Principles of Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pattern Matching
Functional Programming Steven Lau March 2015 before function programming... https://www.youtube.com/watch?v=92WHN-pAFCs Models of computation ● Turing machine ○ invented by Alan Turing in 1936 ● Lambda calculus ○ invented by Alonzo Church in 1930 ● more... Turing machine ● A machine operates on an infinite tape (memory) and execute a program stored ● It may ○ read a symbol ○ write a symbol ○ move to the left cell ○ move to the right cell ○ change the machine’s state ○ halt Turing machine Have some fun http://www.google.com/logos/2012/turing-doodle-static.html http://www.ioi2012.org/wp-content/uploads/2011/12/Odometer.pdf http://wcipeg.com/problems/desc/ioi1211 Turing machine incrementer state symbol action next_state _____ state 0 __1__ state 1 0 _ or 0 write 1 1 _10__ state 2 __1__ state 1 0 1 write 0 2 _10__ state 0 __1__ state 0 _00__ state 2 1 _ left 0 __0__ state 2 _00__ state 0 __0__ state 0 1 0 or 1 right 1 100__ state 1 _10__ state 1 2 0 left 0 100__ state 1 _10__ state 1 100__ state 1 _10__ state 1 100__ state 1 _10__ state 0 100__ state 0 _11__ state 1 101__ state 1 _11__ state 1 101__ state 1 _11__ state 0 101__ state 0 λ-calculus Beware! ● think mathematical, not C++/Pascal ● (parentheses) are for grouping ● variables cannot be mutated ○ x = 1 OK ○ x = 2 NO ○ x = x + 1 NO λ-calculus Simplification 1 of 2: ● Only anonymous functions are used ○ f(x) = x2+1 f(1) = 12+1 = 2 is written as ○ (λx.x2+1)(1) = 12+1 = 2 note that f = λx.x2+1 λ-calculus Simplification 2 of 2: ● Only unary functions are used ○ a binary function can be written as a unary function that return another unary function ○ (λ(x,y).x+y)(1,2) = 1+2 = 3 is written as [(λx.(λy.x+y))(1)](2) = [(λy.1+y)](2) = 1+2 = 3 ○ this technique is known as Currying Haskell Curry λ-calculus ● A lambda term has 3 forms: ○ x ○ λx.A ○ AB where x is a variable, A and B are lambda terms. -

Functional SMT Solving: a New Interface for Programmers
Functional SMT solving: A new interface for programmers A thesis submitted in Partial Fulfillment of the Requirements for the Degree of Master of Technology by Siddharth Agarwal to the DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY KANPUR June, 2012 v ABSTRACT Name of student: Siddharth Agarwal Roll no: Y7027429 Degree for which submitted: Master of Technology Department: Computer Science & Engineering Thesis title: Functional SMT solving: A new interface for programmers Name of Thesis Supervisor: Prof Amey Karkare Month and year of thesis submission: June, 2012 Satisfiability Modulo Theories (SMT) solvers are powerful tools that can quickly solve complex constraints involving booleans, integers, first-order logic predicates, lists, and other data types. They have a vast number of potential applications, from constraint solving to program analysis and verification. However, they are so complex to use that their power is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the Z3 solver into a host language, Racket. Our system defines a programmer’s interface in Racket that makes it easy to harness the power of Z3 to discover solutions to logical constraints. The interface, although in Racket, retains the structure and brevity of the SMT-LIB format. We demonstrate this using a range of examples, from simple constraint solving to verifying recursive functions, all in a few lines of code. To my grandfather Acknowledgements This project would have never have even been started had it not been for my thesis advisor Dr Amey Karkare’s help and guidance. Right from the time we were looking for ideas to when we finally had a concrete proposal in hand, his support has been invaluable. -

Lambda Calculus and Functional Programming
Global Journal of Researches in Engineering Vol. 10 Issue 2 (Ver 1.0) June 2010 P a g e | 47 Lambda Calculus and Functional Programming Anahid Bassiri1Mohammad Reza. Malek2 GJRE Classification (FOR) 080299, 010199, 010203, Pouria Amirian3 010109 Abstract-The lambda calculus can be thought of as an idealized, Basis concept of a Turing machine is the present day Von minimalistic programming language. It is capable of expressing Neumann computers. Conceptually these are Turing any algorithm, and it is this fact that makes the model of machines with random access registers. Imperative functional programming an important one. This paper is programming languages such as FORTRAN, Pascal etcetera focused on introducing lambda calculus and its application. As as well as all the assembler languages are based on the way an application dikjestra algorithm is implemented using a Turing machine is instructed by a sequence of statements. lambda calculus. As program shows algorithm is more understandable using lambda calculus in comparison with In addition functional programming languages, like other imperative languages. Miranda, ML etcetera, are based on the lambda calculus. Functional programming is a programming paradigm that I. INTRODUCTION treats computation as the evaluation of mathematical ambda calculus (λ-calculus) is a useful device to make functions and avoids state and mutable data. It emphasizes L the theories realizable. Lambda calculus, introduced by the application of functions, in contrast with the imperative Alonzo Church and Stephen Cole Kleene in the 1930s is a programming style that emphasizes changes in state. formal system designed to investigate function definition, Lambda calculus provides a theoretical framework for function application and recursion in mathematical logic and describing functions and their evaluation. -

Feature-Specific Profiling
Feature-Specific Profiling LEIF ANDERSEN, PLT @ Northeastern University, United States of America VINCENT ST-AMOUR, PLT @ Northwestern University, United States of America JAN VITEK, Northeastern University and Czech Technical University MATTHIAS FELLEISEN, PLT @ Northeastern University, United States of America While high-level languages come with significant readability and maintainability benefits, their performance remains difficult to predict. For example, programmers may unknowingly use language features inappropriately, which cause their programs to run slower than expected. To address this issue, we introduce feature-specific profiling, a technique that reports performance costs in terms of linguistic constructs. Festure-specific profilers help programmers find expensive uses of specific features of their language. We describe the architecture ofa profiler that implements our approach, explain prototypes of the profiler for two languages withdifferent characteristics and implementation strategies, and provide empirical evidence for the approach’s general usefulness as a performance debugging tool. ACM Reference Format: Leif Andersen, Vincent St-Amour, Jan Vitek, and Matthias Felleisen. 2018. Feature-Specific Profiling. 1,1 (September 2018), 35 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn 1 PROFILING WITH ACTIONABLE ADVICE When programs take too long to run, programmers tend to reach for profilers to diagnose the problem. Most profilers attribute the run-time costs during a program’s execution to cost centers such as function calls or statements in source code. Then they rank all of a program’s cost centers in order to identify and eliminate key bottlenecks (Amdahl 1967). If such a profile helps programmers optimize their code, we call it actionable because it points to inefficiencies that can be remedied with changes to the program. -

Purity in Erlang
Purity in Erlang Mihalis Pitidis1 and Konstantinos Sagonas1,2 1 School of Electrical and Computer Engineering, National Technical University of Athens, Greece 2 Department of Information Technology, Uppsala University, Sweden [email protected], [email protected] Abstract. Motivated by a concrete goal, namely to extend Erlang with the abil- ity to employ user-defined guards, we developed a parameterized static analysis tool called PURITY, that classifies functions as referentially transparent (i.e., side- effect free with no dependency on the execution environment and never raising an exception), side-effect free with no dependencies but possibly raising excep- tions, or side-effect free but with possible dependencies and possibly raising ex- ceptions. We have applied PURITY on a large corpus of Erlang code bases and report experimental results showing the percentage of functions that the analysis definitely classifies in each category. Moreover, we discuss how our analysis has been incorporated on a development branch of the Erlang/OTP compiler in order to allow extending the language with user-defined guards. 1 Introduction Purity plays an important role in functional programming languages as it is a corner- stone of referential transparency, namely that the same language expression produces the same value when evaluated twice. Referential transparency helps in writing easy to test, robust and comprehensible code, makes equational reasoning possible, and aids program analysis and optimisation. In pure functional languages like Clean or Haskell, any side-effect or dependency on the state is captured by the type system and is reflected in the types of functions. In a language like ERLANG, which has been developed pri- marily with concurrency in mind, pure functions are not the norm and impure functions can freely be used interchangeably with pure ones. -

Revised5report on the Algorithmic Language Scheme
Revised5 Report on the Algorithmic Language Scheme RICHARD KELSEY, WILLIAM CLINGER, AND JONATHAN REES (Editors) H. ABELSON R. K. DYBVIG C. T. HAYNES G. J. ROZAS N. I. ADAMS IV D. P. FRIEDMAN E. KOHLBECKER G. L. STEELE JR. D. H. BARTLEY R. HALSTEAD D. OXLEY G. J. SUSSMAN G. BROOKS C. HANSON K. M. PITMAN M. WAND Dedicated to the Memory of Robert Hieb 20 February 1998 CONTENTS Introduction . 2 SUMMARY 1 Overview of Scheme . 3 1.1 Semantics . 3 The report gives a defining description of the program- 1.2 Syntax . 3 ming language Scheme. Scheme is a statically scoped and 1.3 Notation and terminology . 3 properly tail-recursive dialect of the Lisp programming 2 Lexical conventions . 5 language invented by Guy Lewis Steele Jr. and Gerald 2.1 Identifiers . 5 Jay Sussman. It was designed to have an exceptionally 2.2 Whitespace and comments . 5 clear and simple semantics and few different ways to form 2.3 Other notations . 5 expressions. A wide variety of programming paradigms, in- 3 Basic concepts . 6 3.1 Variables, syntactic keywords, and regions . 6 cluding imperative, functional, and message passing styles, 3.2 Disjointness of types . 6 find convenient expression in Scheme. 3.3 External representations . 6 The introduction offers a brief history of the language and 3.4 Storage model . 7 of the report. 3.5 Proper tail recursion . 7 4 Expressions . 8 The first three chapters present the fundamental ideas of 4.1 Primitive expression types . 8 the language and describe the notational conventions used 4.2 Derived expression types . -

Meta-Tracing Makes a Fast Racket
Meta-tracing makes a fast Racket Carl Friedrich Bolz Tobias Pape Jeremy Siek Software Development Team Hasso-Plattner-Institut Indiana University King’s College London Potsdam [email protected] [email protected] [email protected] potsdam.de Sam Tobin-Hochstadt Indiana University [email protected] ABSTRACT 1. INTRODUCTION Tracing just-in-time (JIT) compilers record and optimize the instruc- Just-in-time (JIT) compilation has been applied to a wide variety tion sequences they observe at runtime. With some modifications, languages, with early examples including Lisp, APL, Basic, Fortran, a tracing JIT can perform well even when the executed program is Smalltalk, and Self [Aycock, 2003]. These days, JIT compilation itself an interpreter, an approach called meta-tracing. The advantage is mainstream; it is responsible for running both server-side Java of meta-tracing is that it separates the concern of JIT compilation applications [Paleczny et al., 2001] and client-side JavaScript appli- from language implementation, enabling the same JIT compiler to cations in web browsers [Hölttä, 2013]. be used with many different languages. The RPython meta-tracing Mitchell [1970] observed that one could obtain an instruction JIT compiler has enabled the efficient interpretation of several dy- sequence from an interpreter by recording its actions. The interpreter namic languages including Python (PyPy), Prolog, and Smalltalk. can then jump to this instruction sequence, this trace, when it returns In this paper we present initial findings in applying the RPython to interpret the same part of the program. For if-then-else statements, JIT to Racket. Racket comes from the Scheme family of program- there is a trace for only one branch. -

Functional SMT Solving with Z3 and Racket
Functional SMT Solving with Z3 and Racket Siddharth Agarwal∗y Amey Karkarey [email protected] [email protected] ∗Facebook Inc, yDepartment of Computer Science & Engineering Menlo Park, CA, USA Indian Institute of Technology Kanpur, India Abstract—Satisfiability Modulo Theories (SMT) solvers are can attack range from simple puzzles like Sudoku and n- powerful tools that can quickly solve complex constraints queens, to planning and scheduling, program analysis [8], involving Booleans, integers, first-order logic predicates, lists, whitebox fuzz testing [9] and bounded model checking [10]. and other data types. They have a vast number of potential Yet SMT solvers are only used by a small number of experts. It applications, from constraint solving to program analysis and isn’t hard to see why: the standard way for programs to interact verification. However, they are so complex to use that their power with SMT solvers like Z3 [4], Yices [5] and CVC3 [11] is via is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the powerful but relatively arcane C APIs that require the users Z3 solver into a host language, Racket. The system defines a to know the particular solver’s internals. For example, here programmer’s interface in Racket that makes it easy to harness is a C program that asks Z3 whether the simple proposition the power of Z3 to discover solutions to logical constraints. The p ^ :p is satisfiable. interface, although in Racket, retains the structure and brevity Z3_config cfg = Z3_mk_config(); of the SMT-LIB format. -

Comparative Studies of 10 Programming Languages Within 10 Diverse Criteria
Department of Computer Science and Software Engineering Comparative Studies of 10 Programming Languages within 10 Diverse Criteria Jiang Li Sleiman Rabah Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] Mingzhi Liu Yuanwei Lai Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] COMP 6411 - A Comparative studies of programming languages 1/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai This page was intentionally left blank COMP 6411 - A Comparative studies of programming languages 2/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai Abstract There are many programming languages in the world today.Each language has their advantage and disavantage. In this paper, we will discuss ten programming languages: C++, C#, Java, Groovy, JavaScript, PHP, Schalar, Scheme, Haskell and AspectJ. We summarize and compare these ten languages on ten different criterion. For example, Default more secure programming practices, Web applications development, OO-based abstraction and etc. At the end, we will give our conclusion that which languages are suitable and which are not for using in some cases. We will also provide evidence and our analysis on why some language are better than other or have advantages over the other on some criterion. 1 Introduction Since there are hundreds of programming languages existing nowadays, it is impossible and inefficient -
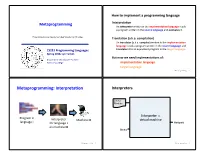
Metaprogramming: Interpretaaon Interpreters
How to implement a programming language Metaprogramming InterpretaAon An interpreter wriDen in the implementaAon language reads a program wriDen in the source language and evaluates it. These slides borrow heavily from Ben Wood’s Fall ‘15 slides. TranslaAon (a.k.a. compilaAon) An translator (a.k.a. compiler) wriDen in the implementaAon language reads a program wriDen in the source language and CS251 Programming Languages translates it to an equivalent program in the target language. Spring 2018, Lyn Turbak But now we need implementaAons of: Department of Computer Science Wellesley College implementaAon language target language Metaprogramming 2 Metaprogramming: InterpretaAon Interpreters Source Program Interpreter = Program in Interpreter Machine M virtual machine language L for language L Output on machine M Data Metaprogramming 3 Metaprogramming 4 Metaprogramming: TranslaAon Compiler C Source x86 Target Program C Compiler Program if (x == 0) { cmp (1000), $0 Program in Program in x = x + 1; bne L language A } add (1000), $1 A to B translator language B ... L: ... x86 Target Program x86 computer Output Interpreter Machine M Thanks to Ben Wood for these for language B Data and following pictures on machine M Metaprogramming 5 Metaprogramming 6 Interpreters vs Compilers Java Compiler Interpreters No work ahead of Lme Source Target Incremental Program Java Compiler Program maybe inefficient if (x == 0) { load 0 Compilers x = x + 1; ifne L } load 0 All work ahead of Lme ... inc See whole program (or more of program) store 0 Time and resources for analysis and opLmizaLon L: ... (compare compiled C to compiled Java) Metaprogramming 7 Metaprogramming 8 Compilers... whose output is interpreted Interpreters.. -

CSE341: Programming Languages Spring 2014 Unit 5 Summary Contents Switching from ML to Racket
CSE341: Programming Languages Spring 2014 Unit 5 Summary Standard Description: This summary covers roughly the same material as class and recitation section. It can help to read about the material in a narrative style and to have the material for an entire unit of the course in a single document, especially when reviewing the material later. Please report errors in these notes, even typos. This summary is not a sufficient substitute for attending class, reading the associated code, etc. Contents Switching from ML to Racket ...................................... 1 Racket vs. Scheme ............................................. 2 Getting Started: Definitions, Functions, Lists (and if) ...................... 2 Syntax and Parentheses .......................................... 5 Dynamic Typing (and cond) ....................................... 6 Local bindings: let, let*, letrec, local define ............................ 7 Top-Level Definitions ............................................ 9 Bindings are Generally Mutable: set! Exists ............................ 9 The Truth about cons ........................................... 11 Cons cells are immutable, but there is mcons ............................. 11 Introduction to Delayed Evaluation and Thunks .......................... 12 Lazy Evaluation with Delay and Force ................................. 13 Streams .................................................... 14 Memoization ................................................. 15 Macros: The Key Points ......................................... -

Lecture Notes on Types for Part II of the Computer Science Tripos
Q Lecture Notes on Types for Part II of the Computer Science Tripos Prof. Andrew M. Pitts University of Cambridge Computer Laboratory c 2012 A. M. Pitts Contents Learning Guide ii 1 Introduction 1 2 ML Polymorphism 7 2.1 AnMLtypesystem............................... 8 2.2 Examplesoftypeinference,byhand . .... 17 2.3 Principaltypeschemes . .. .. .. .. .. .. .. .. 22 2.4 Atypeinferencealgorithm . .. 24 3 Polymorphic Reference Types 31 3.1 Theproblem................................... 31 3.2 Restoringtypesoundness . .. 36 4 Polymorphic Lambda Calculus 39 4.1 Fromtypeschemestopolymorphictypes . .... 39 4.2 ThePLCtypesystem .............................. 42 4.3 PLCtypeinference ............................... 50 4.4 DatatypesinPLC ................................ 52 5 Further Topics 61 5.1 Dependenttypes................................. 61 5.2 Curry-Howardcorrespondence . ... 64 References 70 Exercise Sheet 71 i Learning Guide These notes and slides are designed to accompany eight lectures on type systems for Part II of the Cambridge University Computer Science Tripos. The aim of this course is to show by example how type systems for programming languages can be defined and their properties developed, using techniques that were introduced in the Part IB course on Semantics of Programming Languages. We apply these techniques to a few selected topics centred mainly around the notion of “polymorphism” (or “generics” as it is known in the Java and C# communities). Formal systems and mathematical proof play an important role in this subject—a fact