Data-To-Text Generation with Content Selection and Planning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Canada's Bennett Leads a Draft Without Borders
36 BASKETBALL TIMES Canada’s Bennett leads a draft without borders Carl Berman International Game Since NetScouts but he’ll be more than that. Minnesota. Dieng can rebound and block shots and has Basketball has been Olynyk runs the floor hard, shown improvement out to 15 feet. While he is an older covering international has a consistent jumper to selection (23), he can be a rotation player quickly if he basketball, it has become 20 feet and can drive from continues to improve his offensive game and add strength. apparent to us that although the key. Big Frenchman Rudy Gobert, who’s 7-2, was taken the USA is the deepest Nogueira, of Brazil, at No. 27 by Denver and was subsequently traded to Utah. country for basketball first impressed us at the Gobert, boasting a 7-9 wingspan and a 9-7 standing reach, talent, other countries FIBA Americas tournament will at the very least be a rim protector. He can score around are starting to produce in 2010. He’s skinny and the basket and shows the capability of developing a decent individual talent that likely will not fill out step-out game. However, he’s not a jumper nor is he very compares favorably with much. However, he can athletic, so it will be interesting to see how he develops. the best that America has to block shots and has shown San Antonio picked up another international with the offer. That was never more improvement this past selection of Nike Hoop Summit MVP, 6-9 Livio Jean- apparent than in this year’s year with Estudiantes in Charles of France. -

WICHITA STATE BASKETBALL TUNING in OPENING TIPS No. 4
WICHITA STATE BASKETBALL Contact: Bryan Holmgren, Asst. Director/Media Relations • [email protected] • o: 316-978-5535 • c: 316-841-6206 [4] WICHITA STATE (25-7, 14-4 American) vs. [13] MARSHALL (24-10, 12-6 C-USA) Friday, Mar. 16, 2018 • 12:30 pm CT (10:30 am PT) • San Diego, Calif. • Viejas Arena at Aztec Bowl NCAA Men's Basketball Championship • First Round 33 Winner to Second Round: Sunday, March 18 vs. [5] West Virginia or [12] Murray State [4] WICHITA STATE [13] MARSHALL OPENING TIPS TUNING IN Overall Conf Overall Conf No. 4 seed Wichita State (25-7 and ranked 16th in the latest AP TELECAST TNT 25-7 14-4 Record 24-10 12-6 and USA Today Coaches Polls) tips off its seventh-consecutive NCAA Talent: Carter Blackburn (pbp), Debbie Antonelli 13-3 7-2 Home 15-2 7-2 Tournament appearance Friday morning in San Diego against No. (analyst) & John Schriffen (reporter) 9-2 7-2 Away 6-8 5-4 Streaming ncaa.com/march-madness-live 3-2 Neutral 3-0 13 seed Marshall (24-10) on TNT. The WSU-Marshall winner advances to Sunday's second round RADIO Shocker Radio // KEYN 103.7 FM (Wichita) Lost 1 Streak Won 4 Talent: Mike Kennedy, Bob Hull & Dave Dahl 16 / 16 AP / Coaches -/- to face either No. 5 West Virginia or No. 12 Murray State. Streaming: none 16 NCAA RPI* 87 WSU and Marshall meet for just the third time. The teams split 20 KenPom* 114 a home-and-home, with WSU winning in Wichita in December, RADIO Westwood One // Sirius 145 & XM 203 14 At-Large S-Curve 54 Auto Talent: John Sadak & Mike Montgomery 1940. -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -
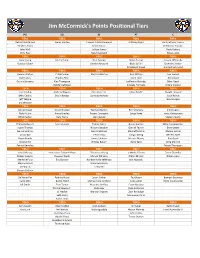
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -

2014-15 Panini Select Basketball Set Checklist
2014-15 Panini Select Basketball Set Checklist Base Set Checklist 100 cards Concourse PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Blue Prizms #/249, Red Prizms #/149, Orange Prizms #/60, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Premier PARALLEL CARDS: Purple/White Prizms, Silver Prizms, Light Blue Prizms Die-Cut #/199, Purple Prizms Die-Cut #/99, Tie-Dye Prizms Die-Cut #/25, Gold Prizms Die-Cut #/10, Green Prizms Die-Cut #/5, Black Prizms Die-Cut 1/1 Courtside PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Copper #/49, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Concourse 1 Stephen Curry - Golden State Warriors 2 Dwyane Wade - Miami Heat 3 Victor Oladipo - Orlando Magic 4 Larry Sanders - Milwaukee Bucks 5 Marcin Gortat - Washington Wizards 6 LaMarcus Aldridge - Portland Trail Blazers 7 Serge Ibaka - Oklahoma City Thunder 8 Roy Hibbert - Indiana Pacers 9 Klay Thompson - Golden State Warriors 10 Chris Bosh - Miami Heat 11 Nikola Vucevic - Orlando Magic 12 Ersan Ilyasova - Milwaukee Bucks 13 Tim Duncan - San Antonio Spurs 14 Damian Lillard - Portland Trail Blazers 15 Anthony Davis - New Orleans Pelicans 16 Deron Williams - Brooklyn Nets 17 Andre Iguodala - Golden State Warriors 18 Luol Deng - Miami Heat 19 Goran Dragic - Phoenix Suns 20 Kobe Bryant - Los Angeles Lakers 21 Tony Parker - San Antonio Spurs 22 Al Jefferson - Charlotte Hornets 23 Jrue Holiday - New Orleans Pelicans 24 Kevin Garnett - Brooklyn Nets 25 Derrick Rose -

2013 NBA Draft
Round 1 Draft Picks 1. Cleveland Cavaliers – Anthony Bennett (PF), UNLV 2. Orlando Magic – Victor Oladipo (SG), Indiana 3. Washington Wizards – Otto Porter Jr. (SF), Georgetown 4. Charlotte Bobcats – Cody Zeller (PF), Indiana University 5. Phoenix Suns – Alex Len (C), Maryland 6. New Orleans Pelicans – Nerlens Noel (C), Kentucky 7. Sacramento KinGs – Ben McLemore (SG), Kansas 8. Detroit Pistons – Kentavious Caldwell-Pope (SG), Georgia 9. Minnesota Timberwolves – Trey Burke (PG), Michigan 10. Portland Trail Blazers – C.J. McCollum (PG), Lehigh 11. Philadelphia 76ers – Michael Carter-Williams (PG), Syracuse 12. Oklahoma City Thunder – Steven Adams (C), PittsburGh 13. Dallas Mavericks – Kelly Olynyk (PF), Gonzaga 14. Utah Jazz – Shabazz Muhammad (SF), UCLA 15. Milwaukee Bucks – Giannis Antetokounmpo (SF), Greece 16. Boston Celtics – Lucas Nogueira (C), Brazil 17. Atlanta Hawks – Dennis Schroeder (PG), Germany 18. Atlanta Hawks – Shane Larkin (PG), Miami 19. Cleveland Cavaliers – Sergey Karasev (SG), Russia 20. ChicaGo Bulls – Tony Snell (SF), New Mexico 21. Utah Jazz – Gorgui Dieng (C), Louisville 22. Brooklyn – Mason Plumlee, (C), Duke 23. Indiana Pacers – Solomon Hill (SF), Arizona 24. New York Knicks – Tim Hardaway Jr. (SG), MichiGan 25. Los Angeles Clippers – Reggie Bullock (SG), UNC 26. Minnesota Timberwolves – Andre Roberson (SF), Colorado 27. Denver Nuggets – Rudy Gobert (SF), France 28. San Antonio Spurs – Livio Jean-Charles (PF), French Guiana 29. Oklahoma City Thunder – Archie Goodwin (SG), Kentucky 30. Phoenix Suns – Nemanja Nedovic (SG), Serbia Round 2 Draft Picks 31. Cleveland Cavaliers – Allen Crabbe (SG), California 32. Oklahoma City Thunder – Alex Abrines (SG), Spain 33. Cleveland Cavaliers – Carrick Felix (SG), Arizona State 34. Houston Rockets – Isaiah Canaan (PG), Murray State 35. -

Dallas Mavericks (42-30) (3-3)
DALLAS MAVERICKS (42-30) (3-3) @ LA CLIPPERS (47-25) (3-3) Game #7 • Sunday, June 6, 2021 • 2:30 p.m. CT • STAPLES Center (Los Angeles, CA) • ABC • ESPN 103.3 FM • Univision 1270 THE 2020-21 DALLAS MAVERICKS PLAYOFF GUIDE IS AVAILABLE ONLINE AT MAVS.COM/PLAYOFFGUIDE • FOLLOW @MAVSPR ON TWITTER FOR STATS AND INFO 2020-21 REG. SEASON SCHEDULE PROBABLE STARTERS DATE OPPONENT SCORE RECORD PLAYER / 2020-21 POSTSEASON AVERAGES NOTES 12/23 @ Suns 102-106 L 0-1 12/25 @ Lakers 115-138 L 0-2 #10 Dorian Finney-Smith LAST GAME: 11 points (3-7 3FG, 2-2 FT), 7 rebounds, 4 assists and 2 steals 12/27 @ Clippers 124-73 W 1-2 F • 6-7 • 220 • Florida/USA • 5th Season in 42 minutes in Game 6 vs. LAC (6/4/21). NOTES: Scored a playoff career- 12/30 vs. Hornets 99-118 L 1-3 high 18 points in Game 1 at LAC (5/22/21) ... hit GW 3FG vs. WAS (5/1/21) 1/1 vs. Heat 93-83 W 2-3 GP/GS PPG RPG APG SPG BPG MPG ... DAL was 21-9 during the regular season when he scored in double figures, 1/3 @ Bulls 108-118 L 2-4 6/6 9.0 6.0 2.2 1.3 0.3 38.5 1/4 @ Rockets 113-100 W 3-4 including 3-1 when he scored 20+. 1/7 @ Nuggets 124-117* W 4-4 #6 LAST GAME: 7 points, 5 rebounds, 3 assists, 3 steals and 1 block in 31 1/9 vs. -

NCAAB: Is Kentucky’S Jamal Murray the Next Canadian
NCAAB: Is Kentucky's Jamal Murray The Next Canadian Hoops Superstar? Author : If the 2015 Pan Am games taught us anything, it's that Canadian basketball is a force to reckoned with. And a great deal of credit for the recent success goes to 18-year-old Jamal Murray. Murray will assuredly be one of the most talked about college freshmen in recent years. He is set to join John Calipari at Kentucky for the 2015-16 season. It's just another quality pick up for a school and coach that have become synonymous with developing NBA talent. Indeed, Murray is going to be a game changer for Kentucky, and will no doubt continue the school's trend of one-and-done players. He is definitely capable of taking his game beyond the college level, and is going to considered for the top overall pick in the 2016 NBA Draft. The Kitchener, Ontario native has seen his stock grow exponentially over recent months. Murray was the main attraction at the Nike Hoop Summit, scoring 30 points and taking home MVP honors. And while that carries a lot of significance to scouts, it's his breakout game at the Pan Am's that put everyone on notice. During Canada's matchup against the United States, Murray was held off the score sheet for the first three quarters. But that was only temporary. He caught fire and scored 22 points in the final quarter. He put himself on the map, not only as a prestigious NCAA Freshman, but as a potential difference maker in Canada's rise to basketball glory. -

Basketball Times
BASKETBALL TIMES Visit: www.usbwa.com March 2013 VOLUME 50, NO. 3 Hall of Fame welcomes Bilovsky, Lopresti, Rawlings Frank Bilovsky made his bones in the “I scrolled down … scrolled down … Big Five’s heyday. Mike Lopresti was born scrolled down,” Wieberg says, “until I’d read and raised in Indiana, where he has spent his through it, and then looked at him. ‘Bleep entire professional career. Lenox Rawlings you,’ I said. I couldn’t have written anything grew up in the Tobacco Road neighborhood, half as good if I’d had hours or even days to worked a brief spell elsewhere and returned think it through.” to become a regional icon. It’s hard to imagine anyone saying It’s not a requirement for USBWA Hall “Bleep you” to Rawlings, who retired in of Fame inductees to be rooted in the na- December after 34 years writing sports col- tion’s most fertile hoops soil. But when great umns for the Winston-Salem Journal, where journalism talent lives among great subject his work was must-read material for anyone matter, the resulting body of work winds up remotely interested in the ACC. He previ- a slam dunk for election. ously worked in Raleigh, Greensboro and At age 13 in rural Pennsylvania, Bi- Atlanta. lovsky was smitten by college basketball Frank Bilovsky Mike Lopresti Lenox Rawlings A graduate of North Carolina, Rawlings when Lebanon Valley College from nearby never played favorites as he wrote about Annville was invited to the 1953 NCAA tournament. The ism start at his hometown newspaper, the Palladium-Item, some of college ball’s hottest rivalries, and he never shied Flying Dutchmen defeated Fordham before falling to Bob while a high school student in Richmond, Ind., where he still from criticizing whoever and whatever deserved rebuke. -
A Victory Worth Dancing About Gonzaga Head Coach
PAGE C16 G SUNDAY G MARCH 24, 2013 THE SPOKESMAN-REVIEW MEN’S NCAA TOURNAMENT: SPOKESMAN.COM/SPORTS COLIN MULVANY [email protected] Will this be the last time Kelly Olynyk leaves the court as a Zag? He has to decide whether to declare early for the NBA draft. End for three seniors THEY SAID IT GONZAGA-WICHITA STATE NOTEBOOK R Jim Meehan and Christian Caple, Staff writers SALT LAKE CITY – Elias Harris, one of Gonzaga’s “I lost it a little bit, just three Gonzaga seniors, would do it all over Mike Hart the instant reaction again, except change the ending. battles “It just hurts,” said Harris, who had 12 Wichita and realizing this was points and seven boards in Gonzaga’s 76-70 State’s the finish. That’s the NCAA tournament loss to Wichita State on Ron Baker Saturday. “It’ll take time to get over this. for a rebound. brutality of the Great coaching staff, great group of guys. If Hart had six NCAA tournament, I could do it all over again with the same points and 14 group of guys, I would.” rebounds how great it can be The forward’s stellar career ended with in his final and how quickly it another tough outing. He was held to five game – and points on 2-of-10 shooting in Thursday’s perhaps can all end.” win over Southern. He made just 2 of 8 his best – Mike Hart, shots against the Shockers. as a Zag. Gonzaga senior guard Harris and the rest of the Zags were struggling to put a wildly successful season – a 32-3 record, a rise to No. -

The Automated General Manager
An Unbiased, Backtested Algorithmic System for Drafts, Trades, and Free Agency that The Automated Outperforms Human Front Oices Philip Maymin University of Bridgeport Vantage Sports Trefz School of Business [email protected] [email protected] General Manager All tools and reports available for free on nbagm.pm Draft Performance 200315 of All Picks Evaluate: Kawhi Leonard 2015 NBA Draft Board Production measured as average Wins Made (WM) over irst three seasons. Player Drafted Team Projection RSCI 54 Reach 106 Height 79 ORB% 11.80 Min/3PFGA 12.74 # 1 D’Angelo Russell 2 LAL 5.422 nbnMock 9 MaxVert 32.00 Weight 230 DRB% 27.60 FT/FGA 0.30 Pick 15 Pick 615 Pick 1630 Pick 3145 Pick 4660 2 Karl Anthony Towns 1 MIN 5.125 Actual: 3.94 Actual: 2.02 Actual: 1.24 Actual: 0.53 Actual: 0.28 deMock Sprint SoS AST% PER 14 3.15 0.56 15.80 27.50 3 Jahlil Okafor 3 PHL 5.113 Model: 4.64 Model: 3.88 Model: 2.75 Model: 1.42 Model: 0.50 $Gain: +3.49 $Gain: +9.18 $Gain: +7.51 $Gain: +4.42 $Gain: +1.08 sbMock 8 Agility 11.45 Pos F TOV% 12.40 PPS 1.20 4 Willie Cauley-Stein 6 SAC 3.297 5 Frank Kaminsky 9 CHA 3.077 cfMock 7 Bench 3 Age 19.96 STL% 2.90 ORtg 112.90 In this region, the model draft choice was 6 Justise Winslow 10 MIA 2.916 siMock 7 Body Fat 5.40 GP 36 BLK% 2.00 DRtg 85.90 6 substantially better, by at least one win. -

Box Score Cavaliers
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Saturday, February 22, 2020 AmericanAirlines Arena, Miami, FL Officials: #48 Scott Foster, #24 Kevin Scott, #17 Jonathan Sterling Game Duration: 2:27 Attendance: 19754 (Sellout) VISITOR: Cleveland Cavaliers (15-41) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 16 Cedi Osman F 37:48 6 15 4 11 3 6 2 5 7 7 2 0 0 0 -22 19 22 Larry Nance Jr. F 28:10 5 10 0 4 0 0 2 5 7 1 3 2 3 0 -8 10 3 Andre Drummond C 24:41 3 3 0 0 0 0 1 5 6 1 3 1 4 0 -25 6 2 Collin Sexton G 33:24 5 15 3 7 4 5 0 2 2 9 3 1 4 0 -15 17 10 Darius Garland G 33:16 6 11 2 5 0 0 0 0 0 5 1 2 2 0 -14 14 4 Kevin Porter Jr. 14:13 0 5 0 2 2 2 0 2 2 1 3 1 2 1 -8 2 13 Tristan Thompson 25:59 7 10 1 1 1 2 4 3 7 1 2 0 3 0 -27 16 1 Dante Exum 25:19 3 6 3 5 5 6 2 6 8 1 1 0 2 1 2 14 18 Matthew Dellavedova 08:35 0 1 0 1 0 0 0 1 1 3 0 0 2 0 11 0 41 Ante Zizic 08:35 3 3 0 0 1 1 0 0 0 0 0 1 2 0 11 7 0 Kevin Love DND - Injury/Illness - Right Achilles; Soreness 240:00 38 79 13 36 16 22 11 29 40 29 18 8 24 2 -19 105 48.1% 36.1% 72.7% TM REB: 12 TOT TO: 25 (37 PTS) HOME: MIAMI HEAT (36-20) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 5 Derrick Jones Jr.