HPC Infrastructures Workshop #10
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

A Scheduling Policy to Improve 10% of Communication Time in Parallel FFT
A scheduling policy to improve 10% of communication time in parallel FFT Samar A. Aseeri Anando Gopal Chatterjee Mahendra K. Verma David E. Keyes ECRC, KAUST CC, IIT Kanpur Dept. of Physics, IIT Kanpur ECRC, KAUST Thuwal, Saudi Arabia Kanpur, India Kanpur, India Thuwal, Saudi Arabia [email protected] [email protected] [email protected] [email protected] Abstract—The fast Fourier transform (FFT) has applications A. FFT Algorithm in almost every frequency related studies, e.g. in image and signal Forward Fourier transform is given by the following equa- processing, and radio astronomy. It is also used to solve partial differential equations used in fluid flows, density functional tion. 3 theory, many-body theory, and others. Three-dimensional N X (−ikxx) (−iky y) (−ikz z) 3 f^(k) = f(x; y; z)e e e (1) FFT has large time complexity O(N log2 N). Hence, parallel algorithms are made to compute such FFTs. Popular libraries kx;ky ;kz 3 perform slab division or pencil decomposition of N data. None The beauty of this sum is that k ; k ; and k can be summed of the existing libraries have achieved perfect inverse scaling x y z of time with (T −1 ≈ n) cores because FFT requires all-to-all independent of each other. These sums are done at different communication and clusters hitherto do not have physical all- to-all connections. With advances in switches and topologies, we now have Dragonfly topology, which physically connects various units in an all-to-all fashion. -

Bringing the Openbmc for Platform Manage- Ment System in Telco Cloud
Rongqiang Zhang Bringing the OpenBMC for Platform Manage- ment System in Telco Cloud Helsinki Metropolia University of Applied Sciences Master of Engineering Information Technology Master’s Thesis 30 Apr 2019 Abstract Rongqiang Zhang Author(s) Bringing the OpenBMC for Platform Man-agement System in Title Telco Cloud Number of Pages 88 pages + 0 appendices Date 30 Apr 2019 Degree Master of Engineering Degree Programme Information Technology Specialisation option Networking and Services Ville Jääskeläinen, Head of Degree Program Instructor(s) Zinaida Grabovskaia, PhL, Senior Lecturer Antti Koivumäki, Senior Lecturer Ari Helminen, Business Manager The current platform management system in Telco cloud infrastructure is based on closed firmware stack. With the upcoming 5G, this closed firmware stack has created several tech- nology and business problems. The major problems are hardware-software vendor lock-in, long lead time for feature development and bug fixing, and security risks. The objective of this study is to evaluate the possibility to bring an Open Source software stack for platform management system and baseboard management controller in Telco cloud. The study was divided into 3 parts. First part is to analyse the current state and project specification. Second part is to introduce and evaluate the OpenBMC, an open source soft- ware stack for the objective of this study. Third part is Proof of Concept to run OpenBMC on Telco. Keywords BMC, 5G, NFV, Redfish, Security Table of Contents Abstract List of Abbreviations 1 Introduction -

View Annual Report
Fellow Shareholders, Headlined by strong growth in revenue and profitability, we had one of our best years ever in 2015, executing across each of our major focus areas and positioning our company for continued growth into the future. We achieved another year of record revenue, growing by nearly 30 percent compared to 2014. In fact, our revenue in 2015 was more than three times higher than just four years prior — driven by growth in both our addressable market and market share. Over the last five years, we have transformed from a company solely focused on the high-end of the supercomputing market — where we are now the clear market leader — to a company with multiple product lines serving multiple markets. We provide our customers with powerful computing, storage and analytics solutions that give them the tools to advance their businesses in ways never before possible. During 2015, we installed supercomputing and storage solutions at a number of customers around the world. In the U.S., we completed the first phase of the massive new “Trinity” system at Los Alamos National Laboratory. This Cray XC40 supercomputer with Sonexion storage serves as the National Nuclear Security Administration’s flagship supercomputer, supporting all three of the NNSA’s national laboratories. We installed the first petaflop supercomputer in India at the Indian Institute of Science. In Europe, we installed numerous XC and storage solutions, including a significant expansion of the existing XC40 supercomputer at the University of Stuttgart in Germany. This new system nearly doubles their computing capacity and is currently the fastest supercomputer in Germany. -

Server Base Manageability Requirements 1.0 Platform Design Document Non-Confidential
Arm® Server Base Manageability Requirements 1.0 Platform Design Document Non-confidential Copyright © 2020 Arm Limited or its affiliates. All rights reserved. Document number: DEN0069B Server Base Manageability Requirements Server Base Manageability Requirements Copyright © 2020 Arm Limited or its affiliates. All rights reserved. Release inormation The Change History table lists the changes made to this document. Table 1-1 Change history Date Issue Confidentiality Change 30 January 2020 A Non-Confidential Initial release, SBMR 1.0 15 June 2020 B Non-Confidential License LES-PRE-21585 Page 2 of 45 Copyright © 2020 Arm Limited or its affiliates. All rights reserved. DEN0069B 1.0 Server Base Manageability Requirements Arm Non-Confidential Document Licence (“Licence”) This Licence is a legal agreement between you and Arm Limited (“Arm”) for the use of the document accompanying this Licence (“Document”). Arm is only willing to license the Document to you on condition that you agree to the terms of this Licence. By using or copying the Document you indicate that you agree to be bound by the terms of this Licence. If you do not agree to the terms of this Licence, Arm is unwilling to license this Document to you and you may not use or copy the Document. “Subsidiary” means any company the majority of whose voting shares is now or hereafter owner or controlled, directly or indirectly, by you. A company shall be a Subsidiary only for the period during which such control exists. This Document is NON-CONFIDENTIAL and any use by you and your Subsidiaries (“Licensee”) is subject to the terms of this Licence between you and Arm. -
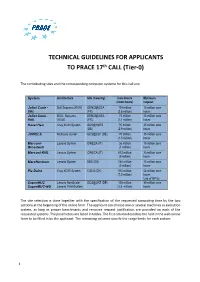
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

OCP's Rack Manager Controller Subproject (Openrmc)
OSF-OpenRMC OCP's Rack Manager Controller subproject (OpenRMC) John Leung, Principle Engineer Intel Corporation Han Wang, Senior Architect Inspur OpenRMC Overview OpenRMC OPENRMC • Goals and Motivation • Logistics and meetings Specifications Status • Reviewed of existing rack management implementations Embedded • Specifying interface and requirements Software • Received Code Contributions RMC for openEdge Platform to DC The OpenRMC Goals manager Specify the Rack Manager Controller service RMC Client interfaces • Northbound interface to datacenter manager (spec) Redfish • Southbound interface requirements to OCP Northbound Interface platforms in the rack Rack Manager Controller Deliver a Rack Manager implementation Service • Available as open source Southbound Interface OCP compliant hardware designs I2C IPMI Redfish • Handled by other OCP projects to OCP platforms Motivation for OpenRMC RMC Rack Mgr Service Controller 1. System Firmware (BIOS) 3 In-band • OCP System Firmware project SW OS 2. BMC Firmware Agent Out-of-band • OpenBMC governed by Linux Foundation (Redfish) 3. Rack Manager Software/Firmware BIOS CPU NIC 1 • OCP OpenRMC NC-SI BMC FW BMC 2 • With OpenBMC, the industry unified the various repositories in 2018 device other • With rack manager, OCP will provide a device source repository and prevent splintering Server The RMC can be hosted in various locations OpenRACK EIA, OpenRACK Olympus (within power shelf) (within switch) (standalone) Switch RMC FW Switch w/ RMC FW Switch Power Shelf w/ RMC FW Server Server Server Server -

Openbmc Overview
Andrew Geissler [email protected] What is a BMC? ▶ BMC – Baseboard Management Controller ▶ Separate uproc (eg. AST 2500) with dedicated RAM and Flash ▶ Provides ▶ System Power/thermal control ▶ Out of Band management ▶ IPMI, REST, etc ▶ Data collection ▶ Debug ▶ GUI and Command line ▶ Interfaces to Host/OCC ▶ System error logging ▶ Based on OpenEmbedded technologies built via Yocto ▶ Embedded Linux stack ▶ Linux Kernel 4.10….4.18, Yocto 2.3…2.6, python, SSH ▶ Applications communicate via D-Bus ▶ Users communicate via REST, IPMI and GUI ▶ Reports externally to management entity ▶ No customer network functional interaction What is the OpenBMC Project Free open source software management Linux distribution designed for the embedded environment … OpenPOWER Eco-system Enablement Industry Collaboration Quality Solutions Reduce Redundant Effort Openness -- provides proof of security Part of Linux Foundation What is OpenBMC ▶ 100% compatible with OpenPOWER Hostboot/Opal/OCC ▶ Aka BIOS ▶ https://github.com/open-power/op-build ▶ Can simply be a reference implementation ▶ Currently runs on… ▶ Barreleye, S822LC, S822LC For HPC, P8 Reference ▶ Witherspoon -- P9 AC922LC Power AI and CORAL ▶ P9 reference boards ▶ AST2400 and AST2500 BMC hardware Core Infrastructure of the OpenBMC Project Control the Functions in your OpenBMC… ▶ Built on Yocto-Linux ▶ YAML/XML input for system configuration Infrastructure at the ready ▶ Process management Systemd ▶ IPC via D-Bus ▶ External Interfaces via REST, IPMI, GUI ▶ Journaling for Trace/debug ▶ Code update ▶ Code -

Openbmc Update
OpenBMC Update Gunnar Mills IBM OpenBMC Overview OpenBMC Today Release Content Agenda Redfish on OpenBMC Community Forums Get Involved • Open Source Baseboard Management Controller (BMC) firmware • Linux Foundation Project • Companies with layers include: Arm, Aspeed, Facebook, Google, OpenBMC IBM, Intel, Inspur, Lenovo, Mellanox, Microsoft, Nuvoton, Qualcomm, Yado • Underlying technologies • Yocto Project • D-Bus • Systemd • 2014 - Out of a Facebook hackathon an open BMC firmware stack named OpenBMC History • 2015 - IBM collaborates with Rackspace on an open BMC firmware stack also named OpenBMC • These projects were similar in name and concept only • March 2018 - OpenBMC becomes a Linux Foundation Project converging • Technical steering committee formed to guide the project • Agreed upon path to a unified OpenBMC community Project Charter and Linux Foundation • Lightweight, flexible charter (five pages) • Apache 2.0 license for code contributions (with clause for exceptions) • CC BY 4.0 license for documentation • Requires execution of corporate or individual contributor license agreement to contribute • https://www.openbmc.org/wp- content/uploads/sites/62/2018/03/charter_op enbmc_02142018.pdf • Linux Foundation owns project trademarks, DNS registrant, and GitHub organization owner • Members • Brad Bishop (IBM) • Sai Dasari (Facebook) • Sagar Dharia (Microsoft) • James Mihm (Intel) Technical Steering • Supreeth Venkatesh (Arm) Committee • Nancy Yuen (Google) • Community contributions drive project direction • Provide resolution at last -

Cray XC40 Power Monitoring and Control for Knights Landing
Cray XC40 Power Monitoring and Control for Knights Landing Steven J. Martin, David Rush Matthew Kappel, Michael Sandstedt, Joshua Williams Cray Inc. Cray Inc. Chippewa Falls, WI USA St. Paul, MN USA {stevem,rushd}@cray.com {mkappel,msandste,jw}@cray.com Abstract—This paper details the Cray XC40 power monitor- This paper is organized as follows: In section II, we ing and control capabilities for Intel Knights Landing (KNL) detail blade-level Hardware Supervisory System (HSS) ar- based systems. The Cray XC40 hardware blade design for Intel chitecture changes introduced to enable improved telemetry KNL processors is the first in the XC family to incorporate enhancements directly related to power monitoring feedback gathering capabilities on Cray XC40 blades with Intel KNL driven by customers and the HPC community. This paper fo- processors. Section III provides information on updates to cuses on power monitoring and control directly related to Cray interfaces available for power monitoring and control that blades with Intel KNL processors and the interfaces available are new for Cray XC40 systems and the software released to users, system administrators, and workload managers to to support blades with Intel KNL processors. Section IV access power management features. shows monitoring and control examples. Keywords-Power monitoring; power capping; RAPL; energy efficiency; power measurement; Cray XC40; Intel Knights II. ENHANCED HSS BLADE-LEVEL MONITORING Landing The XC40 KNL blade incorporates a number of en- hancements over previous XC blade types that enable the I. INTRODUCTION collection of power telemetry in greater detail and with Cray has provided advanced power monitoring and control improved accuracy. -

Hpc in Europe
HPC IN EUROPE Organisation of public HPC resources Context • Focus on publicly-funded HPC resources provided primarily to enable scientific research and development at European universities and other publicly-funded research institutes • These resources are also intended to benefit industrial / commercial users by: • facilitating access to HPC • providing HPC training • sponsoring academic-industrial collaborative projects to exchange expertise and accelerate efficient commercial exploitation of HPC • Do not consider private sector HPC resources owned and managed internally by companies, e.g. in aerospace design & manufacturing, oil & gas exploration, fintech (financial technology), etc. European HPC Infrastructure • Structured provision of European HPC facilities: • Tier-0: European Centres (> petaflop machines) • Tier-1: National Centres • Tier-2: Regional/University Centres • Tiers planned as part of an EU Research Infrastructure Roadmap • This is coordinated through “PRACE” – http://prace-ri.eu PRACE Partnership foR Advanced Computing in Europe • International non-profit association (HQ office in Brussels) • Established in 2010 following ESFRI* roadmap to create a persistent pan-European Research Infrastructure (RI) of world-class supercomputers • Mission: enable high-impact scientific discovery and engineering research and development across all disciplines to enhance European competitiveness for the benefit of society. *European Strategy Forum on Reseach Infrastructures PRACE Partnership foR Advanced Computing in Europe Aims: • Provide access to leading-edge computing and data management resources and services for large-scale scientific and engineering applications at the highest performance level • Provide pan-European HPC education and training • Strengthen the European users of HPC in industry A Brief History of PRACE PRACE Phases & Objectives • Preparation and implementation of the PRACE RI was supported by a series of projects funded by the EU’s FP7 and Horizon 2020 funding programmes • 530 M€ of funding for the period 2010-2015. -

Flatbed Design Specification DRAFT Revision 0.07 Author: Scott Mccauley ([email protected]) Author: Nate Klein (Nxk@G
Flatbed Design Specification DRAFT Revision 0.07 Author: Scott McCauley ([email protected]) Author: Nate Klein ([email protected]) Author: Bill Barry ([email protected]) Open Compute Project Flatbed Design Specification DRAFT • 1. License Contributions to this Specification are made under the terms and conditions set forth in Open Web Foundation Contributor License Agreement (“OWF CLA 1.0”) by: Google, Inc. You can review the signed copies of the applicable Contributor License(s) for this Specification on the OCP website at http://www.opencompute.org/products/specsanddesign Usage of this Specification is governed by the terms and conditions set forth in Open Web Foundation Final Specification Agreement (“OWFa 1.0”). You can review the applicable Specification License(s) executed by the above referenced contributors to this Specification on the OCP website at http://www.opencompute.org/participate/legal-documents/ Note: The following clarifications, which distinguish technology licensed in the Contribution License and/or Specification License from those technologies merely referenced (but not licensed), were accepted by the Incubation Committee of the OCP: CONTRIBUTORS AND LICENSORS OF THIS SPECIFICATION MAY HAVE MENTIONED CERTAIN TECHNOLOGIES THAT ARE MERELY REFERENCED WITHIN THIS SPECIFICATION AND NOT LICENSED UNDER THE OWF CLA OR OWFa. THE FOLLOWING IS A LIST OF MERELY REFERENCED TECHNOLOGY: INTELLIGENT PLATFORM MANAGEMENT INTERFACE (IPMI) I2C TRADEMARK OF PHILLIPS SEMICONDUCTOR. SMBus OpenBMC REST API NC-SI ATX EPS12V MAX31790 (Maxim IC) TM4C129 (Texas Instruments) ISO1540 (Texas Instruments) PCA9548 (Texas Instruments, Phillips Semiconductor) TCA9555 (Texas Instruments, Phillips Semiconductor) LTC4316 (Linear Technology) ADUM1250 (Analog Devices) 24C04 EEPROM Molex Minifit Molex Microfit Tyco Connectivity 5499910-1 Molex 90130-1210 Samtec HW-TH series IMPLEMENTATION OF THESE TECHNOLOGIES MAY BE SUBJECT TO THEIR OWN LEGAL TERMS.