Parallel Prefix Sum with SIMD
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parallel Prefix Sum (Scan) with CUDA
Parallel Prefix Sum (Scan) with CUDA Mark Harris [email protected] April 2007 Document Change History Version Date Responsible Reason for Change February 14, Mark Harris Initial release 2007 April 2007 ii Abstract Parallel prefix sum, also known as parallel Scan, is a useful building block for many parallel algorithms including sorting and building data structures. In this document we introduce Scan and describe step-by-step how it can be implemented efficiently in NVIDIA CUDA. We start with a basic naïve algorithm and proceed through more advanced techniques to obtain best performance. We then explain how to scan arrays of arbitrary size that cannot be processed with a single block of threads. Month 2007 1 Parallel Prefix Sum (Scan) with CUDA Table of Contents Abstract.............................................................................................................. 1 Table of Contents............................................................................................... 2 Introduction....................................................................................................... 3 Inclusive and Exclusive Scan .........................................................................................................................3 Sequential Scan.................................................................................................................................................4 A Naïve Parallel Scan ......................................................................................... 4 A Work-Efficient -

CSE373: Data Structures & Algorithms Lecture 26
CSE373: Data Structures & Algorithms Lecture 26: Parallel Reductions, Maps, and Algorithm Analysis Aaron Bauer Winter 2014 Outline Done: • How to write a parallel algorithm with fork and join • Why using divide-and-conquer with lots of small tasks is best – Combines results in parallel – (Assuming library can handle “lots of small threads”) Now: • More examples of simple parallel programs that fit the “map” or “reduce” patterns • Teaser: Beyond maps and reductions • Asymptotic analysis for fork-join parallelism • Amdahl’s Law • Final exam and victory lap Winter 2014 CSE373: Data Structures & Algorithms 2 What else looks like this? • Saw summing an array went from O(n) sequential to O(log n) parallel (assuming a lot of processors and very large n!) – Exponential speed-up in theory (n / log n grows exponentially) + + + + + + + + + + + + + + + • Anything that can use results from two halves and merge them in O(1) time has the same property… Winter 2014 CSE373: Data Structures & Algorithms 3 Examples • Maximum or minimum element • Is there an element satisfying some property (e.g., is there a 17)? • Left-most element satisfying some property (e.g., first 17) – What should the recursive tasks return? – How should we merge the results? • Corners of a rectangle containing all points (a “bounding box”) • Counts, for example, number of strings that start with a vowel – This is just summing with a different base case – Many problems are! Winter 2014 CSE373: Data Structures & Algorithms 4 Reductions • Computations of this form are called reductions -

CSE 613: Parallel Programming Lecture 2
CSE 613: Parallel Programming Lecture 2 ( Analytical Modeling of Parallel Algorithms ) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2019 Parallel Execution Time & Overhead et al., et Edition Grama nd 2 Source: “Introduction to Parallel Computing”, to Parallel “Introduction Parallel running time on 푝 processing elements, 푇푃 = 푡푒푛푑 – 푡푠푡푎푟푡 , where, 푡푠푡푎푟푡 = starting time of the processing element that starts first 푡푒푛푑 = termination time of the processing element that finishes last Parallel Execution Time & Overhead et al., et Edition Grama nd 2 Source: “Introduction to Parallel Computing”, to Parallel “Introduction Sources of overhead ( w.r.t. serial execution ) ― Interprocess interaction ― Interact and communicate data ( e.g., intermediate results ) ― Idling ― Due to load imbalance, synchronization, presence of serial computation, etc. ― Excess computation ― Fastest serial algorithm may be difficult/impossible to parallelize Parallel Execution Time & Overhead et al., et Edition Grama nd 2 Source: “Introduction to Parallel Computing”, to Parallel “Introduction Overhead function or total parallel overhead, 푇푂 = 푝푇푝 – 푇 , where, 푝 = number of processing elements 푇 = time spent doing useful work ( often execution time of the fastest serial algorithm ) Speedup Let 푇푝 = running time using 푝 identical processing elements 푇1 Speedup, 푆푝 = 푇푝 Theoretically, 푆푝 ≤ 푝 ( why? ) Perfect or linear or ideal speedup if 푆푝 = 푝 Speedup Consider adding 푛 numbers using 푛 identical processing Edition nd elements. Serial runtime, -

A Review of Multicore Processors with Parallel Programming
International Journal of Engineering Technology, Management and Applied Sciences www.ijetmas.com September 2015, Volume 3, Issue 9, ISSN 2349-4476 A Review of Multicore Processors with Parallel Programming Anchal Thakur Ravinder Thakur Research Scholar, CSE Department Assistant Professor, CSE L.R Institute of Engineering and Department Technology, Solan , India. L.R Institute of Engineering and Technology, Solan, India ABSTRACT When the computers first introduced in the market, they came with single processors which limited the performance and efficiency of the computers. The classic way of overcoming the performance issue was to use bigger processors for executing the data with higher speed. Big processor did improve the performance to certain extent but these processors consumed a lot of power which started over heating the internal circuits. To achieve the efficiency and the speed simultaneously the CPU architectures developed multicore processors units in which two or more processors were used to execute the task. The multicore technology offered better response-time while running big applications, better power management and faster execution time. Multicore processors also gave developer an opportunity to parallel programming to execute the task in parallel. These days parallel programming is used to execute a task by distributing it in smaller instructions and executing them on different cores. By using parallel programming the complex tasks that are carried out in a multicore environment can be executed with higher efficiency and performance. Keywords: Multicore Processing, Multicore Utilization, Parallel Processing. INTRODUCTION From the day computers have been invented a great importance has been given to its efficiency for executing the task. -

Parallel Algorithms and Parallel Program Design
Introduction to Parallel Algorithms and Parallel Program Design Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 12 – Introduction to Parallel Algorithms Methodological Design q Partition ❍ Task/data decomposition q Communication ❍ Task execution coordination q Agglomeration ❍ Evaluation of the structure q Mapping I. Foster, “Designing and Building ❍ Resource assignment Parallel Programs,” Addison-Wesley, 1995. Book is online, see webpage. Introduction to Parallel Computing, University of Oregon, IPCC Lecture 12 – Introduction to Parallel Algorithms 2 Partitioning q Partitioning stage is intended to expose opportunities for parallel execution q Focus on defining large number of small task to yield a fine-grained decomposition of the problem q A good partition divides into small pieces both the computational tasks associated with a problem and the data on which the tasks operates q Domain decomposition focuses on computation data q Functional decomposition focuses on computation tasks q Mixing domain/functional decomposition is possible Introduction to Parallel Computing, University of Oregon, IPCC Lecture 12 – Introduction to Parallel Algorithms 3 Domain and Functional Decomposition q Domain decomposition of 2D / 3D grid q Functional decomposition of a climate model Introduction to Parallel Computing, University of Oregon, IPCC Lecture 12 – Introduction to Parallel Algorithms 4 Partitioning Checklist q Does your partition define at least an order of magnitude more tasks than there are processors in your target computer? If not, may loose design flexibility. q Does your partition avoid redundant computation and storage requirements? If not, may not be scalable. q Are tasks of comparable size? If not, it may be hard to allocate each processor equal amounts of work. -

Parallel Processing! 1! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 2! Suggested Readings! •! Readings! –! H&P: Chapter 7! •! (Over Next 2 Weeks)!
CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 1! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 2! Suggested Readings! •! Readings! –! H&P: Chapter 7! •! (Over next 2 weeks)! Lecture 23" Introduction to Parallel Processing! University of Notre Dame! University of Notre Dame! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 3! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 4! Processor components! Multicore processors and programming! Processor comparison! vs.! Goal: Explain and articulate why modern microprocessors now have more than one core andCSE how software 30321 must! adapt to accommodate the now prevalent multi- core approach to computing. " Introduction and Overview! Writing more ! efficient code! The right HW for the HLL code translation! right application! University of Notre Dame! University of Notre Dame! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! 6! Pipelining and “Parallelism”! ! Load! Mem! Reg! DM! Reg! ALU ! Instruction 1! Mem! Reg! DM! Reg! ALU ! Instruction 2! Mem! Reg! DM! Reg! ALU ! Instruction 3! Mem! Reg! DM! Reg! ALU ! Instruction 4! Mem! Reg! DM! Reg! ALU Time! Instructions execution overlaps (psuedo-parallel)" but instructions in program issued sequentially." University of Notre Dame! University of Notre Dame! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! CSE 30321 – Lecture 23 – Introduction to Parallel Processing! Multiprocessing (Parallel) Machines! Flynn#s -

A Review of Parallel Processing Approaches to Robot Kinematics and Jacobian
Technical Report 10/97, University of Karlsruhe, Computer Science Department, ISSN 1432-7864 A Review of Parallel Processing Approaches to Robot Kinematics and Jacobian Dominik HENRICH, Joachim KARL und Heinz WÖRN Institute for Real-Time Computer Systems and Robotics University of Karlsruhe, D-76128 Karlsruhe, Germany e-mail: [email protected] Abstract Due to continuously increasing demands in the area of advanced robot control, it became necessary to speed up the computation. One way to reduce the computation time is to distribute the computation onto several processing units. In this survey we present different approaches to parallel computation of robot kinematics and Jacobian. Thereby, we discuss both the forward and the reverse problem. We introduce a classification scheme and classify the references by this scheme. Keywords: parallel processing, Jacobian, robot kinematics, robot control. 1 Introduction Due to continuously increasing demands in the area of advanced robot control, it became necessary to speed up the computation. Since it should be possible to control the motion of a robot manipulator in real-time, it is necessary to reduce the computation time to less than the cycle rate of the control loop. One way to reduce the computation time is to distribute the computation over several processing units. There are other overviews and reviews on parallel processing approaches to robotic problems. Earlier overviews include [Lee89] and [Graham89]. Lee takes a closer look at parallel approaches in [Lee91]. He tries to find common features in the different problems of kinematics, dynamics and Jacobian computation. The latest summary is from Zomaya et al. [Zomaya96]. -

A Survey on Parallel Multicore Computing: Performance & Improvement
Advances in Science, Technology and Engineering Systems Journal Vol. 3, No. 3, 152-160 (2018) ASTESJ www.astesj.com ISSN: 2415-6698 A Survey on Parallel Multicore Computing: Performance & Improvement Ola Surakhi*, Mohammad Khanafseh, Sami Sarhan University of Jordan, King Abdullah II School for Information Technology, Computer Science Department, 11942, Jordan A R T I C L E I N F O A B S T R A C T Article history: Multicore processor combines two or more independent cores onto one integrated circuit. Received: 18 May, 2018 Although it offers a good performance in terms of the execution time, there are still many Accepted: 11 June, 2018 metrics such as number of cores, power, memory and more that effect on multicore Online: 26 June, 2018 performance and reduce it. This paper gives an overview about the evolution of the Keywords: multicore architecture with a comparison between single, Dual and Quad. Then we Distributed System summarized some of the recent related works implemented using multicore architecture and Dual core show the factors that have an effect on the performance of multicore parallel architecture Multicore based on their results. Finally, we covered some of the distributed parallel system concepts Quad core and present a comparison between them and the multiprocessor system characteristics. 1. Introduction [6]. The heterogenous cores have more than one type of cores, they are not identical, each core can handle different application. Multicore is one of the parallel computing architectures which The later has better performance in terms of less power consists of two or more individual units (cores) that read and write consumption as will be shown later [2]. -

Parallelizing Multiple Flow Accumulation Algorithm Using CUDA and Openacc
International Journal of Geo-Information Article Parallelizing Multiple Flow Accumulation Algorithm using CUDA and OpenACC Natalija Stojanovic * and Dragan Stojanovic Faculty of Electronic Engineering, University of Nis, 18000 Nis, Serbia * Correspondence: [email protected] Received: 29 June 2019; Accepted: 30 August 2019; Published: 3 September 2019 Abstract: Watershed analysis, as a fundamental component of digital terrain analysis, is based on the Digital Elevation Model (DEM), which is a grid (raster) model of the Earth surface and topography. Watershed analysis consists of computationally and data intensive computing algorithms that need to be implemented by leveraging parallel and high-performance computing methods and techniques. In this paper, the Multiple Flow Direction (MFD) algorithm for watershed analysis is implemented and evaluated on multi-core Central Processing Units (CPU) and many-core Graphics Processing Units (GPU), which provides significant improvements in performance and energy usage. The implementation is based on NVIDIA CUDA (Compute Unified Device Architecture) implementation for GPU, as well as on OpenACC (Open ACCelerators), a parallel programming model, and a standard for parallel computing. Both phases of the MFD algorithm (i) iterative DEM preprocessing and (ii) iterative MFD algorithm, are parallelized and run over multi-core CPU and GPU. The evaluation of the proposed solutions is performed with respect to the execution time, energy consumption, and programming effort for algorithm parallelization for different sizes of input data. An experimental evaluation has shown not only the advantage of using OpenACC programming over CUDA programming in implementing the watershed analysis on a GPU in terms of performance, energy consumption, and programming effort, but also significant benefits in implementing it on the multi-core CPU. -

Generic Implementation of Parallel Prefix Sums and Their
GENERIC IMPLEMENTATION OF PARALLEL PREFIX SUMS AND THEIR APPLICATIONS A Thesis by TAO HUANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE May 2007 Major Subject: Computer Science GENERIC IMPLEMENTATION OF PARALLEL PREFIX SUMS AND THEIR APPLICATIONS A Thesis by TAO HUANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Approved by: Chair of Committee, Lawrence Rauchwerger Committee Members, Nancy M. Amato Jennifer L. Welch Marvin L. Adams Head of Department, Valerie E. Taylor May 2007 Major Subject: Computer Science iii ABSTRACT Generic Implementation of Parallel Prefix Sums and Their Applications. (May 2007) Tao Huang, B.E.; M.E., University of Electronic Science and Technology of China Chair of Advisory Committee: Dr. Lawrence Rauchwerger Parallel prefix sums algorithms are one of the simplest and most useful building blocks for constructing parallel algorithms. A generic implementation is valuable because of the wide range of applications for this method. This thesis presents a generic C++ implementation of parallel prefix sums. The implementation applies two separate parallel prefix sums algorithms: a recursive doubling (RD) algorithm and a binary-tree based (BT) algorithm. This implementation shows how common communication patterns can be sepa- rated from the concrete parallel prefix sums algorithms and thus simplify the work of parallel programming. For each algorithm, the implementation uses two different synchronization options: barrier synchronization and point-to-point synchronization. These synchronization options lead to different communication patterns in the algo- rithms, which are represented by dependency graphs between tasks. -
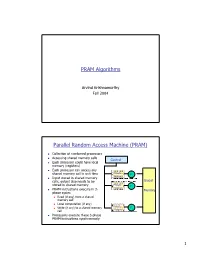
PRAM Algorithms Parallel Random Access Machine
PRAM Algorithms Arvind Krishnamurthy Fall 2004 Parallel Random Access Machine (PRAM) n Collection of numbered processors n Accessing shared memory cells Control n Each processor could have local memory (registers) n Each processor can access any shared memory cell in unit time Private P Memory 1 n Input stored in shared memory cells, output also needs to be Global stored in shared memory Private P Memory 2 n PRAM instructions execute in 3- Memory phase cycles n Read (if any) from a shared memory cell n Local computation (if any) Private n Write (if any) to a shared memory P Memory p cell n Processors execute these 3-phase PRAM instructions synchronously 1 Shared Memory Access Conflicts n Different variations: n Exclusive Read Exclusive Write (EREW) PRAM: no two processors are allowed to read or write the same shared memory cell simultaneously n Concurrent Read Exclusive Write (CREW): simultaneous read allowed, but only one processor can write n Concurrent Read Concurrent Write (CRCW) n Concurrent writes: n Priority CRCW: processors assigned fixed distinct priorities, highest priority wins n Arbitrary CRCW: one randomly chosen write wins n Common CRCW: all processors are allowed to complete write if and only if all the values to be written are equal A Basic PRAM Algorithm n Let there be “n” processors and “2n” inputs n PRAM model: EREW n Construct a tournament where values are compared P0 Processor k is active in step j v if (k % 2j) == 0 At each step: P0 P4 Compare two inputs, Take max of inputs, P0 P2 P4 P6 Write result into shared memory -

Parallel Prefix Sum on the GPU (Scan)
Parallel Prefix Sum on the GPU (Scan) Presented by Adam O’Donovan Slides adapted from the online course slides for ME964 at Wisconsin taught by Prof. Dan Negrut and from slides Presented by David Luebke Parallel Prefix Sum (Scan) Definition: The all-prefix-sums operation takes a binary associative operator ⊕ with identity I, and an array of n elements a a a [ 0, 1, …, n-1] and returns the ordered set I a a ⊕ a a ⊕ a ⊕ ⊕ a [ , 0, ( 0 1), …, ( 0 1 … n-2)] . Example: Exclusive scan: last input if ⊕ is addition, then scan on the set element is not included in [3 1 7 0 4 1 6 3] the result returns the set [0 3 4 11 11 15 16 22] (From Blelloch, 1990, “Prefix 2 Sums and Their Applications) Applications of Scan Scan is a simple and useful parallel building block Convert recurrences from sequential … for(j=1;j<n;j++) out[j] = out[j-1] + f(j); … into parallel : forall(j) in parallel temp[j] = f(j); scan(out, temp); Useful in implementation of several parallel algorithms: radix sort Polynomial evaluation quicksort Solving recurrences String comparison Tree operations Lexical analysis Histograms Stream compaction Etc. HK-UIUC 3 Scan on the CPU void scan( float* scanned, float* input, int length) { scanned[0] = 0; for(int i = 1; i < length; ++i) { scanned[i] = scanned[i-1] + input[i-1]; } } Just add each element to the sum of the elements before it Trivial, but sequential Exactly n-1 adds: optimal in terms of work efficiency 4 Parallel Scan Algorithm: Solution One Hillis & Steele (1986) Note that a implementation of the algorithm shown in picture requires two buffers of length n (shown is the case n=8=2 3) Assumption: the number n of elements is a power of 2: n=2 M Picture courtesy of Mark Harris 5 The Plain English Perspective First iteration, I go with stride 1=2 0 Start at x[2 M] and apply this stride to all the array elements before x[2 M] to find the mate of each of them.