NASA Software Safety Guidebook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Standardizing Functional Safety Assessments for Off-The-Shelf Instrumentation and Controls
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Masters Theses Graduate School 5-2016 STANDARDIZING FUNCTIONAL SAFETY ASSESSMENTS FOR OFF-THE-SHELF INSTRUMENTATION AND CONTROLS Andrew Michael Nack University of Tennessee - Knoxville, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_gradthes Part of the Other Computer Engineering Commons, and the Systems Engineering Commons Recommended Citation Nack, Andrew Michael, "STANDARDIZING FUNCTIONAL SAFETY ASSESSMENTS FOR OFF-THE-SHELF INSTRUMENTATION AND CONTROLS. " Master's Thesis, University of Tennessee, 2016. https://trace.tennessee.edu/utk_gradthes/3793 This Thesis is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Masters Theses by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a thesis written by Andrew Michael Nack entitled "STANDARDIZING FUNCTIONAL SAFETY ASSESSMENTS FOR OFF-THE-SHELF INSTRUMENTATION AND CONTROLS." I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Master of Science, with a major in Computer Engineering. Gregory D. Peterson, Major Professor We have read this thesis and recommend its acceptance: Qing C. Cao, Mingzhou Jin Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) STANDARDIZING FUNCTIONAL SAFETY ASSESSMENTS FOR OFF-THE-SHELF INSTRUMENTATION AND CONTROLS A Thesis Presented for the Master of Science Degree The University of Tennessee, Knoxville Andrew Michael Nack May 2016 Copyright © 2016 by Andrew Michael Nack All rights reserved. -

System Safety Engineering: Back to the Future
System Safety Engineering: Back To The Future Nancy G. Leveson Aeronautics and Astronautics Massachusetts Institute of Technology c Copyright by the author June 2002. All rights reserved. Copying without fee is permitted provided that the copies are not made or distributed for direct commercial advantage and provided that credit to the source is given. Abstracting with credit is permitted. i We pretend that technology, our technology, is something of a life force, a will, and a thrust of its own, on which we can blame all, with which we can explain all, and in the end by means of which we can excuse ourselves. — T. Cuyler Young ManinNature DEDICATION: To all the great engineers who taught me system safety engineering, particularly Grady Lee who believed in me, and to C.O. Miller who started us all down this path. Also to Jens Rasmussen, whose pioneering work in Europe on applying systems thinking to engineering for safety, in parallel with the system safety movement in the United States, started a revolution. ACKNOWLEDGEMENT: The research that resulted in this book was partially supported by research grants from the NSF ITR program, the NASA Ames Design For Safety (Engineering for Complex Systems) program, the NASA Human-Centered Computing, and the NASA Langley System Archi- tecture Program (Dave Eckhart). program. Preface I began my adventure in system safety after completing graduate studies in computer science and joining the faculty of a computer science department. In the first week at my new job, I received a call from Marion Moon, a system safety engineer at what was then Ground Systems Division of Hughes Aircraft Company. -

Manuscript Instructions/Template
INCOSE Working Group Addresses System and Software Interfaces Sarah Sheard, Ph.D. Rita Creel CMU Software Engineering Institute CMU Software Engineering Institute (412) 268-7612 (703) 247-1378 [email protected] [email protected] John Cadigan Joseph Marvin Prime Solutions Group, Inc. Prime Solutions Group, Inc. (623) 853-0829 (623) 853-0829 [email protected] [email protected] Leung Chim Michael E. Pafford Defence Science & Technology Group Johns Hopkins University +61 (0) 8 7389 7908 (301) 935-5280 [email protected] [email protected] Copyright © 2018 by the authors. Published and used by INCOSE with permission. Abstract. In the 21st century, when any sophisticated system has significant software content, it is increasingly critical to articulate and improve the interface between systems engineering and software engineering, i.e., the relationships between systems and software engineering technical and management processes, products, tools, and outcomes. Although systems engineers and software engineers perform similar activities and use similar processes, their primary responsibilities and concerns differ. Systems engineers focus on the global aspects of a system. Their responsibilities span the lifecycle and involve ensuring the various elements of a system—e.g., hardware, software, firmware, engineering environments, and operational environments—work together to deliver capability. Software engineers also have responsibilities that span the lifecycle, but their focus is on activities to ensure the software satisfies software-relevant system requirements and constraints. Software engineers must maintain sufficient knowledge of the non-software elements of the systems that will execute their software, as well as the systems their software must interface with. -

Infrastructure (Resilience-Oriented) Modelling Language: I®ML
Infrastructure (Resilience-oriented) Modelling Language: I®ML A proposal for modelling infrastructures and their interconnections Andrés Silva, Roberto Filippini EUR 24727 EN - 2011 The mission of the JRC-IPSC is to provide research results and to support EU policy-makers in their effort towards global security and towards protection of European citizens from accidents, deliberate attacks, fraud and illegal actions against EU policies. European Commission Joint Research Centre Institute for the Protection and Security of the Citizen Contact information Address: TP 210, EC JRC Ispra, Ispra (Va) Italy E-mail: [email protected] Tel.: +39 0332 789936 Fax: http://ipsc.jrc.ec.europa.eu/ http://www.jrc.ec.europa.eu/ Legal Notice Neither the European Commission nor any person acting on behalf of the Commission is responsible for the use which might be made of this publication. Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) Certain mobile telephone operators do not allow access to 00 800 numbers or these calls may be billed. A great deal of additional information on the European Union is available on the Internet. It can be accessed through the Europa server http://europa.eu/ JRC 63302 EUR 24727 EN ISBN 978-92-79-19324-8 ISSN 1018-5593 doi:10.2788/54708 Luxembourg: Publications Office of the European Union © European Union, 2011 Reproduction is authorised provided the source is acknowledged Printed in Italy Infrastructure (Resilience-oriented) Modelling Language: I®ML A proposal for modelling infrastructures and their connections Andrés Silva1 Roberto Filippini Universidad Politécnica de Madrid JRC of the European Commission Abstract The modelling of critical infrastructures (CIs) is an important issue that needs to be properly addressed, for several reasons. -
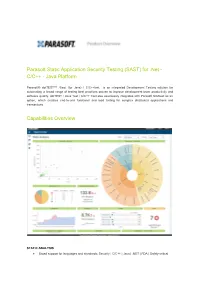
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

Email: [email protected] Website
Email: [email protected] Website: http://chrismatech.com Experienced software and systems engineer who has successfully deployed custom & industry-standard embedded, desktop and networked systems for commercial and DoD customers. Delivered systems operate on airborne, terrestrial, maritime, and space based vehicles and platforms. Expert in performing all phases of the software and system development life-cycle including: Creating requirements and design specifications. Model-driven software development, code implementation, and unit test. System integration. Requirements-based system verification with structural coverage at the system and module levels. Formal qualification/certification test. Final product packaging, delivery, and site installation. Post-delivery maintenance and customer support. Requirements management and end-to-end traceability. Configuration management. Review & control of change requests and defect reports. Quality assurance. Peer reviews/Fagan inspections, TIMs, PDRs and CDRs. Management and project planning proficiencies include: Supervising, coordinating, and mentoring engineering staff members. Creating project Software Development Plans (SDPs). Establishing system architectures, baseline designs, and technical direction. Creating & tracking project task and resource scheduling, costs, resource utilization, and metrics (e.g., Earned Value Analysis). Preparing proposals in response to RFPs and SOWs. Project Management • Microsoft Project, Excel, Word, PowerPoint, Visio & Documentation: • Adobe Acrobat Professional -

Survey of Verification and Validation Techniques for Small Satellite Software Development
Survey of Verification and Validation Techniques for Small Satellite Software Development Stephen A. Jacklin NASA Ames Research Center Presented at the 2015 Space Tech Expo Conference May 19-21, Long Beach, CA Summary The purpose of this paper is to provide an overview of the current trends and practices in small-satellite software verification and validation. This document is not intended to promote a specific software assurance method. Rather, it seeks to present an unbiased survey of software assurance methods used to verify and validate small satellite software and to make mention of the benefits and value of each approach. These methods include simulation and testing, verification and validation with model-based design, formal methods, and fault-tolerant software design with run-time monitoring. Although the literature reveals that simulation and testing has by far the longest legacy, model-based design methods are proving to be useful for software verification and validation. Some work in formal methods, though not widely used for any satellites, may offer new ways to improve small satellite software verification and validation. These methods need to be further advanced to deal with the state explosion problem and to make them more usable by small-satellite software engineers to be regularly applied to software verification. Last, it is explained how run-time monitoring, combined with fault-tolerant software design methods, provides an important means to detect and correct software errors that escape the verification process or those errors that are produced after launch through the effects of ionizing radiation. Introduction While the space industry has developed very good methods for verifying and validating software for large communication satellites over the last 50 years, such methods are also very expensive and require large development budgets. -

An Eclipse Plug-In for Testing and Debugging
GZoltar: An Eclipse Plug-In for Testing and Debugging José Campos André Riboira Alexandre Perez Rui Abreu Department of Informatics Engineering Faculty of Engineering, University of Porto Portugal {jose.carlos.campos, andre.riboira, alexandre.perez}@fe.up.pt; [email protected] ABSTRACT coverage). Several debugging tools exist which are based on Testing and debugging is the most expensive, error-prone stepping through the execution of the program (e.g., GDB phase in the software development life cycle. Automated and DDD). These traditional, manual fault localization ap- testing and diagnosis of software faults can drastically proaches have a number of important limitations. The place- improve the efficiency of this phase, this way improving ment of print statements as well as the inspection of their the overall quality of the software. In this paper we output are unstructured and ad-hoc, and are typically based present a toolset for automatic testing and fault localiza- on the developer's intuition. In addition, developers tend to use only test cases that reveal the failure, and therefore do tion, dubbed GZoltar, which hosts techniques for (regres- sion) test suite minimization and automatic fault diagno- not use valuable information from (the typically available) sis (namely, spectrum-based fault localization). The toolset passing test cases. provides the infrastructure to automatically instrument the Aimed at drastic cost reduction, much research has been source code of software programs to produce runtime data. performed in developing automatic testing and fault local- Subsequently the data was analyzed to both minimize the ization techniques and tools. As far as testing is concerned, test suite and return a ranked list of diagnosis candidates. -

IS2018 Book of Abstract
th Annual INCOSE 28 international symposium Washington, DC, USA July 7 - 12, 2018 Delivering Systems in the Age of Globalization Status as of May 15 th , 2018 Book of Abstract Table of contents keynotes ............................................................................................................................................................................... p. 7 keynotes#Keynote#2: The Big Shift: Innovation and Systems Engineering ................................................................ p. 7 Papers .................................................................................................................................................................................. p. 8 Papers#107: A Framework for Concept and its Testing on Patents ............................................................................ p. 8 Papers#75: A Framework for Testability Analysis from System Architecture Perspective .......................................... p. 9 Papers#128: A Framework for Understanding Systems Principles and Methods .......................................................p. 10 Papers#31: A fresh look at Systems Engineering - what is it, how should it work? .....................................................p. 11 Papers#35: A Hybrid Liver-Candidate Transportation System to Improve Accessibility and Extend Organ Life in L ..p. 12 Papers#55: A Novel “Resilience Viewpoint” to aid in Engineering Resilience in Systems of Systems (SoS) .............p. 13 Papers#97: A successful use of systems approaches in -

Eclipse Project Briefing Materials
[________________________] Eclipse project briefing materials. Copyright (c) 2002, 2003 IBM Corporation and others. All rights reserved. This content is made available to you by Eclipse.org under the terms and conditions of the Common Public License Version 1.0 ("CPL"), a copy of which is available at http://www.eclipse.org/legal/cpl-v10.html The most up-to-date briefing materials on the Eclipse project are found on the eclipse.org website at http://eclipse.org/eclipse/ 200303331 1 EclipseEclipse ProjectProject 200303331 3 Eclipse Project Aims ■ Provide open platform for application development tools – Run on a wide range of operating systems – GUI and non-GUI ■ Language-neutral – Permit unrestricted content types – HTML, Java, C, JSP, EJB, XML, GIF, … ■ Facilitate seamless tool integration – At UI and deeper – Add new tools to existing installed products ■ Attract community of tool developers – Including independent software vendors (ISVs) – Capitalize on popularity of Java for writing tools 200303331 4 Eclipse Overview Another Eclipse Platform Tool Java Workbench Help Development Tools JFace (JDT) SWT Team Your Tool Plug-in Workspace Development Debug Environment (PDE) Their Platform Runtime Tool Eclipse Project 200303331 5 Eclipse Origins ■ Eclipse created by OTI and IBM teams responsible for IDE products – IBM VisualAge/Smalltalk (Smalltalk IDE) – IBM VisualAge/Java (Java IDE) – IBM VisualAge/Micro Edition (Java IDE) ■ Initially staffed with 40 full-time developers ■ Geographically dispersed development teams – OTI Ottawa, OTI Minneapolis, -

A Software Safety Process for Safety-Critical Advanced Automotive Systems
PROCEEDINGS of the 21st INTERNATIONAL SYSTEM SAFETY CONFERENCE - 2003 A Software Safety Process for Safety-Critical Advanced Automotive Systems Barbara J. Czerny, Ph.D.; Joseph G. D’Ambrosio, Ph.D., PE; Paravila O. Jacob, Ph.D.; Brian T. Murray, Ph.D.; Padma Sundaram; Delphi, Corp.; Brighton, Michigan Keywords: SW Safety, Safety-Critical Advanced Automotive Systems, By-Wire Systems Abstract A new generation of advanced automotive systems are being implemented to enhance vehicle safety, performance, and comfort. As these new, often complex systems are added, system safety programs are employed to help eliminate potential hazards. A key component of these advanced automotive systems is software. Software itself cannot fail or wear out, but its complexity coupled with its interactions with the system and the environment can directly and indirectly lead to potential system hazards. As such, software safety cannot be considered apart from system safety, but the unique aspects of software warrant unique development and analysis methods. In this paper we describe the main elements of a software safety process for safety-critical advanced automotive systems. We describe how this proposed process may be integrated with an established system safety process for by-wire automotive systems, and how it may be integrated with an established software development process. Introduction Expanding demand for further improvements in vehicle safety, performance, fuel economy and low emissions has led to a rapid and accelerating increase in the amount and sophistication of vehicle electronics. Emerging vehicle electronics systems are programmable, with a substantial software component, and are highly complex distributed systems. Increasingly, they are receiving driver inputs and directly controlling essential vehicle functions like braking and steering. -

Model for Safety Case Modeling and Documentation
SAFE – an ITEA2 project D3.1.3 Contract number: ITEA2 – 10039 Safe Automotive soFtware architEcture (SAFE) ITEA Roadmap application domains: Major: Services, Systems & Software Creation Minor: Society ITEA Roadmap technology categories: Major: Systems Engineering & Software Engineering Minor 1: Engineering Process Support WP3 Deliverable D3.1.3: Proposal for extension of Meta- model for safety case modeling and documentation Due date of deliverable: 31/03/2013 Actual submission date: 28/03/2013 Start date of the project: 01/07/2011 Duration: 36 months Project coordinator name: Stefan Voget Organization name of lead contractor for this deliverable: fortiss Editor: Maged Khalil (fortiss GmbH) Contributors: Maged Khalil (fortiss GmbH), Eduard Metzker (Vector Informatik GmbH) Reviewers: Eduard Metzker (Vector Informatik GmbH) 2013 The SAFE Consortium 1 (50) SAFE – an ITEA2 project D3.1.3 Revision chart and history log Version Date Reason 0.1 2012-09-19 Initialization of document 0.2 2012-10-18 Input to Introduction Section 4 0.3 2012-11-07 Input to Overview on ISO Section 5 0.4 2012-11-16 Input to EAST-ADL Overview Section 7 0.5 2012-11-16 Input to Overview on ISO Section 5 0.6 2012-11-23 Input to Methodology Section 6 0.7 2012-11-29 Further Input to Methodology Section 6 0.8 2012-12-20 Editing and Input in various sections 0.9 2013-02-13 Input to SAFE Meta-model Contribution Section 8 0.10 2013-02-15 Introduction of Patterns Section 6.3 0.11 2013-03-08 Editing and Input in various sections 0.12 2013-03-24 First version ready for review 0.13 2013-03-26 Incorporation of first review comments 0.14 2013-03-27 Updated version reviewed.