms. For example, the BSDs provide the kqueue API.) A few libraries provide an API that is more abstract and portable than inotify and dnotify. The use of these libraries may be preferable for some applications. Some of these libraries employ inotify or dnotify, on systems where they are available. Two such libraries are FAM (File Alteration Monitor, http:// oss.sgi.com/projects/fam/) and Gamin (http://www.gnome.org/~veillard/gamin/). 19.1 Overview The key steps in the use of the inotify API are as follows: 1. The application uses inotify_init() to create an inotify instance. This system call returns a file descriptor that is used to refer to the inotify instance in later operations. -

Verifying a High-Performance Crash-Safe File System Using a Tree Specification
Verifying a high-performance crash-safe file system using a tree specification Haogang Chen,y Tej Chajed, Alex Konradi,z Stephanie Wang,x Atalay İleri, Adam Chlipala, M. Frans Kaashoek, Nickolai Zeldovich MIT CSAIL ABSTRACT 1 INTRODUCTION File systems achieve high I/O performance and crash safety DFSCQ is the first file system that (1) provides a precise by implementing sophisticated optimizations to increase disk fsync fdatasync specification for and , which allow appli- throughput. These optimizations include deferring writing cations to achieve high performance and crash safety, and buffered data to persistent storage, grouping many trans- (2) provides a machine-checked proof that its implementa- actions into a single I/O operation, checksumming journal tion meets this specification. DFSCQ’s specification captures entries, and bypassing the write-ahead log when writing to the behavior of sophisticated optimizations, including log- file data blocks. The widely used Linux ext4 is an example bypass writes, and DFSCQ’s proof rules out some of the of an I/O-efficient file system; the above optimizations allow common bugs in file-system implementations despite the it to batch many writes into a single I/O operation and to complex optimizations. reduce the number of disk-write barriers that flush data to The key challenge in building DFSCQ is to write a speci- disk [33, 56]. Unfortunately, these optimizations complicate fication for the file system and its internal implementation a file system’s implementation. For example, it took 6 years without exposing internal file-system details. DFSCQ in- for ext4 developers to realize that two optimizations (data troduces a metadata-prefix specification that captures the writes that bypass the journal and journal checksumming) properties of fsync and fdatasync, which roughly follows taken together can lead to disclosure of previously deleted the behavior of Linux ext4. -

Fsmonitor: Scalable File System Monitoring for Arbitrary Storage Systems
FSMonitor: Scalable File System Monitoring for Arbitrary Storage Systems Arnab K. Paul∗, Ryan Chardy, Kyle Chardz, Steven Tueckez, Ali R. Butt∗, Ian Fostery;z ∗Virginia Tech, yArgonne National Laboratory, zUniversity of Chicago fakpaul, [email protected], frchard, [email protected], fchard, [email protected] Abstract—Data automation, monitoring, and management enable programmatic management, and even autonomously tools are reliant on being able to detect, report, and respond manage the health of the system. Enabling scalable, reliable, to file system events. Various data event reporting tools exist for and standardized event detection and reporting will also be of specific operating systems and storage devices, such as inotify for Linux, kqueue for BSD, and FSEvents for macOS. How- value to a range of infrastructures and tools, such as Software ever, these tools are not designed to monitor distributed file Defined CyberInfrastructure (SDCI) [14], auditing [9], and systems. Indeed, many cannot scale to monitor many thousands automating analytical pipelines [11]. Such systems enable of directories, or simply cannot be applied to distributed file automation by allowing programs to respond to file events systems. Moreover, each tool implements a custom API and and initiate tasks. event representation, making the development of generalized and portable event-based applications challenging. As file systems Most storage systems provide mechanisms to detect and grow in size and become increasingly diverse, there is a need report data events, such as file creation, modification, and for scalable monitoring solutions that can be applied to a wide deletion. Tools such as inotify [20], kqueue [18], and FileSys- range of both distributed and local systems. -

NOVA Introduction
NOVA introduction Michal Sojka1 Czech Technical University in Prague, Email: [email protected] December 5, 2017 1Based on exercises by Benjamin Engel from TU Dresden. M. Sojka B4B35OSY NOVA intro December 5, 2017 1 / 16 NOVA microhypervisor I Research project of TU Dresden (< 2012) and Intel Labs (≥ 2012). I http://hypervisor.org/, x86, GPL. I We will use a stripped down version (2 kLoC) of the microhypervisor (kernel). M. Sojka B4B35OSY NOVA intro December 5, 2017 2 / 16 Table of content Prerequisites System booting Program binaries ELF headers Virtual memory management Additional information M. Sojka B4B35OSY NOVA intro December 5, 2017 3 / 16 Prerequisites What you need to know? I NOVA is implemented in C++ (and assembler). I Each user “program” is represented by execution context data structure (class Ec). I The first executed program is called root task (similar to init process in Unix). M. Sojka B4B35OSY NOVA intro December 5, 2017 4 / 16 Prerequisites Getting started unzip nova.zip cd nova make # Compile everything make run # Run it in Qemu emulator Understanding qemu invocation qemu-system-i386 -serial stdio -kernel kern/build/hypervisor -initrd user/hello I Serial line of the emulated machine will go to stdout I Address of user/hello binary will be passed to the kernel via Multiboot info data structure Source code layout I user/ – user space code (hello world + other simple programs) I kern/ – stripped down NOVA kernel I you will need to modify kern/src/ec.cc M. Sojka B4B35OSY NOVA intro December 5, 2017 5 / 16 0 0x2000 3G (0xC0000000) Remap 4G page Virtual memory User space Kernel space EIP EIPEIPEIPEIP Kernel code/data ELF header EIP User code/data User stack multiboot user/hello kern/build/hypervisor info System booting NOVA booting 1. -
Hitachi Cloud Accelerator Platform Product Manager HCAP V 1
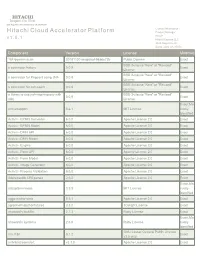
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Cloud Accelerator Platform Product Manager HCAP v 1 . 5 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified 18F/domain-scan 20181130-snapshot-988de72b Public Domain Exact BSD 3-clause "New" or "Revised" a connector factory 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for Pageant using JNA 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for ssh-agent 0.0.9 Exact License a library to use jsch-agent-proxy with BSD 3-clause "New" or "Revised" 0.0.9 Exact sshj License Exact,Ma activesupport 5.2.1 MIT License nually Identified Activiti - BPMN Converter 6.0.0 Apache License 2.0 Exact Activiti - BPMN Model 6.0.0 Apache License 2.0 Exact Activiti - DMN API 6.0.0 Apache License 2.0 Exact Activiti - DMN Model 6.0.0 Apache License 2.0 Exact Activiti - Engine 6.0.0 Apache License 2.0 Exact Activiti - Form API 6.0.0 Apache License 2.0 Exact Activiti - Form Model 6.0.0 Apache License 2.0 Exact Activiti - Image Generator 6.0.0 Apache License 2.0 Exact Activiti - Process Validation 6.0.0 Apache License 2.0 Exact Addressable URI parser 2.5.2 Apache License 2.0 Exact Exact,Ma adzap/timeliness 0.3.8 MIT License nually Identified aggs-matrix-stats 5.5.1 Apache License 2.0 Exact agronholm/pythonfutures 3.3.0 3Delight License Exact ahoward's lockfile 2.1.3 Ruby License Exact Exact,Ma ahoward's systemu 2.6.5 Ruby License nually Identified GNU Lesser General Public License ai's