Logging Statements Rewrite Tool for Java Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Commonjavajars - a Package with Useful Libraries for Java Guis
CommonJavaJars - A package with useful libraries for Java GUIs To reduce the package size of other R packages with Java GUIs and to reduce jar file conflicts, this package provides a few commonly used Java libraries. You should be able to load them by calling the rJava .jpackage function (a good place is most likely the .onLoad function of your package): .jpackage("CommonJavaJars", jars=c("forms-1.2.0.jar", "iText-2.1.4.jar")) We provide the following Java libraries: Apache Commons Logging under the Apache License, Version 2.0, January 2004, http://commons. apache.org/logging/, Copyright 2001-2007 The Apache Software Foundation Apache jog4j under Apache License 2.0, http://logging.apache.org/log4j/, Copyright 2007 The Apache Software Foundation Apache Commons Lang under Apache License 2.0, http://commons.apache.org/lang/, Copyright 2001-2011 The Apache Software Foundation Apache POI under Apache License 2.0, http://poi.apache.org/, Copyright 2001-2007 The Apache Software Foundation Apache Commons Collections under the Apache License, Version 2.0, January 2004, http://commons. apache.org/collections/, Copyright 2001-2008 The Apache Software Foundation Apache Commons Validator under the Apache License, Version 2.0, January 2004, http://commons. apache.org/validator/, Copyright 2001-2010 The Apache Software Foundation JLaTeXMath under GPL >= 2.0, http://forge.scilab.org/index.php/p/jlatexmath/, Copyright 2004-2007, 2009 Calixte, Coolsaet, Cleemput, Vermeulen and Universiteit Gent iText 2.1.4 under LGPL, http://itextpdf.com/, Copyright -

Log4j-Users-Guide.Pdf
...................................................................................................................................... Apache Log4j 2 v. 2.2 User's Guide ...................................................................................................................................... The Apache Software Foundation 2015-02-22 T a b l e o f C o n t e n t s i Table of Contents ....................................................................................................................................... 1. Table of Contents . i 2. Introduction . 1 3. Architecture . 3 4. Log4j 1.x Migration . 10 5. API . 16 6. Configuration . 18 7. Web Applications and JSPs . 48 8. Plugins . 56 9. Lookups . 60 10. Appenders . 66 11. Layouts . 120 12. Filters . 140 13. Async Loggers . 153 14. JMX . 167 15. Logging Separation . 174 16. Extending Log4j . 176 17. Extending Log4j Configuration . 184 18. Custom Log Levels . 187 © 2 0 1 5 , T h e A p a c h e S o f t w a r e F o u n d a t i o n • A L L R I G H T S R E S E R V E D . T a b l e o f C o n t e n t s ii © 2 0 1 5 , T h e A p a c h e S o f t w a r e F o u n d a t i o n • A L L R I G H T S R E S E R V E D . 1 I n t r o d u c t i o n 1 1 Introduction ....................................................................................................................................... 1.1 Welcome to Log4j 2! 1.1.1 Introduction Almost every large application includes its own logging or tracing API. In conformance with this rule, the E.U. -

The Pentaho Big Data Guide This Document Supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, Documentation Revision October 31, 2012
The Pentaho Big Data Guide This document supports Pentaho Business Analytics Suite 4.8 GA and Pentaho Data Integration 4.4 GA, documentation revision October 31, 2012. This document is copyright © 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property of their respective owners. Help and Support Resources If you have questions that are not covered in this guide, or if you would like to report errors in the documentation, please contact your Pentaho technical support representative. Support-related questions should be submitted through the Pentaho Customer Support Portal at http://support.pentaho.com. For information about how to purchase support or enable an additional named support contact, please contact your sales representative, or send an email to [email protected]. For information about instructor-led training on the topics covered in this guide, visit http://www.pentaho.com/training. Limits of Liability and Disclaimer of Warranty The author(s) of this document have used their best efforts in preparing the content and the programs contained in it. These efforts include the development, research, and testing of the theories and programs to determine their effectiveness. The author and publisher make no warranty of any kind, express or implied, with regard to these programs or the documentation contained in this book. The author(s) and Pentaho shall not be liable in the event of incidental or consequential damages in connection with, or arising out of, the furnishing, performance, or use of the programs, associated instructions, and/or claims. Trademarks Pentaho (TM) and the Pentaho logo are registered trademarks of Pentaho Corporation. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

LMAX Disruptor
Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads Martin Thompson Dave Farley Michael Barker Patricia Gee Andrew Stewart May-2011 http://code.google.com/p/disruptor/ 1 Abstract LMAX was established to create a very high performance financial exchange. As part of our work to accomplish this goal we have evaluated several approaches to the design of such a system, but as we began to measure these we ran into some fundamental limits with conventional approaches. Many applications depend on queues to exchange data between processing stages. Our performance testing showed that the latency costs, when using queues in this way, were in the same order of magnitude as the cost of IO operations to disk (RAID or SSD based disk system) – dramatically slow. If there are multiple queues in an end-to-end operation, this will add hundreds of microseconds to the overall latency. There is clearly room for optimisation. Further investigation and a focus on the computer science made us realise that the conflation of concerns inherent in conventional approaches, (e.g. queues and processing nodes) leads to contention in multi-threaded implementations, suggesting that there may be a better approach. Thinking about how modern CPUs work, something we like to call “mechanical sympathy”, using good design practices with a strong focus on teasing apart the concerns, we came up with a data structure and a pattern of use that we have called the Disruptor. Testing has shown that the mean latency using the Disruptor for a three-stage pipeline is 3 orders of magnitude lower than an equivalent queue-based approach. -

Neon Core Infrastructure Services
NeOn-project.org NeOn: Lifecycle Support for Networked Ontologies Integrated Project (IST-2005-027595) Priority: IST-2004-2.4.7 – “Semantic-based knowledge and content systems” D6.4.2 NeOn core infrastructure services Deliverable Co-ordinator: Walter Waterfeld Deliverable Co-ordinating Institution: Software AG (SAG) Other Authors: Diana Maynard, University of Sheffield (USFD), Ian Roberts, University of Sheffield (USFD), Michael Gesmann, Software AG (SAG) Document Identifier: NEON/2010/D6.4.2/v1.0 Date due: October 31st, 2009 Class Deliverable: NEON EU-IST-2005-027595 Submission date: January 31st , 2010 Project start date: March 1, 2006 Version: v1.0 Project duration: 4 years State: Final Distribution: Public 2006–2010 © Copyright lies with the respective authors and their institutions. Page 2 of 25 NeOn Integrated Project EU-IST-027595 NeOn Consortium This document is a part of the NeOn research project funded by the IST Programme of the Commission of the European Communities by the grant number IST-2005-027595. The following partners are involved in the project: Open University (OU) – Coordinator Universität Karlsruhe – TH (UKARL) Knowledge Media Institute – KMi Institut für Angewandte Informatik und Formale Berrill Building, Walton Hall Beschreibungsverfahren – AIFB Milton Keynes, MK7 6AA Englerstrasse 11 United Kingdom D-76128 Karlsruhe, Germany Contact person: Enrico Motta Contact person: Andreas Harth E-mail address: [email protected] E-mail address: [email protected] Universidad Politécnica de Madrid (UPM) Software AG (SAG) Campus de Montegancedo Uhlandstrasse 12 28660 Boadilla del Monte 64297 Darmstadt Spain Germany Contact person: Asunción Gómez Pérez Contact person: Walter Waterfeld E-mail address: [email protected] E-mail address: [email protected] Intelligent Software Components S.A. -

High Performance & Low Latency Complex Event Processor
International Journal of Science and Research (IJSR) ISSN (Online): 2319-7064 Impact Factor (2012): 3.358 Lightning CEP - High Performance & Low Latency Complex Event Processor Vikas Kale1, Kishor Shedge2 1, 2Sir Visvesvaraya Institute of Technology, Chincholi, Nashik, 422101, India Abstract: Number of users and devices connected to internet is growing exponentially. Each of these device and user generate lot of data which organizations want to analyze and use. Hadoop like batch processing are evolved to process such big data. Batch processing systems provide offline data processing capability. There are many businesses which requires real-time or near real-time processing of data for faster decision making. Hadoop and batch processing system are not suitable for this. Stream processing systems are designed to support class of applications which requires fast and timely analysis of high volume data streams. Complex event processing, or CEP, is event/stream processing that combines data from multiple sources to infer events or patterns that suggest more complicated circumstances. In this paper I propose “Lightning - High Performance & Low Latency Complex Event Processor” engine. Lightning is based on open source stream processor WSO2 Siddhi. Lightning retains most of API and Query Processing of WSO2 Siddhi. WSO2 Siddhi core is modified using low latency technique such as Ring Buffer, off heap data store and other techniques. Keywords: CEP, Complex Event Processing, Stream Processing. 1. Introduction of stream applications include automated stock trading, real- time video processing, vital-signs monitoring and geo-spatial Number of users and devices connected to internet is trajectory modification. Results produced by such growing exponentially. -

Need a Title Here
Equilibrium Behaviour of Double-Sided Queueing System with Dependent Matching Time by Cheryl Yang A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of the requirements for the degree of Master of Science in Probability and Statistics Carleton University Ottawa, Ontario @ 2020 Cheryl Yang ii Abstract In this thesis, we consider the equilibrium behaviour of a double-ended queueing system with dependent matching time in the context of taxi-passenger systems at airport terminal pickup. We extend the standard taxi-passenger model by considering random matching time between taxis and passengers in an airport terminal pickup setting. For two types of matching time distribution, we examine this model through analysis of equilibrium behaviour and optimal strategies. We demonstrate in detail how to derive the equilibrium joining strategies for passen- gers arriving at the terminal and the existence of a socially optimal strategies for partially observable and fully observable cases. Numerical experiments are used to examine the behaviour of social welfare and compare cases. iii Acknowledgements I would like to give my deepest gratitude to my supervisor, Dr. Yiqiang Zhao, for his tremendous support throughout my graduate program. Dr. Zhao gave me the opportunity to explore and be exposed to various applications of queueing theory and offered invaluable guidance and advice in my thesis research. Without his help, this thesis would not be possible. I am grateful for his patience, the time he has spent advising me, and his moral support that guided me through my studies at Carleton University. I would also like to thank Zhen Wang of Nanjing University of Science and Tech- nology for his gracious help and patience. -

Develop a Simple Web Application with Apache Wicket and Apache
Develop a simple Web application with Apache Wicket and Apache Geronimo Combine Wicket, Geronimo, and Apache Derby to form an open source Java Web development platform Skill Level: Intermediate Robi Sen ([email protected]) Vice President Department 13 LLC 10 Jul 2007 Apache Wicket is an innovative Java™ Web application framework that was introduced a couple of years ago. It helps simplify Web application development by clearly separating the roles of developers and designers. It lets you remove logical code from the view layer, eliminating the need for JavaServer Pages (JSP), providing a simple plain old Java object (POJO)-centric mode of development, and removing much of the need for XML and other configuration file formats. In this tutorial, learn how to set up your system to develop a simple Web application with Wicket, using Apache Geronimo as your application server and Apache Derby as the embedded database. Section 1. Before you start This tutorial is designed for developers who have found Java frameworks, such as Struts, lacking in needed functionality. If you're interested in developing Web applications in a more object-oriented manner, where the view is clearly separated from logic and there's minimal configuration and mapping, then Wicket is for you! This tutorial walks you through the basics of how Wicket works, while using Apache Geronimo to set up a Java Platform, Enterprise Edition (Java EE) server, Web server, and embedded database in just minutes. Combining Wicket with Geronimo lets you develop data-driven, scalable Web applications using software that's all open source. Develop a simple Web application with Apache Wicket and Apache Geronimo © Copyright IBM Corporation 1994, 2008. -
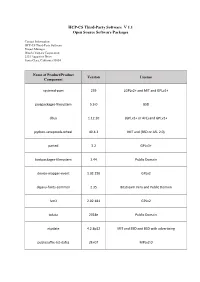
HCP-CS Third-Party Software V1.1
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

Hadoop Operations and Cluster Management Cookbook
Hadoop Operations and Cluster Management Cookbook Over 60 recipes showing you how to design, configure, manage, monitor, and tune a Hadoop cluster Shumin Guo BIRMINGHAM - MUMBAI Hadoop Operations and Cluster Management Cookbook Copyright © 2013 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: July 2013 Production Reference: 1170713 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78216-516-3 www.packtpub.com Cover Image by Girish Suryavanshi ([email protected]) Credits Author Project Coordinator Shumin Guo Anurag Banerjee Reviewers Proofreader Hector Cuesta-Arvizu Lauren Tobon Mark Kerzner Harvinder Singh Saluja Indexer Hemangini Bari Acquisition Editor Kartikey Pandey Graphics Abhinash Sahu Lead Technical Editor Madhuja Chaudhari Production Coordinator Nitesh Thakur Technical Editors Sharvari Baet Cover Work Nitesh Thakur Jalasha D'costa Veena Pagare Amit Ramadas About the Author Shumin Guo is a PhD student of Computer Science at Wright State University in Dayton, OH. -

Varon-T Documentation Release 2.0.1-Dev-5-G376477b
Varon-T Documentation Release 2.0.1-dev-5-g376477b RedJack, LLC June 21, 2016 Contents 1 Contents 3 1.1 Introduction...............................................3 1.2 Disruptor queue management......................................3 1.3 Value objects...............................................5 1.4 Producers.................................................6 1.5 Consumers................................................7 1.6 Yield strategies..............................................9 1.7 Example: Summing integers.......................................9 2 Indices and tables 15 i ii Varon-T Documentation, Release 2.0.1-dev-5-g376477b This is the documentation for Varon-T 2.0.1-dev-5-g376477b, last updated June 21, 2016. Contents 1 Varon-T Documentation, Release 2.0.1-dev-5-g376477b 2 Contents CHAPTER 1 Contents 1.1 Introduction Message passing is currently a popular approach for implementing concurrent data processing applications. In this model, you decompose a large processing task into separate steps that execute concurrently and communicate solely by passing messages or data items between one another. This concurrency model is an intuitive way to structure a large processing task to exploit parallelism in a shared memory environment without incurring the complexity and overhead costs associated with multi-threaded applications. In order to use a message passing model, you need an efficient data structure for passing messages between the processing elements of your application. A common approach is to utilize queues for storing and retrieving messages. Varon-T is a C library that implements a disruptor queue (originally implemented in the Disruptor Java library), which is a particularly efficient FIFO queue implementation. Disruptor queues achieve their efficiency through a number of related techniques: • Objects are stored in a ring buffer, which uses a fixed amount of memory regardless of the number of data records processed.