Simplifying Server Configuration Management Björn Tackmann
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nginx 1 Web Server Implementation Cookbook
Nginx 1 Web Server Implementation Cookbook Over 100 recipes to master using the Nginx HTTP server and reverse proxy Dipankar Sarkar BIRMINGHAM - MUMBAI This material is copyright and is licensed for the sole use by 2135 Lymington on 26th March 2012 2135 Lymington, Carrollton, 75007 Nginx 1 Web Server Implementation Cookbook Copyright © 2011 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: May 2011 Production Reference: 1180511 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849514-96-5 www.packtpub.com Cover Image by Javier Barria ([email protected]) This material is copyright and is licensed for the sole use by 2135 Lymington -

Additional Software 1 Additional Software
Additional Software 1 Additional Software 1 Additional Software 15 Feb 2014 1 1.1 Description 1.1 Description Where to get software written by other parties that might be useful (or necessary) when running mod_perl. 1.2 Perl Perl is probably already installed on your machine, but you should at least check the version you are using. It is highly recommended that you have at least Perl version 5.004. You can get the latest perl version from http://cpan.org/src/. Try the direct download link http://cpan.org/src/stable.tar.gz. You can get Perl documentation from the same location (although copious documentation is included in the downloaded Perl distribution). 1.3 CPAN Downloads You can download most of the Perl modules from CPAN. There are many mirrors of this site. The main site’s URL is http://cpan.org/. You may want to search the Perl modules database by using http://search.cpan.org/. Either use the search form, or type in the name of the package the module is distributed in. For example if you are looking for Apache::DumpHeaders, you can type: http://search.cpan.org/search?dist=Apache-DumpHeaders . 1.4 Apache Get the latest Apache webserver and documentation from http://httpd.apache.org. Try the direct download link http://httpd.apache.org/dist/. 1.5 Squid - Internet Object Cache http://www.squid-cache.org/ Squid Linux 2.x Redhat RPMs : http://home.earthlink.net/~intrep/linux/ 1.6 thttpd - tiny/turbo/throttling HTTP server http://www.acme.com/software/thttpd/ 1.7 mod_proxy_add_forward Ask Bjoern Hansen has written the mod_proxy_add_forward.c module for Apache that sets the X-Forwarded-For field when doing a ProxyPass, similar to what Squid does. -

Server: Apache
Modern Trends in Network Fingerprinting SecTor [11.21.07] Jay Graver Ryan Poppa // Fingerprinting Topics Why, What, Who & How? Tools in action Why Tools Break Tools EOL New Approaches New Tool // Why Fingerprint? WhiteHat needs accurate identification of hosts in a PenTest report BlackHat reconnaissance SysAdmins track down and identify new services or hosts when they appear on their network // What is a Fingerprint? Looking at something common … 192.168.2.187:8004 192.168.2.187 [152] 48 54 54 50 2f 31 2e 31 20 32 30 30 20 4f 4b 0d HTTP/1.1 200 OK. 0a 43 6f 6e 6e 65 63 74 69 6f 6e 3a 20 63 6c 6f .Connection: clo 73 65 0d 0a 41 6c 6c 6f 77 3a 20 4f 50 54 49 4f se..Allow: OPTIO 4e 53 2c 20 47 45 54 2c 20 48 45 41 44 2c 20 50 NS, GET, HEAD, P 4f 53 54 0d 0a 43 6f 6e 74 65 6e 74 2d 4c 65 6e OST..Content‐Len 67 74 68 3a 20 30 0d 0a 44 61 74 65 3a 20 46 72 gth: 0..Date: Fr 69 2c 20 30 32 20 4e 6f 76 20 32 30 30 37 20 32 i, 02 Nov 2007 2 32 3a 32 35 3a 31 38 20 47 4d 54 0d 0a 53 65 72 2:25:18 GMT..Ser 76 65 72 3a 20 6c 69 67 68 74 74 70 64 2f 31 2e ver: lighttpd/1. 34 2e 31 35 0d 0a 0d 0a 4.15... -

Next Generation Web Scanning Presentation
Next generation web scanning New Zealand: A case study First presented at KIWICON III 2009 By Andrew Horton aka urbanadventurer NZ Web Recon Goal: To scan all of New Zealand's web-space to see what's there. Requirements: – Targets – Scanning – Analysis Sounds easy, right? urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets What does 'NZ web-space' mean? It could mean: •Geographically within NZ regardless of the TLD •The .nz TLD hosted anywhere •All of the above For this scan it means, IPs geographically within NZ urbanadventurer (Andrew Horton) www.morningstarsecurity.com Finding Targets We need creative methods to find targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com DNS Zone Transfer urbanadventurer (Andrew Horton) www.morningstarsecurity.com Find IP addresses on IRC and by resolving lots of NZ websites 58.*.*.* 60.*.*.* 65.*.*.* 91.*.*.* 110.*.*.* 111.*.*.* 113.*.*.* 114.*.*.* 115.*.*.* 116.*.*.* 117.*.*.* 118.*.*.* 119.*.*.* 120.*.*.* 121.*.*.* 122.*.*.* 123.*.*.* 124.*.*.* 125.*.*.* 130.*.*.* 131.*.*.* 132.*.*.* 138.*.*.* 139.*.*.* 143.*.*.* 144.*.*.* 146.*.*.* 150.*.*.* 153.*.*.* 156.*.*.* 161.*.*.* 162.*.*.* 163.*.*.* 165.*.*.* 166.*.*.* 167.*.*.* 192.*.*.* 198.*.*.* 202.*.*.* 203.*.*.* 210.*.*.* 218.*.*.* 219.*.*.* 222.*.*.* 729,580,500 IPs. More than we want to try. urbanadventurer (Andrew Horton) www.morningstarsecurity.com IP address blocks in the IANA IPv4 Address Space Registry Prefix Designation Date Whois Status [1] ----- -

Webserver WEBSER Shell-Zugriff Via Webbrowser Debian 6.0 S
COMMUNITY-EDITION Frei kopieren und beliebig weiter verteilen ! 04.2011 04.2011 APACHE-ALTERNATIVEN: WEBSITES AUFSETZEN UND PFLEGEN VER WEBSERVER WEBSER Shell-Zugriff via Webbrowser Debian 6.0 S. 6 Live- und Install-DVDs So verwalten Sie mit PHP Shell und Shell in a Box für 32- und 64-Bit-PCs den Webserver über die Kommandozeile S. 33, DVD Analyse-Tools für die Website Server-Logs grafisch aufbereiten und Benutzerzugriffe detailliert auswerten mit Webalizer und Piwik S. 38, 42, DVD Fünf Apache-Alternativen für alle Fälle S. 20, 28, DVD Profi-Server Nginx, hochsicherer Hiawatha, Allrounder Lighttpd, Minimalist Thttpd, schneller Einstieg mit Monkey HTTP Daemon MoonOS 4 S. 12 Schicke Mac-Optik für Ubuntu „Maverick“ Laptop-Schnäppchen Aspire 5253 Acers neuer 15,6-Zöller auf AMD-Fusion-Basis mit satter Grafik-Leistung und langer Laufzeit S. 80 Texterkennung in Platzfresser von Profi-Qualität S. 48, DVD der Platte putzen S. 70 Unity 2010.2 S. 8 Cuneiform: multilinguale OCR Dateileichen und Altlasten Maßgeschneiderte mit intuitiver Oberfläche aufspüren mit JDiskReport Distro auf Knopfdruck MythTV-Export Geballtes Wissen auf Knopfdruck S. 66 stets zur Hand S. 82, DVD Aufnahmen unkompliziert Goldendict vereint On- und wandeln, streamen, brennen Offline-Lexika in einer GUI ATI FIREPRO 3D • GOLDENDICT LOUT LUCIDOR MYTHTV OCR ATI 4 196067 008502 04 www.linux-user.de EDITORIAL Klare Ansage Sehr geehrte Leserinnen und Leser, im Vorfeld von Ubuntu 11.04 Wohlgemerkt: Die MIT-Lizenz des statt Lizenzgebühren zu verlan- sorgte Canonical immer wieder für Banshee-Projekts hätte jegliche gen. Diesem Geschäftsmodell fol- Schlagzeilen – zuletzt im Zusam- Änderungen auch ganz ohne Nach- gend, werde man grundsätzlich wo menhang mit der Ablösung des frage erlaubt, formaljuristisch war immer möglich aus der Software bisherigen Mediaplayers Rhythm- Canonicals Ansinnen völlig in der freien Upstream-Projekte Ge- box durch Banshee: Der nämlich Ordnung. -
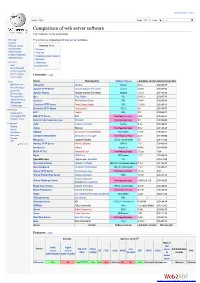
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Frankencode: Creating Diverse Programs Using Code Clones
Frankencode: Creating Diverse Programs Using Code Clones Hayley Borck, Mark Boddy, Ian J De Silva, Steven Harp, Ken Hoyme, Steven Johnston, August Schwerdfeger, and Mary Southern Adventium Labs, Minneapolis, MN 55401 Email: fi[email protected] Abstract enable not just new attacks, but new kinds of attacks. Apparently-minor vulnerabilities can be chained to- In this paper, we present an approach to detecting gether in successful attacks, even on software that is novel cyber attacks though a form of program diversifi- extensively tested and generally viewed as secure.1 cation, similar to the use of n-version programming for In this paper, we describe our research on the Func- fault tolerant systems. Building on extensive previous tionally Equivalent Variants using Information Syn- and ongoing work by others on the use of code clones chronization (FEVIS) system. Part of the Cyber Fault- in a wide variety of areas, our Functionally Equivalent tolerant Attack Recovery (CFAR) program, funded by Variants using Information Synchronization (FEVIS) the U.S. Government’s Defense Advanced Research system automatically generates program variants to be Projects Agency (DARPA), FEVIS builds on previ- run in parallel, seeking to detect attacks through diver- ous and ongoing work on “code clones,” substituting gence in behavior. Unlike approaches to diversification redundant code fragments as a means to generate that only change program memory layout and behavior, program variants automatically. These variants are in- FEVIS can detect attacks exploiting vulnerabilities in tended for use in a multi-variant execution environ- execution timing, string processing, and other logic ment, to be used for attack detection and resistance in errors. -

Ipv6 in Freebsd.Pdf
The FreeBSD Project http://www.freebsd.org/ 1/28 IPv6 in FreeBSD Joseph Koshy [email protected] i ? P Structure of this talk What is FreeBSD? 2/28 • The FreeBSD development model • The KAME project • IPv6 support in FreeBSD • Configuring IPv6 in FreeBSD • Available IPv6 capable application software. • Tracking IPv6 development under FreeBSD • Conformance and performance • A look at IPv6 in operation; demos • Conclusion • i ? P What is FreeBSD? http://www.freebsd.org/ 3/28 A high-performance, volunteer developed, open source, protected mode operating • system. University of California, Berkeley heritage (BSD4.4-Lite). BSD License. • Released for Intel (x86) PCs, laptops and Alpha workstations. • Most recent stable release: FreeBSD v4.2 • Linux, SVR4 (Solaris), SCO application compatibility. • A large number of ported applications (over 4000). • used in very high load scenarios (YAHOO,HOTMAIL, . ); excellent as a worksta- • tion OS. Possesses an excellent IPv6 stack. i ? • P The BSD License very open to commercial use 4/28 • unlike the GPL, there is no requirement that you have to release your modified • sources to the public only requires you to acknowledge authorship of the code • no warranties on the code • many companies are using the FreeBSD code base in their products • e.g. the Interjet from Whistle Inc. (an internet appliance), many router products . i ? P The FreeBSD Organization 5/28 USER COMMUNITY COMMITTERS CORE FreeBSD.ORG FreeBSD is developed and managed by its users. • 3-level organization: • – Over 75% of changes to the source tree originate from the FreeBSD user com- munity. – COMMITTERS are individuals who have the rights to change the source tree. -

Security Assessment INTERNAL NETWORK VULNERABILITIES SUMMARY REPORT
Security Assessment INTERNAL NETWORK VULNERABILITIES SUMMARY REPORT CONFIDENTIALITY NOTE: The information contained in this report is for the exclusive use of the client specified above and may contain Prepared for: Your Customer / confidential, privileged, and non-disclosable information. If you are Prospect not the client or addressee, you are strictly prohibited from reading, photocopying, distributing, or otherwise using this report or its Prepared by: Your Company Name contents in any way. 23-Feb-2021 Scan Date: 12-Feb-2021 Your Company Name Prepared for: MSP WEBSITE URL Your Customer / Prospect MSP PHONE Scan Date: MSP EMAIL 12-Feb-2021 Internal Network Vulnerabilities Summary The Management Plan ranks individual issues based upon their potential risk to the network while providing guidance on which issues to address by priority. Fixing issues with lower Risk Scores will not lower the global Risk Score, but will reduce the global Issue Score. To mitigate global risk and improve the health of the network, address issues with higher Risk Scores first. Appliances Used: 1. NDA1-5488JF 2. NDA1-7584JY 3. NDA1-9644PG High Risk CVSS RECOMMENDATION 10 Trojan horses Summary An unknown service runs on this port. It is sometimes opened by Trojan horses. Unless you know for sure what is behind it, you'd better check your system. Solution If a trojan horse is running, run a good antivirus scanner. Affected Nodes 10.200.1.16(myco-bdr)1 10 IPMI Cipher Zero Authentication Bypass Vulnerability Summary Intelligent Platform Management Interface is prone to an authentication- bypass vulnerability. Solution Ask the Vendor for an update. -

Kqueue: a Generic and Scalable Event Notification Facility
Kqueue: A generic and scalable event notification facility Jonathan Lemon [email protected] FreeBSD Project Abstract delivered to the application, when a file in the filesystem changes in some fashion, or when a process exits. None Applications running on a UNIX platform need to be no- of these are handled efficiently at the moment; signal de- tified when some activity occurs on a socket or other de- livery is limited and expensive, and the other events listed scriptor, and this is traditionally done with the select() or require an inefficient polling model. In addition, neither poll() system calls. However, it has been shown that the poll() nor select() can be used to collect these events, performance of these calls does not scale well with an in- leading to increased code complexity due to use of mul- creasing number of descriptors. These interfaces are also tiple notification interfaces. limited in the respect that they are unable to handle other This paper presents a new mechanism that allows the potentially interesting activities that an application might application to register its interest in a specific event, and be interested in, these might include signals, file system then efficiently collect the notification of the event at a changes, and AIO completions. This paper presents a later time. The set of events that this mechanism covers generic event delivery mechanism, which allows an ap- is shown to include not only those described above, but plication to select from a wide range of event sources, may also be extended to unforeseen event sources with and be notified of activity on these sources in a scalable no modification to the API. -

Reference Guide
Systemwalker Service Quality Coordinator Reference Guide Windows/Solaris/Linux J2X1-7662-01ENZ0(01) September 2012 Preface Purpose of this manual This manual explains the different commands and messages used by Systemwalker Service Quality Coordinator. Target audience This manual is intended for users who will use the Systemwalker Service Quality Coordinator Console window. Readers of this manual should also have a general understanding of basic operating system and GUI operations as well as a working knowledge of communications protocols such as TCP/IP and SMTP. Organization of Systemwalker Service Quality Coordinator manuals The Systemwalker Service Quality Coordinator manuals are organized as follows: - Systemwalker Service Quality Coordinator Technical Guide Provides an overview of the functions of Systemwalker Service Quality Coordinator. - Systemwalker Service Quality Coordinator Installation Guide Explains how to install and set up Systemwalker Service Quality Coordinator. - Systemwalker Service Quality Coordinator User's Guide Explains how to use the functions of Systemwalker Service Quality Coordinator. - Systemwalker Service Quality Coordinator User's Guide (Console Edition) Explains how to use those functions related to console windows. - Systemwalker Service Quality Coordinator User's Guide (Dashboard Edition) Explains how to use dashboard function. - Systemwalker Service Quality Coordinator Reference Guide Explains commands, data formats, messages and so on. - Systemwalker Service Quality Coordinator Troubleshooting Guide -

An Introduction to HTTP Fingerprinting Table of Contents
An Introduction to HTTP fingerprinting Saumil Shah [email protected] 30th November, 2003 Table of Contents 1. Abstract 2. Theory of Fingerprinting 3. Banner Grabbing 4. Applications of HTTP Fingerprinting 5. Obfuscating the server banner string 6. Protocol Behaviour 6.1 HTTP Header field ordering 6.2 HTTP DELETE 6.3 Improper HTTP version response 6.3 Improper protocol response 6.5 Summary of test results 6.6 Choosing the right tests 7. Statistical and Fuzzy analysis 7.1 Assumptions 7.2 Terms and Definitions 7.3 Analysis Logic 8. httprint - the advanced HTTP fingerprinting engine 8.1 httprint signatures 8.2 httprint command line and GUI interfaces 8.3 Running httprint 8.4 The significance of confidence ratings 8.5 httprint Reports 8.6 Customising httprint 9. Trying to defeat HTTP Fingerprinting 10. Conclusion 11. References 1. Abstract HTTP Fingerprinting is a relatively new topic of discussion in the context of application security. One of the biggest challenges of maintaining a high level of network security is to have a complete and accurate inventory of networked assets. Web servers and web applications have now become a part of the scope of a network security assessment exercise. In this paper, we present techniques to identify various types of HTTP servers. We shall discuss some of the problems faced in inventorying HTTP servers and how we can overcome them. We shall also introduce and describe a tool, httprint, which is built using the concepts discussed in this paper. 2. Theory of Fingerprinting A fingerprint is defined as: 1. The impression of a fingertip on any surface; also: an ink impression of the lines upon the fingertip taken for the purpose of identification.