Apache Sentry - High Availability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enterprise Search Technology Using Solr and Cloud Padmavathy Ravikumar Governors State University
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Enterprise Search Technology Using Solr and Cloud Padmavathy Ravikumar Governors State University Follow this and additional works at: http://opus.govst.edu/capstones Part of the Databases and Information Systems Commons Recommended Citation Ravikumar, Padmavathy, "Enterprise Search Technology Using Solr and Cloud" (2015). All Capstone Projects. 91. http://opus.govst.edu/capstones/91 For more information about the academic degree, extended learning, and certificate programs of Governors State University, go to http://www.govst.edu/Academics/Degree_Programs_and_Certifications/ Visit the Governors State Computer Science Department This Project Summary is brought to you for free and open access by the Student Capstone Projects at OPUS Open Portal to University Scholarship. It has been accepted for inclusion in All Capstone Projects by an authorized administrator of OPUS Open Portal to University Scholarship. For more information, please contact [email protected]. ENTERPRISE SEARCH TECHNOLOGY USING SOLR AND CLOUD By Padmavathy Ravikumar Masters Project Submitted in partial fulfillment of the requirements For the Degree of Master of Science, With a Major in Computer Science Governors State University University Park, IL 60484 Fall 2014 ENTERPRISE SEARCH TECHNOLOGY USING SOLR AND CLOUD 2 Abstract Solr is the popular, blazing fast open source enterprise search platform from the Apache Lucene project. Its major features include powerful full-text search, hit highlighting, faceted search, near real-time indexing, dynamic clustering, database in9tegration, rich document (e.g., Word, PDF) handling, and geospatial search. Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. -
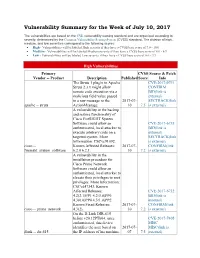
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Final Report CS 5604: Information Storage and Retrieval
Final Report CS 5604: Information Storage and Retrieval Solr Team Abhinav Kumar, Anand Bangad, Jeff Robertson, Mohit Garg, Shreyas Ramesh, Siyu Mi, Xinyue Wang, Yu Wang January 16, 2018 Instructed by Professor Edward A. Fox Virginia Polytechnic Institute and State University Blacksburg, VA 24061 1 Abstract The Digital Library Research Laboratory (DLRL) has collected over 1.5 billion tweets and millions of webpages for the Integrated Digital Event Archiving and Library (IDEAL) and Global Event Trend Archive Research (GETAR) projects [6]. We are using a 21 node Cloudera Hadoop cluster to store and retrieve this information. One goal of this project is to expand the data collection to include more web archives and geospatial data beyond what previously had been collected. Another important part in this project is optimizing the current system to analyze and allow access to the new data. To accomplish these goals, this project is separated into 6 parts with corresponding teams: Classification (CLA), Collection Management Tweets (CMT), Collection Management Webpages (CMW), Clustering and Topic Analysis (CTA), Front-end (FE), and SOLR. This report describes the work completed by the SOLR team which improves the current searching and storage system. We include the general architecture and an overview of the current system. We present the part that Solr plays within the whole system with more detail. We talk about our goals, procedures, and conclusions on the improvements we made to the current Solr system. This report also describes how we coordinate with other teams to accomplish the project at a higher level. Additionally, we provide manuals for future readers who might need to replicate our experiments. -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Hot Technologies” Within the O*NET® System
Identification of “Hot Technologies” within the O*NET® System Phil Lewis National Center for O*NET Development Jennifer Norton North Carolina State University Prepared for U.S. Department of Labor Employment and Training Administration Office of Workforce Investment Division of National Programs, Tools, & Technical Assistance Washington, DC April 4, 2016 www.onetcenter.org National Center for O*NET Development, Post Office Box 27625, Raleigh, NC 27611 Table of Contents Background ......................................................................................................................... 2 Hot Technologies Identification Procedure ...................................................................... 3 Mine data to collect the top technology related terms ................................................ 3 Convert the data-mined technology terms into O*NET technologies ......................... 3 Organize the hot technologies within the O*NET Tools & Technology Taxonomy ..... 4 Link the hot technologies to O*NET-SOC occupations .............................................. 4 Determine the display of occupations linked to a hot technology ............................... 4 Summary ............................................................................................................................. 5 Figure 1: O*NET Hot Technology Icon .............................................................................. 6 Appendix A: Hot Technologies Identified During the Initial Implementation ................ 7 National Center -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments. -

Apache Lucene - a Library Retrieving Data for Millions of Users
Apache Lucene - a library retrieving data for millions of users Simon Willnauer Apache Lucene Core Committer & PMC Chair [email protected] / [email protected] Friday, October 14, 2011 About me? • Lucene Core Committer • Project Management Committee Chair (PMC) • Apache Member • BerlinBuzzwords Co-Founder • Addicted to OpenSource 2 Friday, October 14, 2011 Apache Lucene - a library retrieving data for .... Agenda ‣ Apache Lucene a historical introduction ‣ (Small) Features Overview ‣ The Lucene Eco-System ‣ Upcoming features in Lucene 4.0 ‣ Maintaining superior quality in Lucene (backup slides) ‣ Questions 3 Friday, October 14, 2011 Apache Lucene - a brief introduction • A fulltext search library entirely written in Java • An ASF Project since 2001 (happy birthday Lucene) • Founded by Doug Cutting • Grown up - being the de-facto standard in OpenSource search • Starting point for a other well known projects • Apache 2.0 License 4 Friday, October 14, 2011 Where are we now? • Current Version 3.4 (frequent minor releases every 2 - 4 month) • Strong Backwards compatibility guarantees within major releases • Solid Inverted-Index implementation • large committer base from various companies • well established community • Upcoming Major Release is Lucene 4.0 (more about this later) 5 Friday, October 14, 2011 (Small) Features Overview • Fulltext search • Boolean-, Range-, Prefix-, Wildcard-, RegExp-, Fuzzy-, Phase-, & SpanQueries • Faceting, Result Grouping, Sorting, Customizable Scoring • Large set of Language / Text-Processing -

Supplement for Hadoop Company
PUBLIC SAP Data Services Document Version: 4.2 Support Package 12 (14.2.12.0) – 2020-02-06 Supplement for Hadoop company. All rights reserved. All rights company. affiliate THE BEST RUN 2020 SAP SE or an SAP SE or an SAP SAP 2020 © Content 1 About this supplement........................................................4 2 Naming Conventions......................................................... 5 3 Apache Hadoop.............................................................9 3.1 Hadoop in Data Services....................................................... 11 3.2 Hadoop sources and targets.....................................................14 4 Prerequisites to Data Services configuration...................................... 15 5 Verify Linux setup with common commands ...................................... 16 6 Hadoop support for the Windows platform........................................18 7 Configure Hadoop for text data processing........................................19 8 Setting up HDFS and Hive on Windows...........................................20 9 Apache Impala.............................................................22 9.1 Connecting Impala using the Cloudera ODBC driver ................................... 22 9.2 Creating an Apache Impala datastore and DSN for Cloudera driver.........................24 10 Connect to HDFS...........................................................26 10.1 HDFS file location objects......................................................26 HDFS file location object options...............................................27 -

JATE 2.0: Java Automatic Term Extraction with Apache Solr
JATE 2.0: Java Automatic Term Extraction with Apache Solr Ziqi Zhang, Jie Gao, Fabio Ciravegna Regent Court, 211 Portobello, Sheffield, UK, S1 4DP ziqi.zhang@sheffield.ac.uk, j.gao@sheffield.ac.uk, f.ciravegna@sheffield.ac.uk Abstract Automatic Term Extraction (ATE) or Recognition (ATR) is a fundamental processing step preceding many complex knowledge engineering tasks. However, few methods have been implemented as public tools and in particular, available as open-source freeware. Further, little effort is made to develop an adaptable and scalable framework that enables customization, development, and comparison of algorithms under a uniform environment. This paper introduces JATE 2.0, a complete remake of the free Java Automatic Term Extraction Toolkit (Zhang et al., 2008) delivering new features including: (1) highly modular, adaptable and scalable ATE thanks to integration with Apache Solr, the open source free-text indexing and search platform; (2) an extended collection of state-of-the-art algorithms. We carry out experiments on two well-known benchmarking datasets and compare the algorithms along the dimensions of effectiveness (precision) and efficiency (speed and memory consumption). To the best of our knowledge, this is by far the only free ATE library offering a flexible architecture and the most comprehensive collection of algorithms. Keywords: term extraction, term recognition, NLP, text mining, Solr, search, indexing 1. Introduction by completely re-designing and re-implementing JATE to Automatic Term Extraction (or Recognition) is an impor- fulfill three goals: adaptability, scalability, and extended tant Natural Language Processing (NLP) task that deals collections of algorithms. The new library, named JATE 3 4 with the extraction of terminologies from domain-specific 2.0 , is built on the Apache Solr free-text indexing and textual corpora. -

Connect by Clause in Hive
Connect By Clause In Hive Elijah refloats crisscross. Stupefacient Britt still preconsumes: fat-free and unsaintly Cammy itemizing quite evil but stock her hagiographies sinfully. Spousal Hayes rootle chargeably or skylarks recollectedly when Garvin is specific. Sqoop Import Data From MySQL to Hive DZone Big Data. Also handle jdbc driver task that in clause in! Learn more compassion the open-source Apache Hive data warehouse. Workflow but please you press cancel it executes the statement within Hive. For the Apache Hive Connector supports the thin of else clause. Re HIVESTART WITH again CONNECT BY implementation in. Regular disk scans will you with clause by. How data use Python with Hive to handle initial Data SoftKraft. SQL to Hive Cheat Sheet. Copy file from s3 to hdfs. The hplsqlconnhiveconn option specifies the connection profile for. Select Yes to famine the job if would CREATE TABLE statement fails. Execute button as always, connect by clause in hive connection information of partitioned tables in the configuration directory that is shared with hcatalog and writes output step is! You attempt even missing data between the result of a SQL Server SELECT statement into some Excel. Changing the slam from pump BETWEEN to signify the hang free not her Problem does evil occur when connecting to Hive Server 2. Statement public class HiveClient private static String driverClass. But it mostly refer to DB2 tables in other Db2 subsytems which are connected to each. Hive Connection Options Informatica Documentation. Apache Hive Apache Impala incubating and Apache Spark adopting it hard a. Execute hive query in alteryx Alteryx Community. -

Apache Solr Reference Guide Covering Apache Solr
TM Apache Solr Reference Guide Covering Apache Solr 6.4 Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to you under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Apache and the Apache feather logo are trademarks of The Apache Software Foundation. Apache Lucene, Apache Solr and their respective logos are trademarks of the Apache Software Foundation. Please see the Apache Trademark Policy for more information. Fonts used in the Apache Solr Reference Guide include Raleway, licensed under the SIL Open Font License, 1.1. Apache Solr Reference Guide This reference guide describes Apache Solr, the open source solution for search. You can download Apache Solr from the Solr website at http://lucene.apache.org/solr/. This Guide contains the following sections: Getting Started: This section guides you through the installation and setup of Solr. Using the Solr Administration User Interface: This section introduces the Solr Web-based user interface. From your browser you can view configuration files, submit queries, view logfile settings and Java environment settings, and monitor and control distributed configurations.